
Author: Mu Mu
Currently, autonomous driving technology has moved out of the laboratory and into the mass production stage, becoming a fiercely competitive field for major automakers, parts suppliers, and high-tech companies.
The outbreak of this round of autonomous driving technology largely depends on two factors:
-
The breakthrough in consumer-level computing platforms with large computing power provides basic computing power for the field of artificial intelligence.
-
The breakthrough in deep learning in the field of computer vision, which is also the basis for autonomous driving visual perception.
Currently, the overall computing power of the calculation platform integrated with multiple chips based on Nvidia, Qualcomm, Mobileye, Horizon Robotics, and Huawei’s autonomous driving chips has reached over thousands of Tops, providing computing power guarantees for advanced autonomous driving.
However, the technology is deeply coupled and interacted between algorithms and computing power. Feng Yutao, the General Manager of Ambarella Semiconductor China, said:
“The required computing power for autonomous driving will not expand indefinitely. The computing power needs to grow with the capabilities of the algorithm and data. In terms of various algorithm technologies in the market, mainstream high-computing chips are already sufficient. The algorithm is the key point of competition next, unless the coupling between the algorithm and data and computing power reaches a bottleneck point, it makes no sense to create a larger computing platform.”
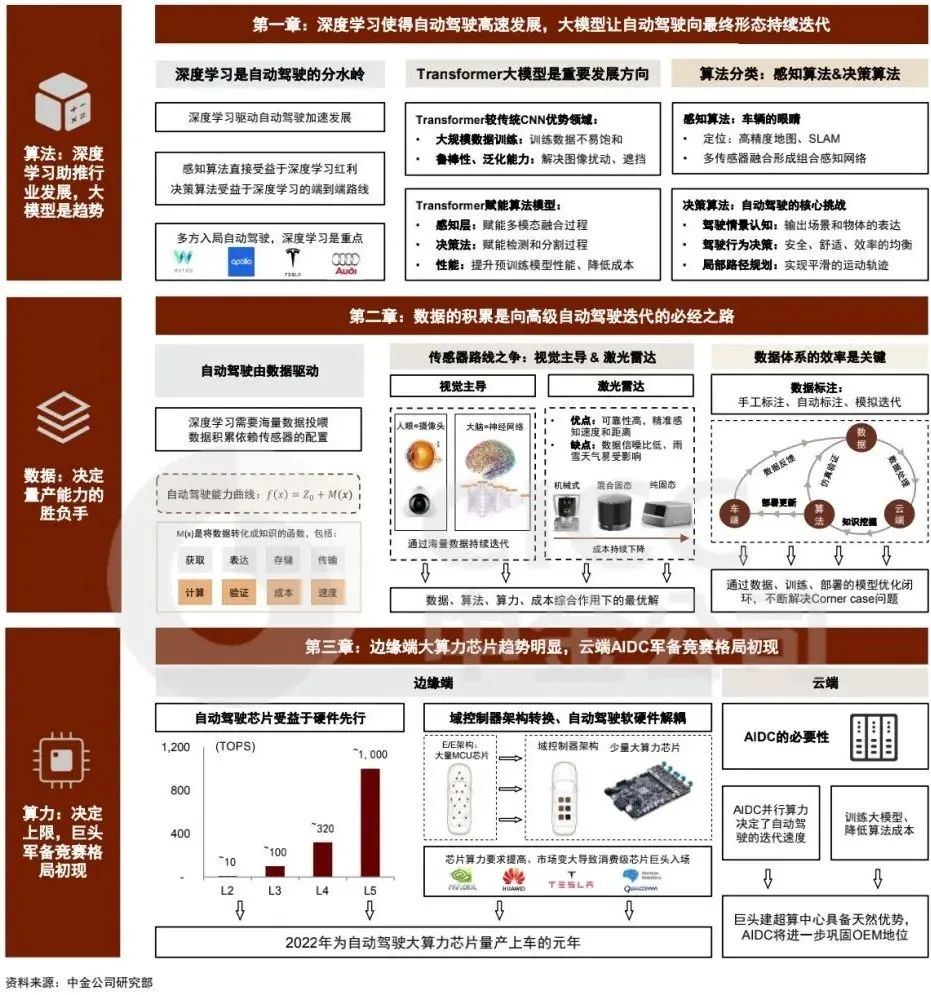
On January 27th, Zhongjin released a research report called “Artificial Intelligence Ten-Year Outlook (III): Comprehensive Analysis of the Autonomous Driving Industry from the Perspective of AI.” The report pointed out that “deep learning is the watershed and underlying driving force for the development of autonomous driving technology, and algorithm is the core ability that manufacturers should focus on in the future. At the same time, data determines the win or loss of autonomous driving mass production capability.”
In other words, the performance of computing power has reached a stage of stable development, and “algorithm capacity + data capacity” will become the key for competition among companies in the autonomous driving field.
Trends in technology for handling multi-layer neural networks
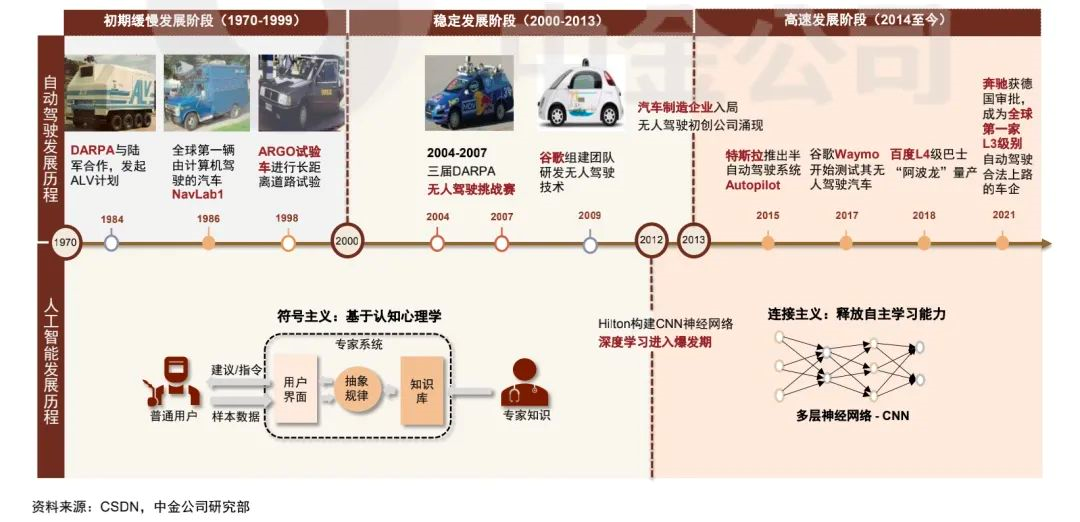
The breakthrough in visual perception technology has further promoted the progress of perception algorithms for other sensors (such as LiDAR and millimeter wave radar) and multi-sensor fusion algorithms. On the other hand, reinforcement learning algorithms in deep learning also play a very important role in decision systems.
For deep learning algorithms, high-quality and large-scale training data, in addition to the ability of the algorithm itself, is also a key factor for algorithm success. Therefore, how to efficiently collect and annotate data is a very realistic problem for every autonomous driving company.In terms of data collection, companies focused on mass production have inherent advantages. Tens of thousands or even millions of vehicles on the road can continuously provide rich road condition data. Together, they form a massive autonomous driving database.
In contrast, L4-level companies can only rely on a limited number of test vehicles to collect data. Currently, Waymo, which has the largest road test scale, only has a few hundred test vehicles, and the scale of data collection is naturally incomparable.
But does having massive amounts of data mean that the problem is solved?
Obviously, it is not that simple.
Although deep neural networks rely on big data, there is still a big difference in the ability of different network structures to learn massive amounts of data. The earliest multi-layer perceptron structure network had only a few layers, and the learning ability of the network could be saturated with very little data.
In recent years, the convolutional neural network (CNN) has been proposed, which has increased in depth from a dozen or so layers to hundreds or even thousands of layers. At this point, large-scale training data is needed to ensure the quality of network training.
But simply stacking layers is not feasible. A very crucial technology in the field of deep learning, ResNet (deep residual network), has appeared, which proposes adding extra connections so that information can be transmitted directly from shallow layers to deep layers, reducing the loss of information when transmitting between network layers. With this technology, convolutional neural networks can have deeper structures and better utilize large-scale data.
Although ResNet technology is available, the performance improvement of deep convolutional neural networks is still limited after the data volume reaches a certain level, indicating that there is still a bottleneck in the learning ability of neural networks.
Since about 2017, a new type of neural network structure has been attracting widespread attention from researchers, which is the famous Transformer network based on attention mechanism.
Transformer was first applied in the field of natural language processing (NLP) to process sequence text data.
The BERT algorithm proposed by the Google team to generate word vectors achieved a significant improvement in all 11 NLP tasks, and the most important part of the BERT algorithm is Transformer.
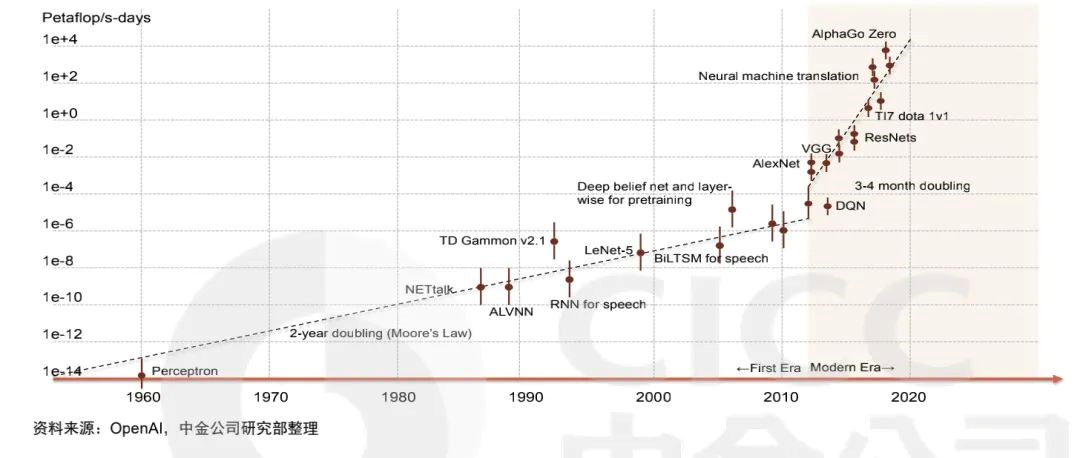
After achieving widespread application in the field of natural language processing, Transformer has also been successfully transplanted to many visual tasks, such as “image classification, object detection”, and has achieved good results. Transformer can obtain greater performance improvement with massive data, that is to say, the saturation interval of learning ability is larger.According to research, the performance of Transformer surpasses that of CNN when the training dataset contains one billion images, and the performance gap between the two becomes larger when the number of images increases to ten billion.
The chart above shows the image classification accuracy of ResNet (CNN) and ViT (Transformer) on different sized training sets. When the dataset size is ten million, the accuracy of the Transformer is far lower than that of CNN, but when the dataset size increases to one billion, the Transformer begins to outperform CNN.
In addition, CNN networks show a saturation trend when the dataset size exceeds one billion, while the accuracy of the Transformer continues to increase.
In simple terms, Transformer has a huge redundant advantage in processing massive amounts of data.
It is precisely because of this that companies in the automobile industry with data collection advantages naturally tend to choose Transformer as the main body of their perception algorithm.
In the summer of 2021, Dr. Andrej Karpathy, head of Tesla’s autonomous driving technology, publicly announced the algorithm used in the FSD autonomous driving system during AI Day, and the Transformer is one of the core modules. In China, Momenta also proposed using the Transformer neural network to effectively integrate massive data.
At the end of 2021, Momenta CEO Gu Weihao introduced the MANA (Xuehu) data intelligence system at the Momenta AI Day. In addition to visual data, the MANA system also includes Lidar data.
Based on the Transformer neural network model, the MANA system integrates the three dimensions of space, time, and sensors to improve the accuracy of the perception algorithm.
After understanding the trend of the development of autonomous driving technology, the next part of the article will briefly introduce the design motivation and working mechanism of the Transformer, and then explain in detail the technical plans of Tesla and Momenta.
Transformer Neural Network
Before discussing the Transformer, it is necessary to understand a concept: “machine translation, attention mechanism“.
Machine Translation
Machine translation can be crudely understood as “simulating human intelligent activity with modern computers, automatically translating between languages“.When it comes to translation, we can’t ignore the application of machine translation in the field of Natural Language Processing (NLP). In simple terms, it means “inputting a sentence and outputting another sentence,” which could be an expression in a different language, for example, “bicycle” translated as “自行车,” or it could be the same language’s keyword expression, like “骑行的两轮车.”
Engineers designed a set of mathematical functions to model the “translation” process, which is commonly understood as a “neural network.”
Prior to the advent of the Transformer, people commonly used the “Encoder-Decoder” structure based on the Recurrent Neural Network (RNN) to accomplish sequence translation.
Sequence translation “is the process of input a sequence and outputting another sequence.” For example, in Chinese-English translation, the input sequence is a sentence in Chinese, while the output sequence is the corresponding expression in English.
The RNN-based architecture has one obvious disadvantage, which is that RNN is a sequence model and requires information processing in a serialized manner, with attention weights depending on the entire sequence input to be determined, which means RNN needs to “see” the whole sequence from start to finish.
For example:
When facing the translation problem “A magazine is stuck in the gun,” should “Magazine” be translated as “杂志” or “弹匣”?
When the word “gun” appears, it becomes clear that “Magazine” should be translated as “弹匣.” In the machine translation model based on RNN, all words from Magazine to gun need to be processed sequentially, and when they are far apart, the information stored in RNN will be continuously diluted, making the translation results often unsatisfactory, and the efficiency very low.
“This architecture has a lot of time overhead in both training and inference, and it’s difficult to achieve parallel processing.” At this point, the engineer came up with a solution, which is to add an “Attention Mechanism” to the standard RNN model.
What is Attention Mechanism?
“The attention mechanism in deep learning originates from the human brain’s attention mechanism. When the human brain receives external information, such as visual or auditory information, it often does not process and understand all the information, but only focuses on the part that is significant or interesting. This is advantageous for filtering out unimportant information and improving information processing efficiency.”
The model with the attention mechanism can “see” all the input words at once and use the attention mechanism to combine words at different distances, providing global context for each element in the sequence.
The Google team gave the new model a well-known name: “Transformer.”Unlike recurrent neural networks (RNNs), which are commonly used in processing sequence data, the attention mechanism in Transformers does not process data in sequence. This means that each element and all elements in the sequence are related, ensuring that the correlations between elements, no matter how far apart they are in time, are well preserved.
And this long-term correlation is usually very important for natural language processing. For example, in the sentence below, “it” refers to “The animal”, but these two elements are far apart, making it difficult to establish a correlation between them using RNN-based sequential processing.
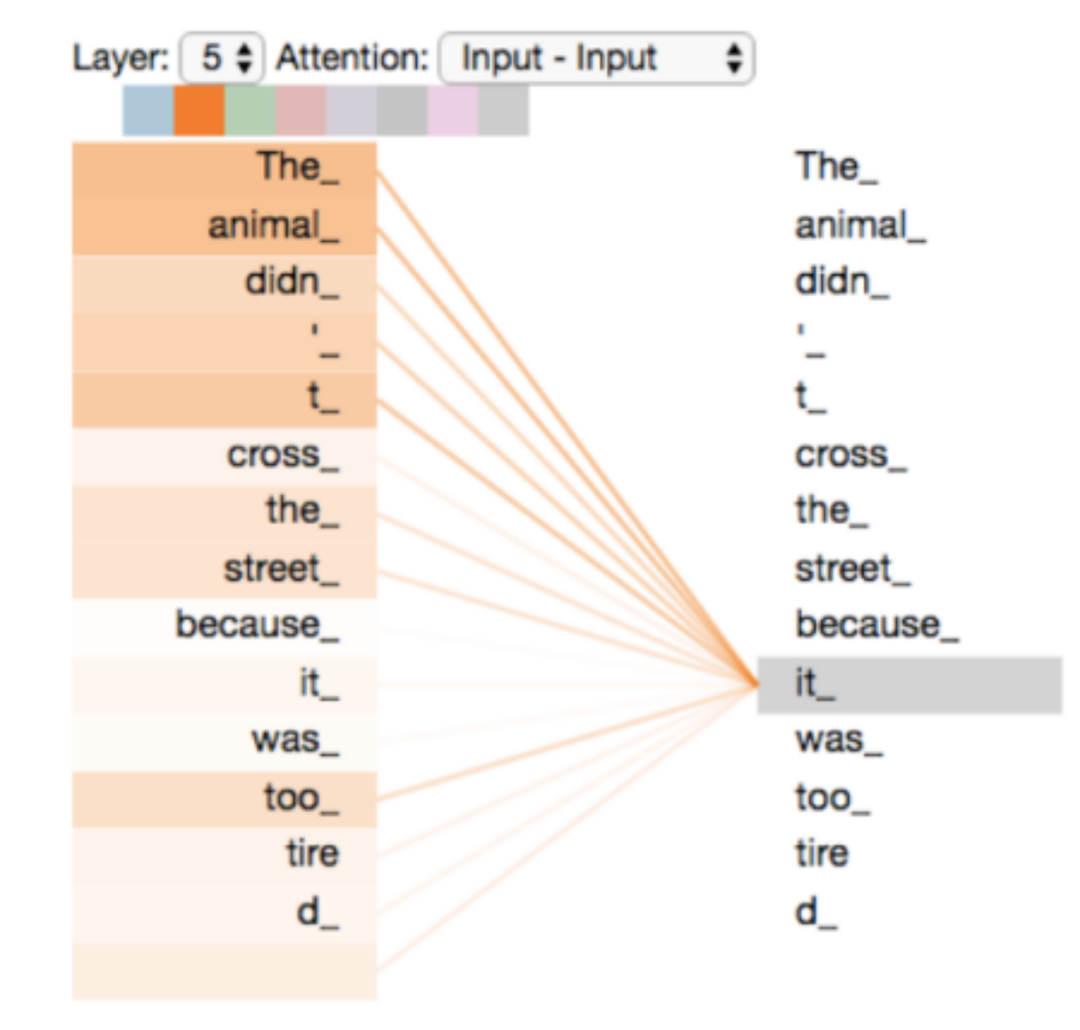
Transformers do not care about order. When computing correlations, the importance of each element is calculated based on the semantic information in the data itself. As a result, correlations between distant elements can be easily extracted.
Why is this important?
Because with Transformer models incorporating attention mechanisms, the results in visual tasks, such as image classification and object detection, are surprisingly good.
Why are algorithms originated from the natural language field also applicable to vision problems?
There are mainly two reasons:
-
Although images are not time-series data, they can be seen as sequences on the spatial axis. A key step in vision tasks is to extract correlations between pixels. Ordinary convolutional neural networks (CNNs) use convolution kernels to extract local correlations (also known as local receptive fields), while Transformers can provide global receptive fields. Therefore, the feature learning ability is much higher than that of CNNs.
-
If we further consider video input data, this is itself sequential data, making it more suitable for processing with Transformers.
In the example shown in Figure 3, Transformer is used for image classification. The image is evenly divided into small blocks, which are arranged spatially to form a sequence of image blocks. The pixel values (or other features) of each image block form the feature vector of that block, and after encoding with Transformer and concatenating, the feature of the entire image is obtained.
The structure of the encoder, with a crucial component called a “multi-head attention module“, is shown on the right.In simple terms, multi-head attention is the integration of multiple attention mechanism modules, each independently encoding and extracting different features to increase the coding ability, while also achieving highly efficient parallel processing on computing chips.
In summary, this is what the “AI Ten-Year Outlook (Part III): A Comprehensive Analysis of the Autonomous Driving Industry from an AI Perspective” report by CICC says:
As Transformer can model well in the “spatial-temporal” dimension, industry leaders such as Tesla and Horizon Robotics have improved their models on the perception end by using Transformer.
Tesla extracts image features from videos captured by eight traditional ResNet cameras installed around the car, and then uses a combination of Transformer CNN and 3D convolution to achieve cross-time image fusion, ultimately forming 3D output based on 2D images.
Horizon Robotics’ AI team is gradually applying Transformer-based perception algorithms to practical road perception problems such as lane detection, obstacle detection, drivable area segmentation, traffic light detection & recognition, road traffic sign detection, and point cloud detection & segmentation.
Interpretation of Tesla’s FSD System
Dr. Andrej Karpathy mentioned at Tesla AI Day that five years ago, Tesla’s vision system first obtained detection results in a single image and then mapped them to a vector space.
This “vector space” is one of the core concepts of AI Day. In fact, it is the representation space of various targets in the environment in the world coordinate system.
For example, “For object detection tasks, the descriptive characteristics of the target’s position, size, orientation, speed, and other features in 3D space form a vector, and the space composed of the descriptive vectors of all targets is the vector space.“
The task of the visual perception system is to convert information from the image space to the vector space.
This can generally be achieved in two ways:
-
Complete all perception tasks in the image space, then map the results to the vector space, and finally fuse the results from multiple cameras;
-
First, convert the image features to the vector space, then fuse the features from multiple cameras, and finally complete all perception tasks in the vector space.
Dr. Karpathy gave two examples to illustrate why the first method is unsuitable.
Firstly, due to perspective projection, the perception results that look good in the image space have poor accuracy in the vector space, especially in distant areas. As shown in the figure below, lane lines (blue) and road edges (red) are positioned inaccurately in the vector space after projection and cannot support autonomous driving applications.
Secondly, in multi-target systems, due to limited visibility, a single camera may not be able to capture the entire target. For example, in the example below, a large truck appears in the field of view of some cameras, but many cameras only see a part of the target, so it is impossible to make the correct detection based on incomplete information, and the subsequent fusion effect cannot be guaranteed. This is actually a general problem of multi-sensor decision-level fusion.

In summary, perception in image space + decision-level fusion is not a very good solution.
Direct fusion and perception in vector space can effectively solve the above problems, which is also the core idea of the FSD perception system.
To achieve this idea, two important problems need to be solved: First, how to transform features from image space to vector space; Second, how to obtain annotated data in vector space.
Feature space transformation
For the problem of feature space transformation, the general solution is: “Use the calibration information of the camera to map the image pixels to the world coordinate system“.
However, there are some conditional problems that need to be constrained. In autonomous driving applications, ground-plane constraints are typically used, that is, the target is on the ground and the ground is horizontal. This constraint is too strong and cannot be met in many scenarios.
Tesla’s solution has three core points:
Firstly, using Transformers and self-attention to establish a correspondence between image space and vector space. In simple terms, the feature at each position in vector space can be regarded as a weighted combination of all feature positions in the image.
Of course, the weight of the corresponding position is certainly larger, but this weighted combination process is automatically realized through self-attention and spatial coding, without manual design, and is completely based on end-to-end learning according to the task at hand.
Secondly, the calibration information of each camera on each production car is different, resulting in inconsistent input data with the pre-trained model. Therefore, this calibration information needs to be provided as an additional input to the neural network.
The simple approach is to concatenate the calibration information of each camera, encode it through a neural network, and then input it to the neural network. However, a better approach is to correct the images from different cameras using the calibration information, so that the cameras corresponding to different vehicles output consistent images.## Three, video (multiple frames) input is used to extract temporal information to increase the stability of the output results, better handle occlusion scenes, and predict the motion of targets.
An additional input in this part is the motion information of the vehicle itself (which can be obtained through IMU) to support the neural network in aligning feature maps at different time points. The processing of temporal information can be achieved via 3D convolution, Transformer, or RNN.

Through these algorithmic improvements, FSD has significantly improved the quality of its output in vector space. In the comparison figure below, the bottom left is the output from the image space perception + decision-level fusion solution, while the bottom right is the solution using the above feature space transformation + vector space perception fusion.
Annotation in Vector Space
Since it is a deep learning algorithm, data and annotation are naturally critical components. Annotation in image space is very intuitive, but what the system ultimately needs is annotation in vector space.
Tesla’s approach is to reconstruct the 3D scene from images from multiple cameras and annotate it in the 3D scene. The annotator only needs to annotate once in the 3D scene and can see the mapping of the annotation results in real-time in various images for corresponding adjustments.

Human annotation is only a part of the entire annotation system. In order to obtain annotations faster and better, automatic annotation and simulators are also needed.
The automatic annotation system first generates annotation results based on images from a single camera, and then integrates these results based on various spatial and temporal clues. To put it plainly, “the various cameras come together to discuss and produce a consistent annotation result.”
In addition to the collaboration of multiple cameras, multiple Tesla vehicles driving on the road can also collaborate and improve annotations for the same scene. Of course, GPS and IMU sensors are required here to obtain the position and attitude of the vehicle and align the output results of different vehicles in space.
Automatic annotation can solve the efficiency problem of annotation, but for some rare scenes, such as the pedestrian running on the highway demonstrated in the “AI Outlook in the Autonomous Driving Industry from the AI Perspective” report by Zhongjin, simulated data is needed to be generated.
All of these technologies combined make up Tesla’s complete deep learning network, data collection, and annotation system.
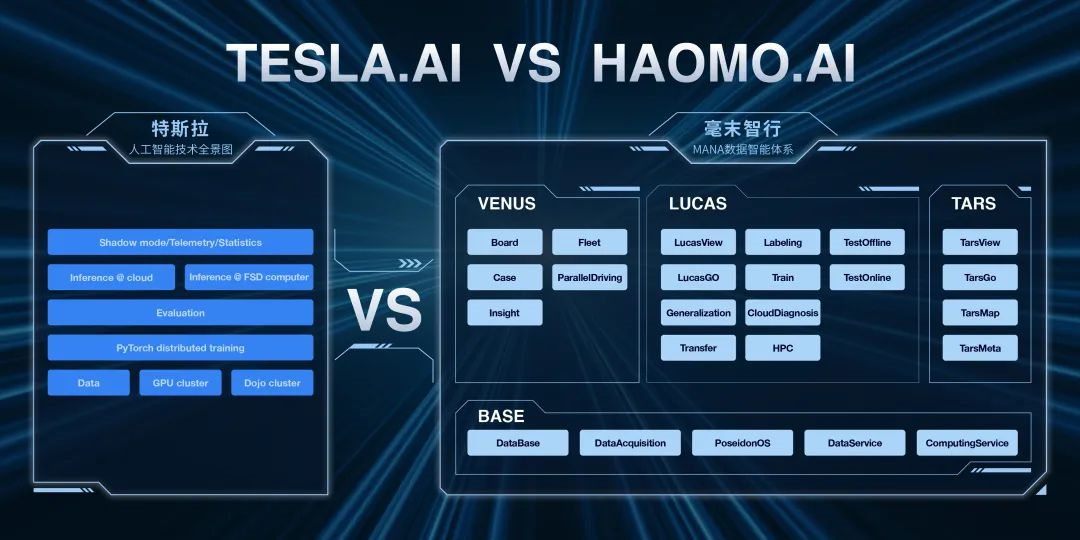
Interpretation of the MANA System from Moovita
Relying on Great Wall Motors, Haomo Zhixing can obtain massive real road test data. As for the problems with processing data, Haomo Zhixing proposes to introduce Transformer into its data intelligence system MANA, and gradually apply it to practical road perception problems, such as obstacle detection, lane line detection, drivable area segmentation, traffic sign detection, etc.
From this perspective, the technology of mass-produced car companies is moving towards convergence with the support of a large-scale dataset.
In the era of diversified autonomous driving technologies, choosing the correct path and establishing the advantages of one’s own technology are extremely important for both Tesla and Haomo Zhixing.
In the development of autonomous driving technology, there has always been a debate over which sensors to adopt. The current focus of the debate is whether to adopt a pure vision approach or a LiDAR approach.
Tesla adopts a pure vision solution, which is also based on its million-level fleet and billions of kilometers of actual road condition data.
There are two main considerations for using LiDAR:
-
The gap in data scale is difficult to fill for other autonomous driving companies. To gain a competitive advantage, it is necessary to increase the perceptual ability of sensors. Currently, the cost of a solid-state LiDAR has dropped to the level of several hundred dollars, which can basically meet the needs of mass-produced models.
-
From the perspective of current technological development, vision-based technologies can meet the requirements of level L2/L2+ applications, but LiDAR is still indispensable for level L3/4 applications (such as RoboTaxi).
In this context, whoever can both have massive data and support both vision and LiDAR sensors will undoubtedly occupy an advantageous position in the competition. Obviously, Haomo Zhixing has already taken the lead in this direction.
According to Haomo Zhixing CEO Gu Weihao’s introduction at AI Day, the MANA system uses Transformer to integrate vision and LiDAR data at the bottom layer and then achieve deep-level perception of space, time and sensors.
Next, I will explain the MANA system in detail, especially the differences with Tesla FSD.
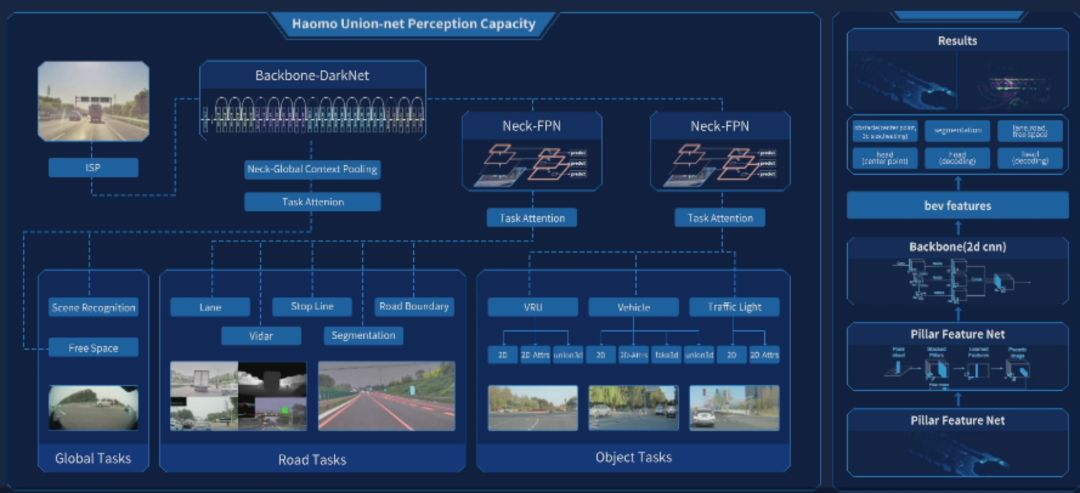
Vision Perception Module
After the camera obtains raw data, it needs to go through the ISP (Image Signal Process) digital processing process before providing it to the back-end neural network.
ISP’s function is generally to obtain better visual effects, but the neural network doesn’t actually need to “see” the data, and the visual effect is only designed for humans.Therefore, using ISP as a layer in the neural network allows the neural network to determine ISP parameters and calibrate the camera according to the backend task. This helps to maximize the retention of original image information and ensure that the captured images are as consistent as possible with the training images of the neural network in terms of parameters.
The processed image data is sent to the backbone network, and the DarkNet, which is similar to a multi-layer convolutional residual network (ResNet), is used in the MANA system, which is also the most commonly used backbone network structure in the industry.
The features output by the backbone network are then sent to different heads to complete different tasks.
The tasks here are divided into three categories: global tasks, road tasks, and object tasks.
Different tasks share the features of the backbone network, and each task has its own independent Neck network to extract features for different tasks. This idea is similar to Tesla’s HydraNet.
However, the characteristic of the MANA perception system is that a Neck network is designed specifically for extracting global information for global tasks.
This is actually very important because global tasks, such as detecting drivable roads, rely heavily on understanding the scene, which in turn relies on extracting global information.
LiDAR perception module
The PointPillar algorithm is used for LiDAR perception, which is also a commonly used 3D object detection algorithm based on point clouds. The feature of this algorithm is that it “projects” 3D information onto a 2D (top-down) view, and conducts similar feature extraction and object detection in 2D data as in visual tasks.
The advantage of this approach is that it avoids the very computationally expensive 3D convolution operation, so the algorithm is very fast overall. PointPillar is also the first algorithm in the field of point cloud object detection that can achieve real-time processing requirements.
In previous versions of MANA, visual data and LiDAR data were processed separately, and the fusion process was completed at the level of their respective output results, which is commonly known as “back-end fusion” in the field of autonomous driving.
This approach can maximize the independence of the two systems and provide safety redundancy for each other. However, back-end fusion also causes neural networks to be unable to fully utilize the complementarity of data between the two heterogeneous sensors to learn the most valuable features.
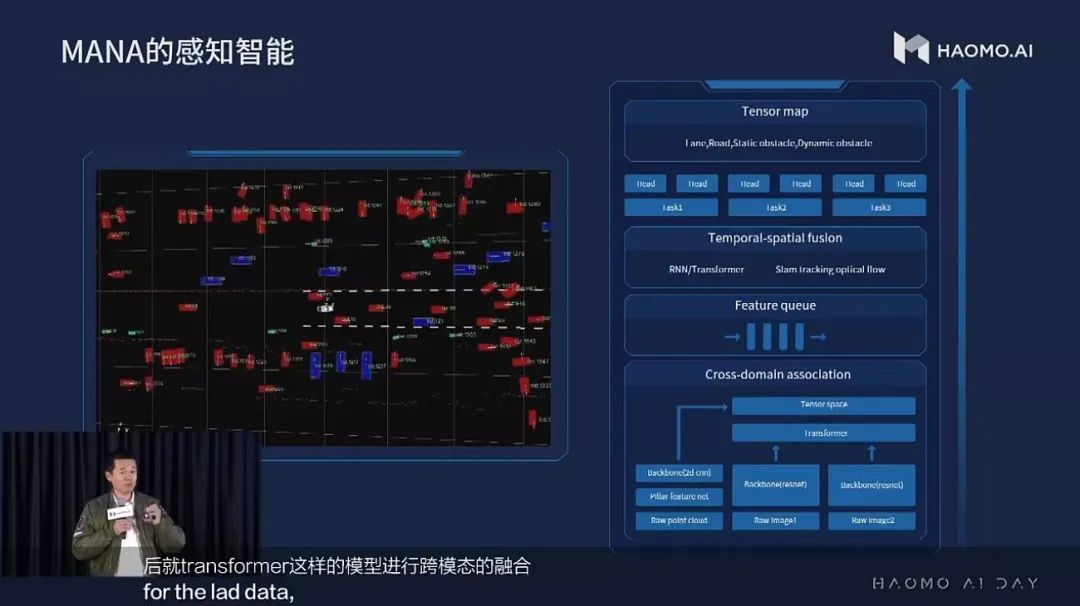
Fusion perception moduleThe concept of “trinity fusion” was mentioned earlier, which is also the key difference of MANA perception system compared to other perception systems. As Haomo Intelligence CEO Gu Weihao said at AI Day, “Most perception systems currently have the problem of ‘discontinuous temporal perception and fragmented spatial perception’.”
Discontinuous temporal perception is due to the fact that the system processes data in units of frames, and the time interval between frames may be several tens of milliseconds. The system focuses more on processing the results of each individual frame and carries out temporal fusion as a post-processing step. For example, a separate object tracking module is used to link the detection results of each frame together, which is also a type of post-fusion strategy. Therefore, useful temporal information cannot be fully utilized.
Fragmented spatial perception is caused by different spatial coordinate systems of multiple homogenous or heterogeneous sensors. For homogenous sensors (such as multiple cameras), because of different installation positions and angles, their fields of view (FOV) are not exactly the same. The FOV of each sensor is limited, and the data from multiple sensors need to be fused to obtain 360-degree perception capability around the vehicle. This is very important for autonomous driving systems above L2 level.
For heterogeneous sensors (such as cameras and lidars), the data acquisition methods and the resulting data information and format differ greatly. Cameras capture image data with rich texture and semantic information, suitable for object classification and scene understanding. Lidars capture point cloud data, which provides very accurate spatial positional information and is suitable for perceiving object 3D information and detecting obstacles. If each sensor is processed separately and then post-fused on the processing results, the complementary information contained in the data of multiple sensors cannot be fully utilized.
So how do we solve these two problems?
The answer is: use Transformer for spatial and temporal pre-fusion.
Let’s first talk about spatial pre-fusion with Transformer. Unlike the role of Transformer in general computer vision tasks such as image classification and object detection, the main function of Transformer in spatial pre-fusion is not to extract features, but to transform coordinates. This is similar to the technology adopted by Tesla, but Haomo goes even further by adding lidar and conducting multi-sensor (cross-modal) pre-fusion, which is the Cross-Domain Association module in Figure 8.The basic working mechanism of Transformer was introduced above, which can be simplified as “computing the relevance among each element of the input data and utilizing it for feature extraction“.
Coordinate transformation can also be formalized as a similar process. For instance, to transform the images from multiple cameras to the 3D coordinate system consistent with the LiDAR point cloud, the system needs to find the correspondence between each point in the 3D coordinate system and the image pixels. Traditional methods based on geometric transformations would map a point in the 3D coordinate system to a point in the image coordinate system and use a small neighborhood of the image point (e.g. 3×3 pixels) to compute the pixel value of the 3D point.
However, Transformer would establish the correspondence between each 3D point and every image pixel and use the self-attention mechanism, which is the calculation of relevance, to determine which image pixels will be used for computing the pixel value of the 3D point.
As shown in Figure 9, Transformer first encodes the image features and then decodes them to 3D space. The coordinate transformation has been embedded into the calculation process of self-attention.
This approach breaks the constraint of neighborhood in traditional methods and allows the algorithm to see a broader range in the scene and conduct the coordinate transformation by understanding the scene. Moreover, the process of coordinate transformation is conducted in the neural network, and the parameters of transformation can be automatically adjusted by the specific task to be forwarded to the backend of the network.
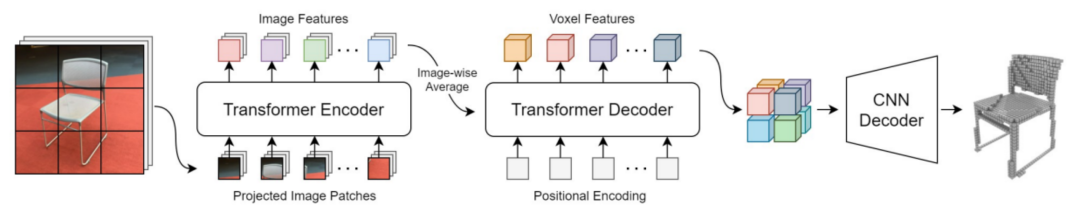
Therefore, this transformation process is completely data-driven and task-specific. Based on the premise of possessing a large dataset, it is completely feasible to use Transformer for spatial coordinate transformation.
Temporal pre-fusion
This is easier to understand than spatial pre-fusion since Transformer was initially designed to handle temporal data.
The Feature Queue in Figure 8 is the output of the spatial fusion module in the temporal dimension, which can be regarded as multiple words in a sentence, so Transformer can naturally extract temporal features. Compared with the solution of using RNN for temporal fusion in Tesla, Transformer has stronger feature extraction capability but lower efficiency in operation.
RNN is also mentioned in the solution of Momenta, and I believe that a comparison between the two solutions, even an integration in some extent to make full use of their strengths, is currently under investigation.
In addition, with the support of LiDAR, Momenta uses SLAM tracking and optical flow algorithms to achieve rapid self-positioning and scene perception, better ensuring the coherence in the temporal dimension.
Cognitive moduleExcept the perception module, there are also some special designs in the cognition module, which is the path planning part.
As introduced by Gu Weihao at the AI Day, the biggest difference between cognition module and perception module is that the cognition module does not have a definite “ruler” to measure its performance, and there are more factors need to be considered in the cognition module, such as safety, comfort, and efficiency, which undoubtedly increase the difficulty of designing the cognition module.
In response to these issues, the solution of Maohao is scene digitalization and large-scale reinforcement learning.
Scene digitalization is the parameterized representation of different scenes on the driving road. The advantage of parameterization is that scenes can be effectively classified for differentiated processing.
According to different granularity, the scene parameters can be divided into macro and micro categories: the macro scene parameters include weather, lighting, road conditions, etc., while the micro scene parameters describe the driving speed of the vehicle itself and its relationship with surrounding obstacles.
After digitizing various scenes, artificial intelligence algorithms can be used for learning. In general, reinforcement learning is a good choice for completing this task.
Reinforcement learning is the method adopted in the famous AlphaGo, but different from the Go game, the evaluation standard for autonomous driving tasks is not winning or losing but the rationality and safety of driving.
How to correctly evaluate every driving behavior is the key to the design of reinforcement learning algorithms in the cognition system. The strategy adopted by Maohao is to simulate the behavior of human drivers, which is also the fastest and most effective method.
Of course, data from just a few drivers is far from enough, and the basis for this strategy is a massive amount of human-driven data, which is precisely the advantage of Maohao. This is also the reason why based on the data, Maohao can rapidly iterate the algorithm and deliver the automatic driving system that covers more scenes.
Conclusion
With the rapid development and landing of autonomous driving technology, more and more mass-produced vehicles are equipped with software and hardware that support different levels of autonomous driving systems. While gradually heading towards commercialization, the scale effect of mass-produced vehicles can also provide massive data support for the iteration of autonomous driving systems. This is also the widely recognized path to high-level autonomous driving in the industry.In this context, companies that have the potential data advantage for mass-produced cars need to find ways to enter the market. Tesla and Hozon Auto, relying on Great Wall Motor, were the first to come up with solutions. Both solutions have similarities in macro aspects and many differences in specific strategies, reflecting both consensus and individuality.
The consensus is that both companies use Transformer neural network structure to improve learning ability on large-scale datasets, and both companies believe that data collection and automatic annotation are important parts of the entire algorithm iteration and have made huge investments in this regard.
Regarding individuality, Tesla adopts a purely visual solution, while Hozon Auto uses a solution that combines visual and LIDAR. In the context of the continuously decreasing production cost of LIDAR, Hozon’s solution has potential for development. In addition, Hozon’s application of Transformer is more in-depth.
In addition to fusing spatial information, Transformer is also used in the MANA system to fuse temporal and multimodal information, unifying various discrete data collected by the system to form a coherent data flow, in order to better support different backend applications.
Regardless of the implementation solutions used, the attempts by Tesla and Hozon Auto on massive data are significant for the development and eventual implementation of autonomous driving technology.
We also hope that more companies will join in the future, try more different possibilities, exchange ideas and learn from each other, and even share technologies and data, so that autonomous driving can serve the public better and faster.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.