Author | Zhang Mengyu
In recent years, the closed-loop data system has become a popular topic in the autonomous driving industry, and many autonomous driving companies are trying to build their own closed-loop data systems.
In fact, the closed-loop data system is not a new concept. In the traditional software engineering field, the closed-loop data system is used as an important way to improve user experience. We believe that everyone has experienced such a situation when using software. A pop-up window appears on the screen, asking you “whether you allow the software to collect your data.” If you agree to the relevant terms, these data will be used to improve user experience.
When a problem is captured by the user-side software, the background can capture corresponding data, which is then analyzed by the development team to repair and improve the software. The new version software will be tested by the testing team and put on the cloud, and users will update to the terminal. This is the closed-loop data system process in software engineering.
In the autonomous driving scenario, problem data is usually collected on trial cars, and only a few vehicles can collect it on mass-production cars. After collection, the data needs to be labeled, and then engineers use the new data to train the neural network model on the cloud. The retrained model is usually deployed to the vehicle end through OTA.
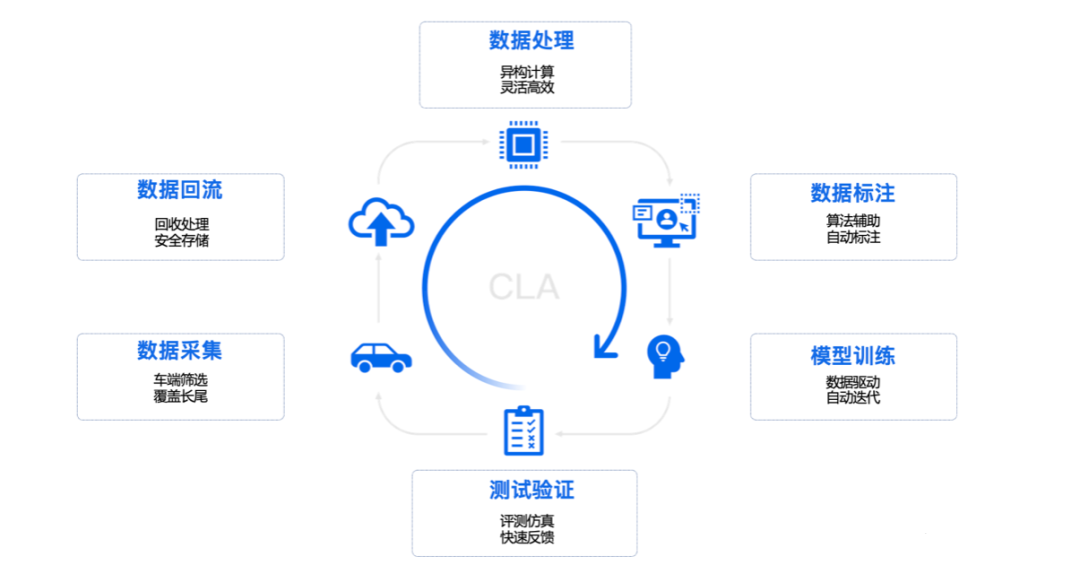
A complete closed-loop data system usually includes data acquisition, data feedback, data processing, data labeling, model training, and test verification.
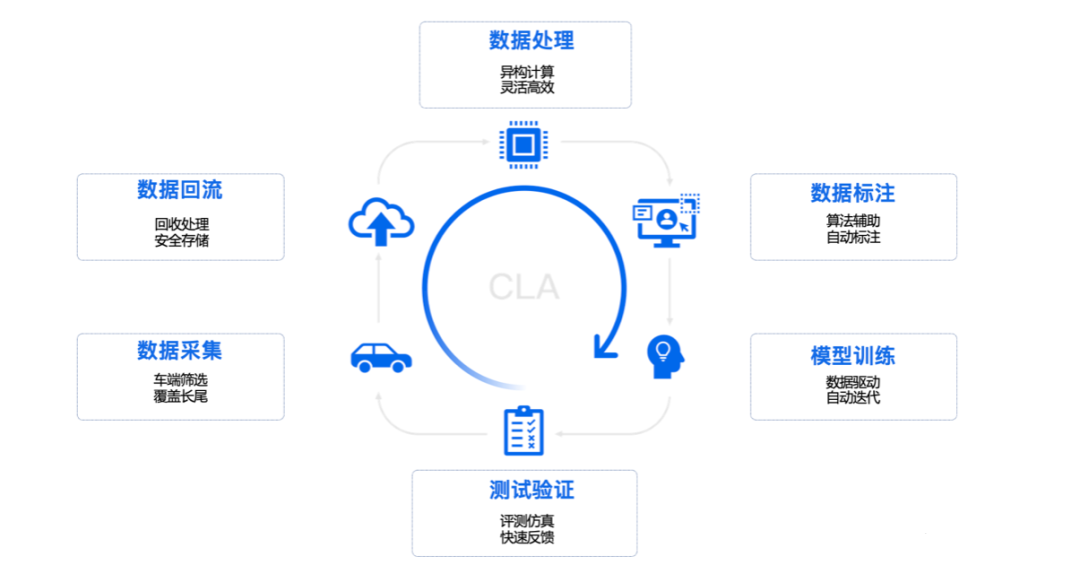
Taking Tesla as an example, the fleet equipped with autonomous driving hardware collects data filtered by triggers through rules and shadow modes, and the semantically screened data is transmitted back to the cloud. Afterward, engineers use tools to process the data on the cloud, place the processed data into the data cluster, and then use this set of effective data to train models. After model training, engineers will deploy the trained models back to the car end for a series of metric checks. The newly verified model will be deployed to the vehicle end for drivers to use.
In this model, new data sources are constantly triggered and sent back, forming a loop. At this time, a complete data-driven iteration development cycle is formed.## The Significance of Closed Loop Data in the Autonomous Driving Industry
Using a closed loop data system to drive algorithm iteration is almost universally recognized as the inevitable path to improving the capabilities of autonomous driving. Many automakers and autonomous driving Tier 1 suppliers are building their own closed loop data systems, with some even creating dedicated positions for closed loop data architects.
What does closed loop data mean? Why is it important to implement closed loop data systems in mass-produced vehicles? What are the challenges of implementing closed loop data in mass-produced vehicles and how can they be addressed?
This article will discuss these topics one by one.
The Significance of Closed Loop Data
According to MAXIEYE, a leading autonomous driving technology provider, “closed loop data not only improves the performance of a single feature, but also allows for shadow-mode verification of new features. Depending on the data categories that trigger it, closed loop data can also help optimize other aspects of the system, such as detecting radar or camera blockages and optimizing thresholds based on feedback data. In terms of performance, closed loop data can optimize almost all aspects, such as AEB, LKA, ELK, ACC, TJA, NOA, etc. MAXIEYE has continuously upgraded AEB, ACC, TJA, and other system functions through OTA updates and has pre-embedded the shadow mode of new functions.”
Today, companies are building their own closed loop data systems, with the primary goal of improving corner case data collection efficiency, improving model generalization ability, and driving algorithm iteration.
1.1 Collecting Corner Case Data
Any Level 2 and above product needs to have the ability to continually evolve. In order to achieve this, it is necessary to constantly obtain corner case data. However, as the number of unknown corner cases continues to decrease and the difficulty of exploring new corner cases through limited numbers and route constraints of test vehicles increases, it is becoming more and more challenging to obtain adequate corner case data.
Deploying a data collection system on mass-produced vehicles with broader scene coverage, and triggering data feedback when the current autonomous driving system is not able to handle the situation well, is a good way to obtain corner case data.
For example, on mass-produced vehicles equipped with Level 2 assisted driving, an AEB system can be deployed, and data can be collected when the driver accelerates, brakes, turns, or steers sharply. By analyzing why the AEB system did not respond when the driver performed these actions, improvements can be made to enhance AEB system performance.### 1.2 Improving Model Generalization Ability
Currently, advanced assisted driving is moving from highways to cities. To solve the relatively simple scenarios on highways, it is basically enough to train the model using the data collected by the test vehicle, rather than necessarily transmitting the data of mass-production vehicles. However, the complexity of the urban scenario has increased significantly, and there are many differences in road conditions between different cities. For example, in Guangzhou, there are everywhere tricycles carrying goods sprinting on the roads, while in Shanghai this situation is rare.
Therefore, many Tier1 autonomous driving companies and automakers have a strong demand for scene connectivity – that is, the vehicle’s assisted driving system can handle various road conditions in major cities. Because automakers cannot limit the user’s driving range, if they only develop assisted driving functions for a small area, it will greatly reduce the range of potential customers, which is obviously not what automakers want to see.
To achieve the goal of scene connectivity, the generalization ability of the model needs to be greatly improved. In order to significantly improve the generalization ability of the model, it is necessary to collect data corresponding to various scenarios as much as possible. And only passenger car assisted driving based on large-scale real human driving data is capable of accumulating a sufficient scale and variety of data.
1.3 Driving Algorithm Iteration
As mentioned earlier, the development of artificial intelligence algorithms based on deep learning has exceeded ten years. During this period, with the evolution of models and the development of computing power, automatic driving systems have become capable of digesting big data. In addition, in order to upgrade the automatic driving system, perception, planning and other aspects need to be correspondingly improved in terms of capabilities. Adopting data-driven methods to continuously evolve algorithms is an efficient way to improve the perception, planning and other capabilities.
City NOA – that is, point-to-point navigation assistance functions within cities, will be the next focus of many automakers and Tier1 autonomous driving companies. To realize the point-to-point navigation assisted driving function, semantic recognition of the perception system, obstacle recognition, and identification of drivable areas all need to have a certain level of accuracy. However, this standard has not been achieved yet.
Currently, the mainstream perception system network architecture is based on the BEV+Transformer model. Reliant solely on software engineers or algorithm architects for optimization, there is not much room for the model to improve. However, the BEV+Transformer architecture can accommodate a large amount of data, which is expected to improve the model’s performance.In terms of planning, data-driven approaches can also be utilized. Previously, Tesla used the optimal solution under partial constraints as the initial value, then incrementally added new constraints and solved the optimization problem with the added constraints to ultimately obtain the optimal solution for the planning problem. To improve this method, Tesla engineers conducted offline pre-generation and parallel optimization online, but the calculation time for each candidate path was still long, ranging from 1 to 5ms. However, according to the content disclosed by Tesla at AI Day on September 30, 2022, Tesla’s engineers now use a data-driven decision tree generation model to help the autonomous driving system quickly generate planning paths. This data-driven decision tree generation model uses human driver data and the optimal path without time constraints in the Tesla fleet as the ground truth for training, and can generate a candidate planning path within 100us, greatly reducing the time to generate the candidate path.
In summary, constructing a closed-loop data system is an important way to enhance the capability of autonomous driving systems.
Background of Closed-loop Data System
Currently, many production vehicles are equipped with advanced driving assistance systems, and it is not difficult to obtain road-test mileage of over 100 million kilometers for autonomous driving systems by collecting data from production vehicles. In addition, with the further enhancement of chip computing power, such as Nvidia’s OrinX chip with computing power up to 254TOPS, large models are being applied to perception systems, making it possible for autonomous driving systems to digest big data. On the other hand, cloud technology is becoming more mature, and autonomous driving is slowly entering an era of data-driven development.
According to MAXIEYE: “To be precise, it is no longer just data-driven, but AI algorithms and data jointly drive the development. AI algorithms solve the problem of learning efficiency, while data solves the problem of learning content. Algorithms and data are in a symbiotic relationship.”
“The development of deep learning-based AI algorithms has surpassed ten years. In the early stages of these ten years, supervised learning was the mainstream in both academia and industry. However, supervised learning has a fatal flaw, which requires massive manual labeling, greatly limiting the space for AI advancement. In recent years, unsupervised and semi-supervised learning algorithms have gradually emerged. Computers can clean up data and iterate algorithms through self-learning. Therefore, the conditions for developing autonomous driving technology through data-driven methods are already mature.”# Completion of L2-L4 architecture loop and data loop are expected to be accomplished by 2022
According to Yang Jifeng, head of the Great Wall Salon Intelligent Center, “from the perspective of the whole vehicle, the architecture loop and data loop from L2 to L4 will be completed in 2022, and the further unification of vehicle-side architecture and cloud architecture will be achieved. The next competition lies in data mining, effective utilization and the understanding of data by the entire technology stack, as well as how to balance the overall computing efficiency on a large-scale infrastructure.”
Pain Points and Countermeasures for Data Loop Deployment
Currently, there is a consensus on the significance of data loop for autonomous driving systems, and the timing for its deployment on mass produced vehicles has basically matured. However, how are the data loops of various companies actually deployed? How can we evaluate the effectiveness of a company’s data loop system?
According to MAXIEYE, a smart driving technology company, for Tier1 of autonomous driving, the realization of the data loop in terms of technology is not a difficult problem, and the key factor is whether Tier1’s product can empower vehicle manufacturers through data loop. Moreover, the effectiveness of the data loop also depends on whether the product iteration is driven by data loop, whether software and algorithms can be optimized based on feedback data, and whether they can be deployed to the end terminal regularly via OTA.
Currently, autonomous driving Tier 1 can be divided into three types according to the level of data loop capabilities: the first is the data loop that has been implemented on a large scale; the second is the data loop implemented through collecting data from cars; and the third is the ability that has not yet implemented the data loop. Currently, the first type is still a minority.
According to the information obtained by the author and industry insiders, most companies currently collect data from cars. Due to factors such as user privacy, basic infrastructure, and cost, collecting large amounts of data from mass-produced vehicles for iterative upgrades of autonomous driving systems has not yet been achieved. Some companies have not established a process for collecting data from mass-produced vehicles for data loops, while some companies have established the process of collecting some data, but have not made good use of it.
It is reported that only a few companies currently collect some data from mass-produced vehicles, but industry insiders reflect that the main purpose of collecting these data is to diagnose the faults of the current autonomous driving system, rather than for iterative upgrades of deep learning models.
In other words, currently, very few companies have truly achieved large-scale mass production of data loops-Good use of data collected from mass-produced vehicles to enhance the capabilities of autonomous driving systems. Then, what are the pain points of mass production deployment of the data loop? And what countermeasures can help address these issues?
3.1 Compliance issues related to data collection and usage
There are various issues that need to be considered when it comes to the practical implementation of mass production. These include but are not limited to: ensuring compliance with data collection and usage, data attribution issues, managing data alongside autonomous driving systems, large-scale data processing difficulties, high-complexity of software systems driven by data, and difficulties associated with model training.
3.1.1 Compliance issues with data collection and usage
Compliance can be divided into mapping compliance and privacy compliance. Mapping compliance mainly concerns compliance when collecting national geographic information, while privacy compliance mainly concerns compliance when collecting user-related data.
In terms of mapping compliance, the state has tightened its management of data security in recent years, enacting relevant laws and regulations to restrict the scope of data transmission. After the “830 New Regulations” in 2022, the data collected by vehicles on the road are all classified as mapping data. To use this mapping data, it is necessary to encrypt the data and ensure its compliance.
Firstly, when collecting data on the road, companies need to possess the national mapping qualification and make relevant filings, otherwise the collection process will be blocked by national security and other departments. Currently, there are about 30 institutions in China with relevant qualifications, some of which have national electronic navigation class A qualifications with a wider applicable scope, while others have class B qualifications with a smaller scope, which can only be collected in specific cities.
Since mapping qualifications are difficult to obtain and require long-term business accumulation, companies need to have relevant mapping businesses in order to maintain these qualifications. Therefore, original equipment manufacturers (OEMs) and Tier1 suppliers for autonomous driving will generally entrust qualified suppliers or units that possess the qualifications, such as some cloud providers that help customers design compliant solutions around data collection, processing, and usage.
After collecting the data, it still needs to be desensitized and encrypted on the vehicle side. After uploading to the cloud (generally a private cloud), some compliance work needs to be done. This part will be done by qualified suppliers or units to help with mapping compliance. For sensitive data, it needs to be collected by map suppliers and stored in a server supervised by the map supplier after desensitization.
In addition, mapping data should not be leaked, especially do not move data abroad. Non-Chinese citizens cannot access mapping data or operate mapping data within the company.
Generally, OEMs and Tier1 suppliers for autonomous driving will establish their own data centers, which are relatively closed for security reasons. In order to comply with requirements, when OEMs and Tier1 suppliers for autonomous driving need to use data stored in these data centers for training and simulation work, they need to deploy relevant models into these data centers for use.According to industry experts, the compliance process for surveying is too complicated, and it is difficult to obtain qualifications. Everyone hopes to minimize reliance on high-precision maps, which is one reason why the “heavy perception, light mapping” solution is popular in the industry. However, in reality, light mapping is not necessarily “better” because map data is definitely better than having none. Currently, this trend is not necessarily the final form, nor is it necessarily the best, it is just that everyone hopes to make it simpler.
In terms of privacy compliance, companies need user authorization to collect data on mass-produced cars. Similar to using WeChat, companies need users to sign an authorization agreement at the beginning and inform users of which data will be collected and which usage behaviors will be recorded.
Currently, in terms of privacy compliance, the country has not yet formulated specific regulations on which data can be collected or not, but there is only a relatively broad clause that stipulates that the data collection side “shall not disclose user privacy.”
In actual operation, data related to user information needs to be anonymized, such as hiding license plate numbers, etc. Chapter Nine has specific introductions in “Understanding Data Anonymization Technology in Smart Cars in One Article,” which will not be elaborated on here.
3.2 Data Right Confirmation
Can we collect the data needed for the autonomous driving industry, such as cameras, lasers, or millimeter waves, in the car?
Sulinfly, the product manager of Moshvision, said: “According to China’s ‘Personal Information Protection Law,’ data collection that is not legally allowed is subject to privacy protection. In Germany, the former Federal Commissioner for Data Protection and Freedom of Information had such regulations. If the driver is not a victim, recording other drivers’ faces and vehicles without their consent is a violation of the Personal Information Protection Law. That is to say, even car owners recording others’ information may be illegal. However, since the autonomous driving industry associated with new energy vehicles is very new, the legal provisions are currently vacant. Therefore, we deduce based on the basic legal principles that the data collected from mass-produced vehicles should be owned by the car owners.”
Can the data collected by car owners using their own vehicles be authorized for use by other units?
Currently, there is no relevant legal provision or constraint. However, in other industries, such as the mobile phone and internet fields, this is widely allowed.
Who can access the data uploaded by car owners?
From the perspective of the automotive industry chain, two main entities can get access. The first is unmanned vehicle fleet operators, such as Baidu’s unmanned taxi. The second is the original equipment manufacturer. However, since the former has a smaller scale, we will focus on the latter.“`
Because the OEMs are closest to the users, they are most likely to obtain user-uploaded data. From a global perspective, Tesla is the OEM that does this best.
Currently, OEMs rarely open up their data, making it difficult for AD Tier 1 to collect feedback data from users when helping OEMs implement custom features, unless Tier 1 has a lot of test vehicles themselves. As a result, AD Tier 1 has difficulty in making subsequent optimizations to related functions based on user feedback data, and the data loop is difficult to achieve.
Magic View’s Product Manager, Su Linfei, told reporters: “After we help OEMs complete a project, if the OEM does not open up data interfaces, it is difficult for us to obtain user feedback data in order to further iterate product performance for a particular car model. As a result, most AD system suppliers have become companies focused on project operations that are gradually being eliminated due to the decline in product performance.”
What is worse is that, as the trend for open-sourcing AD system source code has emerged, some OEMs may want to build their own data loop systems to implement AD functions and therefore do not want to share data with suppliers. But I don’t think it’s reasonable for OEMs to do this. I think it’s best for everyone to specialize in their own field for overall development of the AD ecosystem. It’s just that the industry is still in the early stages of development, and everyone may want to try it out in order to gain more initiative.”
An expert from a new energy OEM stated: “In the past, OEMs did not want to give data to suppliers because they did not understand how the supplier could feedback. Even if data was given in the past, the other party did not know how to use it. But now for cooperative suppliers, such as those providing AD solutions to OEMs, OEMs can open up data usage rights. Of course, the premise of opening up data usage rights is compliance, and suppliers need to ensure that the entire process of receiving and using the data is compliant.”
For OEMs, if they do not open up data to suppliers, then they will have to explore the value of this data themselves. In the early days, everyone did not know the specific value of this data and had to use it to discover its value slowly. OEMs can give data to suppliers to use first, while keeping a copy for themselves. After the supplier uncovers the value of the data, they can give back to the OEM.
Some OEMs now require suppliers to continue to help them iterate software after sop, and suppliers can also use this as an opportunity to obtain data, allowing both OEMs and suppliers to achieve a win-win situation. Of course, from the perspective of OEMs, this approach still has some flaws, as it is difficult for suppliers to guarantee that the iterated results will definitely improve. OEMs also have difficulty verifying the iterative results, so OEMs often require suppliers to open up interfaces for intermediate results (such as perceptual target recognition results) as a way to verify the supplier’s iterative results through statistical indicators targeted at these intermediate results.
“`
Currently, it is necessary for both parties to trust each other and cooperate sincerely. The OEMs need to grant suppliers the right to use open data and the suppliers must regularly update the software and see the corresponding effects. This way, the cooperation could continue. However, this model has not been widely accepted yet, because obvious effects have not been seen until now.
3.3 Data Collection Occupies System Resources
Collecting data on mass-produced cars will occupy some system resources, such as computing and storage. In theory, assuming computing resources and network bandwidth are not limited, it may not have an impact on the normal operation of the ADAS system. However, in the actual process of deployment, it is a challenging problem to ensure that collecting data does not affect the timely operation of the ADAS system, such as how data collection does not affect ADAS system delay.
Of course, some companies upload data only when the ADAS system is not running, so there is no problem of resource allocation. However, some industry insiders believe that uploading data only when the ADAS system is not running will limit the amount of data collected. Therefore, at this stage, it is essential to collect as much data as possible. Therefore, when designing systems, we need to consider the impact of data collection on the operation of the ADAS system.
3.4 Difficulties of Data Annotation and Post-Processing
It is estimated that after the mass-produced cars return the data, the amount of data returned by a single car each day is about one hundred megabytes. During the R&D phase, the total number of vehicles may only be a few dozen or a few hundred. However, in the mass production phase, the number of vehicles can reach tens of thousands, hundreds of thousands or even more. Thus, the total amount of data generated by the entire fleet in mass production is significant.
The dramatically increased data volume has posed challenges to storage space and data processing speed. After mass production, the delay of data processing needs to be at the same level as the delay in the R&D phase. If the underlying infrastructure does not keep up, the delay in data processing will increase significantly with the increase of data volume, which will greatly slow down the progress of the R&D process. An industry expert told the author, “Currently, we have not seen a company with the ability to handle large-scale data returned from mass-produced cars. Even for emerging car manufacturers that are relatively advanced in the data loop, they cannot cope with such data volume, because current storage devices, file reading systems, computing tools, etc., cannot handle huge data volumes.”To cope with the increasing amount of data, the underlying infrastructure and platform design need to be upgraded accordingly.
The engineering team needs to develop a comprehensive data access and storage SDK. Because the file size of visual data and radar data is very large, the efficiency of data access, queries, jumps, and decoding processes needs to be high enough, otherwise it will greatly slow down the research and development process.
After the car-side data is transmitted to the cloud, the engineering team needs to annotate a large amount of data in a timely manner. Currently, the industry will use pre-trained models for assisted annotation, but when the amount of data is large, annotation still requires a lot of work.
When doing data annotation, it is also necessary to ensure the consistency of the annotation results. Currently, the industry has not yet achieved fully automatic data annotation, and still requires manual completion of part of the workload. In the process of manual operation, how to ensure the consistency of the annotation results under the extremely large amount of data is also a major challenge.
In addition, the data related to automated driving is not only large in volume, but also complex in variety, which adds to the difficulty of data processing. Data types are divided according to sources, including vehicle data, location data, environment perception data, application data, personal data, etc. Structured data and unstructured data are divided according to format, and data service types include files, objects, etc. How to unify standards and coordinate different types of storage and access interfaces is also a major challenge.
3.5 High complexity of data-driven software systems
The traditional V-shaped development model is difficult to apply to a data closed loop. Moreover, there is currently no unified software development platform and middleware oriented towards higher-level automated driving in the industry.
Technical experts in the automated driving department of a certain company told the author that “the iterative system of automated driving functions driven by data and deep learning models can be called software 2.0. In this mode, the entire system, including team building, research and development processes, test methods, and toolchain, revolves around data.”
In the era of software 1.0, what code everyone submitted and the expected results were easy to evaluate. However, in the era of software 2.0, the difficulty of measuring the impact of each person’s contribution on the overall effect has increased, and it is also difficult to foresee it in advance, because what everyone communicates with each other is no longer clear and visible code, but data and models updated based on data.
When there is very little data, such as when we were working on AI visual algorithms for mobile internet applications before, because the amount of data was very small, and the visual model engineers involved basically managed their Windows or Ubuntu folders separately, team members directly used various renamed folders to transmit data, which was very inefficient for data exchange or collaboration.When it comes to autonomous driving tasks, we are faced with hundreds of thousands of images and a system developed by hundreds of people. Each modification could affect hundreds or even thousands of modules. How to evaluate the code quality of each module, and how to check for conflicts between them are complex tasks. So far, I think the system is still quite bad, and the engineering part is not mature enough.
In the software 2.0 stage, we also need to address other problems such as how to measure the specific impact of new data on certain scenarios and the overall impact. We also need to avoid the situation where the model is retrained based on new data and performs better in some specific tasks but worse overall. We need to conduct unit tests to check whether the new data helps us solve the specific problem we want to address and whether it has a positive impact on the overall performance.
For example, suppose the original dataset of a specific task includes 20 million images, and we add 500 more images. This can improve the ability to solve the problem, but sometimes it also means that the model’s overall performance is reduced.
In addition, for visual tasks, besides relying on metrics to evaluate the impact of new data on models, we also need to check the actual impact to see if the optimization meets expectations. Only looking at metrics may lead to situations where performance does not meet expectations, even though the metrics have improved.
We also need an infrastructure to ensure that every update we make is globally optimal. This infrastructure involves managing data and evaluating training. Tesla is at the forefront of this aspect, and its data-driven entire process design leads the industry. From 2019 to 2022, the infrastructure can support product iterations without significant changes.
Moreover, after solving problems such as data collection, storage, and annotation, model training and functional iteration remain a challenge. High efficiency file transmission systems are needed to handle the large amount of data transmitted by production vehicles, to ensure that I/O does not bottleneck training. At the same time, we need sufficient computing power. Typically, we can build a multi-card parallel cluster to increase computing power. However, we also need to find ways to maintain efficient communication between cards during training to reduce data transmission delays and make full use of the computing power of each card.To meet the computing power demands of model training, some automobile manufacturers have built their own smart computing centers. However, the cost of building such centers is high, making it almost impossible for small and medium-sized enterprises.
Despite the many pain points that still exist, we can still expect that these problems will be solved one by one in the future. By then, the data loop will be truly implemented in mass-produced cars. After being implemented on mass-produced cars, the collected data will feed back into the data loop system, promoting the development of autonomous driving systems to a higher level.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.