
Author: Zhu Yulong
At yesterday’s Tesla AI Day, Dojo, Tesla’s customized supercomputing platform, was introduced. It was built from scratch and used for training autonomous driving video data. Its two main purposes are: first, to be cheaper than commercial cloud computing; second, to be more powerful than commercial cloud computing. In a sense, Tesla is not competing with Jeff Bezos, so Tesla hopes to be on par with Amazon AWS by using online services to train models with less money and faster speed.
Tesla already has a large supercomputer based on NVIDIA GPUs. The new customized Dojo computer makes significant breakthroughs at the design level.

Dojo Exapod specifications: 1.1 EFLOP, 1.3 TB SRAM, and 13 TB high-bandwidth DRAM.
From the beginning of the design, consideration was given to deep neural network training at the hardware level. The transmission bandwidth from the chip to the unit and then to the data center is very extensive. By applying the Occupancy network to the Dojo system, a better matching between AI hardware and AI software is achieved, and the effects achieved in reducing latency and performance loss are extremely surprising.


The future roadmap of the Dojo supercomputer system is as follows:

Power and Bandwidth Design
1) Power SupplyIn the technical section, a high-performance and high-density (0.86A/mm²) and complex integration computing module needs a specially designed power supply, where the voltage regulation module can transmit a current of 1000A with ultra-high density, using multi-layer vertical power management materials for transition. The future goal of this design is to reduce the CTE by 54% and improve performance three times. Increasing power density is the cornerstone of improving system performance. Interestingly, Tesla has designed and updated 14 versions in 24 months.
In this power supply design, capacitance, clock, and vibration characteristics are fully considered.
- Soft terminals connect to capacitors to reduce vibration
- MEMS clock can have 10 times lower Q-Factor
- The next step is to optimize the switching frequency


2) Expandable System
The system set contains three parts: power, structure, and heat dissipation. The System Tray, which is the smallest unit, has parameters of 75mm height, 54 PFLOPS (BF16/CFP8), 13.4 TB/S (bandwidth per partition), and 100+ KW power.
Standard Interface Processor parameters: 32GB (high-bandwidth dynamic random access memory), 900 TB/S (TTP bandwidth), 50 GB/S (Ethernet bandwidth), and 32GB/S (4th generation PCI bandwidth).
High Interface Processor parameters: 640GB (high-bandwidth dynamic random access memory), 1TB/S (Ethernet bandwidth), 18 TB/S (aggregate bandwidth to tiles).## Dojo Software System
Objective of Dojo System: To solve the difficult problem of scaling constrained models.

The process goes from a single accelerator to forward and backward channels, an optimizer, and multiple copies running on multiple accelerators. When models with higher activation levels try to run through the forward channel, they often face the problem that the batch size suitable for a single accelerator is smaller than the batch norm surface. In this case, multiple accelerators are set to the synchronous batch norm mode.
High-density integration is applied to accelerate the computational constraint and latency constraint parts of the model. A fragment of the Dojo grid can be partitioned to run the model (as long as the fragment is large enough). Fine-grained synchronization primitives in the unified low-latency are used to accelerate parallelism across integration boundaries. Tensors are stored in RAM in the form of Chardon, and are replicated in real-time during the execution of each layer. Another data transfer for tensor copying and computation overlap, and the compiler can also recompute layers.
Below are English Markdown texts:


The Dojo interface processor corresponds to a 32GB high transmission bandwidth storage, 900TB data transfer capacity per second, and 50GB data transfer capacity per second of network bandwidth.

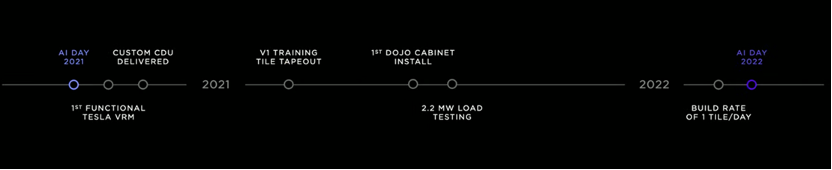
The following figure is the timeline of Dojo.

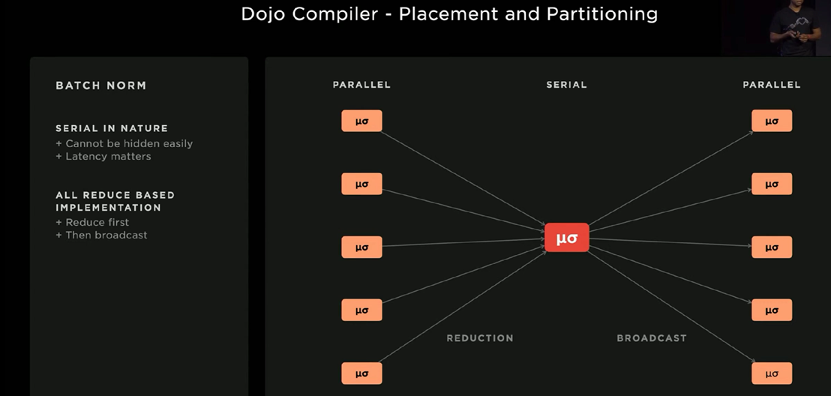
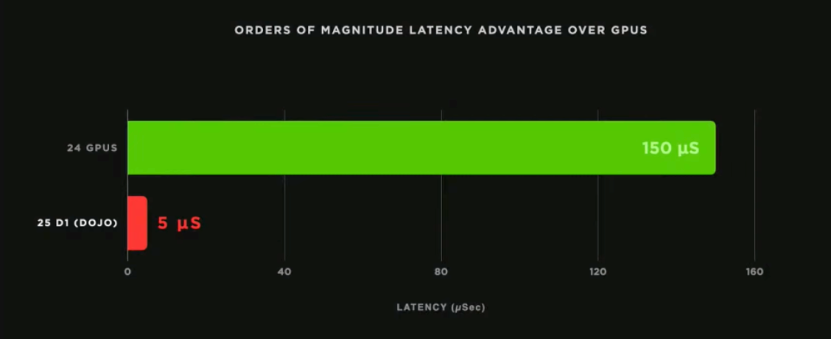
The compiler maps in a model-parallel fashion, starting with the communication phase that calculates local averages and standard deviations on nodes, and then proceeds in parallel. The communication tree is extracted from the compiler; the intermediate radiation reduction value is accelerated by the hardware; and this operation takes only 5 microseconds on 25 Dojo compilers, compared to 150 microseconds on 24 GPUs. This is an order of magnitude improvement over GPUs.
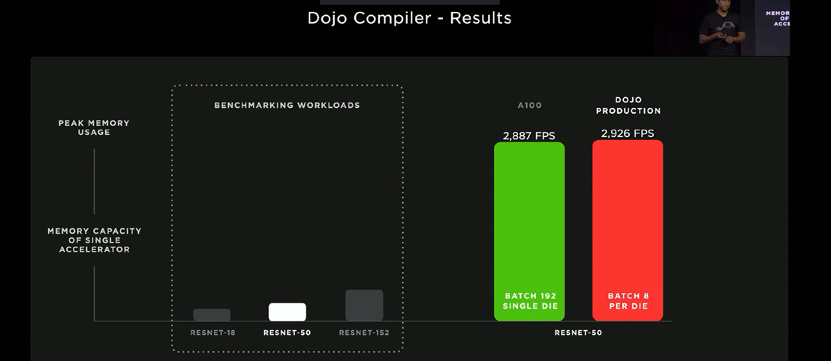
Dojo is designed to solve more complex models and is currently used in two GPU clusters:
- Auto-annotation network (used to generate offline models for ground truth)
- Occupation network (large-scale model with high arithmetic intensity)
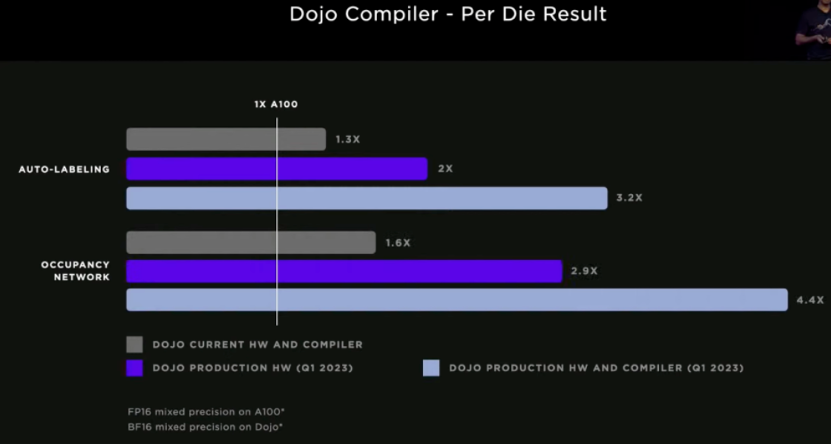
Test results: measurements on multi-mode systems show that the performance of GPU and Dojo exceeds that of any 100 older generation PRMS running on current hardware. The throughput of A100 doubled, and the key compiler optimizations achieved performance more than three times that of M100.
Currently, one Dojo can replace six GPU boxes for ML computing, and the cost is even lower than that of one GPU box. It now takes less than a week to train a network that previously took more than a month to train.
In conclusion: These pieces of information seem to be aimed at engineers worldwide, and provide many directions for technological development, somewhat similar to the mode of opening up patents, to attract young engineers.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.