
On July 29, the highly anticipated LI i8 was finally launched, coinciding with the tenth anniversary of LI’s founding.
The i8 was released in three versions, priced between 321,800 to 369,800 CNY. Let’s take a closer look at the specific pricing and configurations:
- Pro version 321,800 CNY, Max version 349,800 CNY, Ultra version 369,800 CNY.
- Dual-motor intelligent four-wheel drive, dual-chamber magic carpet air suspension, seat comfort configuration, front-row screen, HUD, laser radar, and other features are standard across all versions.
- The Pro version is equipped with LI’s advanced driving assistance AD Pro, while the Max and Ultra versions are equipped with AD Max.

This launch event was packed with information, including the i8 product release, VLA driver large model, LI’s intelligent agent, and the supercharging network, all condensed into a two-hour presentation.
The highlight of today’s event was not just the car itself, but the significant upgrade in the i8’s debut driver assistance features.
LI’s VLA (Vision-Language-Action model) was released alongside the i8, marking it as the first LI model to come equipped with the VLA driver large model. VLA will be available for the i8 in August.

All AD Max owners will also receive an OTA update in August, including those on the Thor-U and Orin-X platforms. Additionally, AD Pro with J6M will have city NOA fully deployed by the end of the year.
Just days before the launch event, we had the opportunity to test drive the VLA-enabled LI MEGA and LI i8, and engage in an in-depth three-hour discussion with Lang Xianpeng and his team. We gained clearer answers to questions about what VLA is, what it can achieve, and how LI executed it.
The enhancement of VLA capabilities focuses on three main aspects: better semantic understanding, improved reasoning skills, and closer approximation to human driving intuition. Specific examples include:
- Understanding natural language commands like “pull over,” “move forward 50 meters,” and “speed up,” and executing them accordingly;
- Setting specific speeds for certain road segments based on past memories;
- Finding destinations through voice commands, such as “find the nearest Starbucks for me”;
- Assessing passage risks, choosing the right road, and actively avoiding obstacles in complex road conditions.
 In LI Auto’s view, VLA brings not just improved driver assistance but a driver that can comprehend human language and think independently.
In LI Auto’s view, VLA brings not just improved driver assistance but a driver that can comprehend human language and think independently.
This marks a leap in the driver assistance field, with LI Auto taking the lead into uncharted territory.
Why VLA
Over the past few years, driver assistance has undergone three architectural iterations: rule-based algorithms, end-to-end systems, and VLA. This evolution represents a shift from command control, to behavior imitation, and ultimately to intent understanding. Each generation of technology has continuously advanced computational power and average disengagement mileage, essentially striving to emulate human driving.
On July 25th, Dr. Xianpeng Lang, Senior Vice President of Autonomous Driving R&D at LI Auto, shared insights into the development journey and thought process behind VLA during a media session. Dr. Lang believes that the dividing line from the manual era of driver assistance to the current AI era is the transition from map-dependency to end-to-end approaches. In the previous manual era characterized by light mapping or mapless solutions, the core of driver assistance was rule-based algorithms. “A typical scenario involved engineers designing algorithms themselves and controlling vehicle operations through programming. The core of performance in the manual era was determined by engineers, where human experience, programming skills, and algorithm capabilities dictated the system’s performance.”
The limitation of the manual era was evident in the inability to address all scenarios solely through human effort. As Dr. Lang put it, many scenarios were like “pushing down a gourd only to see a ladle pop up.” Consequently, driver assistance transitioned into the end-to-end era.
The core of end-to-end systems combined with VLM (Vision-Language Model) is imitation learning, training models using human driving data. During this technological phase, the decisive factor is “data.” Abundant data, comprehensive scenario coverage, and high data quality—preferably from seasoned drivers—ensure exceptional model performance.
However, imitation learning ultimately has its limits. LI Auto was among the first to recognize this and pivot towards a reinforcement learning path. Unlike the previous reliance solely on real driving data, VLA combines synthetic data and simulation environments to allow models to evolve autonomously in risk-free, controlled virtual worlds. This approach is now being adopted by more automotive companies, with VLA becoming the new consensus for intelligent driving.
Dr. Lang explained that synthetic data is needed for model training because human driving data suffers from severe distribution imbalances, mostly concentrating on routine scenarios like daylight, clear weather, and normal commuting, while truly complex or hazardous condition data is scarce and challenging to collect. Yet, models with real decision-making capabilities precisely require these edge and extreme scenarios.
This necessitates the introduction of synthetic data and high-quality simulation environments, employing generative methods to build more comprehensive and widely distributed datasets, while continuously assessing model performance. The key to enhancing model performance isn’t the quantity of real data collected, but the efficiency of simulation iterations. Compared to traditional data-driven methods, this represents a more proactive training approach.
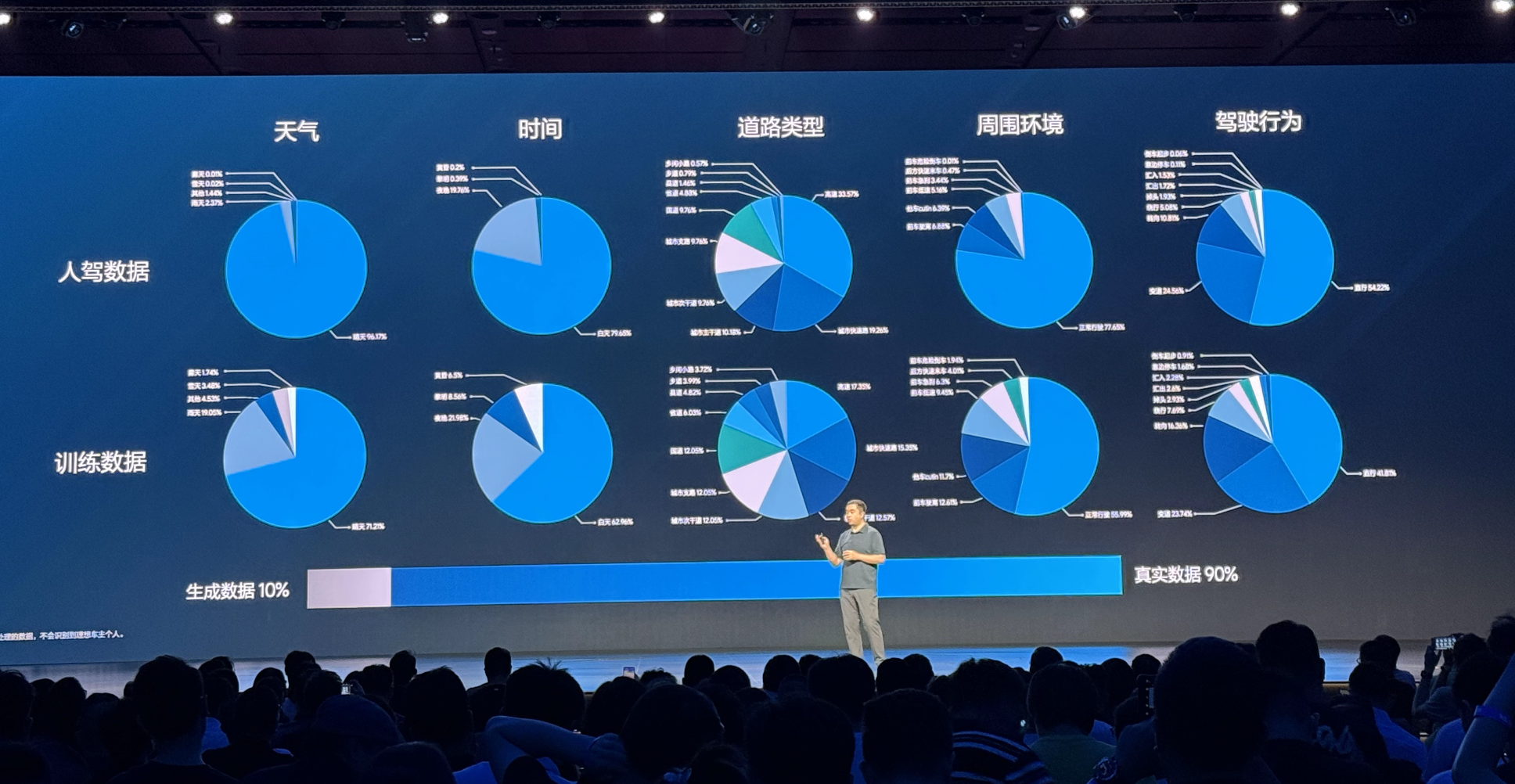 The training method of synthetic data has directly led to cost reduction. According to Lang Xianpeng, in 2023, the effective test mileage using real vehicles was approximately 1.57 million kilometers, with a cost of 18 yuan per kilometer. However, in the first half of this year, a total of 40 million kilometers were tested, of which only 20,000 kilometers used real vehicles, bringing the testing cost to an average of 0.5 yuan per kilometer. “We only pay for electricity and server fees, and the testing quality is still high. All scenarios can be handled seamlessly and can be entirely replicated with precision.”
The training method of synthetic data has directly led to cost reduction. According to Lang Xianpeng, in 2023, the effective test mileage using real vehicles was approximately 1.57 million kilometers, with a cost of 18 yuan per kilometer. However, in the first half of this year, a total of 40 million kilometers were tested, of which only 20,000 kilometers used real vehicles, bringing the testing cost to an average of 0.5 yuan per kilometer. “We only pay for electricity and server fees, and the testing quality is still high. All scenarios can be handled seamlessly and can be entirely replicated with precision.”

The next question LI Auto wants to answer is: What makes the VLA model strong? Why develop VLA after end-to-end + VLM?
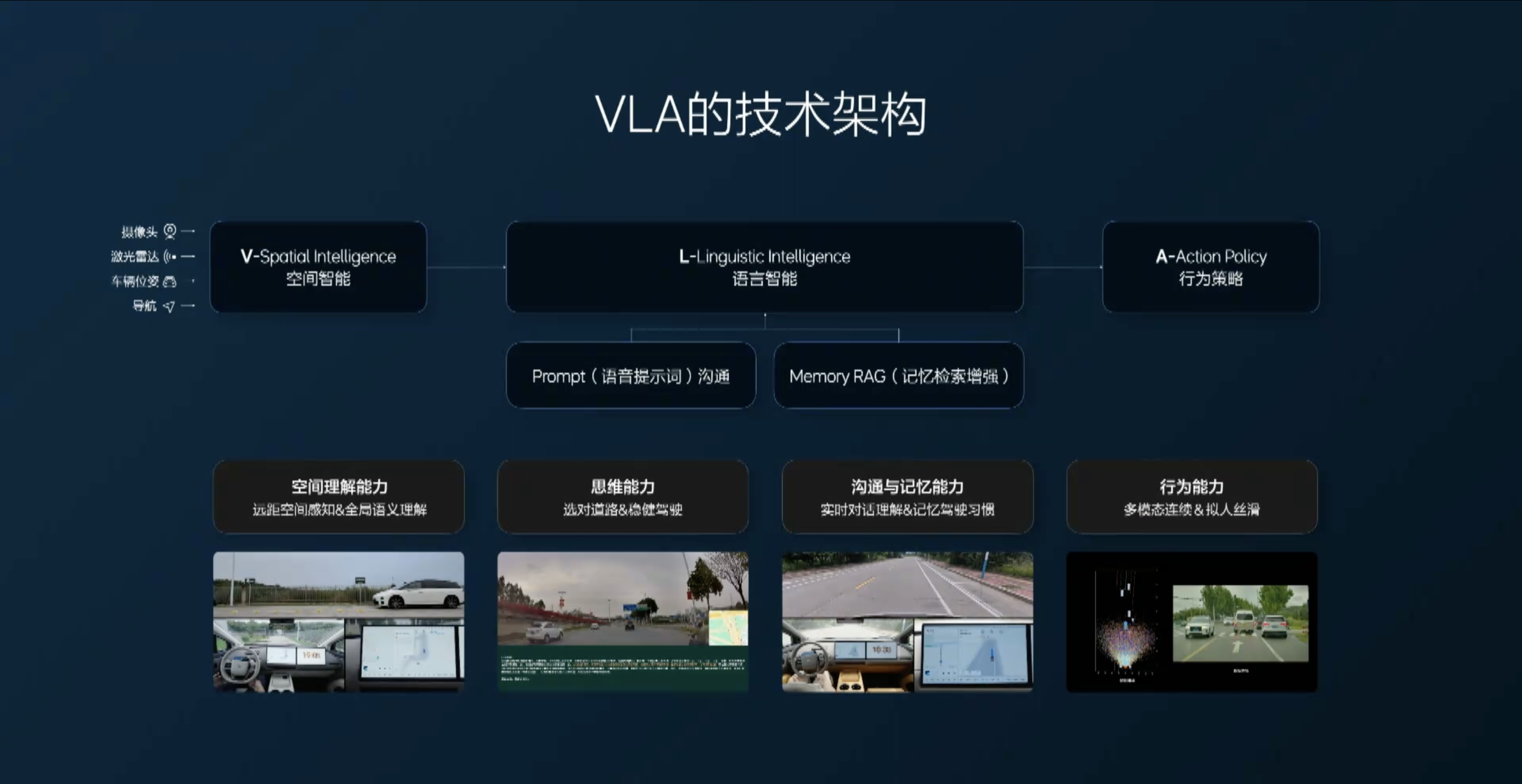
VLA stands for Vision-Language-Action, a model combining vision, language, and action. In the VLA model, ‘V’ takes on the role of spatial perception, forming an understanding of the surrounding environment through various inputs such as cameras and navigation; ‘L’ translates this perception into clear language; ‘A’ refers to generating behavioral strategies based on scene encoding, essentially how the model should drive.
Simply put, VLA is a model capable of understanding human speech, interpreting images, and acting based on this combined information. It allows control of intelligent agents, such as robots and vehicles, through natural language rather than specific voice, text commands, or buttons, enabling independent task execution and responsibility assumption.
It can understand human speech, like “drive slower” or “change to the right lane”; it can remember preferences, such as previously driving at 80km/h on this road; and it can perform defensive maneuvers like a seasoned driver, such as slowing down before a tunnel to avoid a suddenly appearing vehicle. These capabilities cannot be achieved with traditional end-to-end models.
Lang Xianpeng stated that the end-to-end architecture lacks deep thinking ability, acting more like a reflex with an input-output response without deep logic behind it. “It’s like a monkey driving. You feed it bananas, and it might perform actions according to your intention but doesn’t understand why it’s doing them. You can make it come over by banging a gong or make it dance with a drum, but it doesn’t know why it dances.”
Thus, even when LI Auto later attempted to incorporate VLM into the end-to-end approach to facilitate better decision-making, the end-to-end model still struggled to understand what VLM was conveying.
The core capabilities of VLA can be summarized as: think, communicate, remember, and self-improve. Based on these capabilities, the actual experience brought to users is safety, comfort, advanced driving skills, and natural interaction capabilities. In the i8 product, the enhancement of VLA capabilities has upgraded the overall product experience.
 And LI Auto has evolved its approach to assisted driving from a focus on safety and being a “professional driver” to providing a “better family driver for everyone.”
And LI Auto has evolved its approach to assisted driving from a focus on safety and being a “professional driver” to providing a “better family driver for everyone.”
This means that, beyond functional value, assisted driving must also satisfy passengers’ emotional needs. Lang Xiangpeng said, “The way you drive when you’re alone in the car is different from when your family is with you. You will drive more safely, comfortably, and according to your family’s preferences.”
Before the i8 launch event, a short film about the VLA experience was shown, where Li Xiang admitted there was an issue with defining assisted driving as being a “veteran driver.” “A veteran driver may drive comfortably for themselves, but not necessarily for the passengers. Later, we redefined it: a professional driver, with standards akin to a state guest chauffeur, so that no one is dissatisfied.”
During our test ride, we found that this new “state guest chauffeur” standard is not just talk. The VLA shuttle bus experience provided was simple, primarily within the LI Auto park at a speed of about 10 km/h, yet it could perform operations like edge parking, turning, and speeding up through voice control. In unmanned mode, it can simulate completing routine tasks like “going to a café, picking up a package, and returning automatically.”
More notably, VLA demonstrated critical stability in the passage through extremely narrow road junctions and could also leave the park area to access public roads to proceed to the next destination. The overall performance was similar to the Driver Agent version on the L9 test car earlier this year. Although not astonishing, it was indeed more stable in execution precision and motion rhythm.
Is LI Auto Destined to Be the First to Achieve VLA?
VLA has now become the new direction in the intelligent driving industry. Besides LI Auto, several vehicle manufacturers such as XiaoMi, Xpeng, Geely, and suppliers and autonomous driving companies like Pony.ai and Waymo are advancing similar architectural transitions to varying extents. However, in terms of actual implementation speed, LI Auto is clearly leading the way.
The timeline given by Li Xiang at the i8 release event was:
- VLA delivery in August on the i8;
- Simultaneous OTA updates for all AD Max owners in August, covering owners of both the Thor-U and Orin-X platforms.

This did not happen by chance.
According to Lang Xiangpeng, VLA is not a skip-level tactic but rather a natural progression after end-to-end development. Without going through the end-to-end stage with comprehensive training in perception, decision-making, and control models, stepping into VLA wouldn’t be possible.
Lang Xiangpeng stated in an interview that while VLA’s data, algorithms, etc., might differ from before, they are still built on previous foundations. “If there’s no complete data closed loop collected by real vehicles, you cannot train world models. LI Auto’s ability to implement the VLA model is because we have 1.2 billion (kilometers) of data, and only by fully understanding this data can we better generate data.”Why was LI Auto the first to achieve VLA? Liang Xianpeng says, “Data, algorithms, computing power, and engineering—we are strong in all four areas.”

LI Auto’s core competence lies in their understanding and utilization of data. “Not everyone has the data,” Liang Xianpeng states, “By July 2025, we have accumulated 1.2 billion kilometers of effective data. This data is attributable to our sales growth, as we have sold over 1.3 million vehicles.”
Since 2020, LI Auto has systematically refined their tagging dimensions such as weather, road type, and traffic conditions, developing a data system covering complex scenarios and long-tail scenes. Liang Xianpeng notes, “Reaching 10 million or 20 million clips isn’t challenging, but generating such a diverse and valuable data set is one of our advantages. Our 10 million clips consist of various categories, including selectively curated data.”
When traditional real-world data could no longer provide improvements, LI Auto introduced synthetic data on a large scale. Utilizing world model technology, they can reconstruct and expand historical scenes—an ordinary highway ETC toll can be virtually transformed into conditions like rainy nights, foggy days, dusk, and extended to extreme scenarios involving slight deformations or disruptive vehicles. VLA scenarios that previously contained errors are automatically modified into a series of variants for continuous training.
Liang Xianpeng expresses strong confidence in the effectiveness of simulation data during an interview: “Our current simulation results can fully rival real-vehicle tests. Over 90% of tests in the latest super version and LI Auto i8’s VLA version are simulated. Since last year’s end-to-end version, we’ve been validating simulation tests, and we currently find their reliability and effectiveness to be high. Thus, we have replaced real-vehicle tests with this method.”

However, he also mentions that some tests remain irreplaceable. “For example, hardware durability tests. But we basically use simulation tests for performance-related testing with excellent results.”
Supporting this system is LI Auto’s investment in resources for inference and training capabilities. Liang Xianpeng explains that LI Auto currently has a total training platform of 13 EFLOPS, with 10 EFLOPS allocated for training and 3 EFLOPS for inference. The importance of inference ability is magnified in the era of VLA because the generation and expansion of world models depend on inference performance. Without powerful inference cards, effective reinforcement training is impossible. According to LI Auto’s internal estimates, their current inference resources are equivalent to 30,000 NVIDIA L20 inference cards.
However, computational power does not equate to deliverability. Whether VLA can truly be implemented in vehicles hinges on overcoming the hurdles of engineering realization. Over the past year, LI Auto has continuously pushed in chip adaptation and model compression: Last year, they successfully deployed the 2B model on Orin-X and this year achieved the deployment of the 4B MoE (Mixture of Experts) model on the Thor-U chip, with inference precision compressed from FP16 to FP8 and INT8. Currently, VLA is adapted to both the Orin-X and Thor platforms, with future plans to advance towards FP4, further squeezing the potential of computational power.
Lang Xianpeng put forward a perspective: “We believe that the ceiling of the previous generation’s technological capabilities is the starting point for the next generation.” This viewpoint stems from LI Auto’s practical experience in iterative upgrades of the assisted driving architecture. From 2021 to 2024, this period is considered the era of rules. LI Auto achieved an MPI (Mean Miles per Intervention) of around 10 kilometers for (highway + city) all-scenario drives, which was the data for the end-to-end starting phase. Now, the MPI for the end-to-end + VLM solution has reached approximately 200 kilometers.
“Now, if the MPI truly can be elevated to 1,000 kilometers, it would mean interventions might only be necessary every two to three months, potentially signifying entering the next era.”
When Will VLA’s ChatGPT Moment Arrive
On July 25th, the Garage 42 and several industry media outlets engaged in in-depth discussions with LI Auto’s autonomous driving team. Interviewees included Dr. Lang Xianpeng, Senior Vice President of Autonomous Driving R&D at LI Auto, as well as LI Auto’s Senior Algorithm Experts Zhan Kun and Zhan Yifei.
During this interview, LI Auto’s autonomous driving team addressed key issues regarding VLA’s inference capabilities, current indicators, and the pace of implementation. They revealed that the biggest hurdle behind VLA is actually the simulation capability of the world model, making it difficult for others to catch up and complete the entire chain of development quickly.

Below are the main contents of the group interview, edited without changing the original intent:
Q: VLA drivers have inference abilities and behave more like humans, but they need several seconds for inference. How does the VLA driver think quickly in sudden scenarios?
Lang Xianpeng: You perceive the thinking process as slow due to display reasons. The inference itself is very fast; we have merely extracted some key thought processes for clearer visibility. Currently, VLA’s inference frame rate is around 10 Hz, more than tripling from the previous VLM, which was about 3 Hz.Q: How do you determine the timeline for the implementation of autonomous driving, and how will it be commercialized?
Lang Xianpeng: From a technical standpoint, we think the VLA model has the potential to advance to higher levels of autonomous driving, though it is currently in its infancy. At this stage of the technology cycle, the VLA model approximately equates to the upper limit of end-to-end solutions, with a long journey ahead. However, I believe the process won’t be especially slow, as it took approximately one year for end-to-end to progress from 10 MPG to now 100 MPG; I am confident the iterations of VLA will also be rapid. By next year, it may have evolved to 1,000 MPG.
Commercialization involves numerous influencing factors, the most critical being national legal policies. LI Auto is actively participating in national policy regulation discussion groups. Technologically, L4 level autonomous driving can be realized swiftly, though from a business perspective, there are many issues to consider, such as insurance and post-accident compensation.
Q: In intelligent driving, there’s a “Impossible Triangle” involving trade-offs between efficiency, comfort, and safety. Achieving all three is challenging at the current stage. Which indicator is LI Auto’s VLA optimizing first? You mentioned MPI earlier; can it be interpreted that LI Auto’s ultimate goal is to enhance safety to reduce takeovers?
Lang Xianpeng: MPI is one of our metrics, alongside MPA, which measures accident mileage, currently around 3 million kilometers. LI drivers experience accidents every 600,000 kilometers on average, whereas with the assistance driving functionality, it occurs every 3.5 to 4 million kilometers. We aim to increase this figure progressively, aspiring to make MPA ten times safer than human driving, equating to 6 million kilometers per accident with assistance driving—achievable after VLA model enhancements.
Regarding MPI, we’ve analyzed that some safety risks lead to takeovers, and occasionally discomfort causes takeovers, such as sudden or harsh braking. Though not all cases involve safety risks, discomfort can discourage users from utilizing assistance driving. As MPA quantifies safety, besides safety in MPI, we are enhancing driving comfort. Users experiencing the LI i8’s assistance driving will notice significant comfort improvements over previous versions.
Efficiency ranks after safety and comfort; for example, taking a wrong route incurs efficiency losses, but corrections are made safely and comfortably, prioritizing these over immediate efficiency recovery.
Q: You mentioned a significant technological shift from rules to end-to-end + VLM, yet VLA does not disrupt end-to-end + VLM. Can it be understood that VLA leans more towards engineering capability innovation?Jian Kun: VLA is not just an engineering innovation. If you pay attention to embodied intelligence, you’ll notice this wave comes with the application of large models to the physical world. Essentially, it proposes a VLA algorithm. Our VLA model aims to apply the concept and approach of embodied intelligence in autonomous driving. We were the first to propose and start practicing it. VLA is also end-to-end, as the essence of end-to-end is scene input, trajectory output, and VLA does the same, but with the innovation of added thinking. End-to-end can be understood as VA, without Language; Language corresponds to thinking and understanding. We have added this part to VLA, unifying the paradigm of robots, allowing autonomous driving to become a type of robot, which is an algorithmic innovation, not just engineering innovation.
For autonomous driving, a significant challenge is the need for engineering innovation. VLA is a large model, and deploying large models on edge computing power is tremendously challenging. Many teams don’t think VLA is bad; rather, the challenge lies in deploying VLA, especially when it is impossible to accomplish with insufficient edge chip computing power. Therefore, we can only deploy it on chips with substantial computing power. So it’s not only engineering innovation but indeed requires extensive engineering deployment optimization to achieve this.
Q: From an industry perspective, the current intelligent driving experience is somewhat homogeneous. Will LI Auto export its intelligent driving capabilities to the industry, open-source them, or sell them to other automakers in the future?
Lang Xianpeng: I think it’s possible. We hope to contribute to the industry. But the premise is, first, whether we can verify this system well, as the development of VLA is still in the early stages of its technology cycle and requires further enhancement; second, whether others have the capability to work with us on this, as they also need their evaluation methods, simulation environments, and reinforcement learning training capabilities.
From the standpoint of the company or my personal attitude, we hope to promote industry development. However, considering the current stage of VLA’s technology development, it is still relatively nascent. Its development speed could be quite fast, similar to end-to-end, improving the effect tenfold in a year. The industry’s development pace will be very rapid, and I believe by next year, when we communicate, we might discuss the open-source issue.
Q: Starting the second half of this year, all car companies will advance VLA. What are LI Auto’s advantages or technical barriers regarding VLA technology?
Jian Kun: Our first advantage is that our technology stack is continuous. We’re not jumping from the previous rules era suddenly to VLA, which would lead to various issues, like data accumulation, training quality, or simulation evaluation systems. What we’re doing with VLA is actually a continuation of our technological architecture, leveraging original advantages to continue building on the shoulders of giants.
Lang Xianpeng: There are indeed technical barriers. The core technical barrier for LI Auto is the world model simulation barrier, which is extremely high and difficult for others to replicate quickly. Its iteration speed needs to be ensured and tested with real vehicles, so it’s tough to surpass us.Q: LI defines a VLA driver as a better family driver, a secure mobile space. Will VLA technology expand to other product lines or services beyond commodity cars in the future?
Zhan Kun: We believe that VLA will form a larger and unified architecture in the future. We also consider VLA as a highly consistent advanced technology for applying AI to the physical world, not just for autonomous driving. It seems to be the most reasonable direction for physical AI currently.
Lang Xianpeng: It can certainly be expanded. We have established various other robotics departments. VLA is an excellent embodied intelligence technical framework and might extend to other directions.
Q: Are future version releases of Orin X synchronized or differentiated? Additionally, when Orin X pushes VLA, what is the capability ceiling you consider internally, and how long will it maintain parity with or diverge from Thor U in future updates?
Lang Xianpeng: Our updates are synchronized. When the i8 launches, all existing AD Max car owners with Orin X or Thor chips, including those who bought their cars in 2022, will receive synchronized updates. Test results show there’s no capability difference, with identical frame rates, highly optimized engineering, all at 10 frames. The only distinction lies in the chassis differences between the i8 and L9, possibly affecting comfort levels slightly.
Future update schedules will also be synchronized across Orin and Thor platforms. As for if and when differences arise, right now, we have no plans to differentiate. If breakthroughs occur in INT4 quantization during the next iteration, divergence might happen, but it’s too early to discuss that now.
Q: What score would you give to today’s version of the real vehicle, and what score do you think it needs to achieve to be widely released to users?
Lang Xianpeng: We have an internal scoring mechanism. Taking simulation as an example, we’re aligning first with OTA7.5, the last end-to-end version. This version surpasses OTA7.5 in our internal evaluations, including the test drive version of VLA today. Though there might be minor score fluctuations, overall, this version slightly surpasses the previous end-to-end one.
However, before widespread release, we aim for a noticeable performance enhancement. What you experienced today is our improvement in comfort, which seasoned drivers can surely feel. Soon, we will significantly enhance safety, compliance, navigation, efficiency, and other aspects to ensure a superior experience for both familiar users and those new to assisted driving, providing a strong sense of security, comfort, and trust.Q: There is a general consensus that multimodal models have yet to reach what is referred to as the GPT moment, both in terms of world comprehension and data training. Although there is a vague sense of direction, there is no clear solution on how to proceed. At this juncture, you need to draft a mass-production proposal to introduce to the market. Do you believe this proposal qualifies as a sufficiently good solution? Moreover, how much time will it take to reach the so-called GPT moment?
Jian Kun: The claim that multimodal models have not reached the GPT moment likely pertains to VLA in physical AI, rather than VLM. Presently, VLM already fulfills an innovative GPT moment. As for physical AI, the current VLA, particularly in robotics and embodied fields, might not have reached the GPT moment due to limited generalization ability. However, in the autonomous driving sector, VLA addresses a relatively unified driving paradigm and holds the potential to achieve a GPT moment through this approach. We acknowledge that VLA is positioned as the first version in the industry aimed at mass production, despite inherent deficiencies.
This significant venture seeks to explore novel pathways using VLA, with numerous experimental aspects and areas to be grounded. Achieving mass production is viable if it provides users with a “better, more comfortable, and safer” experience, irrespective of attaining the GPT moment.
The GPT moment primarily signifies robust generality and generalization. Along the route, as we expand from autonomous driving into spatial robotics or other embodied domains, we anticipate stronger generalization or integrated coordination abilities. Post-launch, as user data iterates, scenes diversify, logical reasoning enhances, and voice interaction proliferates, we gradually approach the ChatGPT moment. It is not essential to achieve the GPT moment to construct an autonomous driving model.
For instance, once VLA is deployed, transitioning towards ChatGPT capabilities becomes feasible. This initial version of VLA deployment is a stepping stone towards developing a VLA model with richer, more general, and more diversified capabilities. As Langbo mentioned, by next year, should we reach 1000 MPI, users might genuinely perceive the advent of a VLA ChatGPT moment.
This article is a translation by AI of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.