Translation:
Body:
The full article is 1,992 words.
Estimated reading time: 10 minutes.
Tesla has always been a proponent of visual artificial intelligence technology and has been striving for pure visual autonomous driving as its ultimate goal. After understanding Tesla’s AI Day, I am more convinced of this ambition and believe that Tesla is making 200% effort towards this goal.
Below, we will interpret one by one and see how Tesla is using 200% effort to achieve this goal.
As we all know, the sensors installed on Tesla cars can be described as “very few”. In addition to cameras and millimeter-wave radar, there is also ultrasonic radar which is equipped by almost all cars. Recently, the new Model Y, which is offline in the United States, has also removed the millimeter-wave radar. Tesla will gradually cancel the millimeter-wave radar on all models in the future. This time, Tesla has truly achieved “extreme (kou) and ultimate (men)”.
However, only by using the 8 cameras around the car, the autopilot effect of Tesla’s recent release of the FSD Beta V10 is much better than the previous version with millimeter-wave radar.
So why can the version after this “downgrade” be better than the previous version? Now we will unveil Tesla’s pure visual ambition.
The world captured by the 8 cameras around the Tesla car is ultimately output as a three-dimensional vector space representing the surrounding environment through neural networks and logical processing. The image displayed on the car screen on the right in the following picture is the visualized rendering of this three-dimensional vector space.

The camera transforms what it sees into a three-dimensional vector space, and the “prototype” of this idea is the human eyes and brain. After the human “eyes” see something, it is processed by the neural neurons in different areas of the “brain” and finally becomes “information”.
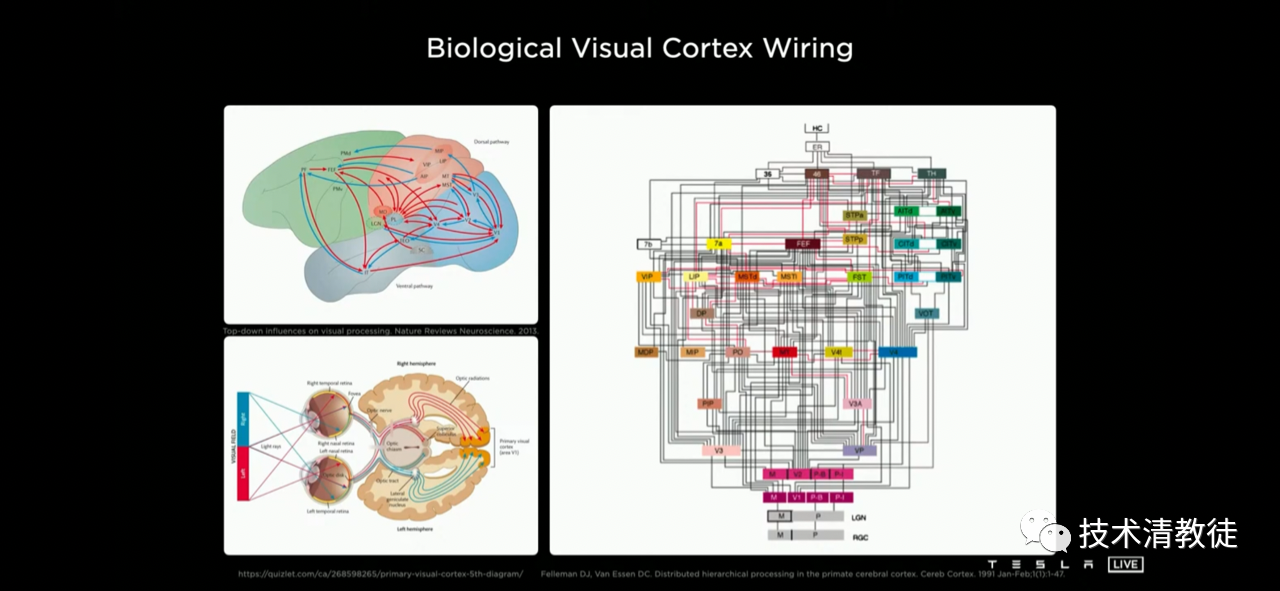
Here, the camera is the “eye”, and it perceives the light signal through the photosensitive element to form pixels.

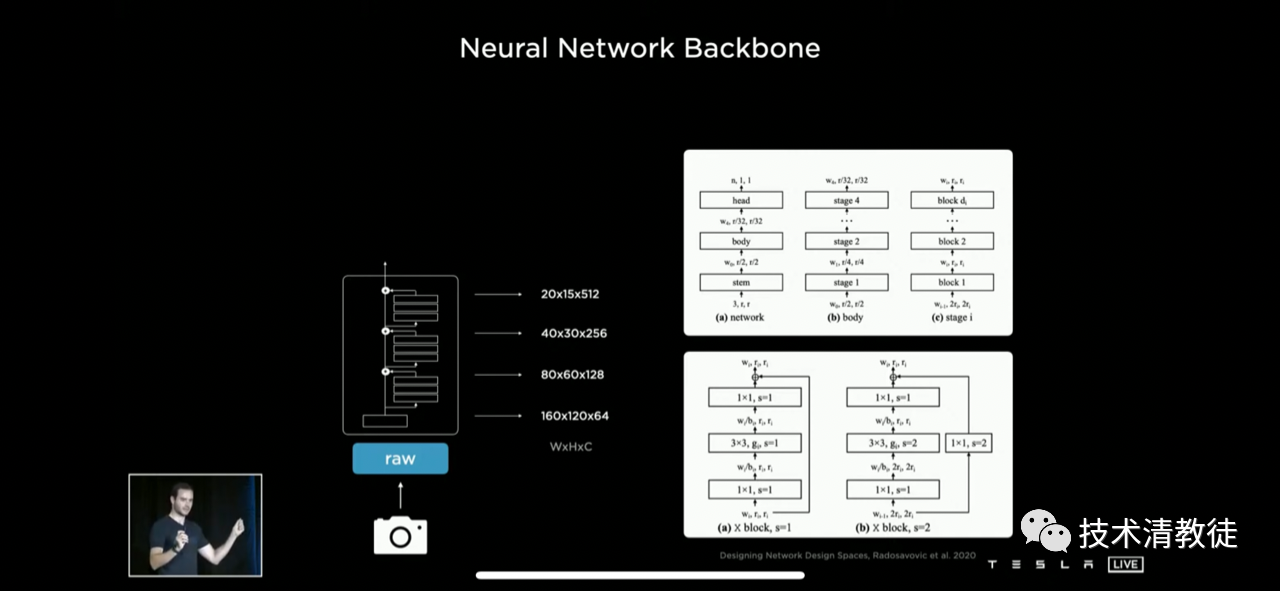
Then, the neural network will process these pixels like the neurons in the “brain”. Tesla gave some examples, as shown on the left in the figure below. By setting different pixel block sizes in the input image, the RegNet neural network can extract many different features from the image from global to local through convolutional operations of different depths.

Then Tesla uses the BiFPN neural network to correlate and compare the globally and locally extracted features to understand useful information in the image. For example, RegNet neural network has extracted many feature information, and there are two dots in the local features and a road in the global features, and these two dots are on the road. Therefore, the BiFPN neural network can roughly deduce that this is a car’s tail light and determine it as a car.
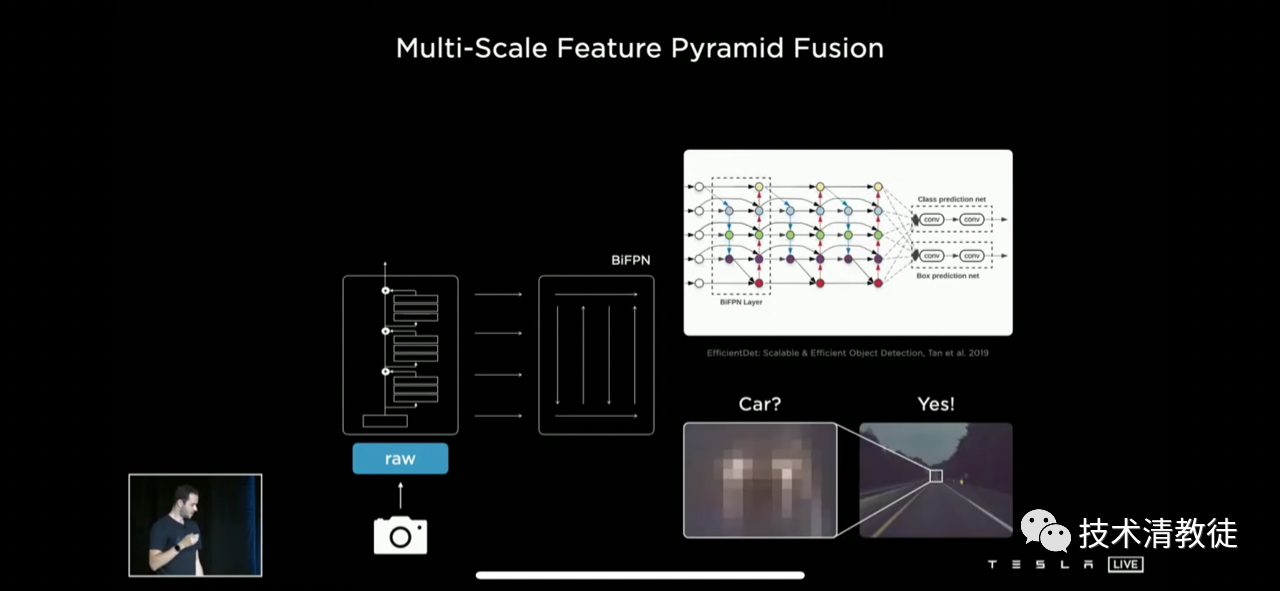
RegNet neural network is mainly used for extracting different feature information, and then the BiFPN neural network is used to fuse these feature information together to find useful clues to infer the content of the image.
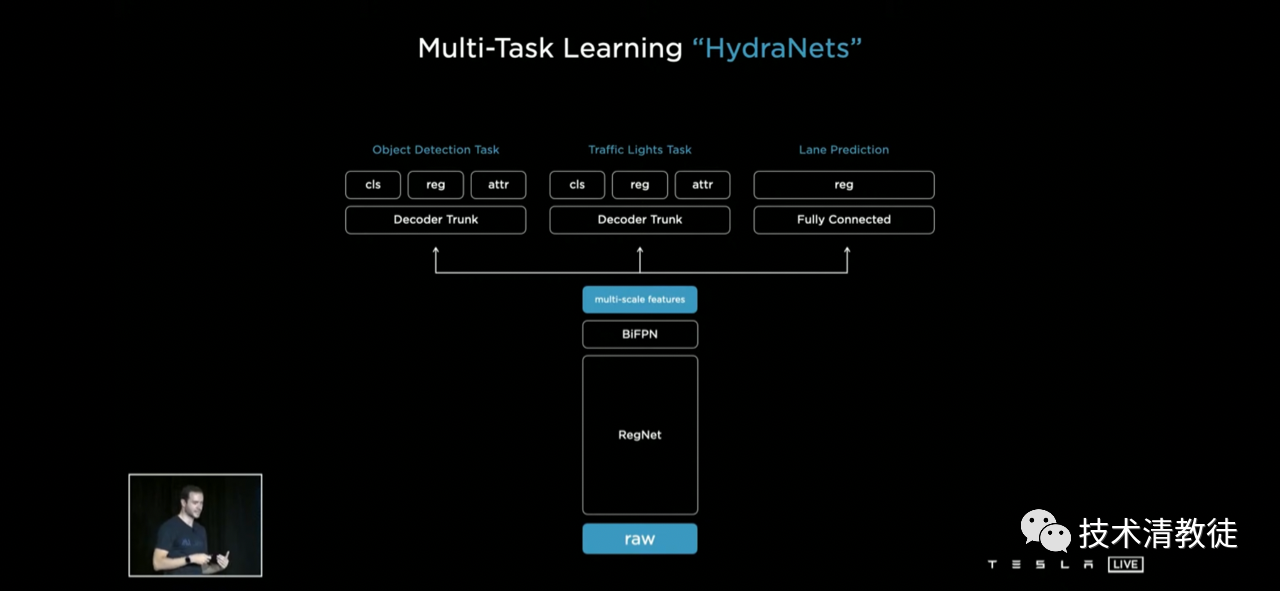
These fused feature information will be divided into different sub-tasks for decoding and fine-tuning, such as objects, traffic lights, and roads.
However, after the operation, Tesla found that the “recognition first and then fusion” effect of the camera was not satisfactory. As shown in the figure below, the roadside far away from the car is almost impossible to see in the three-dimensional vector space. Because it is too difficult to predict the distance based on a single pixel of the camera.

Moreover, when the car passes by a truck, the various parts of the truck are in the 6 cameras separately. If each camera independently recognizes and then fuses, you can imagine that the recognition effect will be very poor.

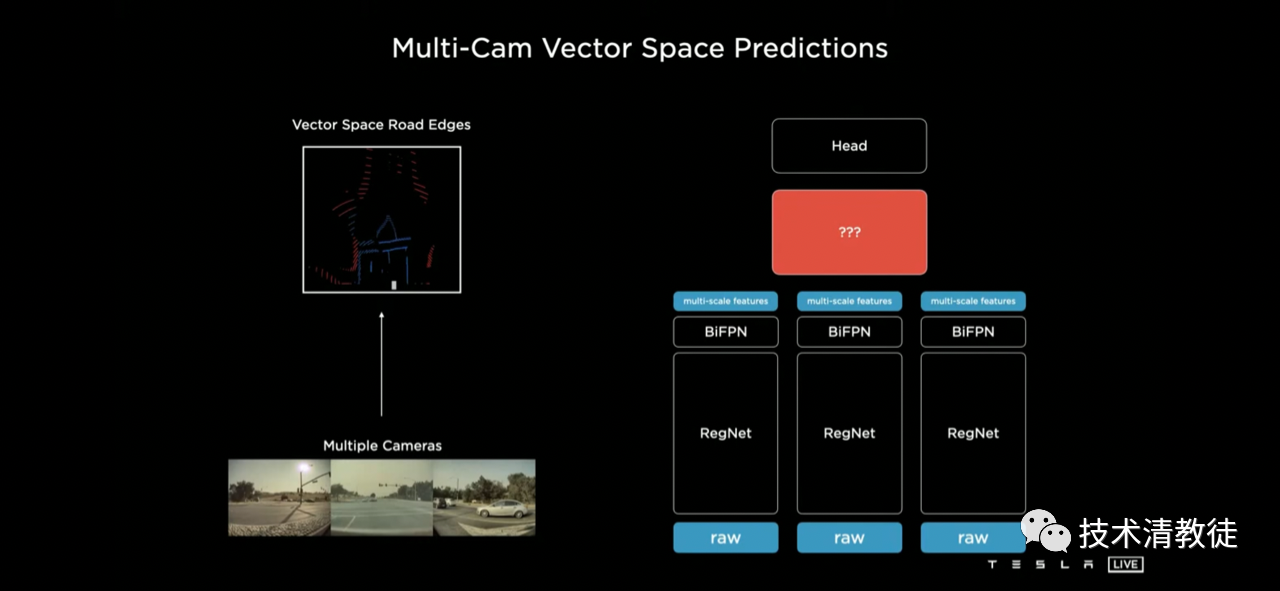
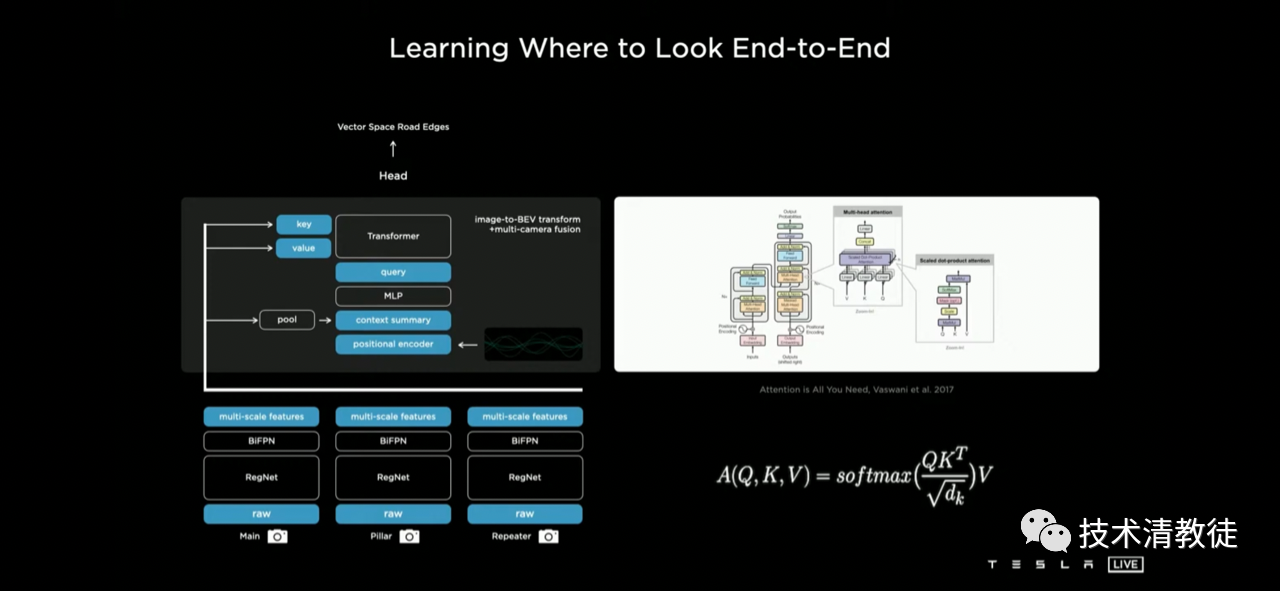
This recognition-first-then-fusion mode brought such a big “bug” to Tesla, which must be dealt with mercilessly. So Tesla came up with a solution, adding a conversion network for fusing features from multiple camera information libraries after completing the RegNet and BiFPN neural network extraction, fusion, and prediction.
 Translate the following Chinese Markdown text into English Markdown text, in a professional way. Keep the HTML tags inside the Markdown, and only output the result.
Translate the following Chinese Markdown text into English Markdown text, in a professional way. Keep the HTML tags inside the Markdown, and only output the result.
In this operation, Tesla stitched together images from all cameras and completed multi-camera fusion.
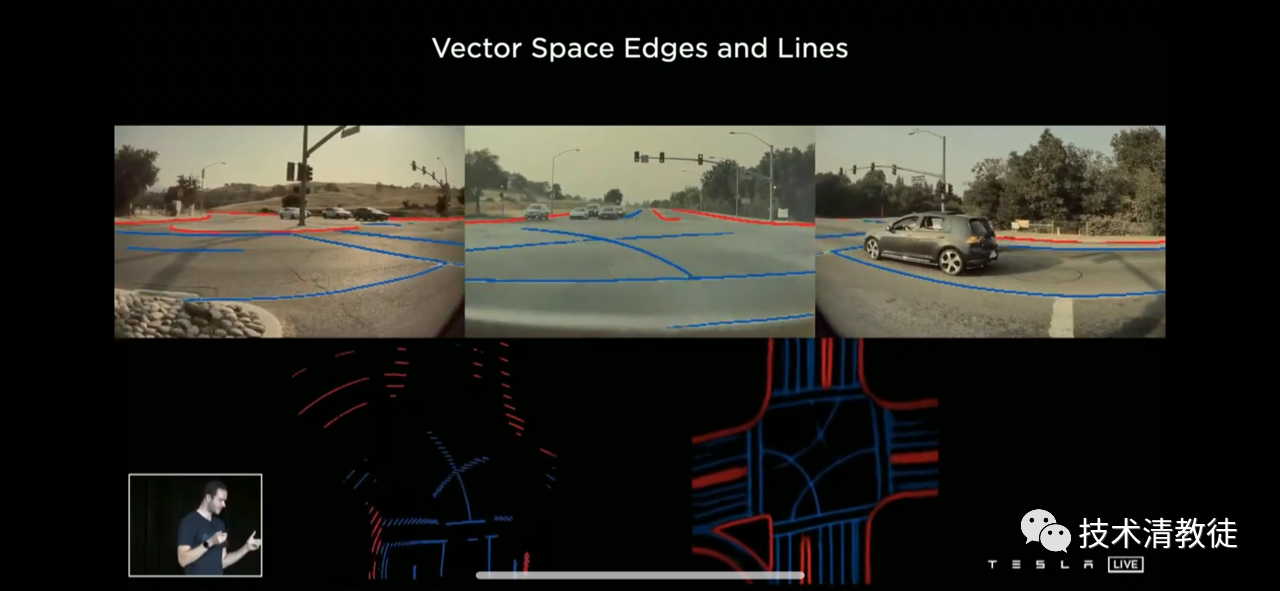
Compared with the pre-fusion (left-hand side of the figure below), the output quality of Tesla’s three-dimensional vector space has taken a huge leap forward after the camera fusion (right-hand side of the figure below).
Multi-camera fusion has also brought many advantages, as shown in the figure below, fusion can significantly improve the recognition of surrounding vehicle posture and location compared to a single camera.


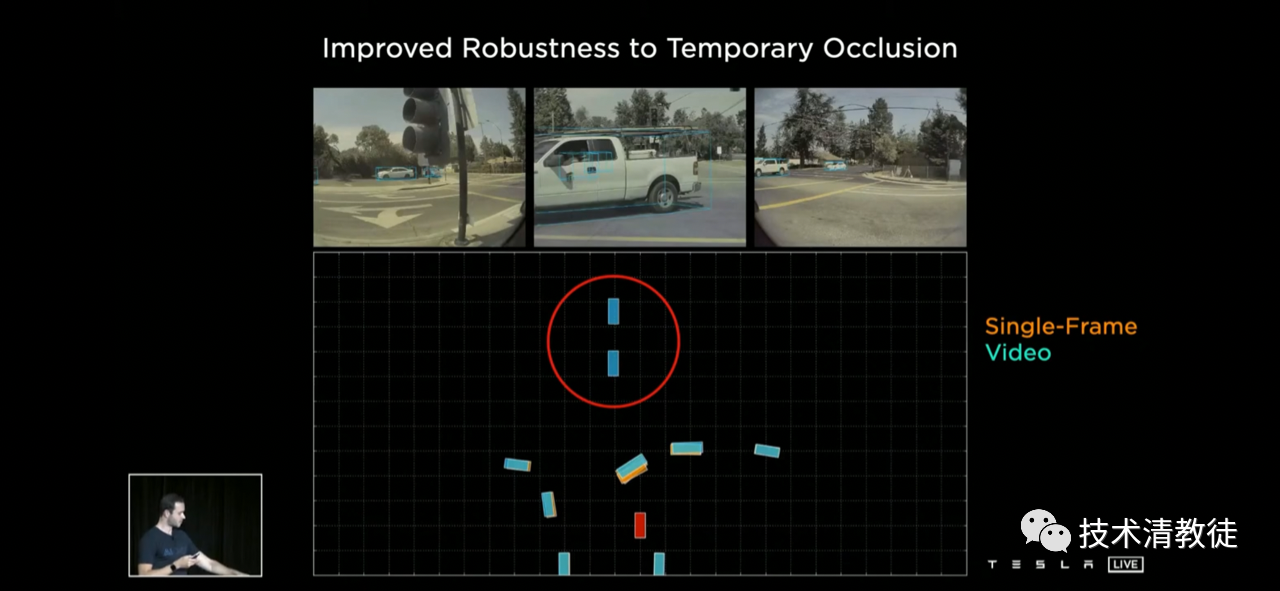
Then Tesla encountered the difficult problem of “forgetfulness”. Recognition that is based only on a single frame instead of continuous multiple frames will bring many problems.

Imagine that when the car is waiting for a red light, obstacles appear in front, and Tesla will briefly lose track of and trajectory prediction for oncoming vehicles. Once you lose track of and trajectory prediction for these key traffic participants, it is very likely to affect Tesla’s subsequent trajectory planning.
In order to solve this “amnesia”, Tesla made video-based recognition so that it can remember the position, speed, etc. of these vehicles before they are obscured, and make corresponding trajectory planning.
Also, when the car chooses a lane, it is often confirmed by the markings on the ground. However, these markings are not always in the line of sight. So it is necessary to remember them when you see them, so that you won’t forget whether the car is on the right lane.
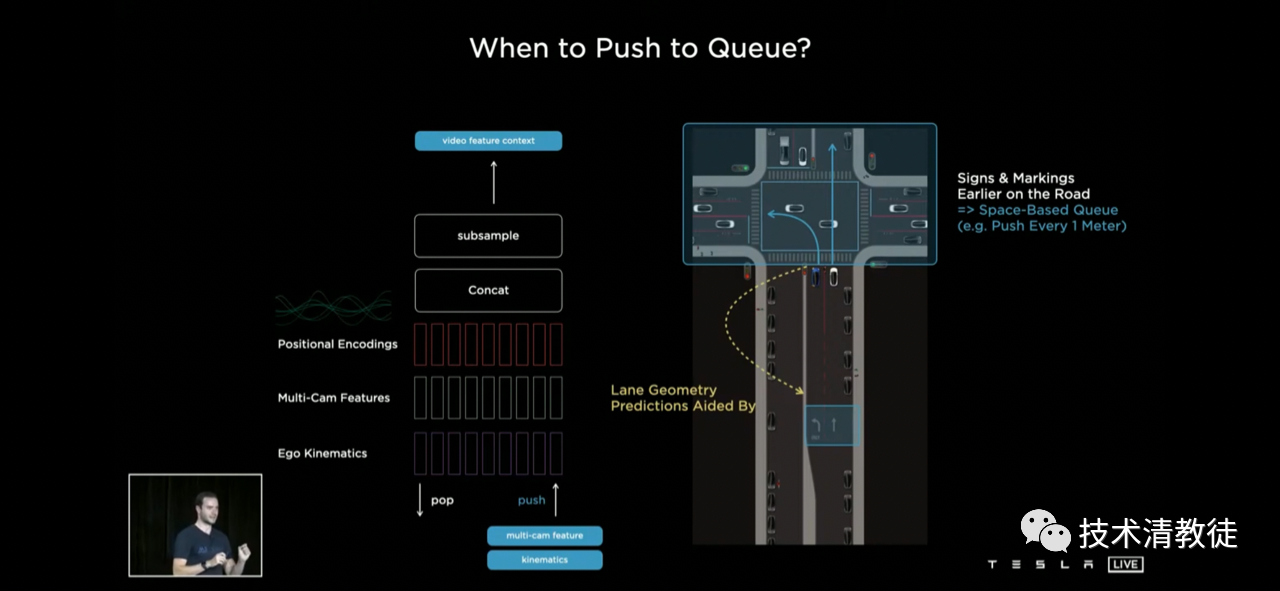 Special thanks to the HTML tags used in the original text. The English translation below retains all HTML tags and only provides corrections and improvements to the original text.
Special thanks to the HTML tags used in the original text. The English translation below retains all HTML tags and only provides corrections and improvements to the original text.
Tesla added “distance” as a measure of how long key clues should be retained, in addition to “time” as a measure of how long to retain them as milestones. This is mainly because it is possible to encounter traffic jams or red lights. If only the time is set, it is easy to “forget” these key clues due to waiting too long.
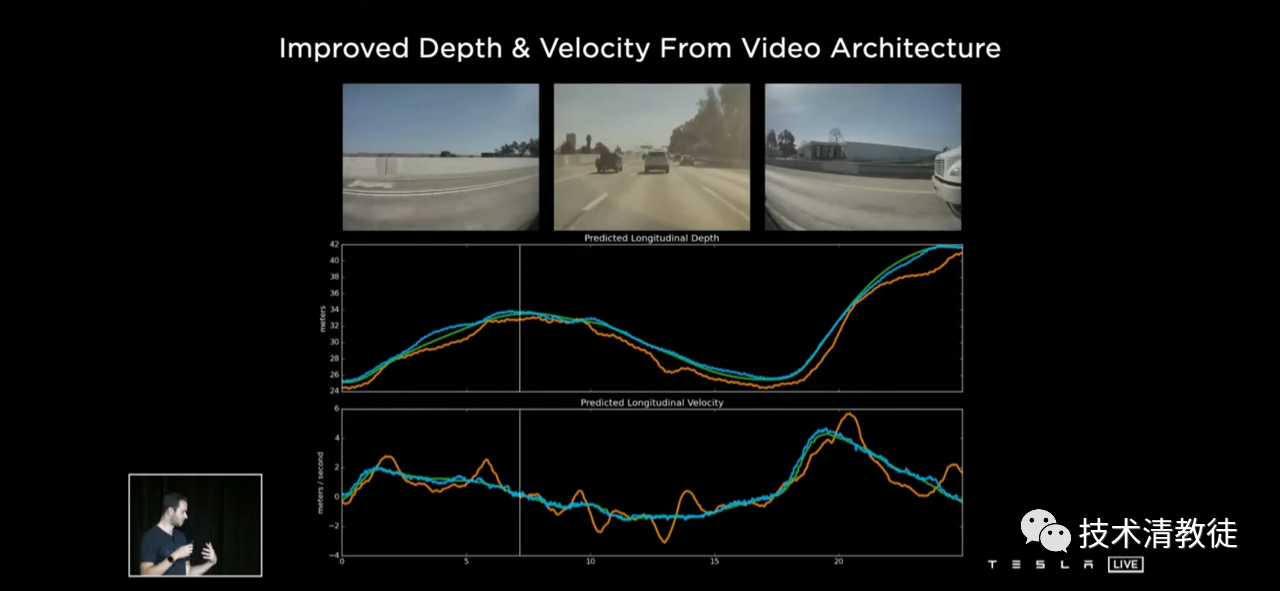
After “Remembering Events,” Tesla significantly improved the accuracy of the prediction of object distance and speed using this purely visual technology, essentially reaching the level of the version with millimeter-wave radar.
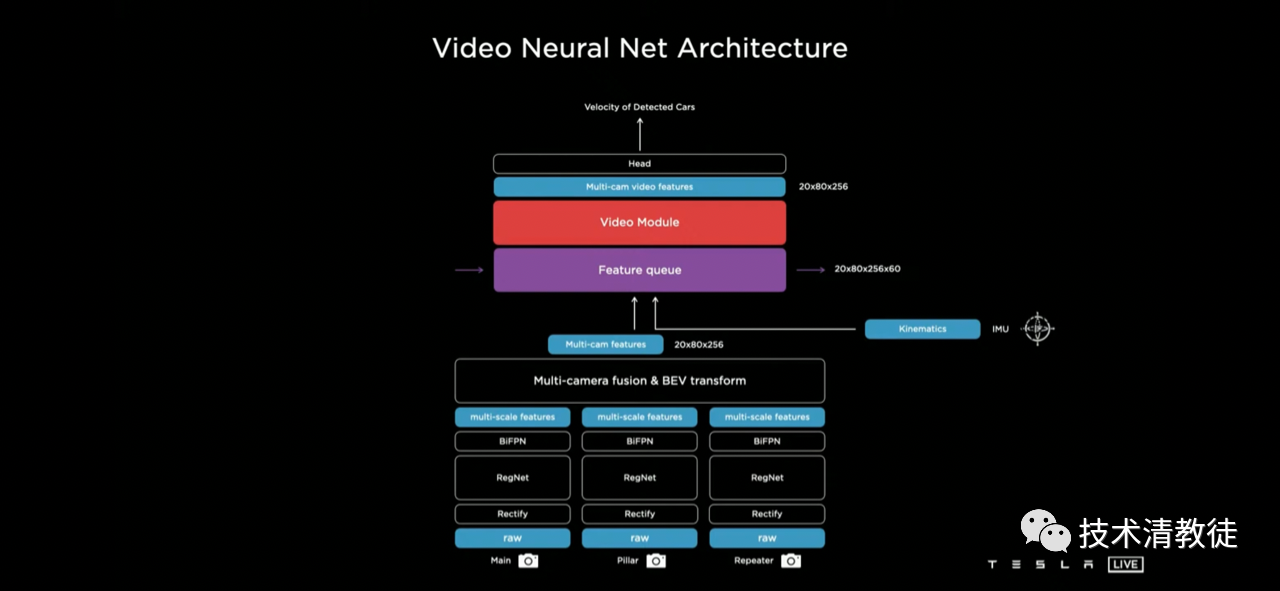
This is Tesla’s current complete visual neural network architecture: multi-camera fusion + 3D vector space conversion + key clue library based on time/distance + video sequence.
This is the foundation of Tesla’s pure visual ambition.
In today’s era, true leadership is not about who has the technology, but who can iteratively improve technology faster. Tesla’s almost unreserved display of its system architecture at AI DAY may precisely indicate Tesla’s confidence in its own technological iteration speed.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.