
A Comparison Between Horizon and NVIDIA in the Field of Automotive AI Chips
Author: Zhu Shiyun
Editor: Qiu Kaijun
Both are in 2023.
On March 22, NVIDIA announced that BYD will produce cars equipped with the DRIVE Orin computing platform.
A month later, Horizon announced that the first fixed-point cooperation of the third-generation product Travel5 chip would settle with BYD.
The on-board time for the two collaborations is also 2023.
BYD is not the only automaker deploying both NVIDIA and Horizon. The Ideal ONE, on which Journey3 is mounted, achieves high-speed navigation driving assistance, while the latest Ideal L9 uses NVIDIA Orin. At present, the fixed-point companies of Horizon’s chips have reached 60, and it can be basically confirmed that NVIDIA is also among their customers.
Some comments believe that this is because Horizon is one of the few domestic AI chips with large computing power that has passed the vehicle-level regulations and is cheaper, so car companies choose it as a “low-cost substitute” for NVIDIA Orin and a supply chain security option.
This statement is not entirely unreasonable.
However, when Horizon was founded in 2015, NVIDIA’s chips had already begun to prepare for use in Tesla. How could a Chinese startup company enter the same procurement list with the AI chip king in just over six years?
More importantly, in the future, will Horizon only be NVIDIA’s “parity substitute,” or will it continue to catch up and become a real competitor in the field of automotive AI chips?
This article presents a comprehensive comparison between Horizon and NVIDIA to help you make a judgment.
Logic: Can AlphaGo drive a car?
If we talk about the widely known artificial intelligence (AI), AlphaGo is undoubtedly one of the most famous examples.
In 2016, Google’s Go AI “AlphaGo Lee” defeated the world’s second-ranked Korean Go player Lee Se-dol with a score of 4:1.

The characteristics of Go make it unsuitable for exhaustive algorithms. Compared with computing power, it requires more “intelligent” moves from players. Therefore, this “man-machine battle” became a milestone in the history of artificial intelligence: AI can be “smarter” than humans in some fields.
But can AlphaGo, the Go giant, drive a car?
The answer is likely no. AlphaGo, positioned as an AI in the Go field, mainly uses decision-making algorithms for reasoning tasks, and the type of neural network it uses may not be suitable for visual perception tasks.
To participate in the competition, AlphaGo required a computing power of approximately 4416 TOPS and consumed up to 10,000W of power (according to a DeepMind publication). Even a car with a 100-degree electrical power supply could only sustain it for 10 hours, not to mention carrying a server the size of a wardrobe.
Furthermore, during the game, AlphaGo had only two hours plus 180 seconds of thinking time, whereas a car has barely a second to think.
The inability to drive that AlphaGo demonstrated highlights the rigorous requirements that artificial intelligence/neural networks face in practical application. Unlike human intelligence, which has high versatility, artificial intelligence’s functional implementation is closely related to the application scenario, AI algorithm model, and deployment hardware.
It is this highly relatedness that provides a logical basis for Horizon Robotics to catch up with Nvidia.
Nvidia, standing on the cloud
Nvidia was the first company to create an appropriate “brain” for AI.
Founded in 1993, Nvidia invented the graphics processing unit (GPU) in 1999. Compared to a central processing unit (CPU), GPU architecture has many more arithmetic and logical units (ALUs) than cache and control units, making it suitable for computing-intensive and data-parallel operations.
Computing-intensive refers to a scenario where numerical calculations account for a significantly greater proportion than memory operations. As such, memory access latency can be masked via computation, reducing the demand for cache.
Data parallelism, on the other hand, means breaking down a large task into smaller ones that execute the same instructions, thus requiring less complex control flow.
AI machine learning is precisely this type of computation program: breaking down a complex problem into numerous, simpler ones and inputting massive parameters for computation. There is a low requirement for the order in which simple problems are solved, and the final overall result is output.
Moreover, GPUs require less storage and control space, allowing it to add more ALUs and increase computing power, eventually becoming the leader in “gigantic computing.”
However, running GPU programs efficiently is extremely challenging, and programmers need to “hack” into graphics API to allow the graphics card to think that it is conducting image rendering computations, thereby making programming difficult.
It wasn’t until 2006 when Nvidia released the CUDA™ parallel computing architecture that software-hardware decoupling was achieved. Developers no longer needed to use a complex GPU-specific programming language but could instead use a general-purpose programming language to call GPU computing power.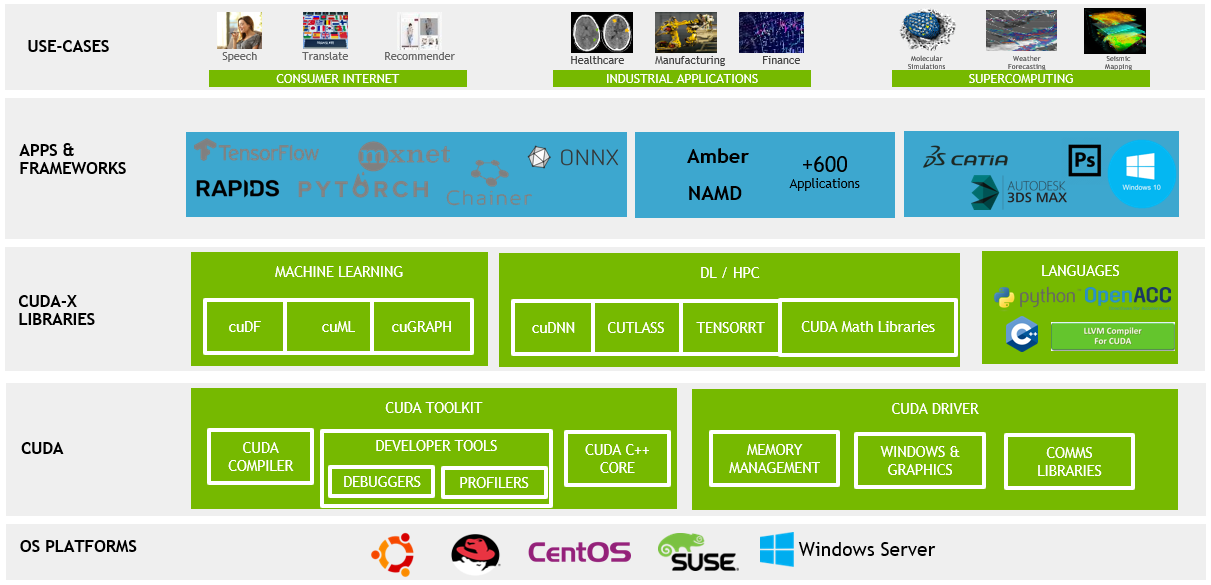
Thus, GPUs “emerge in a stroke” as a universal parallel data processing super accelerator, and NVIDIA, as a result, takes the center stage as the accelerator of the AI era.
On the one hand, workstations, servers, and cloud services equipped with NVIDIA GPU hardware provide software tool chains for machine learning and deep learning required for AI in the field, through the CUDA software system and developed CUDA-XAI library, serving numerous frameworks, cloud services, and other applications, thus driving the rapid development of AI.
On the other hand, NVIDIA has evolved from a pure chip manufacturer to an artificial intelligence platform company, gradually expanding its business to AI acceleration in the cloud, HPC (high-performance computing) high-performance computing, AR/VR (augmented/virtual reality technology), and other areas.
NVIDIA CEO Huang Renxun also stated after 14 years of accumulation in the CUDA ecosystem: “NVIDIA is not a gaming company, it will drive the next artificial intelligence explosion.”
But at least for now, NVIDIA is still a centralized cloud data center and gaming company in terms of its business structure.

On May 26th, NVIDIA released its Q1 financial report for the 2023 fiscal year (ending in March 2022), with revenue of $8.29 billion, a year-on-year increase of 46%. Among them, the data center business driven by ultra-large-scale computing, cloud, and AI accounted for 45.23%, and the gaming business supported by graphics cards accounted for 43.67%.
With cloud data center business as the core, NVIDIA’s core technology needs to serve this scenario.
However, there are fundamental differences in the computation methods of AI chips between cloud-side (servers, digital centers) and end-side (mobile phones, smart cars, etc.) scenarios.
-
First, cloud-side processing accumulates a large amount of data that arrives all at once (increasing batch size), while vehicle-side chips need to handle streaming data that arrives as the vehicle drives (over time);
-
Secondly, cloud-side processing can “wait” for enough data to arrive before processing, while vehicle-side chips need to complete calculations in real-time, minimizing delay and not waiting for even seconds;
-
Thirdly, in the cloud, tasks are limited to the virtual world and do not need to consider interactions with the real world. On the vehicle side, however, each task requires consideration of interaction since it is in the real world.
-
In addition, energy consumption and cost also play a more significant role in considerations for AI chips on the vehicle side.As can be seen, cloud-based AI chips focus more on data throughput and supporting various AI tasks, while on-board AI chips for cars are required to provide high computing efficiency and real-time capabilities, achieve edge-side inference, and meet requirements for low power consumption, low latency, and even low cost.
However, currently, the core GPU architecture of NVIDIA’s on-board chips is still cloud-based.
Orin was born from the Ampere architecture and is the main product architecture that drove nearly 90% growth in NVIDIA’s data center business in the first quarter. In other words, Orin, which targets high-level autonomous driving scenarios, has a computing module technology that competes with cloud data center scenarios.
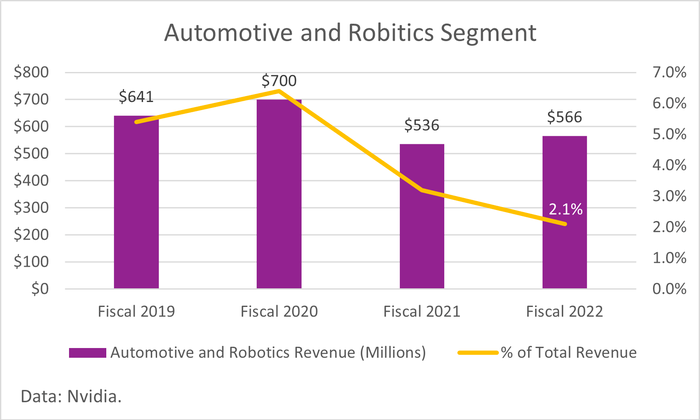
NVIDIA’s choice is understandable. Architecture is the core technology at the bottom of a chip enterprise, and the iterative cost is huge, so it is for the production of more profitable products. Although the automotive business has become an important part of NVIDIA’s Graphics Technology Conference, its revenue is still negligible – accounting for only 2.1% (fiscal year 2022).
Standing on the Horizon of “Edge-Side”
At present, Horizon’s core business is only on-board vehicles.
Horizon’s complete name is “Horizon Robotics,” and its founding scenario is the end-side scenario requiring real-time computation, designed for special end-side needs of all its products’ hardware and software architecture.
But “robots” were mostly in science fiction films until autonomous driving made cars the first outbreak of robots in the real world.
“A single” business structure allows Horizon’s technology to focus on “one” demand, while the explosion of demand for automotive intelligence provides a scaling basis for convergence of AI tasks from intelligent/autonomous driving scenarios, creating more expensive and targeted dedicated chips, thereby establishing a viable business model and attracting investors and professional “players”.
“**A general-purpose chip like GPU is very friendly to developers, but it is not the optimal solution for commercial competition, **” a chip industry expert told the Electric Vehicle Observer: “Horizon uses a methodology of software-hardware integration for specific scenarios to design chips, that is, domain-specific architecture (DSA) chips, which greatly improves the effective computing power of chips.“
Decoupling of software and hardware and turning the specialized GPU chips for graphics processing into general-purpose chips for large-scale parallel computing enables NVIDIA to stand at the C-position of the AI era.
The first step taken by Horizon to catch up with NVIDIA is software-hardware integration.Horizon has repeatedly emphasized the core methodology of combining software and hardware in its public appearances, putting the end first:
- Always evaluate each module from the perspective of the system (starting from the entire system of AI models, toolchains, and development tools, and looking at the layout logic and utilization efficiency of every subtle space on the chip);
- Always use future predictions to guide current choices (based on the trend of automatic driving AI algorithm evolution, guiding the direction and trade-offs of current technical research and development).
The Horizon chip development process can illustrate how the software and hardware integration method is implemented.
Horizon has an AI model performance analysis tool. Firstly, a testing benchmark containing rich algorithm models that represent future trends is selected. It is then run on the modeling tool of the Horizon BPU architecture to test the computing performance of the architecture on the algorithm models. Based on this testing benchmark, the compiler, model quantification tool, and training tools at the software layer are explored.
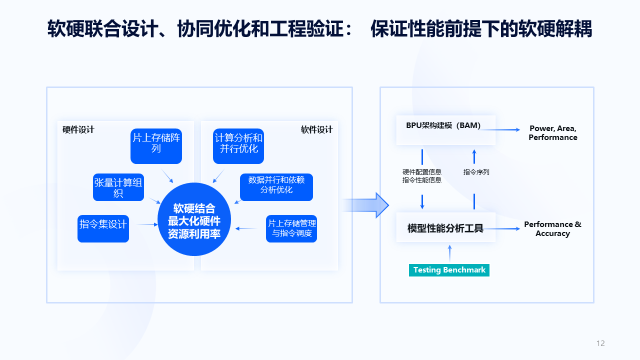
Since there is a time lag of two to three years from chip design to final application, such a workflow helps Horizon to guide hardware architecture design with software algorithm trends in advance.
“Lots of designs in the second and third generation chips, such as those achieved by Horizon with a shipment of millions of chips, had already considered the trend of some relevant algorithms in 2016 and 2017,” said Ling Kun, Senior Director of Horizon R&D.
Architecture: Everything for Faster Performance
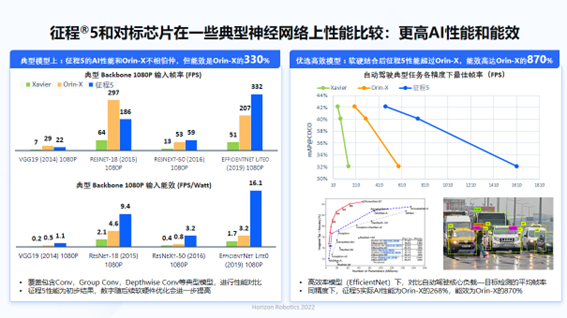
The logic is one thing, the technical implementation is often another. Whether Horizon can obtain NVIDIA’s customers depends on data.
The single-chip computing power of NVIDIA’s Orin and Horizon Journey 5 are 256 TOPS and 128 TOPS respectively. The power consumption of Orin is 55W and that of Horizon Journey 5 is 30W. The power consumption ratios are 4.6TOPS/W and 4.2TOPS/W, respectively.But when comparing the frame-per-second (FPS) rates of the Orin and the Horizon Journey 5 on two platforms testing automatic driving AI, the Orin achieves 1001 FPS while the Horizon Journey 5 with half the computing power achieves 1283 FPS (the Orin data is adjusted by Horizon based on NVIDIA RTX3090 with the same Ampere architecture). “In terms of energy efficiency, we (Horizon Journey 5 compared to Orin) have more than a sixfold improvement,” said Luo Heng, the chief algorithm engineer of Horizon BPU.
In the intelligent/automatic driving scenario, vision is still the most crucial perception route and the core mission that intelligent/automatic driving AI faces: “what do I see.” Thus, FPS is considered one of the evaluation standards for the computational platform’s efficiency when running advanced algorithms for all automatic driving applications.
In 2017, when Tesla released its proprietary FSD chip, founder Elon Musk compared it to the NVIDIA Drive PX2 used before. In terms of computing power, FSD is three times that of Drive PX2, yet when executing automatic driving tasks, its FPS is 21 times that of the latter.
GPU’s specialty is image recognition. Why does NVIDIA’s Orin perform less than half the computing power of the Horizon Journey 5 in the test? Part of the core reason is the difference in the design goals between Ampere and Bayes architectures.
From the physical world’s perspective, chip architecture works on the inch level (currently mainstream mass-produced car-level chip size is 40nm-5nm): how to arrange operators, memory, and communication lines between them in a limited space. Different calculation requirements will result in different array modes.
NVIDIA the Overachiever
Data center scenarios mainly include high-performance computing (HCP) and deep learning. Chip architecture based on these aims must be able to support various AI model tasks and consume a tremendous amount of data within a limited time. Like an overachieving student who excels in history, philosophy, mathematics, and science and can complete 30,000 papers in a day, NVIDIA has pursued high scalability as its core goal from Pascal to Ampere architectures:
-
Supporting as many types of neural network structures as possible to ensure algorithm accuracy and generalization ability;
-
Supporting floating-point operations that can recognize a wide range of numbers to ensure the vast data throughput;
-
Supporting an array structure to connect more processing units to further increase the data’s calculable scale.When it comes to hardware technology, a series of innovative technologies, such as Tensor core and CUDA core, which are parallel and cover a data precision range from INT1 to FP64, have been developed to support the above goals.
In 2017, NVIDIA’s Volta architecture was unveiled, with its core centered on deep learning, and it introduced the Tensor core that runs in parallel with the CUDA core.
Tensor is a mathematical concept referring to a multidimensional array, ranging from 0 to 5 dimensions, and it is considered the foundation of modern machine learning, acting as a container for data.
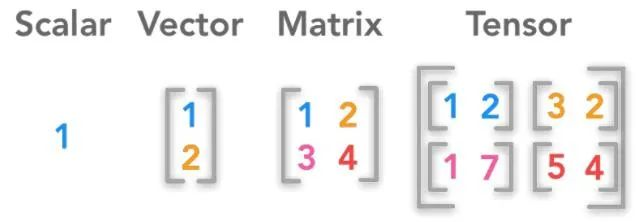
In the early stage of machine learning, which mainly focused on logical models, learning tasks were simple, and learning materials could be structured as two-dimensional charts. However, deep learning in the neural network model stage requires not only finding a blue flower from a bouquet but also finding a cat from an image library. Teaching materials turned into unstructured data, requiring at least three-dimensional tensors to represent single image data, and the dimensions of speech and video data are even higher.
Multiply Accumulate (MAC) operation in conjunction with multidimensional tensor design matches the computation array and neural network model operation mode, becoming the core operator type of AI chips.
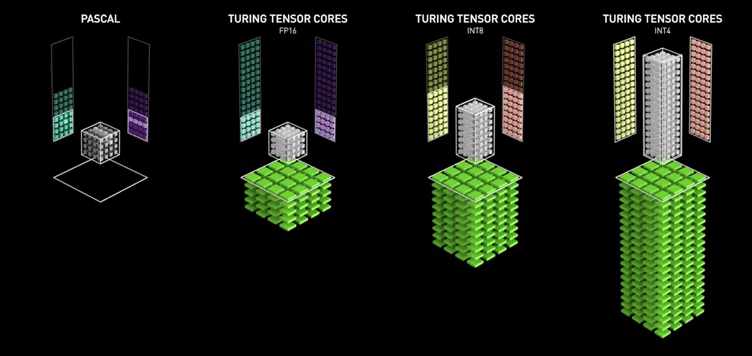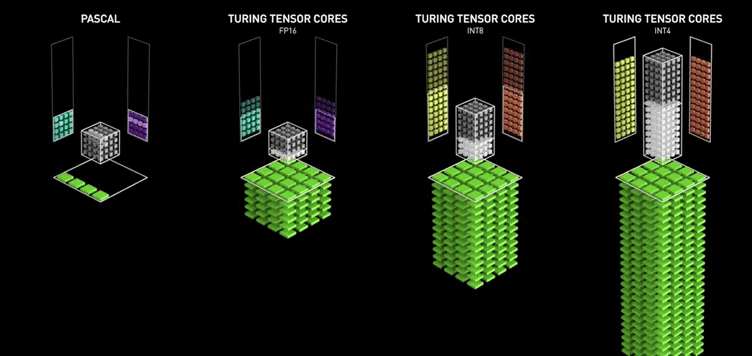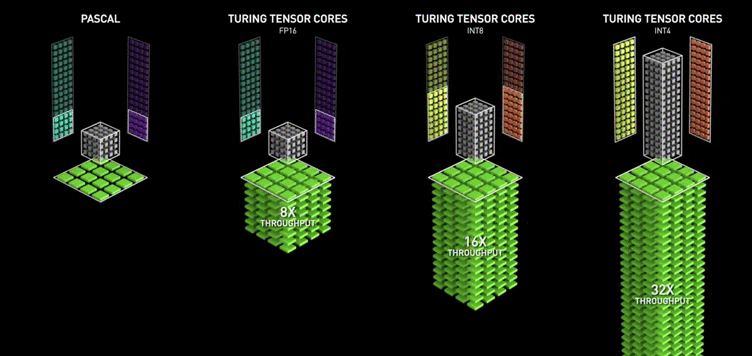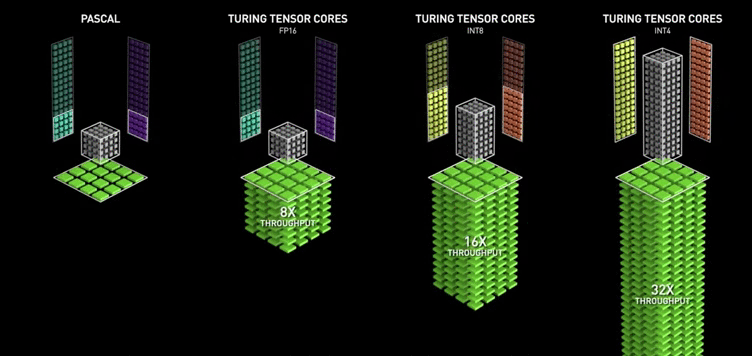
Google introduced the Tensor Processing Unit (TPU) in 2015. In 2017, NVIDIA added the MAC array to the Volta architecture completely oriented towards deep learning and named it “Tensor Core.”
For NVIDIA, which is involved in various businesses such as data centers, graphics cards, and cars, both CUDA Core and Tensor Core are useful.
In each GPU clock cycle, CUDA Core can execute up to one single-precision Multiply Accumulate operation, which is suitable for deep learning of AI models with consistent parameters and high-precision high-performance computing.
However, for AI models, the weights of the model parameters are different, and if all are calculated with high precision, it takes a long time and consumes a lot of memory. On the other hand, if all the weights are reduced to low precision, the output results have a large error.
Tensor Core can achieve mixed precision: executing one matrix multiplication accumulate operation for every one GPU clock cycle, with the input matrix being FB16, and the multiplication result and accumulator being FB32 matrices.Although mixed precision sacrifices training accuracy to some extent, it can reduce memory usage and shorten the model training time.
While expanding operators that adapt to various computational needs, NVIDIA is also constantly expanding the supported floating-point precision of the operator.
CUDA cores have increased their computing capabilities for FP64 and INT32 on top of the most mainstream FP32. Tensor cores support various data precisions, including FP16, INT8/INT4/Binary, TF32, BF16, and FP64.
To what extent is this diversification?
FP64 has a complete 15-17 digit decimal precision, which is primarily used in high-precision scientific calculations such as medicine and the military, and is usually not used for deep learning calculations. TF32 has even become a new mathematical mode within NVIDIA’s GPUs.
The Horizon of Talent
But is this high scalability and richness essential for autonomous driving AI?
In 2018, NVIDIA launched the Soc (system-on-chip) Xavier, which uses the Volta architecture GPU and can perform high-level autonomous driving tasks. According to NVIDIA’s definition, XAVIER is a computing platform designed specifically for robots and edge computing and uses TSMC’s 12nm process.

By comparison, Tesla FSD uses Samsung’s 14nm process and only has half the computing power of Xavier in terms of the GPU. But in terms of area, XAVIER is slightly larger than FSD.
Behind this is the architecture used in cloud scenarios, and the difference in chip layout between a brand’s demand and a car-side architecture that is completely benchmarked against that demand.
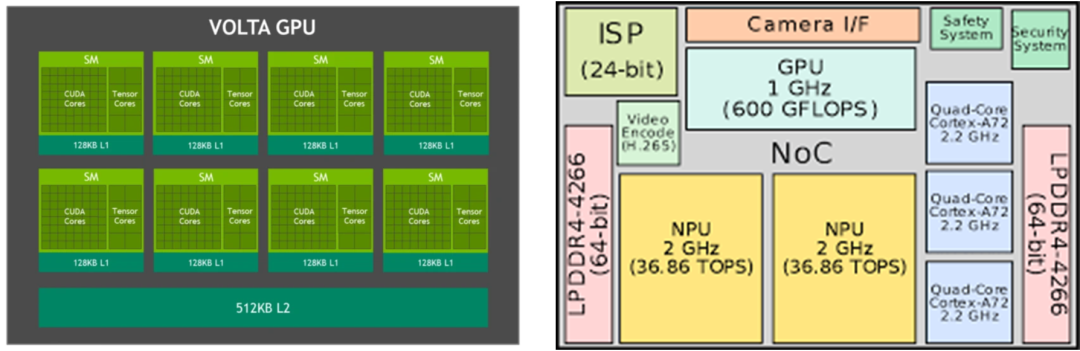
Upon closer inspection, the Volta GPU integrated in Xavier provides 512 CUDA cores and 64 tensor cores. By contrast, the GPU responsible for general floating-point calculations in FSD has an area much smaller than its MAC array NPU.
From a demand perspective, the FSD chip only needs to run Tesla’s autonomous driving AI, so the MAC array that completely benchmarks the deep learning requirements occupies more on-chip space.For Volta GPU, in addition to real-time inference as the top priority for edge computing in deep learning tasks, more tasks such as cloud training and high-performance computing need to be considered. The requirements for general computing and mixed-precision matrix computing need to be balanced, and enough space needs to be reserved for CUDA kernels on a limited area.
According to the chip experts, they stated in the “Electric Vehicle Observer” that “compared with general-purpose architecture, the autonomous driving dedicated architecture will fully consider the characteristics of the target application scenario when designing and adopt more efficient and applicable calculation cores and combination modes to improve computational efficiency and better meet the computing needs of the target application scenario”.
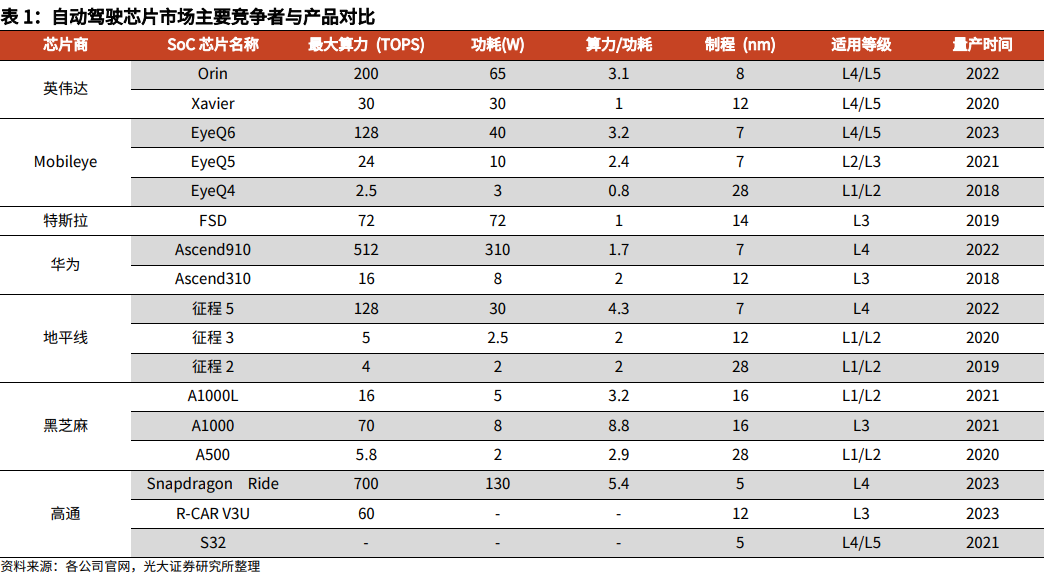
Horizon’s BPU (Brain Processing Unit, an embedded artificial intelligence processor) architecture, which is independently developed for edge autonomous driving requirements, adopts three core technologies of large-scale heterogeneous computing, highly flexible and large-scale concurrent data bridge, and pulsating tensor computing core to create matrix operations.
“NVidia and Horizon’s MAC arrays have many differences in their specific designs.” Luo Heng stated in “Electric Vehicle Observer”. “From the external results, Bayes focuses mainly on batchsize=1, DDR saving, and optimization of convolutional neural networks using depthwise, which fits the characteristics of autonomous driving scenarios and high energy efficiency.”
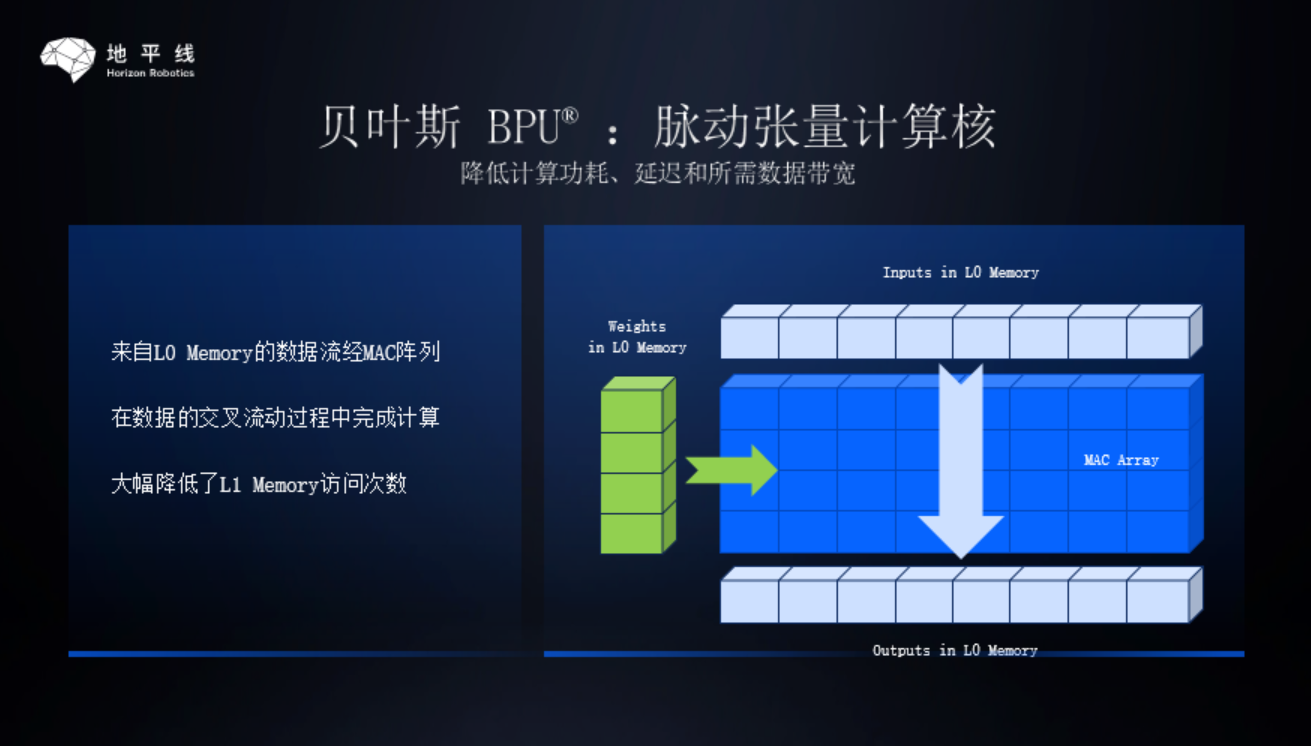
Batchsize refers to the number of samples processed in one batch by the neural network. The larger the number of samples processed in one batch, the greater the potential for parallel computing/acceleration. In the cloud scenario, massive amounts of data need to be processed. GPU and some other cloud AI chips will fully consider the characteristics of large batchsize (processing multiple samples in one batch at a time) in the architecture design to improve hardware efficiency.
In autonomous driving and other edge scenarios, the data arrives at fixed intervals, such as the camera with a frame rate of 30 FPS, which means that a picture will be sent every 33ms, and it needs to be processed immediately to understand the surrounding environment and make necessary controls for the car.
Essentially, autonomous driving faces a batchsize=1 problem (processing one picture immediately when it arrives, rather than waiting for a few more pictures to process together). Tesla’s FSD chip release emphasized that its architecture design is optimized for batchsize=1.
DDR, which stands for double data rate synchronous dynamic random-access memory, is one of the types of memory. In the cloud, memory can be infinitely expanded as a large number of storage units can be connected.
However, at the edge, memory becomes limited and expensive due to the dual constraints of chip area and computing unit competition, and autonomous driving generates huge amounts of data while having to avoid being “stuck” due to insufficient memory. Therefore, the effective increase in data reuse in memory, savings in memory, and ensuring that there is always enough memory space to drive computation are very important through hardware design and software instruction scheduling.

Depthwise is a special form of convolution operator, and the convolutional neural network built with it has the highest algorithm efficiency (it requires less computation to achieve the same algorithm accuracy). The most powerful convolutional neural networks currently are constructed by a large number of depthwise convolutions. For example, the latest ConvNeXt that surpassed Swin Transformer.
To further optimize its MAC array for autonomous driving scenarios, Horizon has also developed vector acceleration units similar to NVIDIA CUDA cores. “Our vector acceleration unit of this generation is a very efficient and relatively simple (not supporting floating-point calculations) vector-oriented accelerator,” said Luo Heng to Electric Vehicle Observer. “The advantage of such a relatively simple vector acceleration unit is the energy consumption and chip area economy. In the next generation of Bayes, we will further strengthen this unit.”
Reducing data throughput in a sense means computing power in exchange for energy consumption and chip area economy. Making the decision between computing power and economy must be based on a deep understanding of autonomous driving scenarios and algorithms.
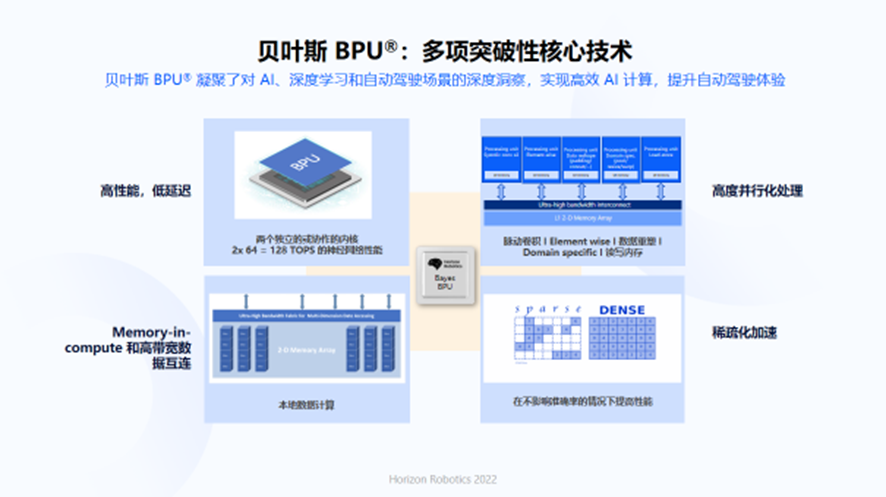
Behind technological innovation is the continuous evolution of Horizon’s BPU third-generation architecture, which focuses on meeting the acceleration needs of autonomous driving at the edge.
One: The third-generation architecture continues to optimize the performance, area, and power consumption of the BPU IP, ensuring that the required DDR bandwidth only slightly increases in the process of significant improvement of performance/computing power.# Horizon 5 (Using Bayesian BPU) achieves 10-25x FPS improvement (with different typical models) compared to Horizon 3 (using BPU Bernoulli 2.0), with less than 2x bandwidth increase and still passive cooling solutions are available.
Furthermore, a better compromise on performance, area, power consumption, and programmability is achieved.
BPU Bernoulli 1.0 and 2.0 mainly support common performance-demanding operators in a hard-core manner (limited programmability). BPU Bayesian considers performance and programmability requirements more systematically and comprehensively by adding flexible and programmable vector acceleration units, and also contains hard-core acceleration units for specific objectives (e.g., Warping, Pooling, Resize, etc). As a result, BPU Bayesian is more general and developing new operators is simpler.
Currently, Horizon 5 achieves 3x FPS on Swin (the most representative transformer in machine vision) compared to Xavier.
“BPU Bernoulli 1.0, 2.0, and Bayesian third-generation architectures are all developed based on accelerating CNNs, and are also among the very few in the industry that continue to efficiently support depthwise convolution (the biggest algorithm improvement for CNN calculations in the past thirty years).” said Luo Heng to “Electric Vehicle Observer”.
By continuously tracking the algorithms required for smart/autonomous driving, designing its own software algorithms, Horizon has a clear and focused judgment on future software algorithm architecture for automotive. Moreover, compared to Nvidia, Horizon single-business doesn’t require consideration of multiple business structures’ technology directions and performance demands.
“Light-weighted deployment” empowers Horizon to catch up with Nvidia’s speed.
More than a year after the release of Horizon 3, it released the brand-new Horizon 5 architecture, which takes only one-third of Nvidia Xavier’s time to evolve into Orin-X.
Ecology: Building its Own Strengths.
Achieving higher efficiency with a dedicated chip specially designed for autonomous driving algorithms and requirements is only the first step for Horizon to catch up with Nvidia. The more challenging work is to build its software system that is suitable for Horizon itself, and to establish a user ecosystem that can support continuous evolution and iterative development — that’s where Nvidia’s strengths lie.
“In history, Nvidia climbed to the top of AI throne by relying on toolchains and established a powerful ecological moat.” said Li Xingyu, Vice President of Ecosystem Development and Strategic Planning, Electric Vehicle Observer. “At the beginning of Horizon’s establishment, we established a toolchain team. At that time, we had an intuition that in the future, the toolchain would become the foundation for our joint innovation with partners.### Horizon Robotics’ AI Development Platform – AIDI
The entire industry is evolving to the data-driven software 2.0 era. Horizon Robotics provides development tools both on-device and in-cloud, including data management and simulation platforms (AIDI), along with TanTan Robotics, to form a complete development platform to accelerate the development of various smart driving, intelligent interaction, in-vehicle entertainment applications and many other solutions.
Horizon Robotics’ AI Development Platform – AIDI “Pursuing” CUDA
Nowadays, NVIDIA GPUs have become the mainstream solution for cloud-based AI acceleration. The reason is not because Intel, Qualcomm, ARM and other chip companies do not have enough computing power, but because they lack a complete programming toolchain like CUDA.
To build a complete, sophisticated, and easy-to-use programming toolchain, it requires a long time, massive capital investment, and technical accumulation. NVIDIA’s CUDA has been leading the way for more than a decade.
As early as 2006, NVIDIA began investing heavily in and promoting the CUDA system in the field of AI. On the one hand, with an annual revenue of only USD 3 billion, NVIDIA invested USD 500 million each year in research and development to update and maintain CUDA. On the other hand, it provided CUDA system usage to US universities and research institutions free of charge at the time, allowing it to flourish rapidly in the AI and general computing fields.
As a newcomer, Horizon Robotics’ AIDI is currently unable to compare with NVIDIA’s CUDA system on completeness, but it has made many impressive performances in AI and edge-side demands.
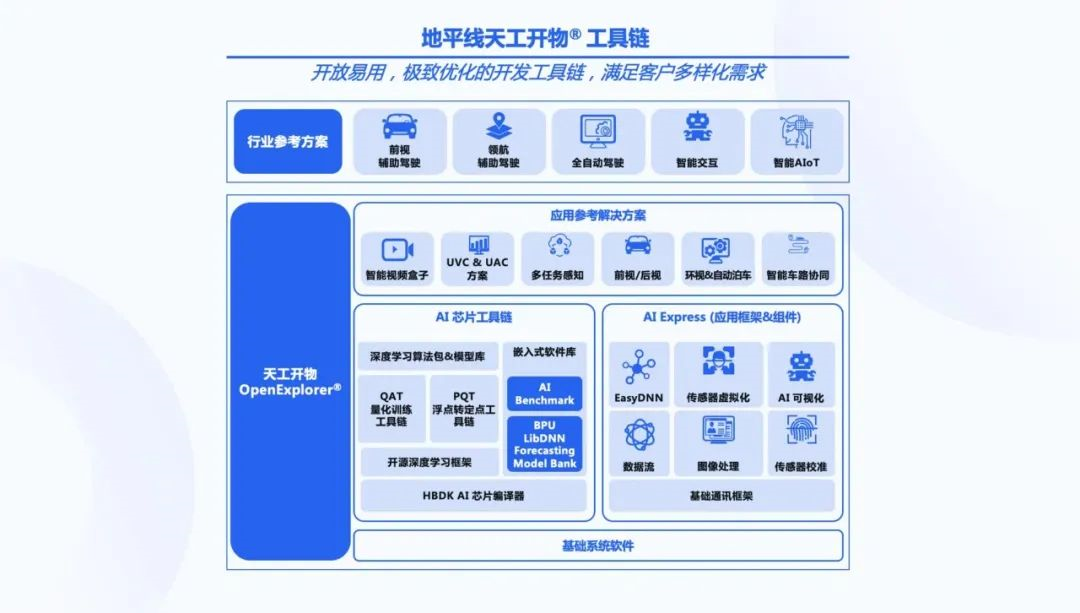
“Horizon Robotics’ toolchain, especially its model conversion tool and compiler, can automatically complete the quantization and compile optimization of models, deploy models on chips quickly through automated algorithms, and achieve high efficiency and low precision loss,” said Luo Heng to the Electric Vehicle Observer.
AI models not only need to complete training in the cloud to output high-precision results but also need to be quantized for deployment.
Model quantization is a compressed model storage (computing) technology that converts floating-point storage (computation) to integer storage (computation).
The model will use floating point during the training process, while AI chips usually use 8-bit integers to compute to save the area and power consumption when inferring. Thus, models trained with floating-point need to be quantized and converted to 8-bit integers for computation.
Quantization can reduce storage cost and bandwidth requirements during runtime, accelerate computing speed, and reduce energy consumption and area occupancy. This way, models can be deployed to more restricted and faster endpoint equipment.
However, data overflow and insufficient precision rounding errors can occur during quantization.In 2017, NVIDIA released a quantization tool called TensorRT, along with its Tensor Core, which realizes the whole process from acquiring models to optimizing, compiling, and deploying them. Horizon Robotics also has a similar quantization tool, and in comparison tests, Horizon’s quantization accuracy for lightweight/small AI models is better than NVIDIA’s TensorRT.
TensorRT needs to cover model quantization in multiple scenarios, such as cloud and edge computing, while Horizon Robotics’ tool is more suitable for deploying models on the edge side, especially for convolutional neural networks in visual recognition.
From 2012 to 2017, convolutional neural networks have undergone rapid development, with a high recognition accuracy, but with a large “volume”. In 2018, the workload of AI model training increased by 300,000 times compared to five years ago, and the model parameters used in research institutions have reached trillions.
Large models bring high performance, but also cause low efficiency and high evaluation costs in the cloud, and difficult deployment on the edge side. Therefore, the industry began to seek “subtraction” at the same accuracy:
Firstly, compression techniques such as knowledge distillation, channel pruning, and low-bit quantization (floating-point calculations converted to low-bit fixed-point calculations) are used to compress complex models that have been trained, reducing the number of parameters and calculations.
A major improvement in the Ampere architecture released by NVIDIA in 2019 is the addition of support for sparse matrix calculations when some of the model parameters are 0.
Secondly, depthwise separable convolution replaces ordinary convolution to form a small-scale/lightweight model, such as SqueezeNet, MobileNet, and ShuffleNet.
However, small models may suffer from accuracy loss during quantization. In 2017, Horizon Robotics designed a quantization training algorithm to solve the precision loss problem of Depthwise models and filed a patent. Google did not release a corresponding quantization algorithm until 2019.
Based on continuous monitoring of algorithms, Horizon Robotics has identified a potential “ultimate solution” – EfficientNet, which it believes represents a temporary plateau in the evolution of convolutional neural network structures in 2019.# EfficientNet Balances Depth, Width, and Resolution with Fixed Scaling Coefficients
EfficientNet achieves a good balance between the three core dimensions of neural networks: depth, width, and resolution, by using a set of fixed scaling coefficients to scale these dimensions uniformly.
Horizon’s FPS tests for Journey 5, Xavier, and Orin (estimations) are conducted using EfficientNet as the test model. In these tests, the models with higher precision than Nvidia’s quantization precision are lightweight/small models like MobileNet and EfficientNet.
Currently, Horizon has already supported over 100 customers in terms of tool chains.
ADI “Chasing” Drive
In addition to tool chains closely integrated with chips, another major competition in software systems is in the development tools closely integrated with automobiles.
Starting in 2017 with the Xavier chip’s official entry into intelligent/autonomous driving scenarios, Nvidia immediately began perfecting and strengthening its end-to-end solutions for autonomous driving and car applications under the Drive series.
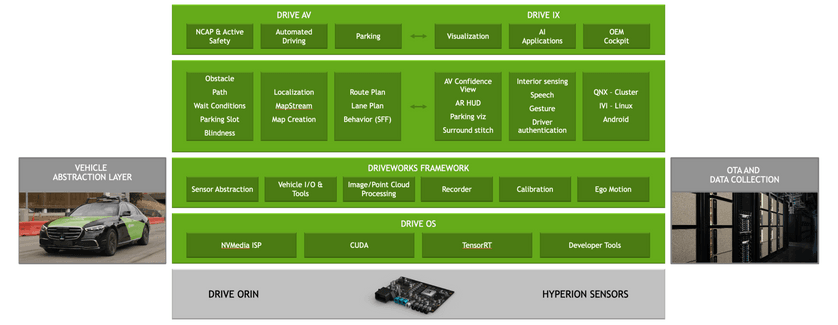
On top of Nvidia’s unified computing architecture (Xavier/Orin/Atlan), four products have been established: the Drive Hyperion autonomous driving development platform, the Drive SDK modular software stack for autonomous driving, the Drive Sim simulation platform, and the Drive DGX deep learning training platform.
Automotive customers can train and optimize models for autonomous driving perception, planning, and control on the DGX; validate models and algorithms in the virtual simulation environment of Sim; select suitable software “assembly” functions and applications in the “software shelf” of Drive SDK; and use Hyperion for data collection and validation development.
Drive SDK includes the OS base software platform, works middleware open to developers, and AV/IX autonomous driving/intelligent cabin software stacks.
Developers can call, combine, and develop various neural networks encapsulated in DriveWorks for the sensor functions of cameras, millimeter-wave radar, lidar, GPS, and IMU, and develop various rich neural networks for typical autonomous driving scenarios and corner case scenarios, constructing computationally intensive algorithms for object detection, map positioning, and path planning.Based on the basic application functions provided by Drive AV/IX, developers can disassemble and combine new features and product capabilities that meet their own needs.

The Horizon Journey is an AI software product development and iteration one-stop tool platform that stands in contrast to Nvidia Drive. It provides intelligent car AI developers with massive data storage and processing capabilities, semi-automatic/automatic annotation capabilities, large-scale distributed training and model management abilities, and automated analysis and problem processing capabilities.
It’s worth noting that Horizon Robotics AI is not only oriented towards Horizon chips, but can also be linked to other chips, with the only difference being in the model deployment stage.
“Developers focus on key scenario issues and automated model iteration throughout the process, which can greatly improve algorithm development efficiency and can also be integrated with a variety of terminals. By doing so, it greatly enhances algorithm developers’ productivity,” said Ling Kun, Horizon’s senior R&D director.
Open Horizon Ecosystem Building
As hardware increasingly serves software and development shifts from human-defined to data-driven software 2.0, the software system is the most difficult part for Horizon to catch up with Nvidia, but it is also the only way to truly catch up with Nvidia.
Being smaller in size, starting up later, yet producing more expensive and narrow-targeted specialized AI chips, how can Horizon catch up with Nvidia in the software field that values ecosystem building?
The answer is to be more open than Nvidia.
On the one hand, it covers a wider range of market segments.
Horizon’s chip product system covers the intelligent/automatic driving needs from L2 to L4. Journey 2 mainly adapts to L2 level assisted driving, Journey 3 can adapt to L2+ level high-speed navigation-assisted driving, while Journey 5 can adapt to more challenging complex urban area assisted driving.
At present, Nvidia Xavier/Orin’s deployment is mostly focused on high-end models’ high-speed navigation-assisted driving, and short-term goals are set on city driving assistance.
This results in significant differences in the scale of the two companies’ chip adoption.
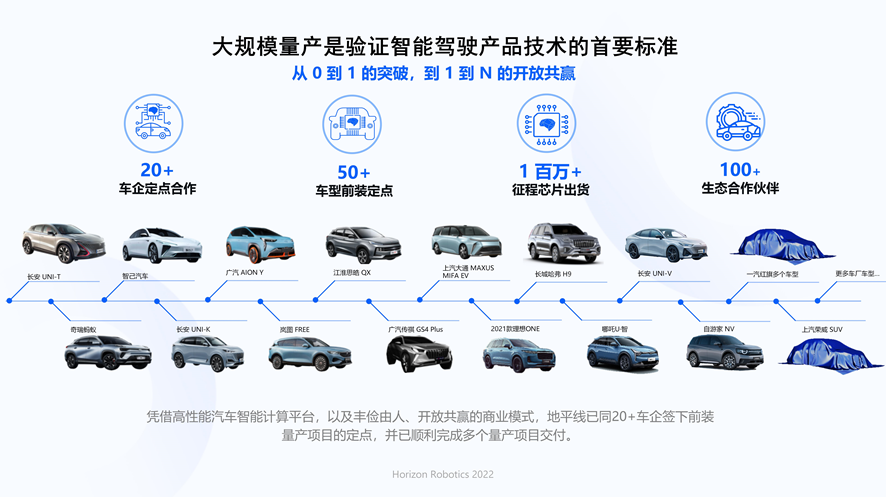 As of now, there are over 15 car models equipped with Horizon Journey chips, including Changan UNI-T/K/V, Chery Ant, GAC AION Y, 2021 Li ONE, NETA U·Smart, and many other hot-selling models with monthly sales of over tens of thousands. Based on this, the shipment volume of Horizon Journey chips has exceeded 1 million pieces, and over 60 mass production project partners have signed contracts with more than 20 automakers.
As of now, there are over 15 car models equipped with Horizon Journey chips, including Changan UNI-T/K/V, Chery Ant, GAC AION Y, 2021 Li ONE, NETA U·Smart, and many other hot-selling models with monthly sales of over tens of thousands. Based on this, the shipment volume of Horizon Journey chips has exceeded 1 million pieces, and over 60 mass production project partners have signed contracts with more than 20 automakers.
In comparison, Xpeng’s models, which mainly use NVIDIA Xavier, have sold approximately 120,000 units.

“More shipment volumes mean more real-world data and application demands, which are the fundamental ‘raw materials’ for continuously improving and perfecting our software systems,” said Ling Kun, adding “We take the problems and ideas that customers encounter and turn the obstacles we encounter in unleashing our creativity into tools that can improve and enhance the Tian Gong Kai Wu toolchain, which can then improve efficiency.”
“On the other hand, we are bringing people together, increasing our openness and depth,” said Li Xingyu to Electric Vehicle Observer.
“Horizon Journey provides a new paradigm of cooperation that showcases ultimate openness and co-creation. We are working to create an ecosystem that fosters collaboration with our upstream and downstream partners. We believe that the value of a company lies in how much it is needed in the innovation ecosystem.”
NVIDIA has developed its own GPU and created system-on-chip (SOC) designs with tight integration with the CUDA operating system. Based on this, the industry has developed software and hardware systems for autonomous driving.
Horizon Journey, on the other hand, has completed the development of its BPU and SOC, and it shares the underlying software, through an open-source OS collaboration with whole-vehicle enterprises, ensuring that developers can deep-dive into the underlying operating systems and efficiently use all sub-resources.
Last year, Horizon Journey launched a proposal to develop an open-source OS, TogetherOS, for intelligent vehicles, in combination with the Journey5 chip. So far, Horizon Journey has embarked on joint development with many domestic automakers, such as Changan and Great Wall.
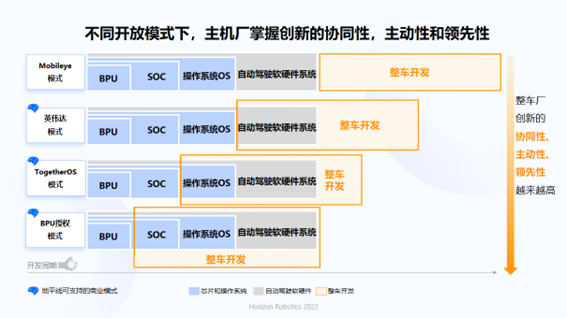
This year, Horizon Journey founder Yu Kai announced that Horizon Journey would not only provide an open-source OS, but also an authorized BPU IP for some of the automakers. As a result, Horizon Journey has adopted three open and collaborative business models:
- The first is to provide BPU and SoC level Journey chips, as well as operating system OS, to help automakers complete the development of their autonomous driving software and hardware systems.- The second is to provide BPU and SoC-level chips, and the automakers develop their autonomous driving software and hardware systems using their self-developed operating system.
- The third is to provide BPU IP, supporting automakers to self-develop SoC and adopt their self-developed operating system and autonomous driving software and hardware system for car development.
In this mode, the high-level collaboration from chip to operating system and then to autonomous driving software and hardware system will greatly improve the iteration speed of vehicle development.
As a provider of AI chips and software tools, the higher the level of underlying development, the more autonomy the automaker has, which can quickly promote product and function iteration – this is the core indicator for current intelligent vehicle competition. Undoubtedly, this will attract more customers and partners for Horizon as well.
This is an opportunity, but also a cost. The higher the openness, the higher the cost of adaptation resources and the costs provided by the provider for users.
As said by Mobiveil CEO Ravi Thummarukudy, “Cost is required to bring IP to market, and once customers obtain authorization and begin to integrate it into SoC, supporting the IP will become a regular expense.”
Not only IP, just in the process of loading onto journey 5, the depth and thoughtfulness of the supporting service provided by Horizon for customers is something that foreign multinational corporations like Nvidia cannot achieve.
Nvidia has been in the AI industry for 16 years since the launch of CUDA, and began collaborating with intelligent car-leading enterprise Tesla in 2015. Their high technology barriers, wide ecological moats, all this can be imagined.
Today, China has become the arena of global intelligent vehicles. Fortunately, Horizon starts with the Chinese market, beginning this arduous pursuit.
Whether Horizon’s technical roadmap of combining software and hardware and co-creative open business model can create a story of reversal through winning by a small margin and winning with weakness against strength years later, only time will tell the answer.
References:
“New AlphaGo First Unveiled: Runs on One Machine, 4 TPU, Algorithm More Powerful” by Quantum Bit
“For Faster Speed” by arcsin2
“Nvidia Research Report: From Hardware GPU Design to Software CUDA+Omniverse Development” by Dongwu Securities
“AMiner Artificial Intelligence Chip Research Report” by 2018 Tsinghua-China Academy of Engineering AI Lab
“Latest Development in Automatic Driving CNN Algorithm, Visual and Linguistic Modeling May Be Unified” by Automotive Reference
“Concept of Tensors and Basic Operations” by ChihYuanTSENG
“Touching the ARM River, Horizon Opened up the Future of BPU IP Authorization Business Model?” by eefocus
“Exclusive Interview with Yiran Chen of Duke University: Nvidia Open-sources Xavier DLA, AI Chip Startups Being Squeezed?” by Lei Feng Net## “Evolution of NVIDIA GPU architecture in the past decade: From Fermi to Ampere” by Will Zhang
“Differences between FP32, FP16, and INT8 numerical types for deep learning model weight precision” by Qian Yu Programming
“FP64, FP32, FP16, BFLOAT16, TF32, and other members of the ZOO” by Grigory Sapunov
“A detailed explanation on model quantization” by Technical Explorers
“Behind the leap of GPU computing power in deep learning: The key investment of NVIDIA CUDA”
“Open BPU IP authorization | Does Horizon’s model have a future?” by EE Times.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.