
Author: DeLuo
Recently, there has been a lot of discussion about autonomous driving technology, especially with two major events: the earlier held HAOMO AI DAY by Hema (Alibaba’s local services platform) and Tesla’s AI Day.
In terms of attention, Tesla AI DAY attracted global attention, while the influence of HAOMO AI DAY is gradually expanding. In terms of content itself, both companies are sharing their technological achievements and roadmaps, highlighting many common thoughts in technology that are worth our attention.
This is the main direction of our discussion today:
- What did Tesla and Hema’s AI DAY say about autonomous driving?
- Is there a division of so-called technical routes in autonomous driving?
- What are the points of convergence of advanced autonomous driving technologies among top-level companies?
A step from science to engineering
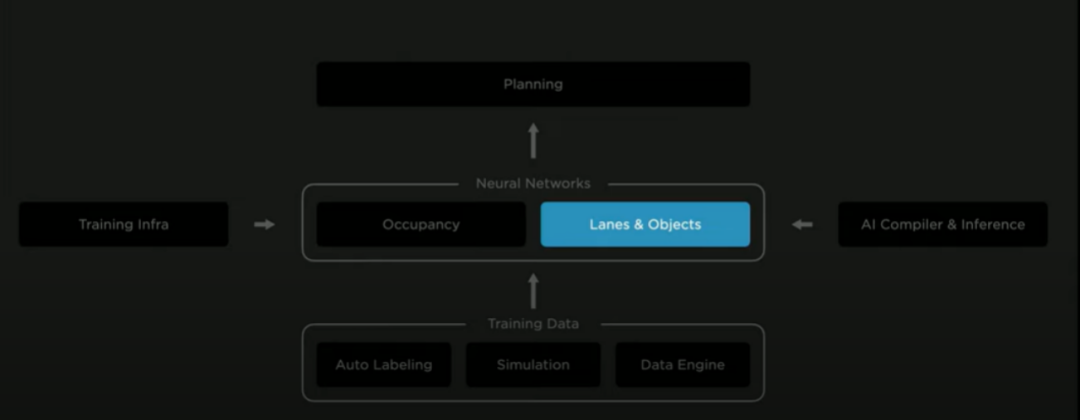
Tesla shared a lot of technical content at this AI Day, including robotics and autonomous driving. The latter covers perceptual and cognitive algorithms, data loops, chip design, supercomputing centers, and other content.
The first two are the core of the big model + data-driven route, while the latter two are the hardware carriers for this technical route. The following will focus on analyzing the algorithm and data aspects.
In terms of algorithms, the focus of this release was on the Occupancy Network, which came from last year’s BEV perception upgrade, and the improved lane and object detection networks based on it.
In terms of data, this release listed some progress that Tesla has made in automatic annotation, system simulation, and data engines in autonomous driving.
 ### Algorithm: Occupancy Network
### Algorithm: Occupancy Network
Review of BEV Perception
At last year’s AI Day, Tesla proposed the concept of multi-camera fusion perception, which also sparked a wave of research on BEV (Bird’s Eye View) perception in academia and industry.
BEV perception belongs to the feature layer fusion strategy in multi-sensor fusion. Its core idea is to transform the features generated by multiple sensors into a unified coordinate system, and then merge them together to complete the subsequent perception tasks.
The unified coordinate system here refers to BEV, which is the world coordinate system under a top-down view.
As shown in Figure 2, in the BEV coordinate system, the space around the vehicle is represented as a two-dimensional grid, and each grid corresponds to a region on the input image. In Tesla’s FSD pure vision system, multiple cameras are placed around the vehicle, with overlapping areas between the camera fields of view. Therefore, each BEV grid may have corresponding regions in multiple images.
The core task of BEV perception is to fuse the features from multiple images into the corresponding BEV grids.
Here, a method called cross-attention is used. The transformer network commonly used in Transformer networks uses self-attention mechanisms, which is to complete feature encoding through the correlation between input data itself.
Cross-attention describes the correlation between two different types of data, where the two types of data refer to data under image coordinates and BEV coordinates, respectively.
Upgraded Occupancy GridAt this year’s AI Day, Tesla showcased an improved version of its BEV perception called “Occupancy Grid Network,” which is a continuation of the BEV perception network, but with a focus on a three-dimensional grid instead of two.
By adding height information, the Occupancy Grid Network better describes the three-dimensional surroundings of the vehicle.
While BEV perception is typically used to identify various objects in a scene and detect lane lines on the road, the Occupancy Grid Network generates a three-dimensional description of the scene and provides semantic information.
Compared to sparse outputs like object and lane detection, the semantic information provided by the Occupancy Grid Network is more similar to the dense output of semantic segmentation in visual perception.
As shown in Figure 3, the three-dimensional space is divided into a grid structure, and the Occupancy Grid Network provides information on whether each grid is occupied by an obstacle. If it is occupied, the network also gives corresponding semantic information such as vehicles, pedestrians, and buildings. For movable objects like vehicles and pedestrians, the network can also provide their motion states.
Similar to BEV perception, the Occupancy Grid Network heavily relies on temporal information from multiple frames.
According to the presentation, temporal fusion first aligns the three-dimensional grids in space based on the vehicle’s motion information, meaning that the three-dimensional grids from multiple frames need to be unified in a common coordinate system.After unifying the coordinate system, grid features from multiple frames can be stacked together and the Transformer’s self-attention mechanism is used to extract features.
From a structural perspective, on the one hand, the grid network uses cross-attention to extract spatial information and fuse image data from multiple cameras; on the other hand, it uses self-attention mechanism to extract temporal information and fuse image data from multiple frames.
Both of these parts incorporate attention mechanisms, with large numbers of parameters and calculations, which is what we referred to earlier as a “large model”.
Why use the grid network?

Traditional object detection networks output bounding box information for various targets in the scene, which has two main limitations.
First, the target categories must be known, which means that the target categories must appear in the annotated training data.
In the real world, targets are varied and diverse, and building a comprehensive training dataset is basically impossible. For example, in road datasets collected in Europe and America, electric bicycles and tricycles are rarely included, so target detection networks trained on this basis will miss these targets on Chinese roads.
Even if data is collected on Chinese roads that include these target categories, there is likely to be significant variation in the same target category. For example, tricycles may have different shapes or transport different types of cargo, causing significant differences in target appearance, and making it difficult for the network to reliably identify these targets.
Obviously, if important targets on roads cannot be detected stably, the reliability of autonomous driving systems will be severely affected.The previously criticized white Tesla semi-truck accident was caused by the system failing to detect the semi-truck obstructing the center of the road, which is a scenario not commonly seen in regular road datasets.
Furthermore, some targets are difficult to represent with rectangular bounding boxes. For instance, articulated buses, when turning, have a shape that approximates a curve, and a rectangular bounding box cannot accurately describe its contour.
In addition, some irregularly shaped construction vehicles, such as vehicles with mechanical arms, have highly irregular shapes when performing work. If a rectangular bounding box is forcibly used to describe them, measurement errors can occur, leading to collisions.
Occupancy grid, which is a dense output at the grid level, can avoid problems caused by unknown object categories and rectangular bounding boxes.
Firstly, the occupancy grid output is whether each grid is occupied by an obstacle. Therefore, even if the obstacle category is unknown, the autonomous driving system at least knows that the position is occupied and cannot be driven through.
Secondly, if the grid resolution is sufficient, the occupancy grid can accurately describe the three-dimensional shape of an object, avoiding the problems caused by rough descriptions with rectangular bounding boxes.
The concept of occupancy grid used to frequently appear in perception tasks of millimeter-wave radar and lidar. Both sensors can directly obtain the scene’s three-dimensional information and are thus suitable for constructing occupancy grids to describe which areas are obstacles and which are drivable.
Visual perception is rarely used to generate occupancy grids due to its relative difficulty in obtaining depth information. However, based on multi-camera fusion BEV perception and an upgraded version of the occupancy grid network, three-dimensional information can be obtained directly from images captured from multiple angles through deep neural networks and attention mechanisms, resulting in an occupancy grid representation comparable to lidar.
In addition, because images contain rich color and texture features, the resultant occupancy grids contain more useful semantic information compared to those generated by lidar.### Algorithm Section: Lane Line and Object Perception
As mentioned earlier, three-dimensional scene features can be used not only to generate three-dimensional occupancy grids but also to enhance the perception of lane lines and objects. With reliable three-dimensional features, the detection of three-dimensional objects will naturally be more accurate, which goes without saying.
Next, let’s focus on the improvement of the lane line perception.
At last year’s conference, Tesla demonstrated how to use BEV perception to enhance the detection of lane lines, which had a very impressive effect. This is also one of the important reasons why the industry and academia have turned to research on BEV perception.
From this year’s conference, we can see that FSD’s lane line perception has adopted three-dimensional scene features, which can describe the changes in the ground undulation.
In addition, Tesla also uses lane line information from low-precision maps, such as topological relations, quantity, and width. Interestingly, in my interview with HaoMo CEO Gu Weihao and HaoMo Vice President of Technology Ai Rui, both of them mentioned “low-precision maps” and expressed some similarities between Tesla and HaoMo’s algorithms at the bottom level.
After encoding these information, they are fused with three-dimensional visual features and input to the Vector Lane model in the back end for processing. The highlight here is the use of the language model in the Vector Lane module, which provides excellent performance.Unlike most physical objects, lane lines can extend in space, and as a vehicle progresses, different portions/nodes of the lane lines enter the camera’s field of view in temporal order.
This data arrangement is very similar to the sentence structure in natural language, and the encoding-decoding structure in Transformers is designed to process such sentence structures.
As a result, it is natural and clever to apply this encoding-decoding framework to lane perception.
Path Planning based on Vector Space
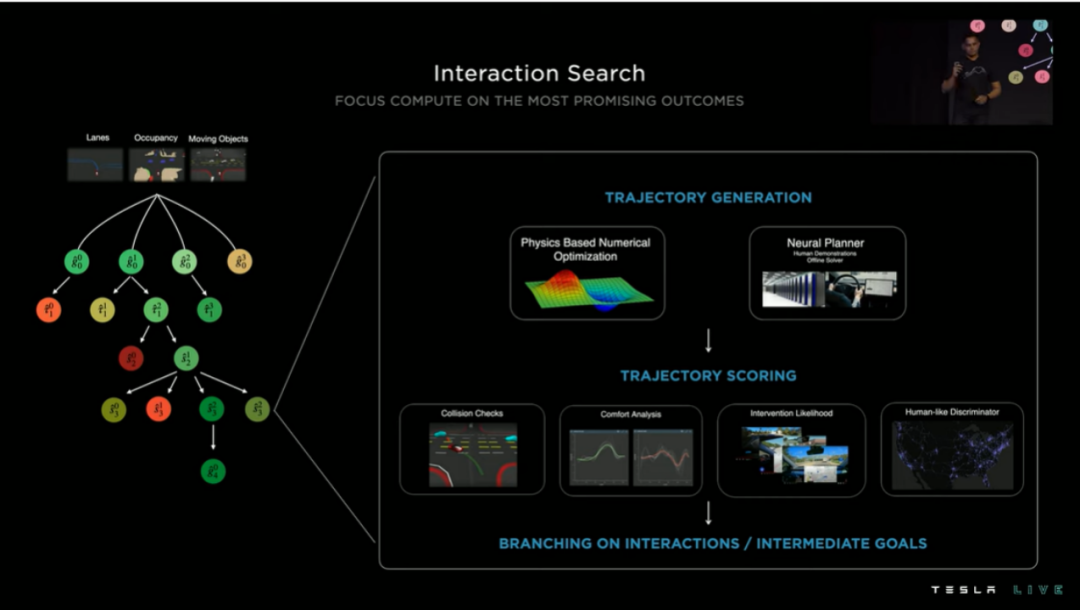
In contrast to the perception module, Tesla provides little detail about the cognition module. Based on the two AI Day presentations, Tesla’s main approach to path planning is to first obtain feasible trajectory spaces and then use various optimization methods to determine the optimal trajectory. The primary optimization method used here is the incremental decision tree search.
Based on the lane lines, target movement, and grid occupancy information obtained from the perception module, the planning system can generate a driving trajectory decision tree.
Using traditional constraint-based methods, which control the number of constraints incrementally, results in high time delay in complex road traffic environments.
Therefore, Tesla also uses a data-driven method that employs neural networks and training data from human drivers to assist in generating the optimal path.
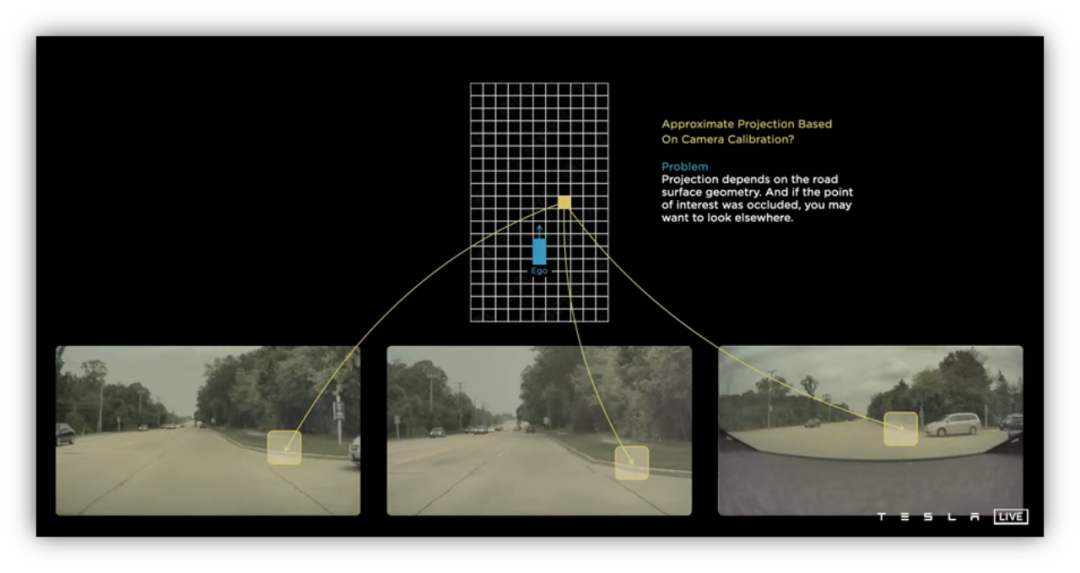
Additionally, Tesla’s path planning system considers the uncertainty of perception results in occluded/hidden regions. The occluded region is determined by the grid occupancy, which means that perception results behind occupied regions are uncertain and may include or exclude objects.Simply put, the planning system needs to consider the uncertainty of occluded areas.
For example, if a pedestrian suddenly appears from behind a vehicle, and their trajectory happens to overlap with the self-driving vehicle’s motion path, a collision accident is likely to occur if the planning system has not taken into account such a scenario.
To solve this problem, Tesla has introduced ghost objects — imaginary dynamic objects — in the occluded areas. The planning system is required to plan the safest driving path based on these hypothetical objects.
In the figure, the blue area represents the visible area where perception results are certain, while the gray area represents the occluded area where perception results are uncertain. Therefore, ghost objects need to be introduced in this area.
Data part
As shown above, machine learning methods play an important role in both perception and cognition modules. Long ago, there was a saying in the machine learning field: “Data is the King”.
In other words, data is crucial.
When I interviewed Dr. Ai Ruibo, the Vice President of Horizon Robotics, he also mentioned: “Using data for neural network training to iterate self-driving capabilities may be the most suitable practice and feasible approach currently. When Tesla switched to self-development in 2015, they decided on an algorithm architecture based on ‘data’ iteration, and when Horizon Robotics was founded, we also determined the model based on data iteration.”
In the era of deep learning, this view has been further strengthened. Without large-scale, high-quality data, neural networks cannot unleash their full potential.We have mentioned earlier that the large-scale network models based on Transformer and attention mechanism rely more on massive data, and solving the “long-tail problem” in autonomous driving also requires high-quality corner case data.
All of these points actually indicate that a data-driven system based on deep learning should be employed in autonomous driving systems.
Tesla’s data-driven system includes three main modules:
- Automatic labeling;
- System simulation;
- Data engine.
The data engine is used to efficiently collect valuable data, which is challenging scenarios data or corner case data. The collected data is quickly sent to the automatic labeling system to generate truth values for iterative neural network model training. The simulation system is used to test the network model and discover scenarios where it fails, updating the data engine’s collection strategy accordingly.
In this way, the three modules form a data feedback loop, which can quickly iterate and test neural network models. Not only Tesla, but many autonomous driving companies have made building high-quality, efficient data feedback loops one of their core competencies.
Now let’s talk about Momenta. Because Momenta’s executives have expressed their affirmation of Tesla’s autonomous driving technology several times in public, meanwhile also mentioning that they have learned a lot from Tesla’s techniques.
Therefore, let’s dive into some technical information about the 2022 Momenta AI DAY.
Momenta: “Having and using good data” is crucial
With the support of Great Wall Motors, Momenta also has inherent advantages in acquiring massive data.
Therefore, it is not difficult to understand that the two companies have very similar strategies in achieving autonomous driving, that is, adopting a progressive strategy, believing that assisted driving is the way to fully autonomous driving.
At the same time, with the background of providing massive data from production fleets, both Momenta and Tesla have adopted the big model + data-driven approach.
Although the technical approach is similar, the explorations made in this direction by the two companies are distinctive.It is well known that Tesla’s FSD currently uses a pure vision mode, which aims to fuse data from multiple cameras into a unified BEV coordinate. Of course, BEV perception has been upgraded to a three-dimensional occupied grid network this year.
On the one hand, this network can provide a three-dimensional description of the scene; on the other hand, it can also enhance lane detection, target detection, and subsequent path planning.
Tesla previously proposed the concept of software 2.0, which transformed the architecture of the autonomous driving system into a data-driven mode, allowing the system to constantly improve its capabilities based on data scale.
At this year’s AI DAY, Huawei further proposed the concept of autonomous driving 3.0.
In addition to large models and data-driven methods, autonomous driving 3.0 also includes multi-modal sensor perception and explainable scenario-based driving knowledge.

In order to meet the various challenges of autonomous driving 3.0, Huawei has conducted targeted research on algorithms and data under its MANA data intelligence system.
In terms of perception algorithms, similar to Tesla, Huawei also uses a temporal fusion BEV perception framework but employs lidar for multi-modal sensor fusion, and enhances perception capabilities by using interactive interfaces in the human world.
Regarding cognitive algorithms, Huawei proposes to make the system learn scenario-based driving knowledge to make path planning more similar to that of human drivers.
In terms of data, Huawei uses self-supervised learning and incremental learning to improve the utilization efficiency of training data.
Next, we will introduce in detail from three aspects: perception algorithms, cognitive algorithms, and data-driven methods.
Perception Algorithms
Multi-modal PerceptionIn the current field of assisted driving, the strategy of “heavy perception, light map” has gradually been accepted by the industry, as the high cost of constructing high-precision maps and the inability to satisfy the requirements of practical applications for updates are too high.
However, the difference is that some companies didn’t design their technological architecture specifically for the so-called “heavy perception, light map” when they originally started, but changed it later after experiencing the difficulty of using high-precision maps, which brought many problems. The other part had a clear understanding of the heavy perception from the beginning, such as Tesla and Horizon Robotics.
The core of “heavy perception” is to enhance the ability of the perception system, and the solution adopted by Horizon Robotics is a multimodal fusion perception based on the Transformer large model.
This fusion perception actually includes three different dimensions: space, time, and sensors.
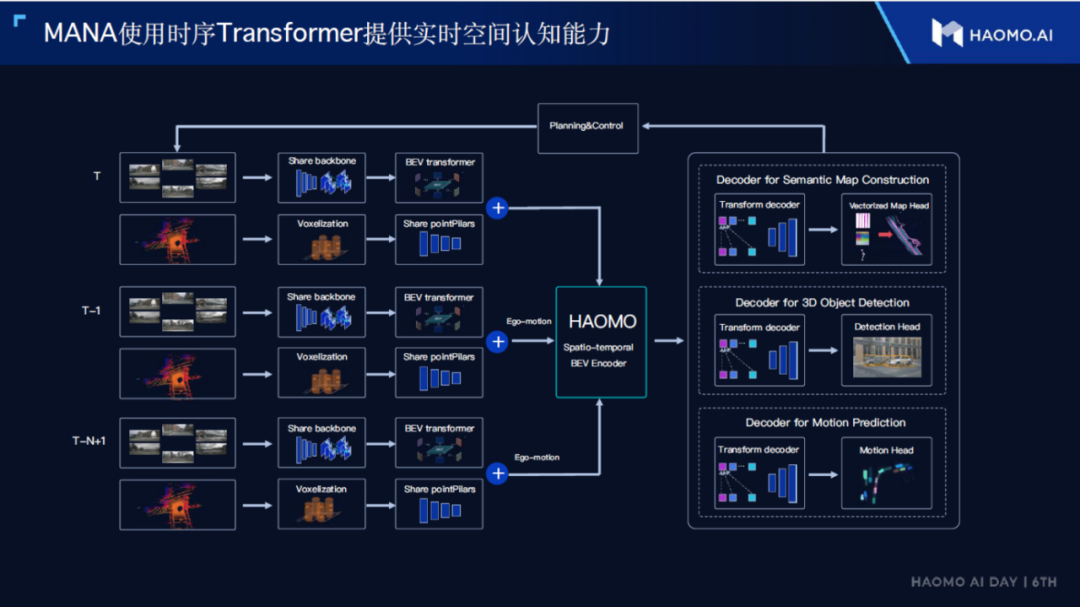
Space fusion mainly converts images from multiple cameras into a unified BEV coordinate system before performing feature layer fusion. This is basically consistent with the BEV perception that Tesla and the industry are currently focusing on, which can be referred to in the previous section on Tesla’s BEV perception.
Single frame information can be highly random, so temporal information is essential for autonomous driving perception. In BEV perception and Tesla’s latest proposed occupancy grid network, temporal fusion is also an essential link.
From the introduction at Horizon Robotics’ press conference, it seems that their temporal fusion also uses the vehicle’s own motion information to unify the spatial coordinate system of multiple frames, thereby fusing data from different times in a unified spatial coordinate system.
This is actually a solution the industry often adopts.
Another point is to utilize the interaction interface in the human world.We all know that in perception systems, vehicle detection is a very important part. However, a typical vehicle detection system only provides information such as the position, size, and speed of the target vehicle.
In addition, the target vehicle can actually provide more abundant information. When we are driving, the turning and braking information of the front vehicle can be judged through the signal lights.
Therefore, in addition to multimodal fusion perception, Hon Hai also proposed to use the interaction interface of the human world to enhance the ability of the perception system at the press conference.
For the perception system, it can also use this human world interaction interface to increase the amount of information obtained, which is very helpful for the assisted driving system in complex urban environments.

To achieve this goal, the most important thing is to stably detect the turn and brake lights of the front vehicle and determine their working status. It may sound simple, but in actual situations, this task is also very complex, because the shape and position of the signal lights of different vehicle models are very different, and the external weather and lighting conditions can also interfere with the detection of signal lights.
Cognitive Algorithm
In addition to safety, comfort is also a very important indicator for autonomous driving systems. In order to make the vehicle’s autonomous movement look more like human manipulation, cognitive algorithms need to learn common sense and humanize vehicle actions.
The input of the cognitive algorithm is the result obtained by the perception system, and the output is a series of actions such as accelerator, brake, and steering. In fact, while collecting perception system data, the driving actions of human drivers also provide the annotations needed by the cognitive system.
Therefore, we can train the cognitive system according to the driving habits of human drivers, so that the output action sequence is more humanized, thereby improving the comfort of the system.The sequences of actions, such as accelerating, braking, and steering, are very similar to multiple words in a sentence in natural language. Therefore, Maeimo proposes to use the popular Prompt model in natural language processing to handle these action sequences. Unlike perceptual models, the output of the Prompt-based cognitive model is interpretable.
For example, the model will give a clear semantic output indicating the need to overtake, before subsequent actions of accelerating and steering can follow. This is very convenient for system debugging.
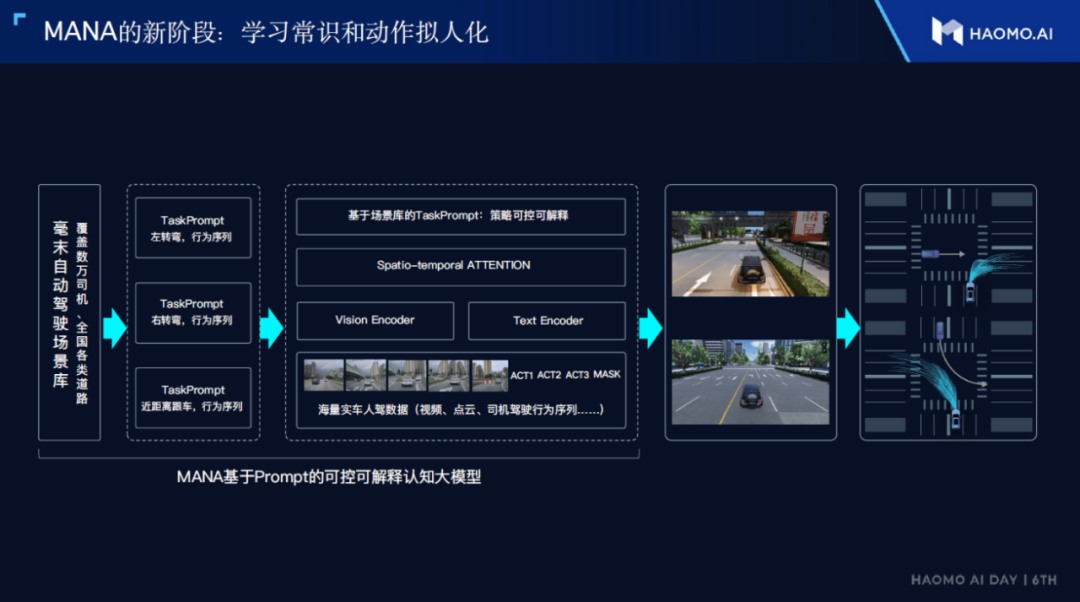
Data-driven
Large models require massive amounts of data support, especially data containing various complex scenarios. How to effectively use these data is an important task of the data-driven module.
In this section, Maeimo mainly introduces two aspects of work: 1. the use of self-supervised learning to effectively use massive data; and 2. the use of incremental learning to effectively utilize newly collected data.
Self-supervised Learning
The training of large models based on Transformer not only requires massive data, but more importantly, these data need to be marked. The mass production team makes it easier to obtain massive data, but after obtaining the massive data, it is more difficult to quickly and accurately mark this data.
Automatic labeling is, of course, a solution, and at the presentation of the data-driven part, Tesla also explained how to achieve automatic labeling. In addition to automatic labeling, Maeimo further proposes to use self-supervised learning to effectively utilize unmarked data.
We will use the visual perception system as an example to explain the working principle of self-supervised system.
Perception systems usually need to complete one or more specific tasks, such as obstacle detection, lane marking detection, traffic lights detection, etc.To better complete these tasks, neural networks need to learn how to extract corresponding visual features from images, similarly to the human visual system. Feature extraction in neural networks is a hierarchical process in which low-level features describe the basic attributes of visual data, such as shape, color, and texture. On the other hand, high-level features correspond to different tasks, for example, lane detection requires extracting white stripe-shaped features, while traffic light detection requires extracting colored circular features. Of course, this is just an intuitive explanation, and the actual feature extraction process is more complex.
In deep neural networks, low-level features are actually weakly correlated with the back-end tasks, and we can roughly consider them as independent of specific tasks. Therefore, we can use an auxiliary task to learn how to extract these low-level features from unannotated data. Auxiliary tasks are generally some reconstruction tasks, i.e., the original image can be approximately reconstructed through the extracted low-level features.
What we adopted in this study is 3D scene reconstruction as an auxiliary task, learning universal low-level features from large-scale unannotated data with billions of samples. These features can describe the basic information of the 3D scene very well.
With these low-level features, we can conduct supervised learning on millions of small-scale annotated data. On the one hand, fine-tuning the main network that extracts low-level features is required for supervised learning. On the other hand, it is also used to learn the head network of completing specific perception tasks.
At this point, since low-level features only need to be fine-tuned, the limited annotated data can be more efficiently used to complete the learning of the head network.
By mixing self-supervised learning and supervised learning, the training efficiency of neural networks can be increased by at least 3 times, and the accuracy can also be greatly improved.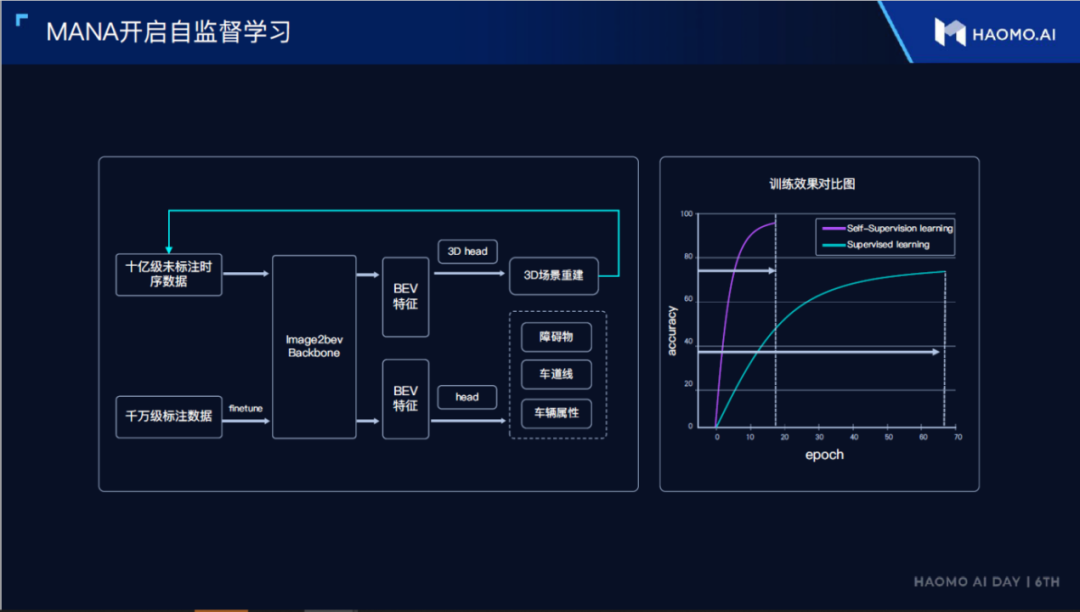
During the press conference, Tesla proposed that there is a big difference between the data utilization in the industry and academia.
Academia usually adopts a fixed dataset and improves the system accuracy by refining the algorithm, while the industry continuously increases the amount of data through closed-loop data feedback and improves the system accuracy through data-driven approaches.
Therefore, a challenge in the industry is “how to effectively utilize new data to update the model”.

As shown in Figure 12, the broad definition of “new data” may include new data in general scenarios, invalid scenarios, and even newly added class labels (i.e., adding new tasks).
The best way to utilize new data is to add them to the original data and train the neural network model from scratch. However, the original data has a large scale, and the time and cost of complete training are too high, making it unrealistic in practice.
Therefore, Moji proposed to use incremental learning to more effectively utilize new data.
Specifically, this incremental learning is accomplished from both the data and model aspects.
Data Aspect
Random samples are taken from the original and new data, and coupled to meet the general distribution pattern of natural data.
The purpose of doing this is to “maximize the amount of information contained in the constraint of limited data scale”.
Model AspectTranslate the Chinese Markdown text below into English Markdown text in a professional manner, keeping the HTML tags inside the Markdown and only outputting the result:
New models are trained using the newly generated coupled dataset, and the various parameters of the new models are kept as consistent as possible with the old models. During the retraining process, the new model must consider two constraints simultaneously: firstly, to keep the output of the new model as consistent as possible with that of the old model; secondly, to fit the new data as closely as possible. The latter is usually more important in training, and using this incremental learning method can save up to 80% of the overall computing power.
As of 2022, the Mozi AI DAY has been held six times, and looking at these six times together, the architecture, perception, planning, control, and data of the entire autonomous driving system have been analyzed.
Why discuss Mozi and Tesla together?
First, Mozi itself highly recognizes Tesla; second, the two companies have many similarities in underlying technology.
From the press conference, it can be seen that Tesla and Mozi have many similarities in their technical approaches.
These can be summarized as follows:
- Strong perception model.
Powerful perception ability is the basic guarantee of the safety of the autonomous driving system. Tesla and Mozi both use Transformer big models in perception and employ BEV perception strategy for feature-level fusion of multiple sensors.
- Light map strategy.
From the demonstration videos shown by both companies, the results of spatially stitching the output of a strong perception model are already very similar to maps.
Although it is still difficult for the perception system to recover the topological relationships of various elements on the map, combining with ordinary navigation maps can provide this information very reliably.
Therefore, both Tesla and Mozi propose to add the topological relations in the navigation map after modeling the perception model to reduce the dependence on high-precision maps.
- Learning from NLP models.
From current perspective, the next breakthrough in the AI field is likely to be a universal neural network that can handle various modal data. This can be done because multi-modal data actually have some similarities in their underlying structures.The two companies have adopted models from the NLP field in the perception and cognition modules of their autonomous driving systems, such as Vector Lane used by Tesla in the lane perception part, and the Prompt model used by Momenta in the cognition module, due to the similarities in these areas.
Fourth, efficient model training.
The large size of the model and the data have resulted in a huge amount of computing involved in the entire training process. In order to quickly iterate network models in a data-closed loop, both companies have invested heavily in supercomputing centers and cloud-based training resources.
Fifth, simulation.
Training a large model requires big data. The important thing is not just the scale of the data, but also the ability to cover a variety of scenarios. Both Tesla and Momenta attach great importance to simulating the real world to rapidly test models, collect failure scenarios, and improve model iteration efficiency.
Conclusion
After years of research and practice, the development of autonomous driving technology has entered the “second half”. As the mysterious veil of the concept of autonomous driving gradually fades, the core focus of major players in the “second half” is how to land the technology or how to find a suitable business model.
Some people are skeptical of autonomous driving technology, mainly considering it from a safety perspective. Currently, the technology level cannot fully support L4/5 level fully automated driving systems, but if the system only assists human drivers in avoiding driving accidents and makes driving more comfortable, then I think no one would object.
This is like how nobody objects to using rearview mirrors and ESP (Electronic Stability Program) nowadays. On the contrary, they have become standard configurations for vehicles.
L2 level advanced driving assistance systems have already appeared on many mass-produced models, which brings profit to car companies and suppliers while also accumulating technology and data for higher-level autonomous driving.
Currently, some companies that are committed to L4 level systems are also entering the L2 level market, indicating that the gradual development strategy starting with advanced driving assistance systems is more pragmatic.Tesla and Huami, with the support of their mass production teams, have naturally adopted a gradual development strategy and a large-model + data-driven technology route.
Although there is a high degree of consensus in terms of development strategy and technology route, the two companies have made many different explorations and attempts based on actual application scenarios.
Looking forward to the future, more companies can join this mass production practice and steadily promote the development of autonomous driving technology, making everyone’s travel safer and more comfortable.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.