Some people say that autonomous driving has already solved 90% of the problems, but the remaining 10% are the most difficult to solve, including many edge cases, often referred to as Corner Cases. Edge cases generally refer to issues that have never been encountered before, and automated driving cars cannot cope with these issues due to the lack of data, as in the case of the child in dinosaur clothing in the image below.

There are also those who say that artificial intelligence, as wise as it is, is still only as good as the human intelligence behind it. This is because current deep learning technologies often use supervised learning, which is too reliant on large-scale annotated datasets, requiring a great deal of human effort to collect and label data. For autonomous driving, acquiring enough meaningful data through actual road testing is not an easy task.
These difficult problems now seem to have been solved with the support of the concept of self-supervised learning.
Recently, China’s autonomous driving company, Pony.ai, teamed up with scholars from Johns Hopkins University to use self-supervised learning to obtain motion information from unannotated laser point clouds and paired camera images, allowing for a better understanding of the movements of traffic participants without the need for labeled data.
Currently, this research has been included in CVPR 2021, an annual academic conference and one of the world’s top computer vision conferences.
Self-supervised learning is the biggest piece of the AI cake
Before introducing this achievement, let’s first take a look at what self-supervised learning actually is.
Supervised learning requires a large amount of annotated data and has long been criticized by the academic community. Jitendra Malik, a professor at the University of California, Berkeley, once said, “Supervised learning is the opium of the AI researcher.” And according to Professor Alyosha Efros of Carnegie Mellon University, “The AI revolution will not be supervised.”
Self-supervised learning solves the problem of supervised learning relying too much on large-scale annotated datasets by allowing for the learning of features from large-scale unannotated data without the need for any labeled data. It has currently been applied to natural language processing and computer vision fields.
Typical self-supervised tasks include colorizing black and white photos:

And turning blurry photos into high definition:
 # Applying Self-Supervised Learning to Lidar Point Clouds for Autonomous Driving
# Applying Self-Supervised Learning to Lidar Point Clouds for Autonomous Driving
Self-supervised learning is currently one of the most exciting directions in the field of AI. According to Yann Lecun, one of the three giants of deep learning, Turing Award winner, and Chief AI Scientist at Facebook, self-supervised learning is the most significant part of the AI “cake,” with supervised learning as the icing, and reinforced learning as the cherry on top.
When autonomous vehicles are in motion, real-time understanding of the movements of various traffic participants is essential for detection, tracking, prediction, planning, and other technical modules. Lidar sensors are one of the most commonly used sensors in autonomous vehicles. Consequently, it is a significant challenge to obtain information about the movement of other traffic participants from point clouds, as there are various categories of traffic participants, each exhibiting specific motion behaviors, and the sparsity of the lidar point cloud makes precise correspondence between two lidar scans impossible. Furthermore, the calculation must be completed within a short time limit and limited onboard computing power.
Traditional methods involve predicting traffic scenarios by identifying other traffic participants and observing their historical information. However, most identification models are trained to detect known object categories. In practical scenarios, there are often unseen object categories, which is not a sustainable long-term solution.
Another method involves estimating the 3D movement of each point in the lidar point cloud to obtain a scene flow. However, this approach requires high calculation requirements and is not practical for autonomous driving since it needs to be real-time.
The third method involves using bird’s eye view (BEV) representation, where the lidar point cloud is visualized into small grids, and each grid cell is called a voxel. The movement information of the point cloud can be described by the displacement vector of all voxels, which describes the movement size and direction of each voxel on the ground. This representation successfully simplifies scene motion since only the horizontal direction’s movement situation is considered, without paying much attention to the vertical direction. All critical operations in this method can be performed through 2D convolution, making the calculation speed exceptionally fast; however, this method depends on a significant amount of annotated point cloud data, and point cloud data’s annotation cost is higher than that of ordinary images.
These challenges have inspired researchers from RoboSense and Johns Hopkins University to explore self-supervised learning methods for lidar point clouds. An autonomous vehicle produces more than 1TB of data per day, but less than 5% of the data is utilized. Therefore, exploiting the rest of the data for learning, without manual annotation, would be incredibly efficient.
The self-supervised learning method for lidar point clouds is called “point cloud kinematics learning,” specifically designed for autonomous driving.As shown in Figure 1, to fully leverage the advantages of motion representation in battery electric vehicles (BEVs), the research team organized point clouds into pillars and referred to the motion information associated with each pillar as pillar motion.

The research team first introduced a point cloud-based self-supervised learning method assuming that the structural shape of either the pillar or object between two consecutive scans is invariant. However, this is generally not the case, as the sparce scan of the LiDAR results in a lack of exact point-to-point correspondence between consecutive point clouds.
The solution is to utilize the optical flow extracted from camera images to provide cross-sensor self-supervision and regularization. As illustrated in Figure 2, this design forms a unified learning framework involving interactions between the LiDAR and paired camera:
(1) The point cloud helps decompose the image motion caused by ego-motion from optical flow;
(2) The optical flow provides auxiliary regularization for pillar motion learning in the point cloud;
(3) The probability motion mask obtained by back-projecting optical flow enhances the consistency of point cloud structure.
Note that camera-related modules are only used for training and not introduced to add extra computations during inference.
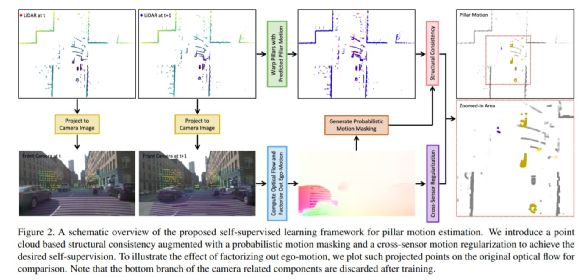
As shown in Figure 2, the proposed motion learning method closely couples self-supervised structural consistency of point cloud with cross-sensor motion regularization. The regularization involves decomposing ego-motion from optical flow and performing motion agreement between sensors. The research also introduces a probabilistic motion masking based on back-projected optical flow to enhance point cloud structure similarity matching.
The first learning paradigm for fully self-supervised point cloud voxel motion prediction
The performance of the research results needs to be verified by facts.
The researchers first conducted various combination experiments to evaluate the contribution of each individual component in the design. As shown in Table 1:

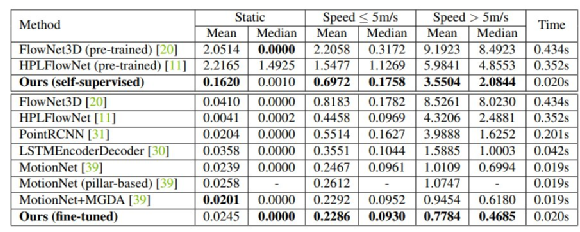
The research team compared their proposed method with various supervised algorithms in Table 3.
The proposed self-supervised model was first compared with FlowNet3D and HPLFlowNet, both of which were pretrained on FlyingThings3D and KITTI Scene Flow.
As shown in Table 3, the model proposed in this study was significantly better than these two supervised pretrained models.
Interestingly, this achievement was even better than or comparable to some fully-supervised training methods on benchmark datasets, such as FlowNet3D, HPLFlowNet, and PointRCNN.
When the self-supervised model proposed in this study was further fine-tuned using ground truth labels, the model achieved the state-of-the-art performance. As shown in Table 3, for fast-moving targets, the fine-tuned model outperformed MotionNet.
This suggests that the self-supervised model proposed by the research team provided a better foundation for effective supervised training, and the gain of self-supervised learning did not decrease with complex supervised training.
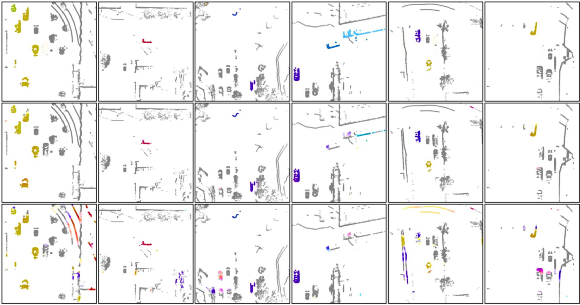
Finally, the experiments demonstrated the qualitative results of voxel motion estimation using different self-supervised combinations.
As shown in Figure 5, these examples present different traffic scenarios. Compared with the full model of this study, the basic model with only structural consistency loss tended to generate false positive motion predictions in the background region (the first and fifth columns) and static foreground objects (the second and third columns).Compared to the basic model, the complete model can produce smoother motion on moving targets (columns 5 and 6). In addition, as shown in column 4, the basic model lacks the moving truck in the upper right corner of the scene, but it can be reasonably estimated through the complete model. This again verifies the effectiveness of extracting motion information from camera images.
The research team achieved the required self-supervision by tightly integrating the laser radar point cloud and paired camera images, which is the world’s first learning paradigm that can predict point cloud column motion under a completely self-supervised framework.
Research Team
Both of the two main members of the research team are from Smarter Vision Navigation (SVM): Chenxu Luo is an SVM intern and a PhD candidate in Computer Science at Johns Hopkins University, while Alan Yuille is the Bloomberg Distinguished Professor in the Department of Computer Science at Johns Hopkins University.
SVM is a well-known company that emerged as a dark horse in the self-driving industry in 2020. In less than a year, it became the leader in the Robobus field. Last year, it launched the first 5G unmanned bus project for normalized operation in Suzhou, and it has now deployed unmanned bus projects on public roads in Suzhou, Shenzhen, Wuhan, and other places.
Aside from the impressive background of the founding team, SVM is also known for having other team members who are top talent from world-class companies such as Waymo, Tesla, Uber ATG, Ford, NVIDIA, and Facebook.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.