
Before we welcome the new XPeng P7, let’s talk about XPeng’s ancestors.
Hello, everyone, I’m Goodmourning.
Recently, XPeng P7 will once again receive an OTA upgrade to version 2.6.1. I believe through various interesting preheating activities, everyone should also know that our lovely voice assistant XPeng will receive a brand new voice through OTA upgrade. For those who haven’t heard it yet, watch the video below to have a listen.
Insert video 1
I don’t know what your thoughts are after listening to it. But Goodmourning’s first impression was:

Next, let’s discuss the past and present of voice assistants.

In essence, the voice assistant that we are now accustomed to is a system that recognizes and responds to your voice commands. So when I say that the earliest speech recognition system appeared before computers, are you surprised?

Yes, it’s this unremarkable toy dog called Radio Rex that was produced in the 1920s. When called, this toy dog can pop out and was widely considered the predecessor of speech recognition. It was a rare thing at the time and was popular throughout European high society. However, limited by the technology at the time, speech recognition could only be limited to this.

Fast forward to 1946, when the first computer was born. People realized that computers could do many things and one of the beautiful ideas at the time was to command them through conversation with the computer.

Alan Turing, the father of computer science, proposed an idea of “communicating with human and machine…” Although Turing didn’t come up with an implementation method, he proposed a simple yet practical intelligence test method, which is the “Turing test”.
And soon in 1952, the famous Bell Labs developed a system called “Audrey”. This was the world’s first system that recognized Arabic numerals, and henceforth machines could understand human speech. This was the first generation of “speech recognition systems”. However, its level was very limited, and it only intelligently recognized the ten digits from 0 to 9. We hoped that it could understand human speech, but it could only count numbers, which was insufficient. Therefore, people had to continue their research.

In 1970, speech recognition had a major breakthrough. In that year, the American scientist Jelinek proposed the theory of “statistical-based speech recognition framework”, and led the Watson Laboratory of IBM to raise the number of recognized words from several hundred to several tens of thousands, and the recognition rate rose from 70% to 90%.

By the 1990s, an important algorithm was born: the hidden Markov model (HMM), which became an important foundation of speech recognition technology. I won’t go too deep about it since it is too academic. IBM’s ViaVoice program was born, and it also became an important milestone in speech recognition. At this point, the technology had reached the level of being able to input text through a microphone.

Then in 2006, speech recognition experienced its biggest transformation since its inception. Because in that year, the Google AI scientist team proposed the concept of deep learning, which is an algorithm that enables computers to actively learn. The proposal of this concept led to a huge breakthrough in AI. When the era of big data on the Internet came, people added Internet big data to speech recognition, and thus, AI speech recognition composed of artificial intelligence, big data, and speech recognition was born.
 As for the first time, the intelligent speech recognition system entered the public’s life around 2010. In that year, the rising Steve Jobs brought iPhone 4S to the world, and the Siri system made people feel the convenience of using voice to operate mobile phone functions.
As for the first time, the intelligent speech recognition system entered the public’s life around 2010. In that year, the rising Steve Jobs brought iPhone 4S to the world, and the Siri system made people feel the convenience of using voice to operate mobile phone functions.

Later on, intelligent speech became like standard equipment and appeared in various types of smart phones that followed. Today, intelligent speech systems such as Siri, Xiao Ai, Xiao E, Xiao Du, Bixby, Breeno, and Jovi have entered every aspect of our lives. The interconnection of all things is becoming possible, and voice control of all things is gradually becoming possible.
Now let’s turn our attention back to cars. Since the birth of cars at the end of the 19th century, people have come up with countless ways to communicate with and exchange information with cars. From various types of steering wheels and manual or automatic transmissions to a multitude of interactive buttons and switches and LED LCD displays, people have tried everything, and it’s like a condensed history of technology.

After a hundred years of development, people have suddenly realized that they not only receive information through vision and touch, but they are not deaf! So around 1983, the centennial of the invention of cars, two such products were created.

This is the prototype of the Blaupunkt-developed Electronic Pilot for Drivers (EVA) used for in-car voice navigation systems. You may not be able to imagine that its storage method is magnetic tape, so due to limitations in magnetic tape technology, the prototype only stored map data for Stuttgart, so it cannot provide navigation beyond Stuttgart, thus its practical value was quite limited. But the significance of EVA was that it enabled users to obtain navigation information through auditory perception and created another dimension of interactive experience.

The other product is the Maestro from the British company Leland, with its super high-tech configuration making it the most futuristic car model of the 1980s.
LCD instrument panel has replaced mechanical pointers. Although it was just a monochrome LCD instrument panel like an electronic clock, it was considered cutting-edge technology in that era.

Another disruptive design, the in-car voice system, also appeared on the Maestro. British Leyland invited actress Nicolette McKenzie to be the voice-over for the Maestro, recording 32 group voice messages, including reminders to fasten the safety belt, warnings of unclosed doors, oil level prompts, and reminders for unclosed lights and low temperature alerts. Although it wasn’t as intelligent as today’s voice control systems, it was still impressive for the car owners in the early 1980s to hear the Maestro speak.
These two speech products opened the door to a new era of in-car interaction, marking the beginning of the love-hate relationship between cars and speech systems.

In 2001, the first large-scale application of in-car voice interaction was launched in the BMW 7 Series iDrive. In addition to various knobs and buttons, speech recognition become a key element of the human-machine interface.
Unfortunately, due to various reasons such as technological and hardware limitations, in-car voice interaction has been in a usable but not user-friendly state. There have been many jokes about it, and the phrase “Correcting, correcting, not 96” is still unforgettable to this day.
Despite the jokes, it is worth knowing that this video was shot in 2015, and in-car voice systems have been suffering for a long time!
Finally, the year 2020 arrived. This was already the second year I had planned to purchase a car. Over the past year or so, I test drove all the new energy vehicles and more than ten gasoline cars on the market, totaling more than 30. At that time, I wasn’t only satisfied with traditional vehicle mechanical properties, I had higher requirements for intelligent cars.The dazzling publicity of various intelligent cars on the market showcases their powerful features, but I have always had a barrier in my heart: the human-computer interaction of these cars never meets my expectations. Here are two examples that have left a deep impression on me.

Although Tesla has a powerful car system and various functions, the extremely poor voice system makes it difficult to use the functions. You can only swipe on the screen, not to mention convenience and efficiency, even during driving you need to constantly check the central control screen to confirm whether the click was successful, which greatly affects driving safety.

NIO’s NOMI also has several shortcomings that make me feel dissatisfied. First of all, the fixed format of voice expressions cannot reflect my natural questions or expressions. Instead, I have to use specific predefined language to trigger the corresponding action. As an unfamiliar user, I need to remember the fixed expressions. Even to a familiar user, it may feel too rigid and unnatural. Another issue is that NIO’s voice integration is not deep enough. Many functions cannot be operated through voice, whether it is for safety concerns or a lack of ability. The overall experience is just like using a common intelligent speaker – nothing outstanding.

However, all of this changed when I encountered XPeng P7. It feels like the interaction barrier between people and cars has been completely removed. It’s worth noting that even when XPeng P7 just started delivery in 2020, its XPeng voice assistant was already able to understand your intentions simply through your expression. It integrates deeply with the car system, making it possible to complete almost all functions through voice control. Not to mention the response speed and recognition accuracy.

Three months later, at the end of October, XPeng P7 ushered in a major update: full-scene voice recognition, which had greatly improved the interaction experience, like adding four more engines to XPeng P7. These four new functions are continuous conversation, visible speech recognition, semantic interruption, and double audio zone locking.“`markdown
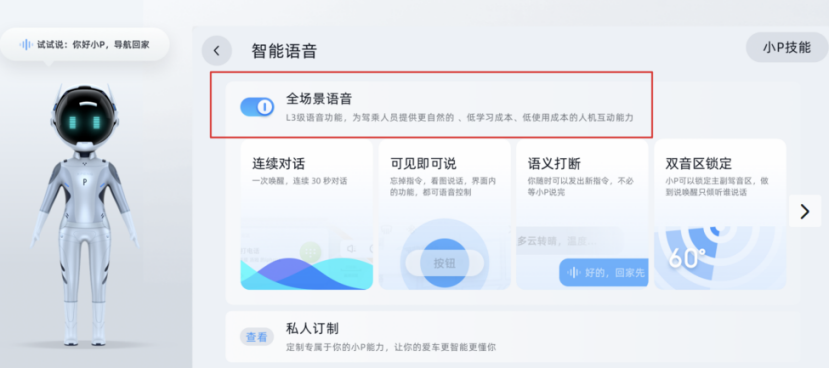
The continuous dialogue function allows small P to speak multiple commands with only one activation. During the entire conversation, it is not necessary to wake up small P again after issuing a command once, and it is possible to give another command with the context of the previous one by voice continuously without clicking switches manually. This feature greatly enhances driving safety.
The “see it, say it” function allows any options on the current page to be controlled by shouting out their text with voice, without using hands to click on switches. This feature greatly enhances driving safety.
The semantic interruption support enables new commands to be issued at any time when encountering longer broadcasts from small P without waiting for small P to finish speaking, greatly enhancing the fluency of voice use.
The dual sound zone lock function is an experience-enhancing function. Without this function, when there are two or more people in the car, the voice interaction will recognize the speech of all passengers in the car and cause confusion. With this function, the voice interaction will only recognize the voice of the user who activates the wake-up voice and listen to the instructions given to that user exclusively.
With these four functions, small P completely outperforms other voice control systems and has become a truly useful voice assistant.

As of the release of this article, Gu-Domonic’s P7 has been updated to the latest version of Xmart OS 2.6.1 beta system.
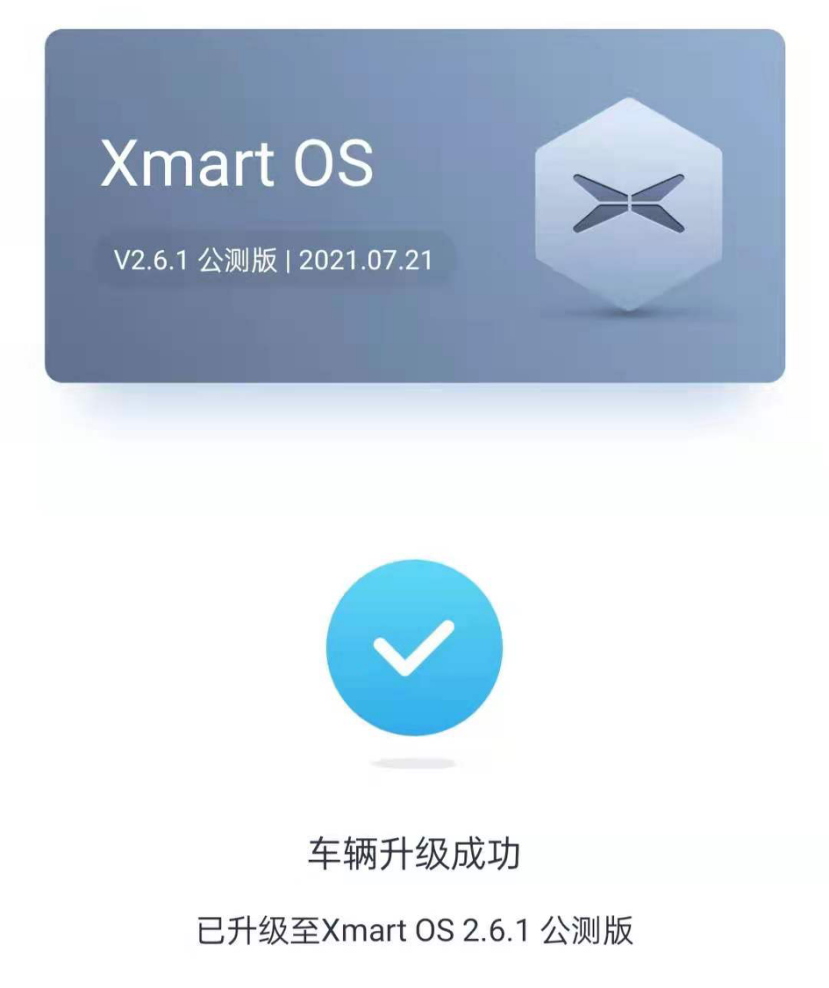
The most important change in this voice system is that small P has a more human-like tone and stronger sound quality, which uses the rare “ultra-large-scale online neural network engine + small offline splicing engine” technology combination in the market.
Let us wait and see how the new small P performs in the new system.
Gu-Domonic will talk about the new experiences of the all-new small P in the next article after experiencing it.
Follow me and let me show you how to play with the Gu-Domonic P7. I am Gu-Domonic, and see you in the next issue.

“`
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.