
Author: My name is Stephen.
This year, Tesla’s FSD section has made further progress on the basis of last year’s Bev perception (Hydranet) and put forward the occupancy network. Let’s take a closer look together.
Why Occupancy Network?
In LiDAR-based systems, the existence of objects can be determined by the detected reflection intensity, but in camera systems, neural networks must first be used to detect objects. What if you see an object that does not belong to the data set, such as a overturned truck? This alone has caused many accidents.

Some issues with the drivable area
There are some problems with the drivable area in the rv and bev spaces:
-
Inconsistent depth of the horizon, only about 2 pixels determine the depth of a large area.
-
Unable to see through obstructions, and unable to drive.
-
The structure provided is 2D, but the world is 3D.
-
In the height direction, there may be only one obstacle (hanging obstacles cannot be detected), and a fixed rectangle is currently set for each category of objects.
-
There are unknown objects, such as objects that do not belong to the data set.
Therefore, we hope to have a universal way to solve the problem. The first thing that comes to mind is the drivable area under bev, but relatively speaking, it will be more limited in the height dimension, so it is better to predict and reconstruct in 3D space in one step.
Occupancy Network## Occupancy Network in 2022 CVPR
The new head of Tesla FSD, Ashok Elluswamy, launched Occupancy Network in the 2022 CVPR. Inspired by the commonly used idea in the field of robotics, Occupancy Network is a simple form of online 3D reconstruction based on occupancy grid mapping. It divides the world into a series of grid units and defines which unit is occupied and which unit is empty. By predicting the occupancy probability in 3D space, it obtains a simple 3D space representation, using occupancy probability rather than detection, and supporting multiple perspectives.
Occupancy Network doesn’t output an exact shape of the object, but an approximation due to the limited computing power and memory, which is enough for most needs. In addition, it can predict between static and dynamic objects and runs at a speed of over 100 FPS (or three times that of the camera).
There are three core keywords in the Hydranet algorithm presented in the 2020 AI day: bird’s-eye view (BEV) space, fixed rectangle, and object detection. To see the optimization of the occupancy network for these three points:
Firstly, Occupancy Network deals with the bird’s-eye view. At the Tesla AI Day 2020, Andrej Karpathy introduced Tesla’s bird’s-eye network, which demonstrated how to put detected objects, drivable spaces, and other objects into a 2D bird’s-eye view. Occupancy Network, however, calculates the probability of occupying space.

BEV vs Volume Occupancy
The most significant difference is that the former is represented in 2D while the latter is represented in 3D.
The second difference is in the fixed rectangle. When designing perception systems, detection is often related to fixed output sizes. Rectangles cannot represent irregularly shaped vehicles or obstacles. If you see a truck and place a 7×3 rectangle on the feature map or a 1×1 rectangle if you see a pedestrian, the problem is that it cannot predict suspended obstacles. If there is a ladder on the top of the car or a trailer or arm on the side of the truck, the fixed rectangle may not be able to detect the target. On the other hand, using Occupancy Network can accurately predict these situations as shown in the image below.

Fixed Rectangle vs Volume Occupancy
The working principle of the latter is as follows:
-
Divide the world into small (or ultra-small) cubes or voxels.
-
Predict whether each voxel is free or occupied.

Occupied voxels in voxel space.Here are two completely different ways of thinking. The former allocates a fixed-size rectangle for an object, while the latter simply asks “Is there an object in this small cube?”
Thirdly, object detection.
Currently, many newly proposed object detection algorithms are mainly aimed at fixed datasets, which only detect part or all of the objects belonging to the dataset. Once an unmarked object appears, such as a white overturned truck or a trash bin appearing in the middle of the road, it cannot be detected. To address this issue, thinking and training a model to predict whether “this space is free or occupied, regardless of the object’s class” can avoid such problems.
Object detection vs. Occupancy Network
Visual-based systems have 5 main flaws: inconsistent horizon depth, fixed object shape, static and moving objects, occlusion, and body cracks. Tesla aims to create an algorithm to address these issues.
The new Occupancy Network solves these problems by implementing three core ideas: volume bird’s-eye-view, occupancy detection, and voxel classification. These networks can run at a speed of over 100 FPS, can understand moving and static objects, and have super memory efficiency.
Model structure:
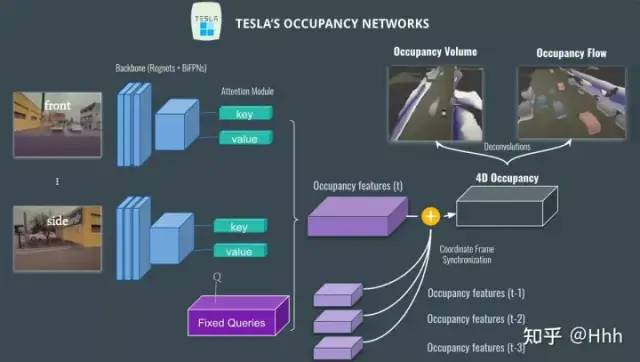
Network structure during the CVPR period.
-
The input is images from different perspectives (a total of 8: front, side, back, etc.).
-
The images are processed for feature extraction by networks such as Regnet and BiFPN.- Following the transformer module, the attention module is used to obtain features by applying position-image encoding with QKV to generate occupancy.
-
This produces an occupancy feature, which is then fused with previous volumes (t-1, t-2, etc.) to obtain a 4D occupancy feature.
-
Finally, we use deconvolution to retrieve the original size and obtain two outputs: occupancy volume and occupancy flow.

Network architecture at AI day
Compared with the presentation at CVPR, the AI day presentation is more detailed, with three main updates:
The leftmost part uses a photon count based sensor image as the model input (although it is touted as high-end, it is actually raw data before ISP processing). The benefit is that it can perceive a better dynamic range in low light or low visibility situations.
Temporal alignment uses odometry information to sequentially fuse occupancy features from previous time steps, with different time features having different weights. Then, it seems that the temporal information is concatenated in the channel dimension? The combined feature enters the deconvolution module to increase the resolution. In terms of temporal fusion, it seems to be more inclined to use a transformer or a temporal CNN that treats the time dimension as a channel for parallel processing, rather than a spatial RNN scheme.Compared to the approach of CVPR, in addition to outputting 3D occupancy features and occupancy flow (velocity, acceleration), Tesla also added a query idea based on x, y, and z coordinates (borrowed from Nerf), which can provide query-based sub-pixel, variable-resolution geometric and semantic outputs for the occupancy network.
Because Nerf can only perform offline reconstruction, can the generated occupancy hypothesis be supervised by using pre-trained Nerf to generate ground truth?
Optical flow estimation and Occupancy flow
What Tesla is actually doing here is predicting optical flow. In computer vision, optical flow is the amount of pixel movement from one frame to another. The output is usually a flow map.
In this case, the flow of each voxel can be had, so the movement of each car can be known; this is very useful for occlusions, but also useful for predicting, planning, and other issues.

Occupancy Flow
Occupancy flow actually shows the direction of each object: Red: forward – Blue: backward – Gray: stationary, etc. (there is actually a color wheel that represents each possible direction).
Nerf

Tesla’s NeRFNeural Radiance Fields, or Nerf, has recently swept through 3D reconstruction and has loyal fans among Tesla. Its initial idea was to reconstruct scenes from multi-view images (see 3D reconstruction course).
This is similar to occupancy network, but the difference here is that it is also performed from multiple positions. Drive around a building and reconstruct it. This can be accomplished by a car or a Tesla fleet driving around a town.
How are these NeRF’s used?
Since the occupancy network produces a 3D volume, these volumes can be compared to the 3D-reconstruction volumes (obtained through Nerf offline training) to compare whether the predicted 3D scenes match the “map” (NeRF produces 3D reconstruction).
There may also be problems during these reconstruction processes, such as image blurring, rain, fog, etc…. To solve this problem, they use fleet averaging (every time a vehicle sees the scene, it updates the global 3D reconstruction scene) and descriptors instead of pure pixels.
Using Nerf’s descriptor
This is how the final output is obtained! Tesla also announced a new type of network called the implicit network, whose main idea is similar: to avoid conflicts by judging whether views are occupied.
In summary:1. The algorithms based solely on visual systems currently have issues: they are discontinuous, do poorly with occlusion, cannot differentiate between moving and stationary objects, and depend on object detection. Therefore, Tesla has invented the “Occupancy network”, which can determine whether a cell in 3D space is occupied or not.
- These networks improve in 3 main aspects: bird’s-eye view, object categories, and fixed-sized rectangles.
- The occupancy network works in 4 steps: feature extraction, attention and occupancy detection, multi-frame alignment, and deconvolution, thus predicting optical flow estimation and occupancy estimation.
- After generating a 3D volume, NeRF (Neural Radiance Fields) compares the output with the trained 3D reconstruction scene.
- The average data collected by the fleet of cars is used to solve problems caused by occlusion, blur, weather, and other scenarios.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.