
Author: I The Office
The 7th AI DAY of Hozon Auto in 5th Jan 2023
After the accumulation of the seven AI DAYs and more than three years of development, Hozon Auto has become an indispensable part of the intelligent driving field.
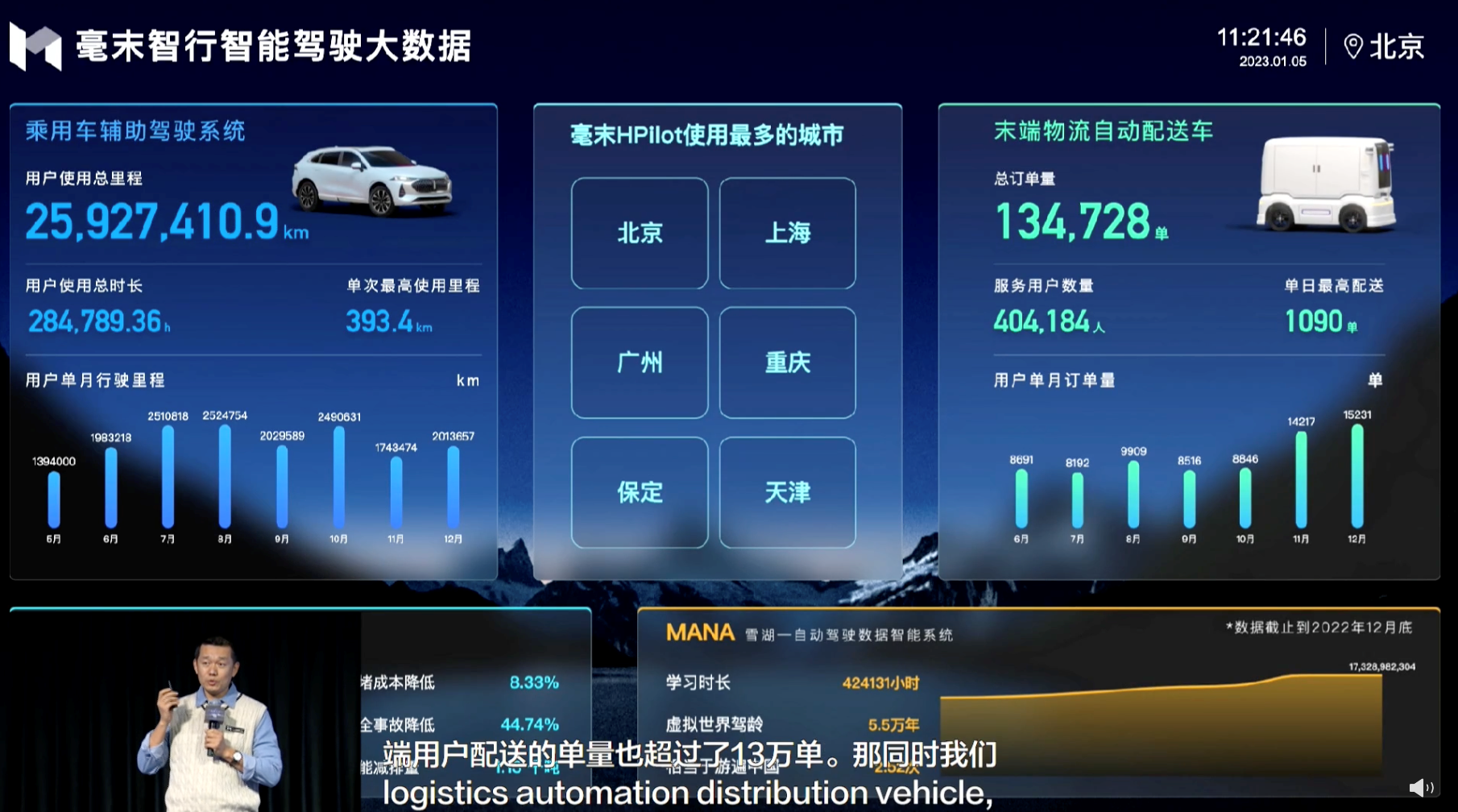
Until the end of 2022, nearly 20 models equipped with Hozon HPilot have been launched, and the user-assisted driving mileage has exceeded 25 million kilometers, providing fertile soil for data-driven advanced intelligent driving.
In addition, its self-developed AEB (Autonomous Emergency Braking) has been implemented both at home and abroad. It has delivered over 1000 smart logistics vehicles, the MANA system has learned for more than 420,000 hours, and the urban NOH (Navigation and Obstacle Handling) has opened lane testing in multiple cities. These achievements are definitely not easy for a company that has just been established for three years.
At the end of this AI DAY event, Hozon Auto announced its plan for the next step. In 2023, Hozon will deeply improve the performance of urban NOH and launch the NOH hundred cities landing plan in 2024. Undoubtedly, this is a sufficiently aggressive engineering landing plan for advanced intelligent driving.
Therefore, let us explore from the content of this AI DAY event, what are the reasons behind the rapid development of Hozon Auto?
Self-Developed AEB
Before talking about the urban NOH, let’s have an appetizer. Hozon’s self-developed AEB algorithm has been implemented both at home and abroad. Currently, four car models, which are Wei Pai Mocha, Latte, Euler Good Cat, and Tank 300, have obtained the five-star safety certification of A-NCAP and E-NCAP in Australia and Europe, respectively. AEB, as an active safety function, is undoubtedly an important basic function to protect the driver and road participants, comparing to advanced intelligent driving.Using the Tank 300, which just received a 5-star safety rating from A-NCAP (Australian New Car Assessment Program), as an example, the results show that in the four categories of adult passenger protection, child passenger protection, vulnerable road user protection and safety assistance, the Tank 300 scored a rate of 88%, 89%, 81%, and 85% respectively.

To achieve such results with the self-developed AEB, Hover Automotive conducted a large number of real-life proactive safety scenario tests, such as static frontal collision tests at speeds of 50-60 km/h, pedestrian crossing collision tests, and child dummy head tests, as well as numerous simulated tests to ensure safety.
Choosing a self-developed AEB is a typical “easier said than done” strategy. As a highly safety-correlated AEB, it should be triggered in real-time before every potential collision scenario, to prevent unexpected events. However, at the same time, it is often difficult to control the boundaries between strong triggering and false triggering. One small mistake could result in overcorrection, leading to negative effects. Hover Automotive needed to minimize the false trigger rate to ensure a good balance between safety and false reporting.

Imagine the impact of a 1% false triggering rate, even in a large number of real-life driving scenarios. Therefore, for AEB, the false-triggering rate needs to be reduced to once every 100,000-150,000 kilometers to be considered qualified. That is why most car companies choose supplier black box solutions, and there are very few companies that have self-developed AEB.
However, supplier black box solutions are almost impossible to iterate. On the other hand, as a white box solution, the self-developed AEB of Hover Automotive not only has the ability to continuously iterate and upgrade, but even can enhance detection effects by adding laser radar fusion.
Even though getting a 60 is considered a pass, who wouldn’t want to score a 90?
The Birth of Snow Lake Oasis
It has become an industry consensus that achieving advanced intelligent driving requires a large amount of data driving. Hover Automotive had previously proposed the idea of data-driven imprinting, which involves continuously producing data from the vehicle end, processing and mining the data, and iterating algorithms to better design algorithms for the vehicle. As a commercial project, cost and iteration speed should not be neglected.How to achieve low cost and quick iteration? In late 2021, Horizon Robotics released an automated driving data intelligence system, MANA, also known as “Snow Lake” in Chinese.

MANA uses the LUCAS data generalization system as the core to perform data mining and self-iteration. The on-vehicle core algorithm prototype of MANA is implemented via the TARS data prototype system, including perception, cognition, and simulation algorithms. The data services such as storage and feedback are performed using the BASE underlying system, while VENUS is responsible for data statistics, analysis, and frontend display. MANA consists of the four major systems: LUCAS, TARS, BASE, and VENUS.
The data of MANA is rapidly accumulating. At the 5th Horizon Robotics AI Day in April 2022, MANA only had a learning time of 197,000 hours. By the 7th Horizon Robotics AI Day, this number had surpassed 420,000 hours, which is equivalent to a virtual world driving time of 55,000 years. As more vehicles are delivered, this data will continue to climb.
The production of a large amount of data has produced the next issue on how to efficiently utilize these data.
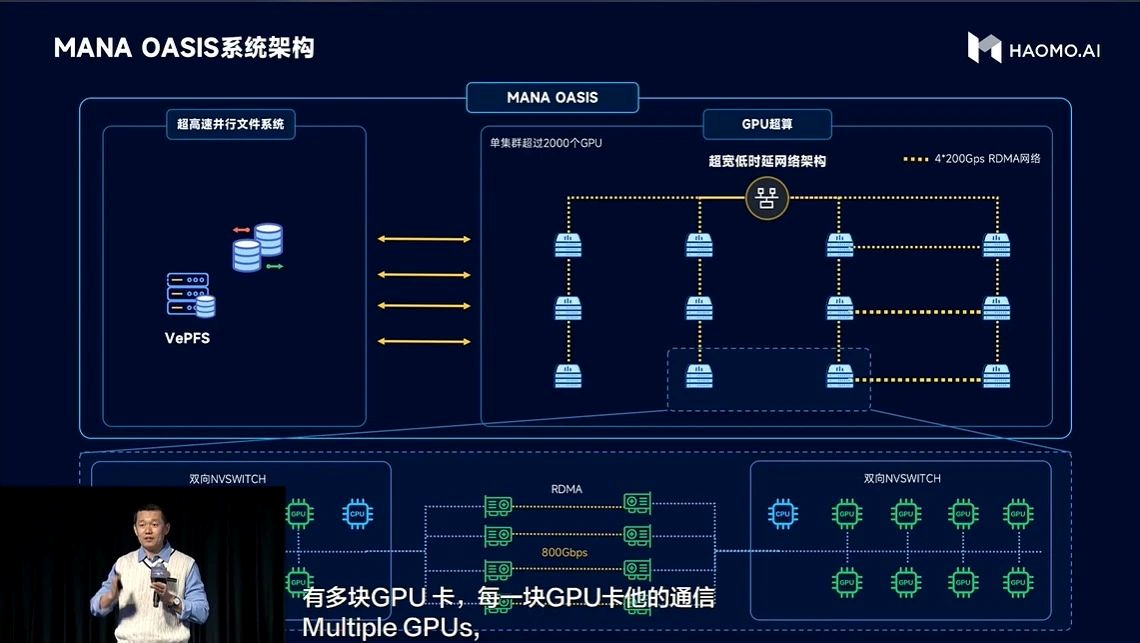
Horizon Robotics officially released its smart computing center, MANA OASIS, also known as “Snow Lake Oasis” in Chinese.

MANA OASIS has also become the largest smart computing center in China’s autonomous driving industry. The three important indicator parameters of MANA OASIS, jointly built by Horizon Robotics and ByteDance’s Volcano Engine, are:- High performance computing: 67 billion billion calculations per second of floating point operations;
- High performance storage: 2T/second storage bandwidth;
- High performance network: 800G/second communication bandwidth.
If you don’t have a concept, XPeng announced in August this year the “Fu Yao” intelligent computing center, with a computing power scale of 60 billion billion calculations per second of floating-point operations.

Of course, the simple stacking of computing power is meaningless. The key is how to keep the GPU running at full saturation and fully realize the value of the intelligent computing center. In two years, HMMT has established the whole set of data engines for large-scale training, which can screen hundreds of PB of data at a speed 10 times faster, and reduce the latency of reading and writing billions of small files in the HMMT file system to below 500 microseconds.
In terms of computing power optimization, HMMT has cooperated with the volcano engine to optimize MANA OASIS through deploying Lego high-performance operator library, ByteCCL communication optimization capability, and large-scale training framework.
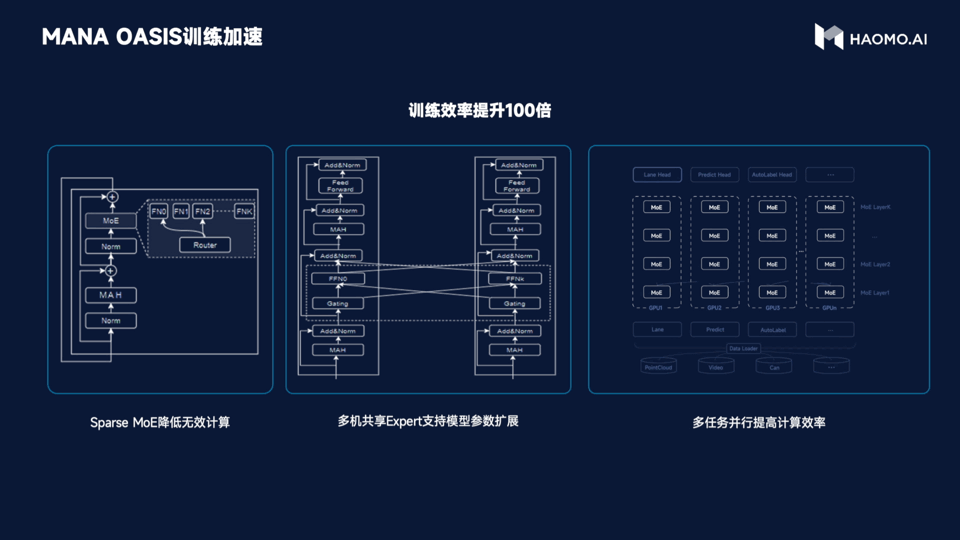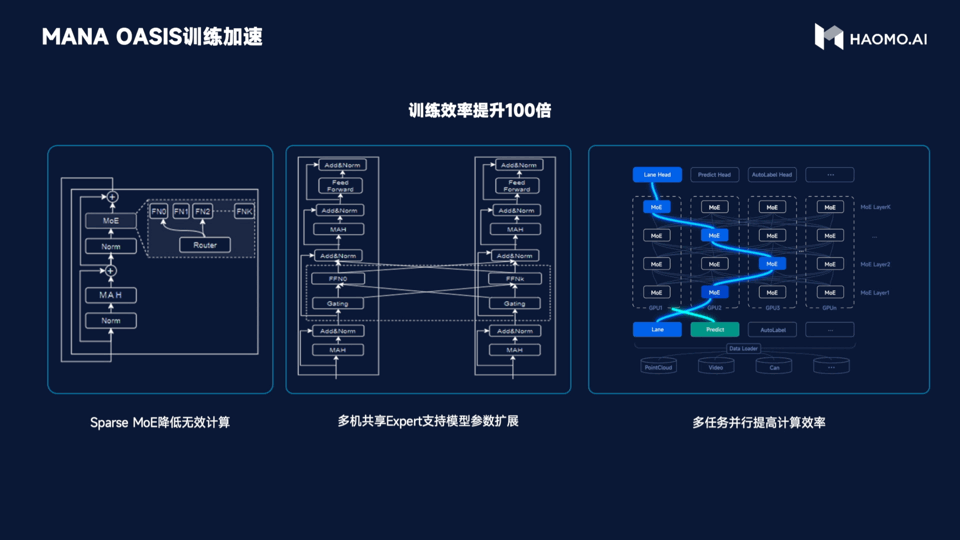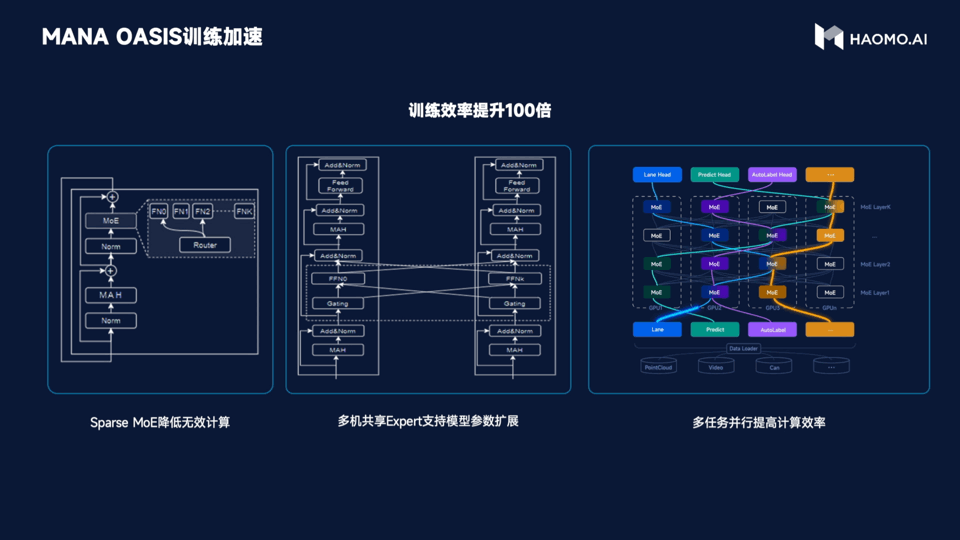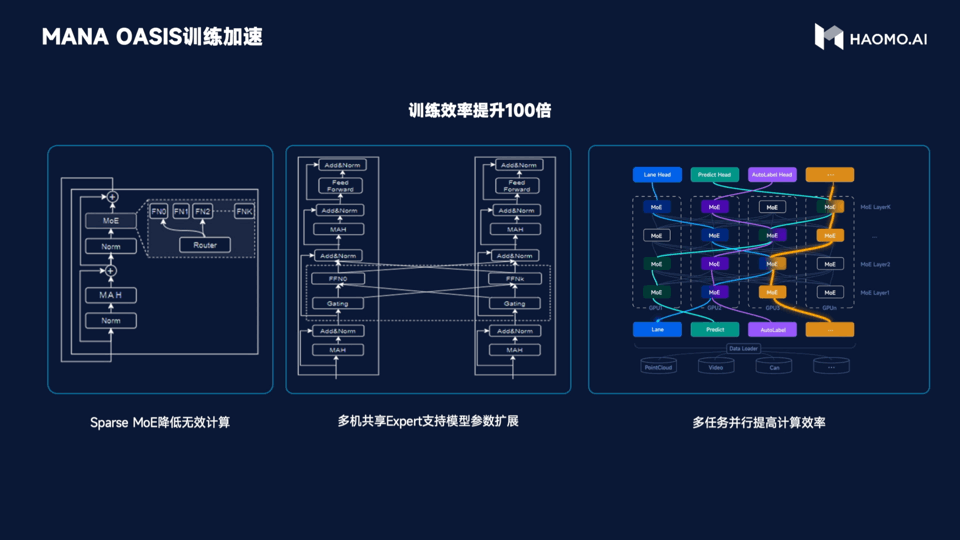
As for training efficiency, based on Sparse MoE to reduce useless calculation, it can achieve the effect that one machine with 8 cards can train billions of parameter models. Through the method of cross-machine sharing expert, the training cost of millions of Clips can be compressed to the week level of hundreds of cards. Meanwhile, HMMT’s multi-task parallel training system can simultaneously process multi-modal information such as images, point clouds, and structured text, ensuring the sparsity of the model while improving computational efficiency.
In simple terms, MANA OASIS has improved training efficiency by 100 times.
 In the last Haomo AI DAY, the most talked about topic by the management team was “data”, and Haomo Intelligent CEO Gu Weihao defined the era of autonomous driving 3.0 as a data-driven era. The urgent problem to be solved is how to effectively utilize the continuously growing massive data and abstract high-level intelligent driving algorithms from the data.
In the last Haomo AI DAY, the most talked about topic by the management team was “data”, and Haomo Intelligent CEO Gu Weihao defined the era of autonomous driving 3.0 as a data-driven era. The urgent problem to be solved is how to effectively utilize the continuously growing massive data and abstract high-level intelligent driving algorithms from the data.
MANA OASIS emerged, and with the help of MANA OASIS, the five major models of Haomo MANA were upgraded and will lay the foundation for Haomo’s development route in urban NOH.
Five Major Models
The five major models are video self-supervised big model, 3D reconstruction big model, multimodal mutual supervision big model, dynamic environment big model, and human-driver self-supervised cognitive big model. Simply understanding these five major models from the perspective of annotation, simulation, multi-sensor fusion, map, and driving strategy has become the basis of Haomo’s iteration direction in urban NOH.
We can analyze these five major models in detail. First is the video self-supervised big model, which Haomo adopts as a heavy sensory route. The dependence on this model is no less than people’s demand for water. The video self-supervised big model enables Haomo’s 4D Clip annotation to achieve 100% automation, and the cost of manual annotation is reduced by 98%.

Let’s explain what a 4D Clip is first?
The Clip consists of sensor data on a segment of road, and 4D means 3D space + time dimension. In the era of massive data stacking, it is unrealistic for algorithms to iterate quickly with manual annotation. Unlimited expansion of the annotation team is also a huge disaster in terms of cost.

Tesla also shared its method of automatic annotation at AI DAY. Simply put, a car can collect a Clip by driving along a road. After obtaining the Clip, the automatic annotation system completes various types of information annotation, including road information and reconstruction of road data, motion information of moving objects, etc., using the processing of local neural networks. This produces annotations that can be used to train models, and finally, professional annotators verify the annotations, remove noise, or add other annotations to make the data usable.The prerequisite for automatic annotation is the millimeter-level video self-supervised large model. Firstly, pretrain a large model and fine-tune it with a small amount of Clip data that has been manually annotated, train the detection and tracking model to enable the model to have the ability of automatic annotation. The original videos corresponding to the millions of single-frame data that have been annotated are extracted and organized into Clips, among which 10% are annotated frames and 90% are unannotated frames. Then, these Clips are input into the model to complete the automatic annotation of the 90% unannotated frames, and finally achieve the automatic transformation of single-frame annotation to Clip annotation. Millimeter also claimed that the generalization effect of the video self-supervised large model is extremely good, even for severely occluded riders, small targets in the distance, bad weather and lighting, the automatic annotation can be accurately achieved.
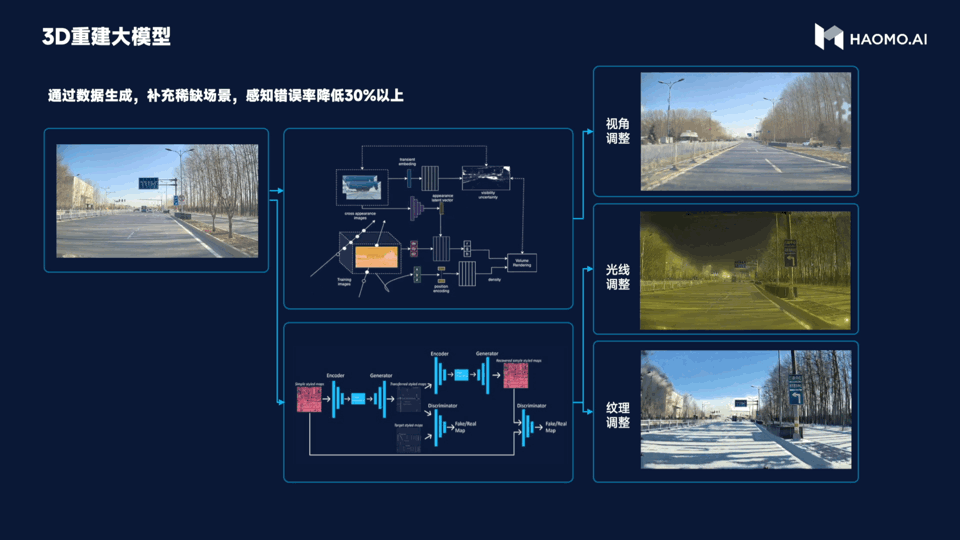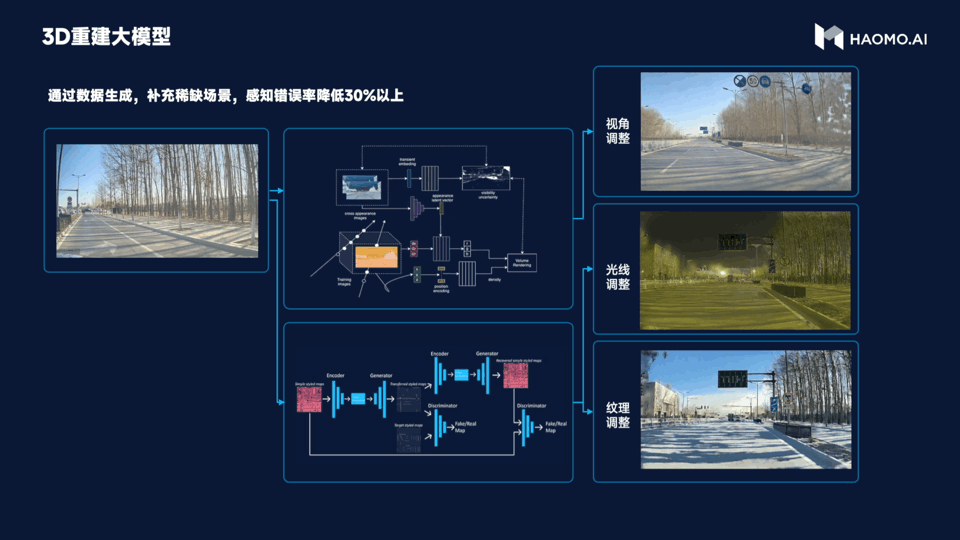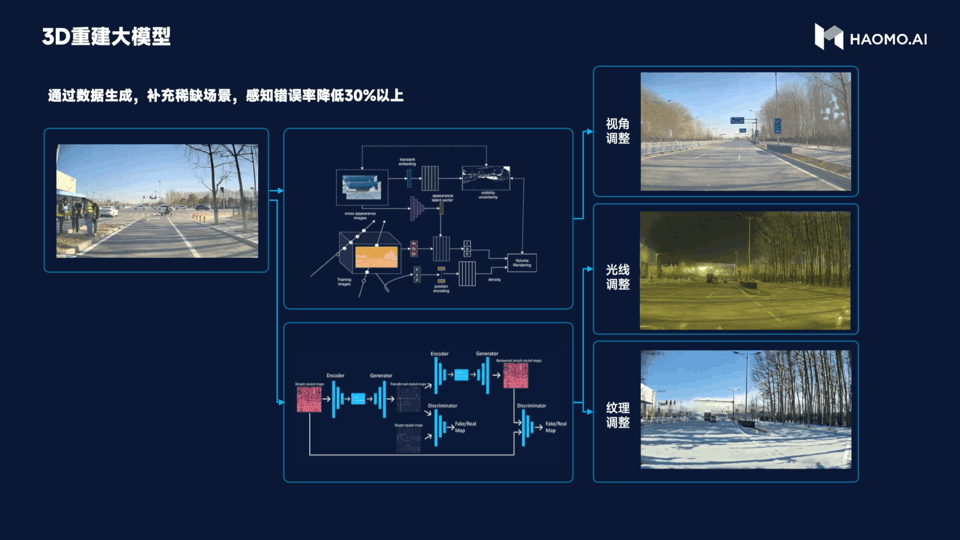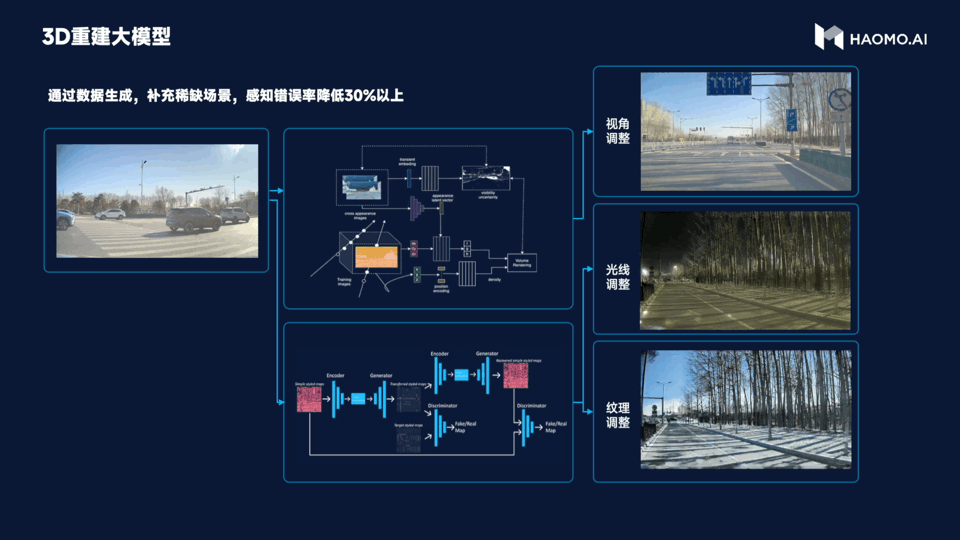
Secondly, the 3D reconstruction large model is used to simulate a large number of corner case scenarios. After all, corner cases are rare events in the real world. When facing corner cases, the intelligent driving may appear somewhat “stupid”. Therefore, the purpose of 3D reconstruction large model is to use the NeRF technology in the reconstruction and data generation in the automatic driving scenes. It can generate highly realistic data by changing the perspective, lighting and texture materials, etc., to achieve low-cost acquisition of normal cases and generate various high-cost corner cases.
Compared with the traditional manual modeling method, the data generated by 3D reconstruction large model has better effect and lower cost, and can reduce the error rate of perception by more than 30%. In the future, Millimeter will rely on MANA OASIS to reconstruct all the past scenes in 3D.
This means that Millimeter’s intelligent driving system can more efficiently deal with all kinds of extreme scenarios, greatly improving the efficiency of algorithm iteration.
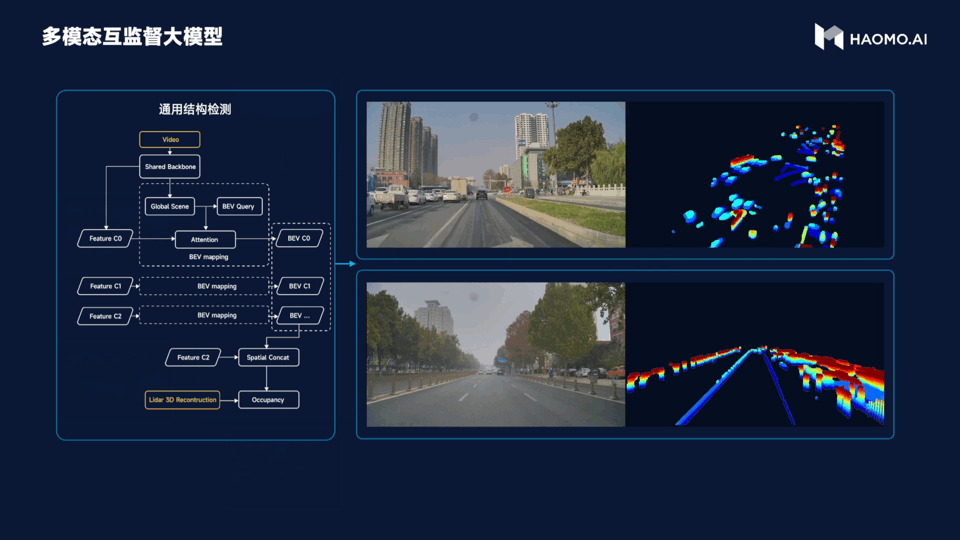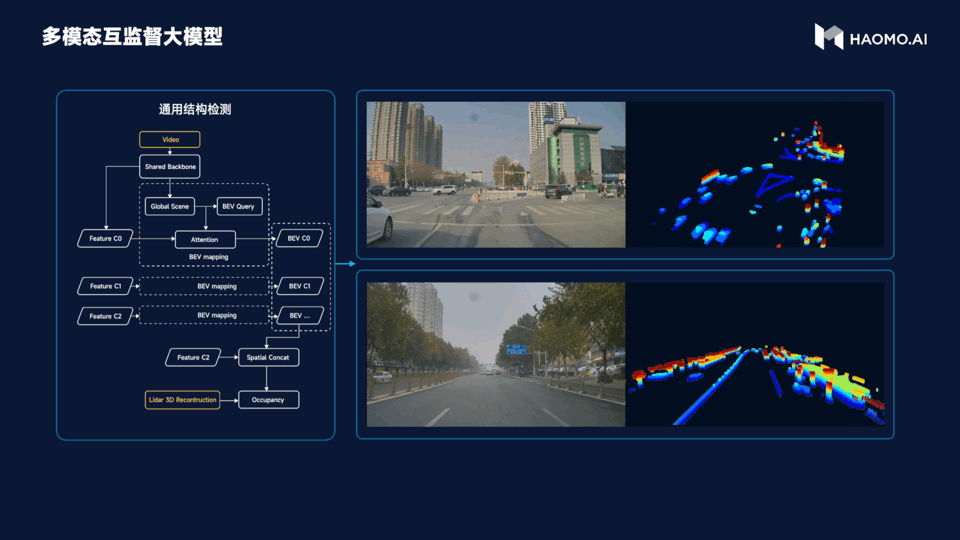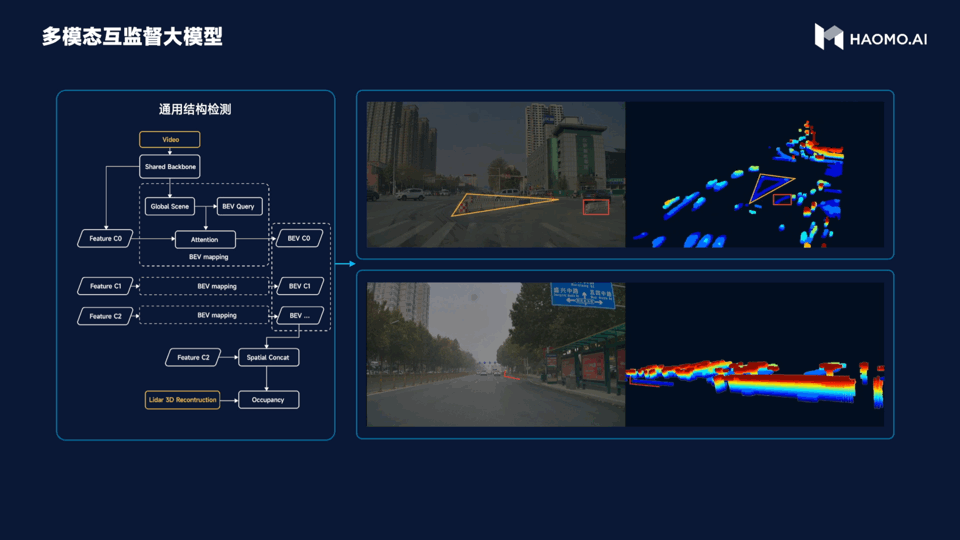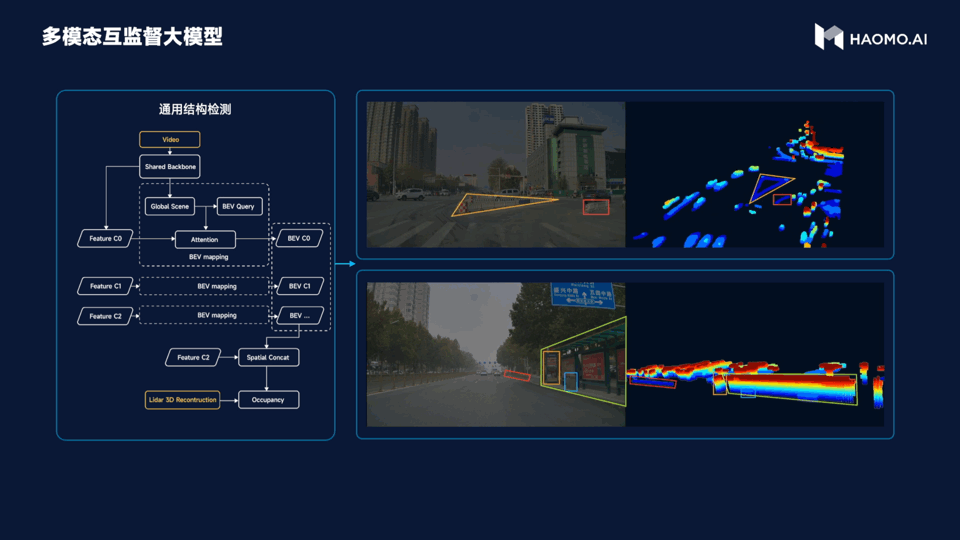
The third large model is multimodal unsupervised learning, and it is easy to judge its function from the name. This model introduces a LiDAR as a visual supervision signal and addresses the stable detection problem for various irregular obstacles in the city. For example, there may be a tricycle in the city. If there is only one tricycle, it can be easily recognized through a lot of training visually, but if the tricycle is full of garbage or is pulling a steel pipe, the visual recognition becomes difficult, as there is no learning about it. In this scenario, the characteristics of LiDAR are played out. It can recognize obstacles ahead, effectively avoiding them, and improving the success rate of intelligent driving in complex urban conditions.
The fourth point is the dynamic environment large model. Its purpose is to accurately predict the topological relationships of roads, allowing vehicles to drive on the correct roads. This is the difficulty encountered by the pixel-perfect map strategy. With the support of high-definition maps, vehicles can be regarded as having a perspective view, knowing whether there is a zebra crossing, traffic lights, a ramp or a turn ahead.
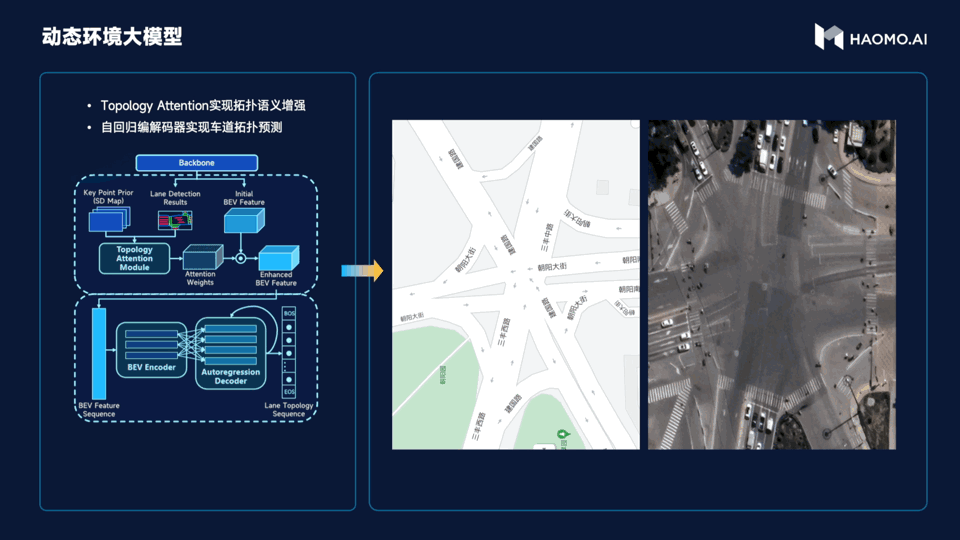
However, the disadvantages of high-definition maps cannot be ignored. To achieve large-scale urban driving, restricted by regulations, update speed, road maintenance, etc., high-definition maps cannot be updated in time, which also brings obstacles to urban intelligent driving.
So, if Momenta wants to achieve large-scale implementation in cities, it cannot rely heavily on high-definition maps. The challenge here is that the perception system needs to infer the road topology structure directly output by the high-definition map in real time. Momenta chooses to generate an enhanced version of the BEV feature map through the Topology Attention model based on the BEV feature map with the guidance of the standard definition map (which is the navigation map we commonly use), then decode the structured topology point sequence through the BEV decoder and the autoregressive encoder-decoder to achieve real-time inference of the road topology structure.“`
The entire implementation process is naturally more complicated than described. As of now, in the two cities of Baoding and Beijing, the Momenta intelligent driving system has achieved up to 95% accuracy in topology reasoning in 85% of intersections, even in complex or irregular intersections.
As shown in the figure, this intersection is composed of five intersecting roads. Perception and regulation in multi-intersection crossings are one of the most important challenges in urban intelligent driving scenarios. Overcoming similar scenes has laid the foundation for the large-scale landing of cities.
After solving the perception and mapping issues, how to solve complex driving decisions is the next challenge. Momenta introduces user takeover data and trains a reward model (RM) with RLHF (human feedback) approach to select better driving decisions.
My understanding is that in roundabout scenarios, if 8 out of 10 people choose a similar route, the system will also choose similar driving decisions. Through continuous human behavior feedback, the model’s performance is further deepened, ultimately resulting in an optimal solution. RLHF is also a recent popular approach used in chatGPT, a conversational neural network model.
Through this approach, Momenta’s intelligent driving system can increase its passage rate by more than 30% in difficult scenarios such as U-turns and roundabouts.
The MANA’s five new models comprehensively enhance Momenta’s underlying capabilities of perception and planning. Through massive data feeding, Momenta is constantly strengthening its NOH landing process in cities. At the same time, it can be seen that launching the five new models still prioritizes cost reduction and efficiency improvement in both aspects.
Final Thoughts
From this Session of Momenta AI DAY, it is not difficult to see Momenta’s determination for the high-order intelligent driving of cities. From the perspective of the entire industry, industry leaders have begun to conduct generic training and are no longer confined to structured roads with high-precision map coverage such as high-speed and overhead roads, but are advancing towards more extensive urban non-structured scenarios.
“`Progressive development strategy combined with precise sensing and light mapping has gradually revealed its advantages. Momenta has fully disclosed its technological direction and current situation in a more “transparent” way, and has given a more “reasonable” time point:
- In 2023, the handling of city NOH special working conditions will be improved, and long-distance parking without learning will be available;
- In 2024, urban NOH will be implemented on a larger scale;
- Starting in the second half of 2024, full-scenario NOH will be opened on a larger scale.
As a leading player in advanced intelligent driving, Momenta has taken the lead in launching the first salvo in 2023, bringing this urban war into a white-hot stage.
END
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.