Author: Su Qingtao
In the field of autonomous driving simulation, there are many points of knowledge, with “simulating real road data” ranking first. I have been curious about this for more than two years, but I had no chance to learn it before. During the outbreak in April last year, I had the opportunity to chat with the founder of a simulation company and consulted him on many questions.
After that, for cross-validation, I consulted nearly 20 experts in the front line of autonomous driving simulation business.
Experts who supported the study notes of this series include but are not limited to An Hongwei, CEO of Zhixing Zhongwei, Yang Zijiang, founder of Shenzhen Science and Innovation, Li Yue, CTO of Zhixing Zhongwei, Bao Shiqiang, CTO of 51 World, as well as experts in simulation from Haomao Zhixing, Qinzhou Zhihang, and Choyright Intelligence. I would like to express my gratitude here.
Question 1: Scenario source — from synthetic data to real road data
According to Li Manman, the author of WeChat public account “Chelumanman,” and Li Yue, CTO of Zhixing Zhongwei, there are generally two approaches to the source of simulation testing scenarios:
The first approach is the three-level system of functional scenarios, logical scenarios, and specific scenarios proposed by the PEGASUS project in Germany: 1) Obtain different scenario types (i.e., functional scenarios) through real road data collection and theoretical analysis; 2) Analyze the key parameters of these different scenario types, and obtain the distribution range of these key parameters through real data statistics and theoretical analysis (i.e., logical scenarios); 3) Finally, select a set of parameter values as a test scenario (i.e., specific scenarios).
As shown in the figure below:
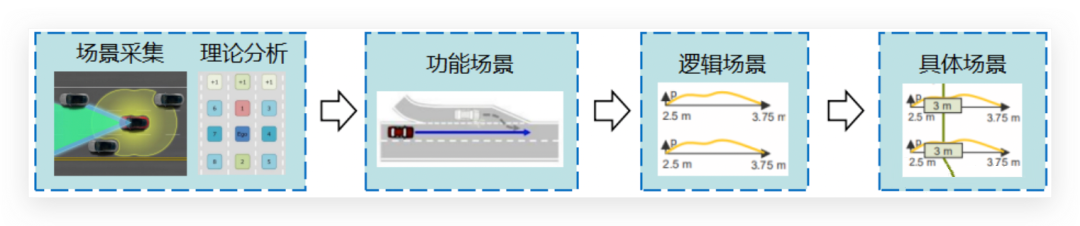
For example, a functional scenario can be described as “the test vehicle is driving in the current lane, and a lead vehicle is accelerating ahead of it, so the test vehicle needs to follow the lead vehicle.” The logical scenario extracts the key scenario parameters, and assigns specific values according to the distribution range of these key parameters, such as the test vehicle speed, the lead vehicle speed and acceleration, the distance between the test vehicle and the lead vehicle, etc. Each parameter has a certain range of values and distribution characteristics, and there may be correlations between parameters. The specific scenario needs to select specific values of the scenario parameters, compose the scenario parameter vector, and represent it in a specific scenario language with specific words.
This is what is commonly referred to as “virtual construction/generation of scenes using algorithms.” Although the understanding of the scene still comes from real road scenes, in practice it is mostly based on this understanding to “manually set” a driving trajectory and a set of scenes in software. Therefore, the data behind this kind of scene is also called “synthetic data.”
In practice, the main challenge facing this approach is whether the simulation engineer’s understanding of normal driving scenes for vehicles is deep enough. If the engineer does not understand the scene and arbitrarily “draws up” a scene, it will definitely not be useful.
The second approach is to collect traffic flow data within the autonomous driving vehicle’s designated working area automatically, input these data into traffic simulation tools to generate traffic flow, and use this traffic flow as the “surrounding traffic vehicles” for the autonomous driving vehicle to achieve automatic generation of testing scenarios.
According to Yang Zijiang, the founder of DeepBlue Tech, to ensure more accurate “truth”, typically, the sensor configuration for collecting engineering data onboard the vehicle will be much higher than that for ordinary autonomous vehicles, such as positioning systems that use equipment of 20W or more and high-fidelity LiDAR data.
Waabi, a simulation company founded by former UberACT Chief Scientist Raquel Urtasun, is said to use camera-collected data for simulation without high-precision sensors, such as LiDAR.
The biggest advantage of using real road data for simulation is that the diversity of scenes will not be limited by engineers’ inadequate understanding of the scene, making it easier to identify those “unimaginable” unknown scenes.
In addition, a simulation manager at an autonomous driving company said that in order to increase the realism of simulation, fewer and fewer synthetic data will be used, and more and more real road data will be used. In fact, simulation is already moving towards this direction – there are more and more real data and modules being used.
However, engineers who are engaged in first-line simulation practice generally believe that this approach is too idealistic. Specifically, there are several limitations to using real road data for simulation:
- The data needs to be manually verified.
In fact, the data collected by sensors cannot be directly used for simulation – the data types and formats need to be converted, a lot of invalid data needs to be cleaned up, valid scenes need to be identified from them, and certain specific elements need to be annotated, and data from different sensors need to be synchronized and fused in real time, among other things.The perception data of autonomous vehicles is usually directly fed to the decision-making algorithm without the need for manual verification. However, if it is for simulation purposes, manual verification of the perception data is an essential step.
- Implementing the reverse process is more difficult than the forward process.
A simulation engineer from a self-driving truck company said, “Using synthetic data for simulation is a forward process, where you first know which tests you need to do and then actively design such a scenario. Using real data for simulation is a reverse process, where you first encounter a problem and then try to solve it. Compared to the former, the latter is much more difficult.”
- Unable to solve interaction issues.
Jame Zhang, the head of Fu Rui Microelectronics, mentioned in a public sharing session that WorldSim (simulation using virtual data) is like playing a game, while LogoSim (simulation using real road data) is more like watching a movie. Therefore, LogoSim cannot solve the problem of interactivity naturally.
- Unable to perform closed-loop simulations.
Jame Zhang also mentioned another difference between these two simulation methods: using real road data for playback can only collect a limited segment of data, and danger may have occurred some time before the collection began, making it difficult to obtain previous data. However, if virtual data (synthetic data) is used, this problem can be avoided.
A simulation manager from a leading automaker said, “The above expert’s description is about the collection process. Indeed, considering the capacity of the collection equipment and the definition of effective scenarios, the scenes where data is collected have limited length, usually before and after the function trigger. The cache before the trigger is not particularly long. On the other hand, when using collected data for playback, only the scene before the function trigger is valid, but the real scene after the function trigger is invalid.”
The simulation manager of this automaker also emphasized that “the term ‘unable to achieve closed loop’ is relative. There are already suppliers who can parameterize all the elements in the collected scene, so closed-loop simulation is achievable, but the equipment for that kind of simulation is very expensive.”## 5. Ensuring the authenticity of data is still a challenge
The use of actual traffic data in simulation, also known as “playback”, requires two core technologies, as explained by Yang Zijiang, founder of Deepthinking Tech: first, the road network structure of the collected data must be restored in the simulation environment, and second, the pose information of dynamic traffic participants (such as pedestrians and vehicles) in the road-collected data must be mapped to the global coordinate system of the simulation world.
To achieve this, tools such as SUMO and OpenScenario are needed to read the participant’s position information.
One simulation expert from a major automaker says, “However, even the playback of raw data cannot ensure 100% authenticity because vehicle dynamics simulation must be added after the raw data is injected into the simulation platform. But in doing so, it is difficult to say whether the scene is still consistent with the one on the real road.”
The main shortcomings of current traffic flow simulation software are as follows:
-
The generated traffic flow is not authentic enough, often only supporting the import of vehicle trajectories and lacking bi-directional interaction between vehicles.
-
The data transmission interface between the simulation module (the ego car) and the traffic flow module (other road users) is limited (such as different road network formats requiring network matching), and third-party operability is limited.
-
Rule-based traffic flow models are designed for traffic efficiency evaluation and may oversimplify the actual scenario (often using one-dimensional models, assuming driving is along the center line, and paying little attention to lateral effects), making it difficult to satisfy interactive safety requirements.
A simulation engineer from a Tier 1 company explained that the generation of a simulation scenario from actual traffic flow data involves considerable difficulty in choosing a traffic flow model (such as defining follow-up models and lane changing models) and defining the interface between traffic flow simulation modules. Synchronizing data from both the ego car and other road users also presents a major challenge.
6. Low universality and high generalization difficulty of data
An Hongwei, CEO of Zhongwei Smart Travel, and Li Yue, CTO, particularly emphasized the issue of data universality in simulation. Data universality refers to the adjustability of vehicle and scene parameters. For example, if data were collected by a sedan with a low camera angle, after being converted into a simulation scenario, the camera angle can be increased and the data can also be used for testing truck models.
If the scenario is built virtually, the parameters can be adjusted as needed. But what about scenarios based on real-world road data?
The simulation chief of a certain toolchain company stated that in simulation using real road data, once the position or model of the sensor changes, the value of this set of data will decrease, and even become “invalid.”
The simulation expert from QZ Smart Navigation stated that neural networks can also be used to parameterize real road data. This kind of parameterization has a higher level of intelligence, but controllability is weaker.
Simulation using real traffic flow data is also known as “playback,” which can be divided into two types: direct playback and model playback.
Direct playback refers to feeding the algorithm with sensor data without any processing. In this mode, the parameters of the vehicle and scene cannot be adjusted, and the data collected by a certain vehicle model can only be used for simulation testing of the same model.
Model playback refers to first abstracting and modeling the scene data and expressing it using a set of mathematical formulas. In this mathematical formula, the parameters of the vehicle and scene are adjustable.
According to Li Yue, direct playback does not require the use of mathematical models, “it is relatively simple, and can be done as long as there is big data capability”. However, in their model playback solution, whether it is the sensor model or the vehicle’s driving trajectory and speed, it all needs to be accomplished through math formulas.
The technical threshold of model playback is very high, and the cost is also high. A simulation engineer said: “Converting sensor recorded data into simulation data and interpreting data is very difficult. Therefore, currently, this technology is mainly used at the PR level. In practice, the simulation tests of each company are mainly based on algorithm-generated scenes, supplemented by scenes collected from real roads.”
The simulation chief of a certain autonomous driving company said: Using real traffic flow data for simulation is still a cutting-edge technology, and the difficulty of parameter tuning for this data is very high (only for tuning within a very small range). Because the data captured from the road is a bunch of logs and records of how the vehicle runs in the first and second seconds, and not like some scenarios edited manually which are composed of a series of formulas.
This simulation expert stated that the biggest challenge for model playback is: in complex scenes, the difficulty of expression using formulas is extremely high, and this process can be achieved through automation. However, whether the ultimately produced scene can be used is still a problem.
Waymo’s ChauffeurNet, which was announced in 2020 and “simulates by directly generating realistic image information collected by sensors,” is actually a model playback, in which neural networks are used to convert original road data into mathematical models in the cloud for simulation. But a simulation expert who has been working in Silicon Valley for many years stated that this is still in the experimental stage and will take some time to become a real product.The simulation expert suggested that instead of data playback, introducing machine learning or reinforcement learning would be more meaningful. Specifically, after fully learning the behavior habits of various traffic participants, the simulation system would train its own logic, formalize these logics into formulas, and then tune the parameters in these formulas.
However, Li Yue, CTO of Zongwei, and Feng Zonglei, deputy general manager, said that they could already achieve model playback.
Feng Zonglei believes that whether a simulation company has the ability to perform model playback mainly depends on the tools and scenario management capabilities they use.
“In scenario management, slicing is a very important part – not all data is valid. For example, in one hour of data, only less than 5 minutes may be truly effective. When doing scenario management, the simulation company needs to cut out the effective part, which is called’slicing’.”
“After the slicing is completed, the simulation company also needs to have a corresponding management environment with semantic information (such as which is a pedestrian and which is a crossroad) for easy filtering next time. Specifically, it is necessary to classify the data slices first and then refine the dynamic target list. After refinement, they are imported into the model of the simulation environment so that the model has corresponding semantic information. With semantic information, parameters can be adjusted, and data can be reused.”
“The reason why most companies based on real traffic flow data cannot adjust parameters is that they have not done scenario management.”
Yang Zijiang, founder of Deepinno Tech, said: “If you want to generalize road data and keep the data true, you can replay the road data during scenario initialization and start-up stages, and then let the smart-npc model take over the background vehicles in the road at a certain moment, so that the background vehicles will not run according to the road data. After smart-npc takes over, it records the generalized scene to achieve replay of the key scenes after generalization.”
A simulation engineer from a certain host factory believes that although model playback sounds “cool”, in fact, its “necessity is not significant.” The reason is: the goal of modeling data and playback is not consistent – the goal of playback is to obtain real data, but once it is modeled and its parameters can be adjusted, it is not the most true. Besides, it is time-consuming and laborious. The format conversion of data is very troublesome and thankless.
“This engineer said: “Since you want more scenarios, just use the simulator to generate generalized scenes on a large scale, and you don’t have to take the road of modeling real data playback.”### Response from Feng Zonglei:
“Generating scenes directly through algorithms may not be a problem in the early stages of development, but its limitations are also obvious — what about the scenes that engineers cannot imagine? The real traffic conditions are constantly changing, and it is impossible for your imagination to enumerate them all.
“More importantly, the interaction between target objects in the scenes imagined by engineers is often unnatural. For example, if a vehicle inserts in front of you, at what angle is it inserted? Is it inserted at 10 meters or 5 meters away from you? In the practice of generating scenes through algorithms, the formulation of scene parameters often carries a significant degree of subjectivity and arbitrariness. The engineer comes up with a set of parameters to inject into the model, but are these parameters representative?”
Feng Zonglei believes that generating virtual scenes through algorithms can meet the requirements of unmanned driving in the Demo stage, but in the era of front-end mass production, it is very necessary to use large-scale natural driving data (real traffic flow data) for scene generalization.
According to an individual who has had contact with Momenta, “Momenta already has the ability to use real road data for scene generalization (parameter tuning), but they only use this technology for themselves and do not share it with others.”
Bao Shiqiang, the person in charge of 51 World’s car simulation, believes that using natural driving data for generalization is still relatively forward-looking at present, but it will definitely become an important direction in the future, and they are also exploring this.
Summary: The two routes are increasingly permeating, and the boundaries are becoming increasingly blurred
James Zhang, the person in charge of simulation at Fourier Intelligence, mentioned in a recent sharing session that there are two methods for Tesla’s simulation: WorldSim, which is completely virtual scenes (generated through algorithms), and LogSim, which replays real data for the algorithm to assess. “However, the road network in WorldSim is also generated based on automatically standardized data from real roads, so the boundaries between WorldSim and LogSim are becoming increasingly blurred.”
The simulation expert at QZJH says, “After real scene data is transformed into standardized formatted data, rules can be applied to achieve generalization and generate more valuable simulation scenes.”
Bao Shiqiang, the person in charge of the 51 World car simulation business, also believes that in the future, the trend will be for the two routes of using algorithm-generated data and real road data for simulation to interpenetrate.
Bao Shiqiang says, “On the one hand, generating scenes through algorithms also depends on engineers’ understanding of real road scenes. The more thorough the understanding of real scenes, the closer the modeling can be to reality. On the other hand, using real road data for simulation also requires slicing and extracting the effective parts, setting parameters, triggering rules, making fine classifications, and then logicalizing and formulating them.”### Question 2: Scenario Generalization and Extraction
The “parameter tuning” repeatedly mentioned above for scene data is also called “scenario generalization”––usually referring to generalization of virtual built scenes. As a system engineer from a certain automaker pointed out, the advantage of scenario generalization is that we can “create” some scenes that have never existed in the real world.
The stronger the scenario generalization ability of a simulation company is, the more usable scenes can be obtained by tuning certain scenes. Therefore, scenario generalization ability is also a key competitive advantage for simulation companies.
However, an algorithm expert from Swift Navigation said that scenario generalization can be implemented through mathematical models, machine learning, and other methods. The key question is how to ensure that the generalized scenarios are both realistic and more valuable.
What are the key factors determining the strength or weakness of a company’s scenario generalization ability?
According to Yang Zijiang, the founder of DeepTech, a major difficulty in scenario generalization is how to abstract trajectories into higher-level semantics and express them using a formalized descriptive language.
According to a Tier 1 simulation engineer, it mainly depends on the language (such as OpenSCENARIO) used by the company’s simulation tool to describe different traffic scenarios, and whether the language is reasonably defined at various levels in the traffic environment (which can represent the required details while also being expandable).
There are also corresponding scenario languages for functional, logical, and specific scenarios, such as high-level scenario language like M-SDL for the first two, and OpenSCENARIO and GeoScenario for the latter.
Another level may be the degree of generalization for interfering behaviors, including various driving behaviors and driving “personalities.”
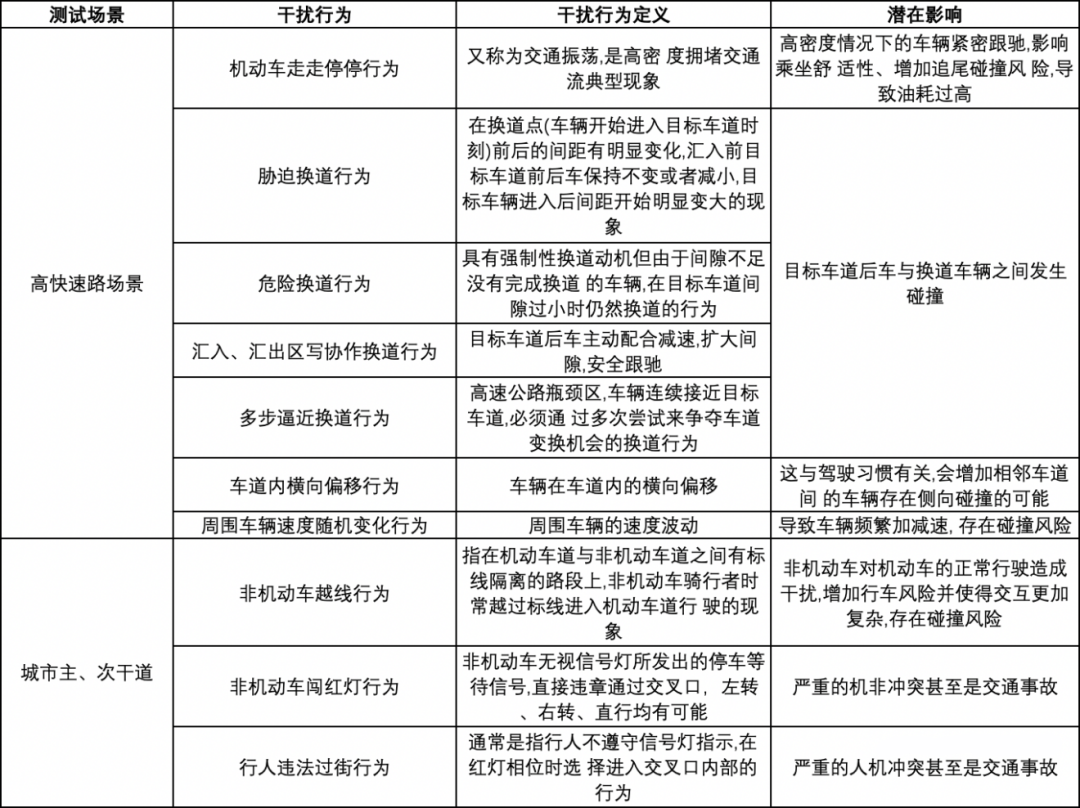
According to Yang Zijiang, the founder of Swift Navigation, “based on the generalization of traffic flow and the intelligence of drivers, if the model is good enough, running the scenario ten times due to the existence of random factors is equivalent to generalizing ten scenarios.”
However, Li Yue, CTO of Zhixing Zhongwei, believes that we cannot generalize for the sake of generalization. “We must have a deep understanding of the functions being tested and then design a generalization plan, rather than generalizing for the sake of generalizing or going too far with generalization. Scene generalization may be virtual, but it must also respect reality.”
Another simulation expert said, “In the final analysis, simulation is still for the service of testing. We have encountered a problem on the road and then we look for ways to solve it through simulation, rather than saying that we have a simulation technology and then trying to find a problem to apply it to.”
As mentioned earlier, a simulation expert stated that from his knowledge, currently, there are not many companies that can truly achieve self-generalization of scenes. In most cases, parameter tuning is done manually. “Although scene generalization ability is very important, at this stage, no company can do it well.”
Bao Shiqiang, the person in charge of 51 World’s car-mounted simulation business, believes that the most important thing in scene generalization is to have a deep understanding of what kind of scene automatic driving simulation testing requires. In fact, the problem now is not that there are too few generated scenes, but that there are too many scenes that will not actually occur, which cannot be regarded as effective testing scenes, due to inadequate understanding of the requirements.
Some experts have said that the biggest challenge facing third-party simulation companies is that they have not personally participated in automatic driving and thus have insufficient understanding of what kind of simulation is needed.
And those L4 level automatic driving companies that have the ability and deeper understanding of simulation needs do not have enough motivation to do great depth in scene generalization. Robotaxi usually only runs in a very small area of a city, and they only need to collect scene data from this area for training and testing, and there is no need to generalize a lot of scenes that they will not encounter for a considerable period of time.
Bao Shiqiang believes that for companies like Weizhixiao and other automakers, there is a relatively large amount of real road data, and they do not have great demands for scene generalization. On the contrary, what is more urgent for these companies is to do fine-grained classification and management of scenes and filter out truly effective ones.
The simulation expert of Light Boat Navigation also believes that as the scale of the fleet increases, and the amount of data from real roads increases dramatically, it is much more important for simulation companies to fully tap into the effective scenes in this data than to do scene generalization. “We may explore more intelligent generalization methods that can quickly verify algorithms on a large scale.”Yang Zijiang said: “Regarding the generalization at the parameter level, such as the number of lanes, the number of types of traffic participants, weather, speed, TTC and other key parameters, the ability of various companies to generate generalized scenarios is almost the same. However, the core of scenario generalization ability lies in how to identify effective scenarios and filter out invalid scenarios (including repeated and unreasonable ones); and the difficulty of scenario recognition lies in the need to identify the relationships between multiple objects in complex scenarios.”
The “identification of effective scenarios and filtering out of invalid scenarios,” mentioned by the experts above, is also known as “scenario extraction.”
The premise of scenario extraction is first to clarify what is an “effective scenario.” According to several simulation experts, in addition to scenarios that should be tested according to legal regulations, effective scenarios also include the following two types: scenarios defined by engineers based on algorithm development requirements when designing the system in a forward manner, and scenarios that cannot be solved by algorithms discovered during testing.
Of course, effective and invalid are both relative, which is related to the company’s development stage and the maturity stage of the algorithm. In principle, with the maturity of the algorithm and the solution of problems, many of the original effective scenarios will become invalid scenarios.
So how does everyone efficiently screen for effective scenarios?
There is a hypothesis in academia that sets up some entropy values in perception algorithms. When the complexity of the scenario exceeds these values, the perception algorithm marks the scenario as effective. However, there is a great challenge in how to set these entropy values.
The simulation company mentioned earlier employs an “exclusion method.” If an algorithm that was originally performing very well has “frequent problems” in certain generalized scenarios, the scenario is likely to be an “invalid scenario” and can be excluded.
A system engineer from a certain automaker said: “There is currently no good method for screening scenarios. If you are uncertain, then put it on cloud simulation to calculate. In any case, you can calculate these extreme scenarios, and then use these extreme conditions for verification on your own HIL or VIL platform, which will greatly improve efficiency.”
Question Three: What is the difficult part of simulation?
In the process of communication with many simulation companies’ experts and their downstream users, we learned that currently, one of the most challenging aspects of autonomous driving simulation is sensor modeling.
According to Li Yue, the CTO of Zhixing Zongwei, sensor modeling can be divided into several levels, including functional information level modeling, phenomenon information level / statistical information level modeling, and full physical level modeling. The differences between these concepts are as follows —
- The functional information-level modeling describes simply the functions of the camera output image and the millimeter wave radar for detecting targets within a certain range. The main purpose is to test and verify perception algorithms, but does not focus on the performance of the sensors themselves.
- The phenomenon information and statistical information-level modeling is a mixed, intermediate-level modeling that includes some functional information-level modeling as well as some physical-level modeling.
- The full physical-level modeling simulates the entire physical chain of the sensor’s operation, with the objective of testing the physical performance of the sensor itself, such as the filtering ability of the millimeter wave radar.
In a narrow sense, sensor modeling refers specifically to full physical-level modeling. Very few companies can do this well, for the following reasons:
- Inefficient image rendering
From the perspective of computer graphics imaging principles, sensor simulation includes simulations of light (input, output), geometric shapes, material, and image rendering. The difference in rendering capabilities and efficiency affects the authenticity of the simulation.
- Too many types of sensors & the “impossible triangle” of model accuracy, efficiency, and universality
It is not enough to have a high precision single sensor. You also need all the sensors to simultaneously reach an ideal state, which requires broad coverage in modeling. However, under cost pressures, simulation teams cannot do 10 or 20 versions of laser radar modeling. On the other hand, it is difficult to use a universal model to express various types and styles of sensors.
The accuracy, efficiency and universality of the model are a relationship of the “impossible triangle”. You can improve one or two sides or even both sides, but you can hardly continuously improve all three dimensions simultaneously. When the efficiency is high enough, the model accuracy must decrease.
Carzone’s simulation experts said, “Even the most complex mathematical model may only simulate real sensors with 99% similarity. However, the remaining 1% can be a factor that causes fatal problems.”
- Sensor modeling is constrained by the parameters of target objects
Sensor simulation requires external data, which means that external environmental data is strongly coupled to the sensor, but the external environment modeling is also quite complex and costly.
In urban scenarios, the number of buildings is too high and this will severely consume the computing resources used for image rendering. Some buildings will obstruct the traffic flow, pedestrians, and other target objects on the road. The calculation load is completely different with and without obstruction.In addition, it is difficult to model the reflectivity and materials of the target accurately through sensors. For example, it can be said that a target is cylindrical in shape, but it is difficult to express whether it is made of iron or plastic through modeling. Even if it can be expressed clearly, it is still a huge task to adjust these parameters in the simulation model.
If the physical information of the target’s materials is unclear, it is difficult for the simulation simulator to choose.
- It is difficult to determine how much noise the sensor should add
A Tier 1 simulation engineer said: “The deep learning algorithm to identify objects is a process of collecting sensor data from the real world and removing signals from noise. In contrast, sensor modeling is to add noise reasonably based on the ideal physical model. The difficulty lies in how to add noise that can be close enough to the real world, so that the deep learning model can recognize it while effectively improving the generalization of the model recognition.”
In other words, the sensor signal generated by the simulation needs to be “similar enough” to the real-world sensor signal (able to identify the corresponding object), but not “too similar” (simulate corner cases so that the perception model can recognize it in more situations—generalization). However, the problem is that in the real world, sensor noise is often random, which means that how the simulation system simulates these noises is a major challenge.
From the perspective of sensor principles, camera modeling also needs to perform camera blurring (first generate an ideal model and then add noise), distortion simulation, vignetting simulation, color conversion, fisheye effect processing, etc. Similarly, lidar models can be divided into ideal point cloud models (including scene clipping, visibility determination, occlusion determination, and position calculation), power attenuation models (including settings for received laser power, reflected laser power, reflected antenna gain, target scattering cross section, aperture size, target distance, atmospheric transmission coefficient, optical transmission coefficient, etc.), and physical models considering weather noise.
- Resource constraints
An Hongwei, the CEO of zongwei intelligence, mentioned the limitations of resources on sensing virtual simulation: “We need to do full physical modeling of sensors, such as the optical physical parameters of cameras, and we also need to know data such as the material and reflectivity of the target (perception object). This is a huge task. -In the case of sufficient manpower, the construction cycle of a one-kilometer scene takes almost a month. Even if it can be built, the complexity of the model is extremely high and it is difficult to run on the current physical machines (it is too computationally expensive).”“`
Future simulation needs to be on the cloud. Although the computing power on the cloud seems unlimited, when it comes to a single node model, the computing power on the cloud may not be as good as a physical machine. In addition, when simulating on a physical machine, if the computing resources on one machine are not enough, three machines can be used, one for sensor modeling, one for dynamics, and one for governance. However, when running simulations on the cloud, the computing power available for a single scenario and a single model is not infinite, which limits the complexity of the model.
It is difficult for simulation companies to obtain low-level data from sensors.
Full physical modeling requires all the various aspects of the sensor to be mathematically modeled. For example, a specific performance of the signal receiver, the propagation path (including the impact of air, the entire chain of reflection and refraction) can be expressed as a mathematical formula. However, in the early stage when software and hardware are not yet truly decoupled, the sensing algorithm inside the sensor is a black box that simulation companies cannot understand.
Full physical modeling requires obtaining the underlying parameters of the sensor components (such as CMOS chips, ISPs), modeling these parameters, and understanding the underlying physical principles of the sensor, as well as modeling the laser waves of the Lidar and the electromagnetic waves of the mmWave radar.
To this end, a simulation expert said, “To model sensors well, one must have a deep understanding of underlying hardware knowledge, almost equivalent to knowing how to design a sensor.”
However, sensor vendors generally do not want to open up their low-level data.
Li Yue, the CTO of Zongwei, said: “If you get these underlying parameters and use them for modeling, you can basically create this sensor.”
Andongwei, the CEO of Zongwei, said: “Usually, when the host factory is dealing with sensor suppliers, not to mention the material physics parameters and other details, it is already difficult to get the interface protocol. If the host factory is strong enough and the sensor supplier is willing to cooperate, they can get the interface protocol, but not all of it. Things that even the host factory finds difficult to obtain would be even more difficult for simulation companies.”
In fact, the physical-level simulation of the sensor can only be done by the sensor vendor itself. Many domestic sensor vendors rely more on the integration of externally sourced chips and other components. Therefore, TI, NXP and other upstream suppliers are the ones who can really do physical-level sensor simulation.
An engineer from a commercial unmanned driving company said: “Simulating sensors is difficult, which makes the process of selecting sensors very complicated. When we need to select sensors, the sensor company usually sends us a sample, and then we install various types of sensors on the car to test them. If sensor vendors can cooperate with simulation companies, they can open up all the interfaces between them and provide accurate sensor modeling. As a result, the amount of work required to select sensors will be greatly reduced at a low cost.”
“`However, according to Bo Shiqiang, the CTO of 51 World, “Perception simulation is still in its early stages, and it is far from necessary to model sensors so finely. It is meaningless to disassemble and model the things inside the sensors.”
In addition, as stated by the simulation director of a certain unmanned driving company, the inability to simulate sensors does not mean perception simulation cannot be fully done.
For example, in Hardware-in-the-Loop (HIL), physical sensors (both sensors and domain controllers) can be connected for testing. By connecting physical sensors, both perception algorithms and sensor functionality and performance can be tested. In this mode, the sensors are real, and the simulation accuracy is higher than sensor simulation.
However, due to the complexity of integrating supporting hardware and the need for sensor models to control the generation of environmental signals, the cost is higher, and therefore, this method is rarely used in practice.
Attachment: Two Stages of Autonomous Driving Simulation Testing
(From the article “Introduction to Autonomous Driving Virtual Simulation Testing” published on the public account “Carlu Slowly” on March 26, 2021.)
Considering the current situation, autonomous driving simulation can be roughly divided into two developmental stages (of course, these two stages may not have obvious time boundaries).
Stage One:
Test the perception and recognition module of the sensor in the laboratory and closed test field, and test the decision and control module in the virtual simulation environment. The simulation environment directly provides the target list to the decision and control module.
This is mainly because there are still many limitations in modeling sensors, which make it difficult to simulate them effectively (even correctly). For example, it is relatively easy to simulate the images output by a camera, but it is difficult to simulate characteristics such as stains and strong light; and in order to establish a highly accurate model of millimeter wave radar, the calculation speed is slow and cannot meet the simulation testing requirements.
In the laboratory and closed test field, the test environment can be fully controlled and data can be recorded. For example, different types, positions, and speeds of pedestrians and vehicles can be arranged, and the environmental elements such as rain, snow, fog, and strong light can be simulated. The target list output by the sensor processing can be compared with the real environment to provide evaluation results and improvement suggestions for the perception and recognition module.
The advantage of doing this is that, under the circumstances of many limitations in sensor modeling, testing of the decision and control module can still be carried out in the simulation environment, thus enjoying the advantages of simulation testing in advance.(2)阶段二:
The high-precision sensor modeling is carried out in a virtual simulation environment to test the complete autonomous driving algorithm. This not only improves the testing efficiency, scenario coverage, and complexity by conducting tests in the same environment, but also allows for end-to-end testing of AI-based algorithms. The challenges of this stage include meeting the testing requirements for sensor modeling and dealing with potential inconsistencies (in some cases, non-existence) in interfaces between different sensor and OEM manufacturers.
Question 4: What are the differences in simulation testing between lower and higher levels of autonomous driving?
Simulation is an auxiliary tool for lower level autonomous driving, but for higher level autonomous driving, simulation is a threshold requirement – L3 requires sufficient simulation mileage before it can hit the road. According to a simulation expert from a major automaker, autonomous driving companies generally have stronger L4 simulation capabilities, while third-party simulation companies primarily focus on L2 simulations. So, what are the specific differences in simulation testing between these two stages?
- Functional boundaries
According to a simulation expert from QZ Intelligent Navigation, “L2 product definitions are mature and functional boundaries are clear, so service providers’ simulations are highly compatible with various automakers. However, the functional boundary of L4 is still being explored, so customers have high levels of customization needs for simulation.”
- Scale of scenario libraries
From a testing scenarios perspective, L4 has a higher complexity of testing scenarios (ODD) with far more scenario libraries than L2, as noted by Yang Zijiang, founder of DeepBlue Technology.
- Requirements for scene reproducibility
An expert in simulation from a major automaker says, “L4 simulation has higher requirements for scene reproducibility, which means that issues found on roads should be able to be replicated in simulation scenarios. However, many companies that simulate for L2 have not considered this issue yet.”
- Attention to data mining capabilities
While low-level autonomous driving simulation mainly focuses on the authenticity of scenarios, high-level autonomous driving simulation pays more attention to data mining capabilities.
- Data composition
Bao Shiqiang, head of the car simulation business at 51 World, notes that “L2 has a relatively clear definition of functionality, so simulations can mainly use synthetic data supplemented by real road data. However, in the L4 stage, importance is placed on real road data, with algorithm-generated data as a supplement.”6. Perception
Higher level autonomous driving vehicles require more cameras with higher resolution, which pose higher requirements for the image rendering ability, data synchronization ability, and stability of the simulation engine of the simulation system.
- High-Precision Map
Li Yue, CTO of Zhixing Zhongwei, said, “Low-level autonomous driving does not require high-precision maps, but high-level autonomous driving relies heavily on high-precision maps at the current stage. This is also one of the reasons for building a digital twin when constructing scenarios, to compare with the real world.”
- Decision Making
Li Yue, CTO of Zhixing Zhongwei, said, “The L2 scheme pays more attention to the testing of decision-making strategy logic and execution mechanisms, but does not focus on planning algorithms. However, in the L4 scheme, more consideration is given to path planning algorithms such as how to avoid obstacles and how to detour.”
- Whether a Driver Model Is Needed
For low-level autonomous driving, the system will not control the vehicle’s behavior completely, but only plays an auxiliary role. Therefore, simulation companies have to design a lot of driver model in the scene design. For high-level autonomous driving, vehicle control is achieved through autonomous driving. Therefore, there is no need to design driver models in the simulation scene design.
- Whether to Set Test Processes in Advance
Regarding this logic, the public account “Slow Car and Road” gave a more detailed explanation in an article:
The complexity and range of working conditions faced by low-level autonomous driving are relatively small. Or because the driving behavior is mainly responsible for by human drivers, the autonomous driving system only needs to deal with a limited number of determined working conditions. Higher level autonomous driving, on the other hand, has more complex working conditions and a wider range, even unpredictable.
Based on these differences, the use-case-based testing method is more suitable for low-level autonomous driving testing, that is, setting the test inputs and testing processes in advance and evaluating whether the tested algorithm achieves the expected function. For example, for ACC testing, the initial vehicle speed of the tested vehicle and the preceding vehicle, as well as the moment and deceleration of the preceding vehicle’s deceleration, are preset to check whether the tested vehicle can follow the preceding vehicle to stop.
The scenario-based testing method, on the other hand, sets testing inputs but not testing processes in advance, only sets the behavior of traffic vehicles, giving the tested algorithm more freedom, and evaluating whether the tested algorithm achieves the expected goal by checking. For example, for straight road driving tests, the initial vehicle speed of the tested vehicle and the preceding vehicle, as well as the moment and deceleration of the preceding vehicle’s deceleration are preset, but the tested vehicle is not limited to avoiding collision with the preceding vehicle through deceleration or overtaking by changing lanes.### Industry Ecology
One reason why different levels of autonomous driving require different testing methods is that lower levels of autonomous driving can generally be decomposed into simple and independent functions, which can be tested as individual units, while higher levels of autonomous driving are difficult to decompose into simple and independent functions and require the entire autonomous driving system or a relatively large part of it to be tested.
Question 5: How to understand “how many kilometers per day” in simulation?
Similar to real-road testing, some simulation companies also emphasize “driving distance”, such as “hundreds of thousands of kilometers” per day. What is the real meaning behind this number? How is it different from the driving distance on real roads?
Virtual distance refers to the total distance traveled by parallel simulation nodes in a massive simulation platform in a unit of time. The number of simulation miles per unit time depends on the number of nodes that the entire platform supports to run in parallel and the super-real-time index under different simulation scene complexity.
Simply put, a simulation node is a car, and it is the number of “test cars” that the simulation platform can support to run in parallel at the same time.
According to An Hongwei, CEO of Zhixing Zhongwei: Simply put, if a simulation platform has the computing power of 100 GPU servers, each of which deploys eight simulation instances, then this simulation platform has the ability to run 800 simulations in parallel at the same time. The simulation mileage depends on the mileage run by each instance every day.
The number of instances that can be run on one GPU server depends on the performance of the GPU and whether the simulation solver can simulate in parallel on one server.
An Hongwei said: “Our cloud simulation platform has implemented a variety of deployment methods, which can flexibly meet the various cloud resource situations of customers and achieve large-scale, elastic node deployment. At present, our cloud simulation platform in Xiangcheng, Suzhou has deployed more than 400 nodes.”
Combined with the mileage run by each instance every day, the total simulation mileage per day on the simulation platform can be roughly calculated. If an instance (virtual car) runs an average of 120 kilometers per hour and runs 24 hours a day, then it is nearly 3,000 kilometers per day. If there are 33 instances, then there are almost 100,000 kilometers per day on that server.
But according to An Hongwei’s statement, the industry’s usual claim about simulating “millions of kilometers per day” is not very rigorous. “It needs to be supported by a reasonable simulation testing plan and a large number of scenarios, and continuous expansion in both coverage and effectiveness of the scenarios. Only through running effective scenarios can we obtain fundamental results.”
Question Six: Super Real-time Simulation
During the interview, the author repeatedly asked a question: Do the cars running on the simulation platform and the ones in the real world exist in the same time dimension? In other words, is one hour on the simulation platform equivalent to one hour in the real world? Will the situation of “one year on earth and ten years in heaven” occur?
The answer is: it can be equivalent (real-time simulation) or not equivalent (super real-time simulation). Super real-time simulation can be divided into “time acceleration” and “time deceleration”-time acceleration means that the time on the simulation platform is faster than that in the real world, and time deceleration means that the time on the simulation platform is slower than the real world.
“Why is the simulation slower than the real world for some tests?” An Hongwei explained, “For example, some high-precision image rendering tests may require the rendering of a single frame of the image, which cannot be completed in real-time to achieve the required accuracy. Such simulations that are slower than real-time are not real-time closed-loop testing, but offline testing.”
Specifically, in real-time simulation, the generated image is directly sent to the algorithm for recognition, which may be completed in 100 milliseconds. However, in offline simulation, the image is saved and sent to the algorithm for processing under offline conditions.
According to An Hongwei’s explanation, two prerequisites must be met to perform super real-time simulation on the simulation platform: sufficient server computing resources and the algorithm to receive virtual time.
“How to understand that the algorithm can accept virtual time?” An Hongwei explained that some algorithms may need to read hardware timing, such as clock or network timing, when running on a hardware platform. However, it may not be able to read virtual time provided by the simulation system.
A simulation expert from Tier 1 said that precise time alignment and synchronization can be achieved in the engineering framework of the simulation system PoseidonOS, and the algorithm can be deployed on the cluster server. Then, the time of the simulation space can be decoupled from the real physical time, and can be “accelerated” arbitrarily.So, when it comes to time acceleration, whether it can be accelerated 2 times or 3 times depends on what?
According to An Hongwei, it depends on the server’s computing resources, the complexity of the test scenarios, the complexity of the algorithm, and the efficiency of the algorithm. Theoretically, under the same scenario complexity and the same algorithm, the more powerful the server’s computing resources, the more acceleration can be achieved.
What is the upper limit of the time acceleration factor? We need to answer this question in combination with the principle of time acceleration.
According to the simulation manager of an autonomous driving company, due to uneven algorithm complexity and other reasons, the calculation speed of each module such as the training module and the vehicle control module is different, and the most common method for super real-time is to do unified scheduling for all participating computing modules. The so-called acceleration is to “cancel waiting time” for modules with fast calculation speed – regardless of whether your other module has finished calculating, I will synchronize when the time comes.
If the difference in calculation cycles between the modules is too small, the canceled waiting time is very small, so the acceleration factor will be very low. On the other hand, if the difference in calculation cycles between the modules is particularly large, such as one module requiring 1 second and another module requiring 100 seconds, it is impossible to “cancel waiting”.
Therefore, the time acceleration factor is often limited – reaching 2-3 times is considered high.
Even many experts say that it is difficult to achieve time acceleration in practice.
Yang Zijiang, the founder of DeepTrack, believes that if the algorithm of the autonomous driving system has been compiled and deployed to the domain controller or industrial computer (this is the case in the HIL stage), it can only run in real-time in the simulation system-at this time, super-real-time simulation is not feasible.
An Hongwei also said: “Hardware-in-loop (HIL) itself must be real-time simulation, there is no concept of ‘super-real-time’ or the approach of ‘parallel simulation’ or ‘time acceleration’ is not applicable.”
Bao Shiqiang said: “The premise of time acceleration is precise control of time and time synchronization. Perception is difficult to accelerate, because the frequencies of different sensors are different. Cameras may be 30 Hz and LiDAR may be 10 Hz, and so on. How do you ensure that the signals from different sensors can be strongly synchronized?”
In addition, a simulation expert who has worked in Silicon Valley for many years believes that no company can really achieve super-real-time simulation now. “It’s good enough to achieve real-time.” In this expert’s view, large-scale parallel simulation is a more feasible solution to improve simulation efficiency.And An Hongwei believes that the time acceleration ability depends on the ultra-real-time level, the total number of instances, and the quality of the scene for each instance. “In fact, for cloud computing simulation, the ultra-real-time level on a single instance is not very important. The core is still to focus on the quality of the simulation on that instance.”
Even simulation experts at QZ-Zoo believe that the term “acceleration factor” is not really valid. This is because the relationship between time in simulation and time in the real world is not a simple multiple relationship, and they may not be related at all. In practice, more technological means are used to reduce the occupancy of computing resources and improve the efficiency of timing scheduling to improve operating time.
In real-world road tests, the vehicle is continuously moving, and you cannot say that this is a corner case. If there is a section that is not a corner case, I will not run it, but will run a long section and then filter out the corner cases in it. On the simulation platform, engineers usually only capture the snippets related to corner cases (i.e., “effective scenes”). After handling this, the clock will jump to the next time period without wasting time on ineffective scenes.
Therefore, when doing simulations, how to efficiently screen effective scenes is more important than the time acceleration factor.
At this point, we can see that although time acceleration seems impressive, relying on it to increase the virtual driving distance on the simulation platform is not the main factor. The key is to rely on “multiple instance concurrency”, that is, to do cloud computing simulations and increase the number of servers and simulation instances.
Question 7: Large-scale concurrency testing
Is it possible to support high concurrency in the cloud, and what is the difficulty level? Can we rely on stacking servers alone?
It sounds like it should work, but the problem is that “each increase in the scale of servers brings new problems”—
(1) The cost of servers is high. Each server costs tens of thousands of dollars. If there are one hundred servers, the cost will be several million dollars. The ideal solution is to go to the public cloud, but domestic hosting companies need some time to accept public cloud.
(2) In the case of large-scale concurrency, the sensor’s raw data is extremely large, the storage cost of this data is quite high, and it is difficult to transmit it—data synchronization between different servers will cause delays, which will affect the efficiency of intelligent driving.(3) Each run is not a continuous traffic flow scene, but a very short segment, maybe only 30 seconds, but usually there are thousands of parallel runs. If there are 1,000 algorithms running on 1,000 scenes, it poses a very severe challenge to the architectural design of the simulation platform. (CEO of a simulation company)
However, in response to the above last point, An Hongwei’s statement is: this is the basic requirement of cloud computing simulation, and it is not a challenge for us. The cloud simulation platform in Xiangcheng District, Suzhou solved this problem as early as 2019. In addition, the scenario running on the cloud simulation platform may also have continuous complex/combination scenarios of several kilometers, such as in the Robo-X simulation evaluation system in Xiangcheng, which includes such (group) scenarios. Based on this type of scenario, “takeover” tests can be conducted through virtual simulation.
Question Eight: What is the most critical indicator for measuring a company’s simulation ability?
At present, there are significant differences between different companies in terms of simulation, from toolchain to the used scenario data, and from methodology to the source of data. Everyone talks about “simulation”, but in fact, they may not be referring to the same concept. Then, what are the most critical indicators for measuring a company’s simulation ability? After this round of interviews, we obtained the following answers:
- Reproducibility
That is, whether the problems found in real road tests can be reproduced in the simulation environment. (Qingzhou Zhiahang, Haomo Zhixing)
There will be a more detailed interpretation of this issue in the latter part of this article.
- Scenario definition ability
That is, whether the simulation scenarios defined by the company can genuinely help improve the actual pass-through capability of autonomous driving.
- Scenario data acquisition ability
The ability to acquire and produce scenario data, data universality and reuse.
- The quality and quantity of scenario data
That is, how high is the similarity between simulation scenarios and real scenarios, and the accuracy, confidence, and freshness of scenario data, as well as the number of effective simulation scenarios that can support mass simulation instances.
- Simulation efficiency
That is, how to automatically and efficiently mine data to generate an environment model needed for simulation to quickly discover real problems.
- Technology architecture
That is, whether there is a complete technology closed-loop system suitable for the tested object’s requirements. (IAE Zhixing Zhongwei, Li Yue)7. Capability of Large-scale Concurrent Testing
A company can evaluate the construction of an evaluation system for model accuracy and system stability only in large-scale testing where the number of instances and scenarios are sufficient. This tests a company’s ability in data management, data mining, resource scheduling, etc. (Qingzhou Intelligence)
- Accuracy of Simulation
The precision required for rule-based simulation and perception-based simulation is different. The former may require seeing what the vehicle dynamic model is, what abstract levels there are, and how the granularity of the disturbance behavior in traffic flow, while the latter may require seeing the noise added by different sensors based on different imaging principles.
Usually, users hope that the technical architecture can be universal due to cost considerations. However, overly general solutions may sacrifice precision – the precision, efficiency, and versatility of the model are a triangular relationship.
Regarding the authenticity of simulation data, we need to add another question. MANA introduced real traffic flow scenes into the simulation system. MANA claims to have recorded the real-time traffic flow at intersections every moment through cooperation with Alibaba and Deqing government. Through log2world, we can import it into the simulation engine and use it for intersection scene debugging and verification after adding the driver model. So, how can the accuracy of this data be guaranteed?
Regarding this, MANA’s simulation experts said: “Currently, this data is mainly used for the research and development testing of cognitive modules. Therefore, what we need is as realistic as possible dynamic traffic behavior, and the data itself is discretized for the continuous world. As long as the acquisition frequency meets the calculation requirements of the cognitive algorithm, we do not need to compare this data with the true value (there is no way to obtain the absolute true value). In simple terms, what we pursue is the rationality and diversity of actions, not accuracy.”
- Consistency between Simulation and Real-world Testing
A simulation engineer from a commercial vehicle unmanned driving company said that they often find that the results of SIL testing are opposite to those of real-world road tests – scenarios that are not problematic in real-world road tests present problems in SIL testing, and conversely, scenarios that have problems in real-world road tests do not have problems in SIL testing.
The person in charge of automatic driving simulation test in a main engine plant said that they found that the performance of a vehicle in a simulation scene varies more or less from that on a real road during HIL testing. The reason for this discrepancy may be that (1) virtual sensors, EPS, etc. are not identical to those on real vehicles; (2) virtual scenes are not entirely consistent with real scenarios; (3) the calibration of vehicle dynamics is inaccurate.10. The Position of Simulation in Company’s R&D System
The penetration rate of simulation in actual business, that is, the proportion of simulation data in the entire business usage data in the R&D process, and whether simulation is used as a basic tool for research and testing. (Mr. Mao, a simulation expert)
- Whether to Form a Business Closed Loop
For simulation companies, it is more important to establish a business closed loop than the technical advantages, according to a simulation expert from an autonomous driving company.
Bao Shiqiang, the person in charge of 51 World’s onboard simulation, said that customers’ main concerns when choosing a simulation supplier are: A) Are the simulation modules comprehensive enough? Do they have everything they need? B) What kind of toolchain can you provide for them? C) The openness of the simulation platform.
Regarding openness, Bao Shiqiang said: “The overall trend is that users actually do not want to directly buy software to solve a specific problem, but hope to build their own platform. Therefore, they hope that the simulation supplier’s technology modules can empower them to build their own simulation platform. Therefore, simulation suppliers need to consider how to design API interfaces, how to integrate them with customers’ existing modules, and even open up some code to customers.”
Attached: How to Improve the Reproducibility of Scenarios
“The question is whether a problem found on the road can be reproduced in the simulation environment”, which is regarded as one of the most critical indicators of a company’s simulation ability by companies such as QZ Intelligent Navigation. So, what factors will affect the reproducibility of scenarios?
With this question in mind, the author repeatedly asked multiple experts and obtained the following answers:
-
The vehicle model, sensor model, road model, and weather model may differ from the real situation.
-
The evaluation criteria of the cloud and the vehicle may not be consistent.
-
The communication timing and scheduling timing in the simulation system are inconsistent with those on the actual car. For example, if a message is received, if you accidentally receive a frame early or late, the difference will be significant due to the butterfly effect.
-
The vehicle control parameters in the simulation system are inconsistent with those in the actual vehicle. In actual vehicle testing, the throttle, brake, steering wheel, and tires are all present in physical form, but there are no such physical parts in the simulation system. Therefore, only simulation methods can be used. If the problem of vehicle dynamics is not handled properly, the degree of simulation will be discounted.
-
Scenario data in the simulation system is incomplete. When doing simulations, we may only capture a certain portion of the scenario, and data from a few seconds before and after the traffic light is missing, for example.6. The logic language used to describe the environment may not be comprehensive enough in terms of level and coverage.
-
The simulation software itself does not adapt well to various scenarios, and switching between languages is not smooth, making it difficult to support large-scale, multi-node operations.
-
There are many variables in the data from real roads. In order to quickly identify problems during simulation, engineers need to “assume” that certain parameters remain unchanged in order to reduce interference with key variables.
-
The calculation order between modules such as perception, prediction, and positioning for autonomous driving may be different on the cloud and the vehicle. Some information may not be recorded accurately on the vehicle. Even a slight difference in one frame may cause a problem in the final result.
-
If the problem is at the perception level, scene reproduction requires good reverse generation of three-dimensional scenes, and data augmentation through generalization and perspective transformation, with each step being somewhat difficult. If the problem is at the control level, accurate scene reproduction requires identification of scene interaction behavior and key parameters to generate and trigger the scene. (Yang Zijiang, Founder of DeepRoute.ai)
Triggering a scene means testing whether the content intended to be tested in this scene is realized. For example, to test a scenario where a pedestrian suddenly crosses the road in front of the main car, the scenario is not triggered until the main car has passed before the pedestrian crosses. The walking speed of the pedestrian, the time point of the turn back, and the speed of the main car are all critical factors. This is only for one pedestrian and one car; it becomes much more complex with multiple traffic participants, where the relationships are coupled and even a slight deviation in one parameter can greatly affect the simulation result.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.