
The Premier Event in the Global AI World — NVIDIA GTC Opens in San Jose, USA
The NVIDIA GTC, the premier gathering of the global AI community, has officially opened in San Jose on the West Coast of the United States. Yesterday and today, a significant portion of China’s intelligent driving industry has gathered at GTC to discuss the future of intelligent driving in 2025.
Jueying SenseTime CEO Wang Xiaogang, LI Auto’s Head of Intelligent Driving Development Jia Peng, Yuanrong Qixing CEO Zhou Guang, XiaoMi Auto’s Autonomous Driving and Robotics Department Yang Kuiyuan, and Zepoint AI CTO Chen Xiaozhi made successive speeches. Their core arguments focused on two main areas: the implementation of end-to-end intelligent driving and the next-generation VLA model (Vision-Language-Action) architecture.
This morning, both LI Auto and Yuanrong Qixing announced their VLA models. Li Xiang declared on Weibo, “This is our most important step towards L4. Just as the iPhone 4 redefined the phone, MindVLA will redefine autonomous driving.”
Both companies, the first in the intelligent driving domain to launch the VLA architecture, coincidentally plan a similar rollout timeline. LI Auto’s MindVLA will arrive with the i8, and Yuanrong Qixing aims to integrate it in several models by mid-year.
In the 2025 intelligent driving race, VLA will be a crucial element.
In the process of mass-production deployment of intelligent driving, “end-to-end” has become an indispensable technology for any manufacturer. Throughout last year, XiaoMi Auto completed a three-generation technological upgrade from high-speed NOA, rule-based city NOA, to end-to-end intelligent driving. The latest end-to-end version will utilize models trained on over 13.6 million clips. The Jueying SenseTime end-to-end solution, UniAD, is also set for mass production this year. Additionally, Zepoint aims to deliver a more personalized end-to-end intelligent driving system.
Behind the realization of end-to-end + VLA is NVIDIA’s provision of core computing power and extensive toolchains. NVIDIA has always held a central market position in China’s intelligent driving landscape. In the face of fierce competitors like Huawei and Tesla, how NVIDIA and its partners respond to the 2025 intelligent driving competition was revealed at this GTC.
LI Auto Releases VLA Model, Controlling Cars with Speech
It may not be long before you can freely command a vehicle with your voice. For instance, desiring a coffee, you could instruct the car to find a Starbucks and drop you off at the entrance.
Encouragingly, this scenario is not merely a mental conception. At the NVIDIA GTC conference, LI Auto’s Head of Intelligent Driving Development Jia Peng demonstrated this scenario via video.

Jia Peng also demonstrated two other scenarios: one where the owner isn’t sure of their location but can call the car to pick them up, and another where the owner disembarks first and lets the car find a parking spot independently.Overall, Jia Peng described this as “everyone’s dedicated driver,” and he also stated that LI Auto will “redefine intelligent driving.”
This scenario is made possible, according to Jia Peng, by LI Auto relying on VLA technology, which stands for Vision-Language-Action Model, and they call their VLA technology MindVLA.
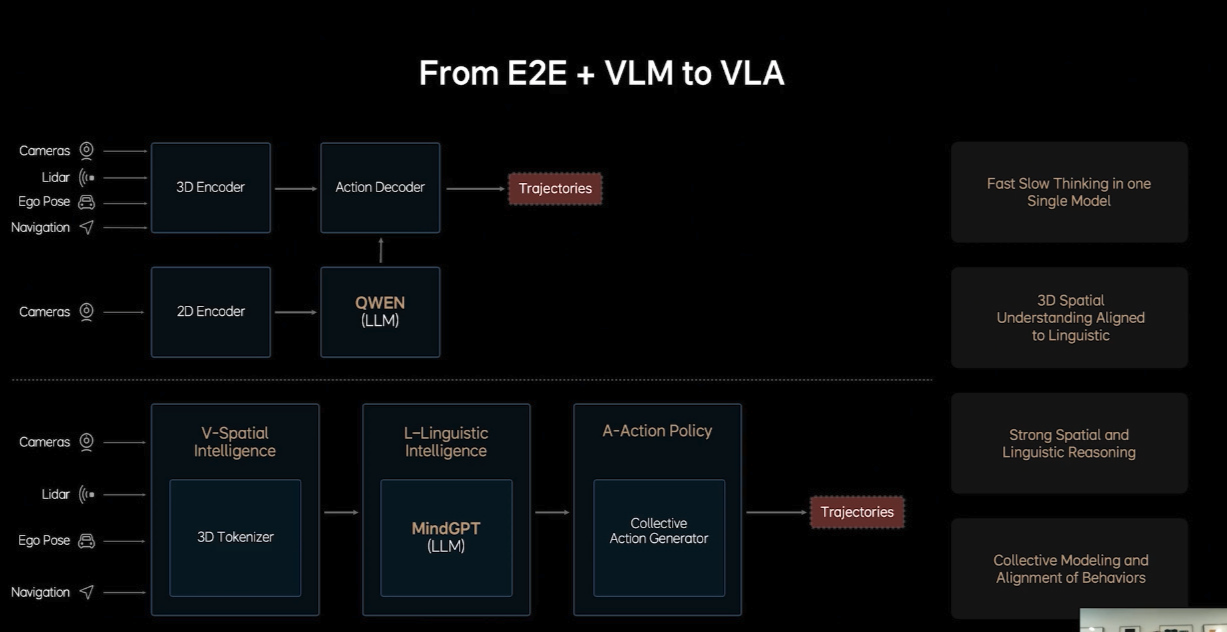
Currently, LI Auto’s intelligent driving technology remains end-to-end + VLM. Once this tech solution is applied, it significantly enhances LI Auto’s smart driving level and boosts the sales growth of the AD Max model. However, Jia Peng mentioned that there are many issues with end-to-end + VLM.
For instance, end-to-end and VLM are two separate models, and joint training is quite challenging. Additionally, end-to-end + VLM has issues like insufficient understanding of 3D space, lack of driving knowledge and memory bandwidth, and difficulty in handling the multimodality of human driving.
Regarding the multimodality of human driving, Jia Peng provided further explanation, meaning that for the same driving behavior, the driving state may vary from person to person. Moreover, even the same person might drive differently depending on their mood.
As for MindVLA, Jia Peng mentioned that it does not crudely unify the two models of end-to-end and VLM; many modules need redesigning. In terms of capability, MindVLA can simultaneously raise both the upper and lower limits of smart driving, achieving unity of space, action, and language.
Specifically, MindVLA can have a better understanding of 3D space, possess language intelligence to comprehend the driver’s voice commands, and reinforce learning within the world model, among other capabilities.
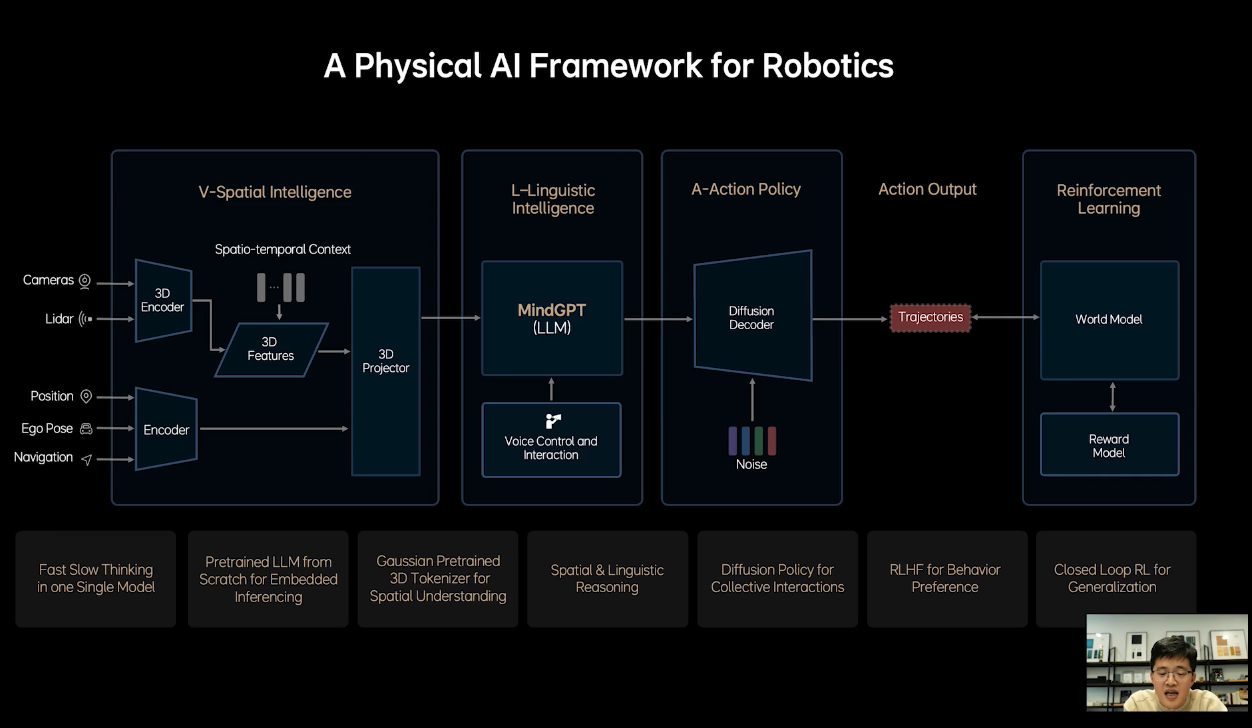
Ultimately, with the aid of VLA, LI Auto aims to achieve the driving scenarios described initially. When those scenarios truly materialize, cars will resemble four-wheeled robots even more.
Xiaomi’s Yang Kuiyuan: Over 13.6 Million Clips of End-to-End Data
In 2021, Xiaomi Auto was officially launched, and Yang Kuiyuan had already joined Xiaomi Auto. Over the past four years, he has been involved in the entire process from the R&D and mass production to the OTA of Xiaomi SU7’s smart driving.
At this year’s GTC, Yang Kuiyuan from Xiaomi’s Autonomous Driving and Robotics Department shared technical details regarding Xiaomi’s end-to-end full-scenario intelligent driving exploration and modeling in the physical world.Distinguished from traditional modular architecture, end-to-end intelligent driving involves only one model from input to output—extending beyond previous perception modeling to perception regulation and control modeling. For end-to-end intelligent driving, data-driven processes and model generalization capabilities are crucial.
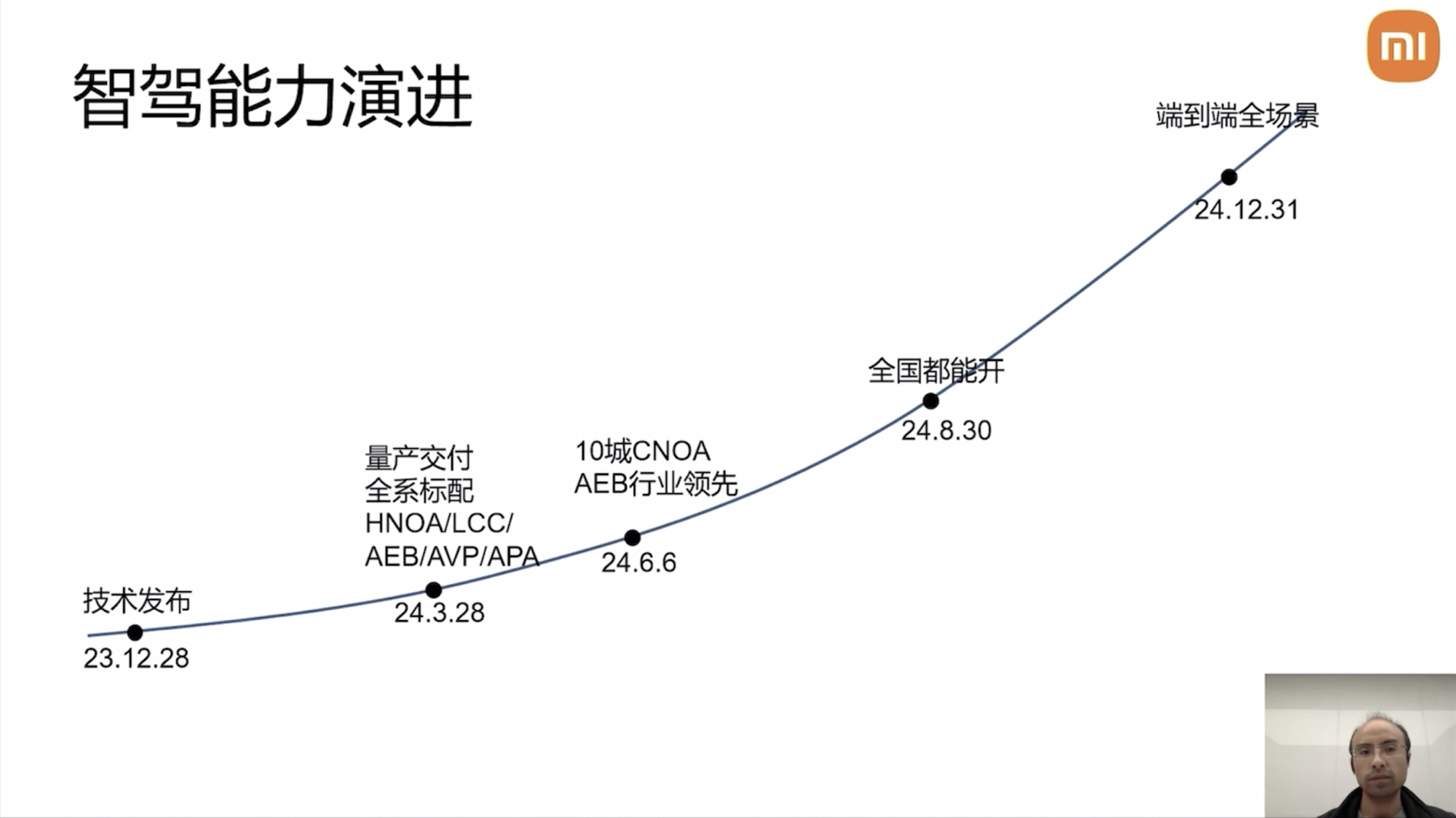
This is also the secret behind the rapid mass production and delivery of Xiaomi’s intelligent driving system. By March 2024, the Xiaomi SU7 will be equipped with high-speed NOA; by August 2024, NOA will be operational nationwide; by the end of 2024, Xiaomi will launch the end-to-end pioneer edition. Currently, Xiaomi’s intelligent driving system is end-to-end + VLM. Yang Kuiyuan stated, “Xiaomi’s intelligent driving has achieved the feat of three generations in one year.”
Yang Kuiyuan mentioned that whether it’s the SU7, SU7 Ultra, or YU7, Xiaomi has fully considered the vehicle’s exploration of the physical world and the realization of advanced intelligent driving demands in its design. Consistency in sensors selection and installation across different models establishes a solid hardware foundation for scalable exploration of the physical world.
Since last March’s delivery, the fleet involved in physical world exploration has exceeded 180,000 vehicles (Xiaomi Auto announced this afternoon that deliveries have surpassed 200,000), and it’s climbing at a rate of 20,000 vehicles per month.
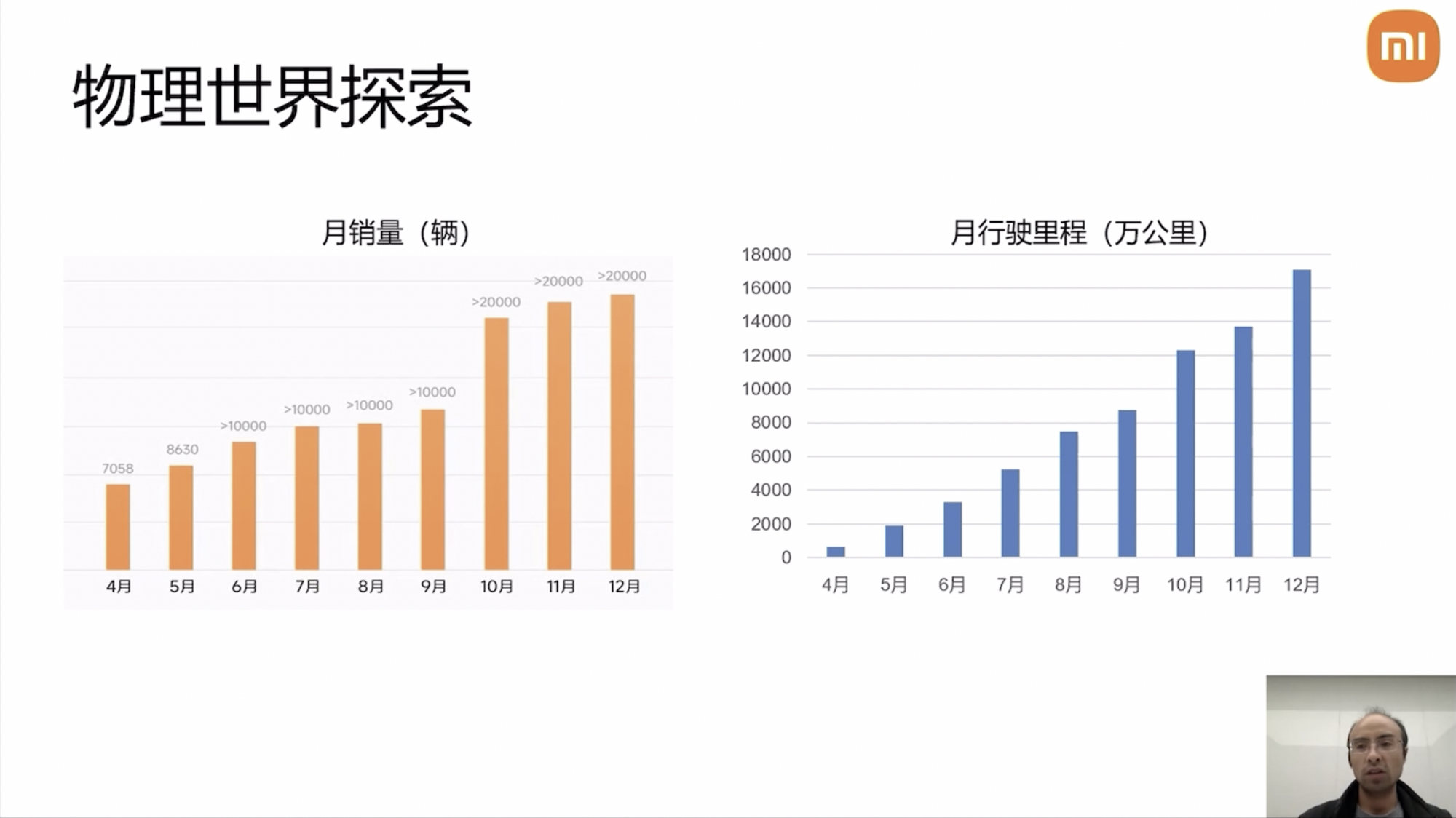
The rapid growth of the fleet also leads to a swift increase in mileage. By the end of last year, the fleet’s daily mileage was 5 million kilometers. Currently, the total daily mileage is approaching 10 million kilometers.
For end-to-end intelligent driving, parking lots, ETC toll stations, urban roundabouts, and rural roads are challenging scenarios. Training these scenarios requires continuous video clips. In Yang Kuiyuan’s presentation last October, Xiaomi Auto’s training data stood at 2.38 million Clips, which accumulated to 13.638 million Clips by February of this year.
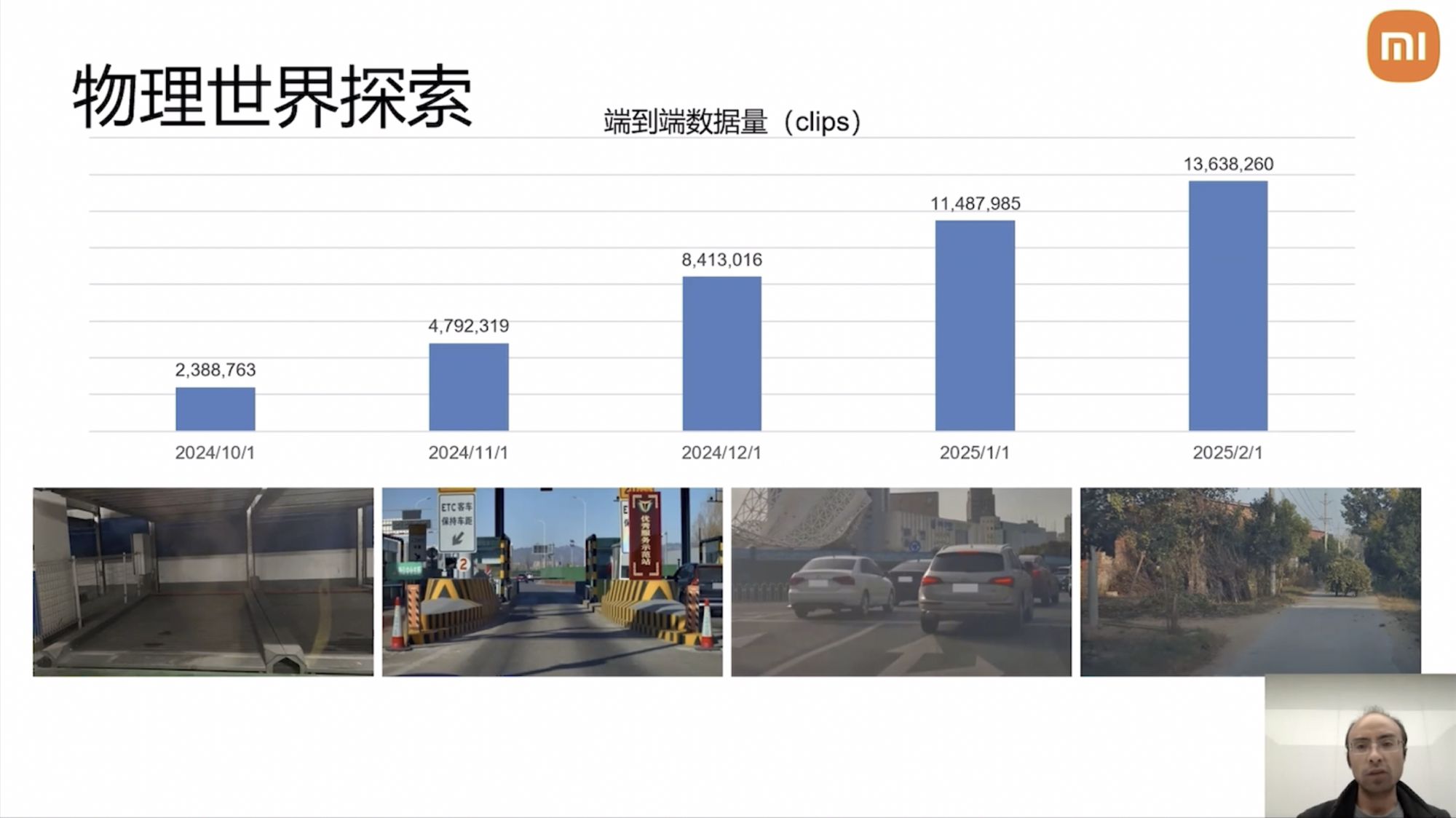
Yang Kuiyuan remarked, “This is also the volume of training data used for the next million Clips in the end-to-end version.”
After obtaining extensive physical world exploration data, it is also essential to model the physical world.
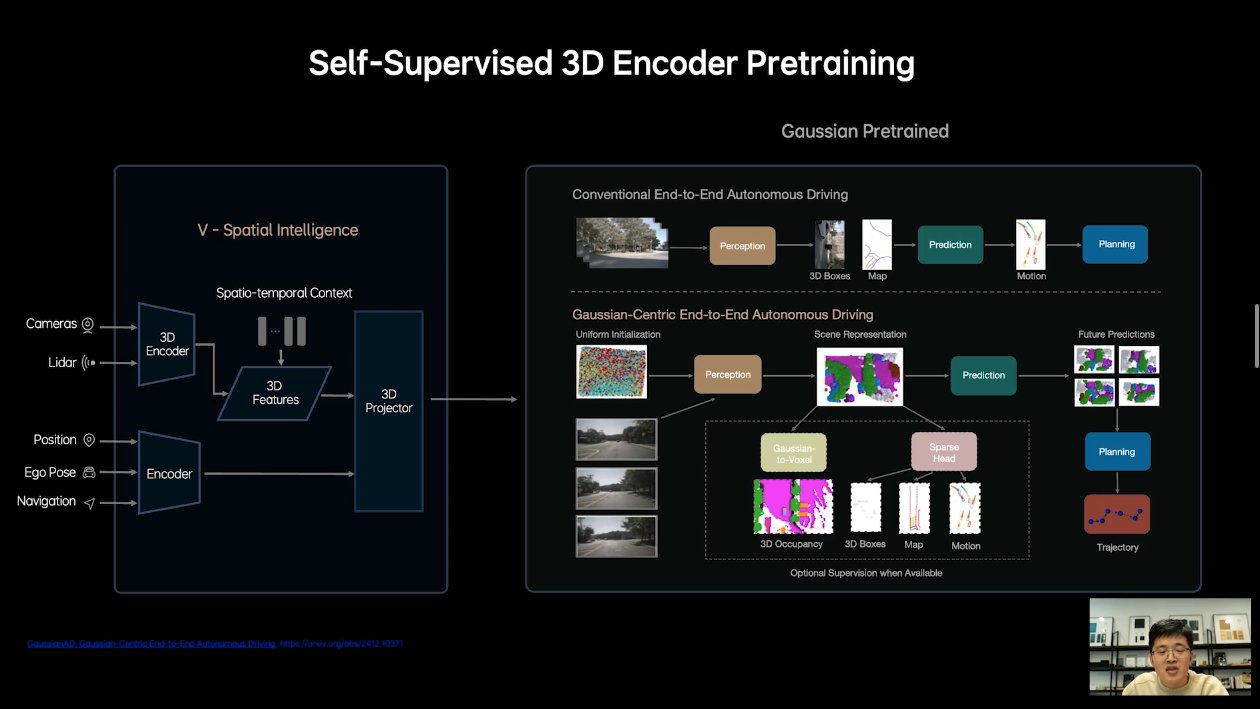
Yang Kuiyuan explained that physical world modeling consists of three layers: Ot (the original data observation layer, recording the physical world through vehicle sensors), Zt (the implicit feature layer of deep neural networks, forming an understanding of the current scene in a data-driven manner), and St (the representation layer for human understanding and operation).
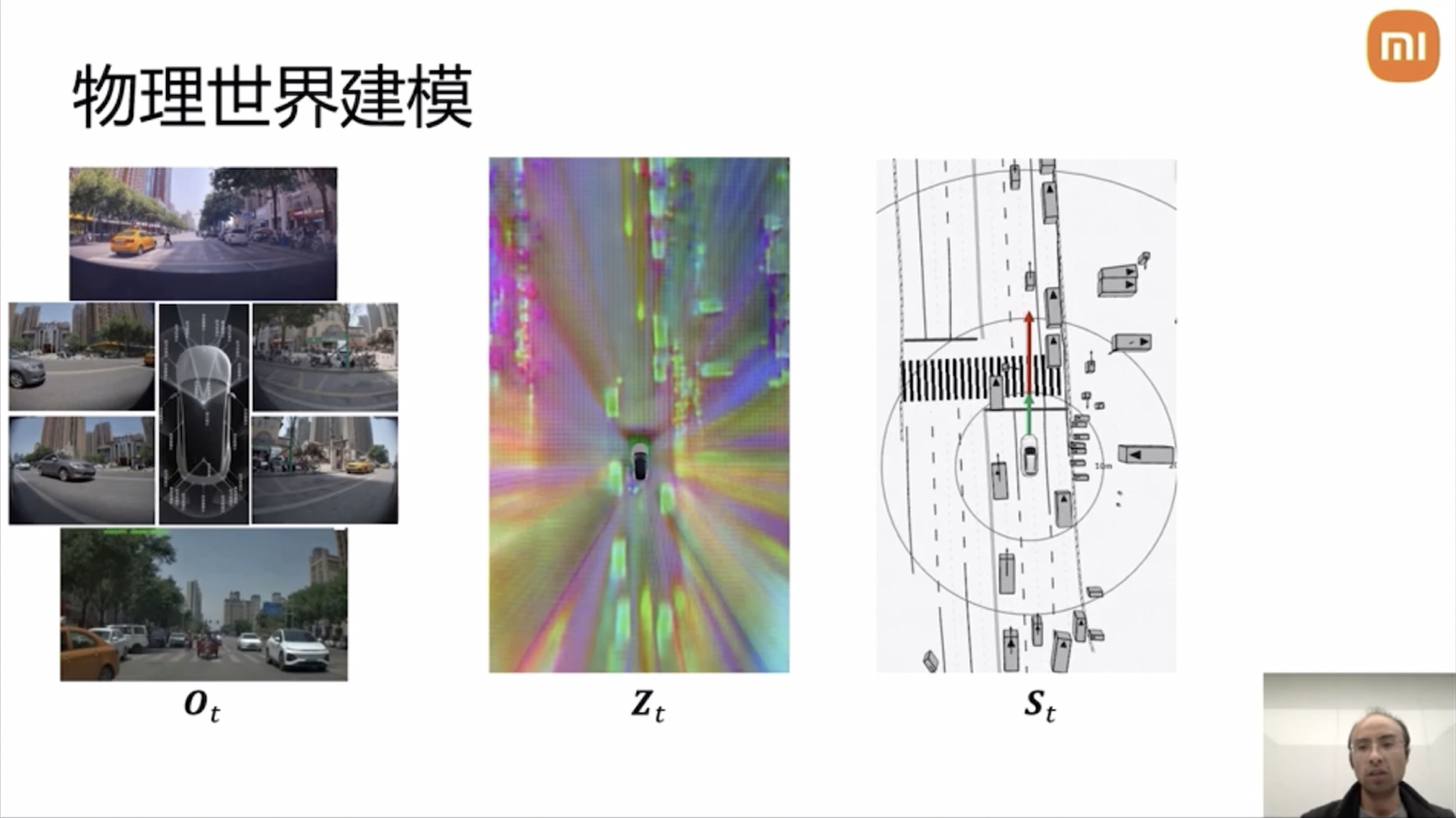 ### Input, Intermediate, and Output Layers in Neural Networks
### Input, Intermediate, and Output Layers in Neural Networks
The data observation layer requires images, LiDAR point clouds, and navigation information (Ot). Through the BEV encoding network, we obtain the BEV implicit representation (Zt), which, through different decoders, yields dynamic elements, static elements, and future trajectories. Various modeling methodologies ultimately pass through manually modeled Costs (including collision Cost, lane departure Cost, and comfort Cost) to constrain the trajectory’s rationality.
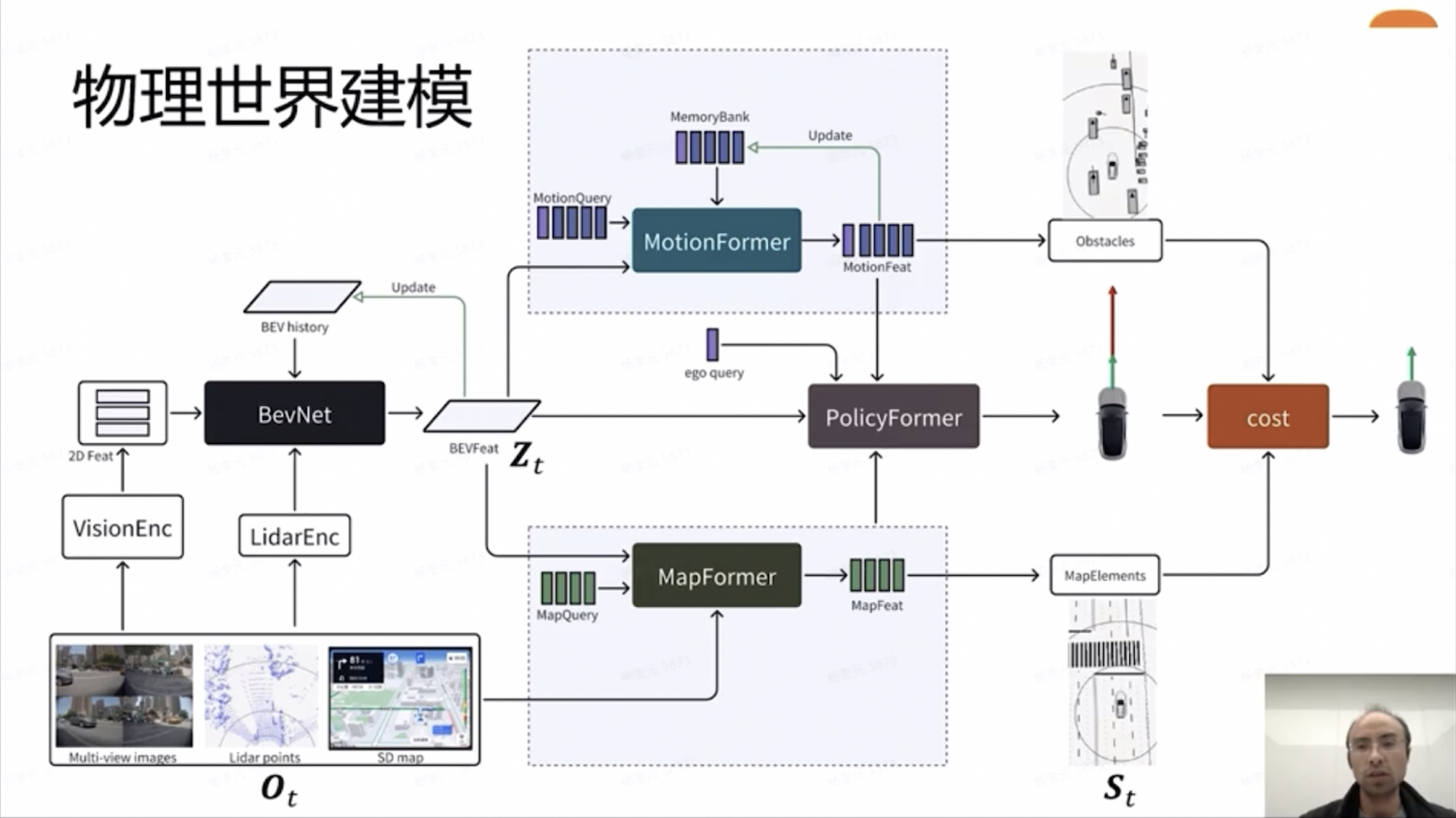
Additionally, there’s a time dimension. Historical frames are easy to model, but future frames, which cannot be directly observed, pose the main challenge and focus of modeling.
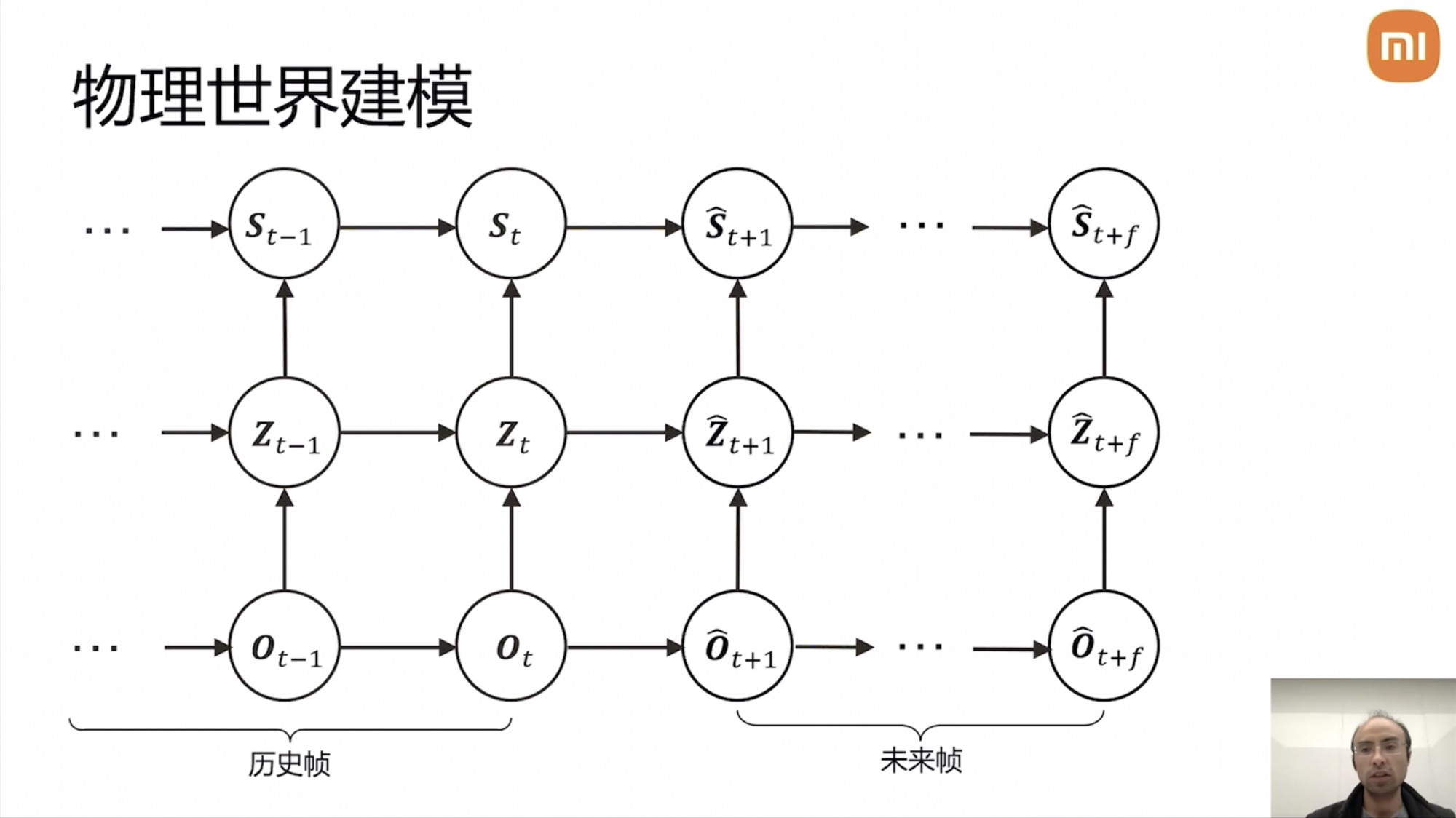
The data observation layer (Ot) has many tools at its disposal, such as 3DGS reconstruction technology or OpenAI’s Sora, Nvidia’s Cosmos, etc. Large model generation can fit the probability distribution of raw data directly, and with additional historical frame images, implicit features, and explicit symbols as control conditions, original signal generation can occur. This generation part is relatively slow, primarily simulating the physical world in the cloud for closed-loop simulation evaluation and long-tail data generation. However, these models mainly aim to restore sensor detail signals and have limited understanding capabilities. Of course, there are combinations of generation + understanding in implicit feature spaces.
In the intelligent driving domain, there is no mature foundational model for stable feature expression generation.
In the explicit symbol layer, humans can directly code operations, leveraging the existing modeling capabilities humans possess regarding the physical world, using rule-based code to combine with models for temporal modeling, like uniform acceleration and trajectory sampling.
Simultaneously, XiaoMi is attempting to combine the three layers of expression for temporal modeling. It also expands the intermediate implicit features in the temporal dimension to future frames on the deep neural network model, forming a complete spatiotemporal neural network model, unified through data-driven learning. When predicting future frame changes, XiaoMi also processes dynamic and static elements separately.
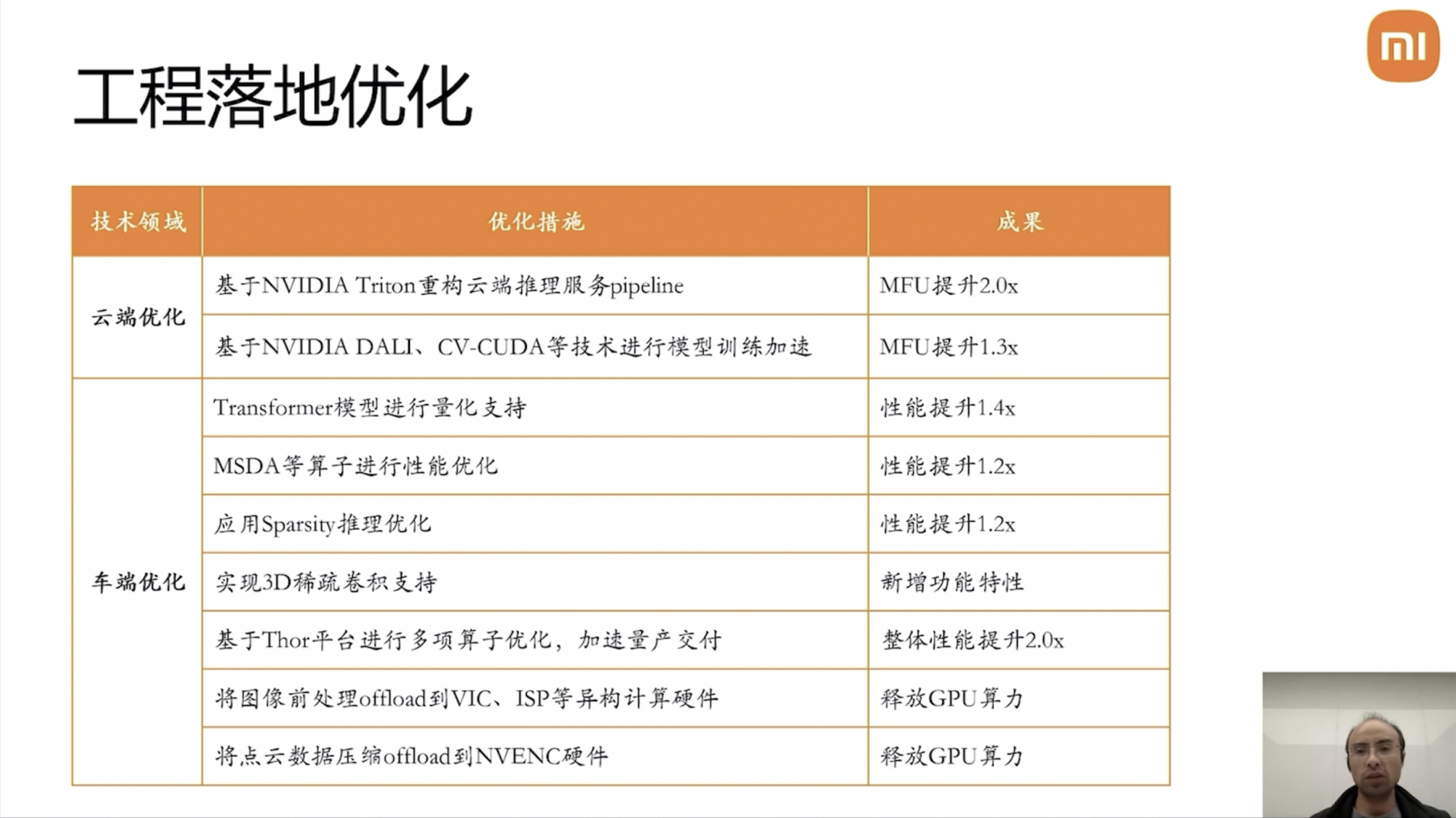
On the engineering front, XiaoMi and Nvidia have undertaken numerous optimizations both on the cloud and on the vehicle end.
Yuanrong Technology CEO Zhou Guang: VLA on Board Mid-Year
In the speech, Zhou Guang first addressed Yuanrong Technology’s progress in the intelligent driving field over the past year.
Last year, Yuanrong Technology’s intelligent driving solutions were deployed in two vehicle models (WEY Lanshan and smart Genie 5). It is expected that this year, over ten intelligent driving models will be launched. By the fourth quarter of 2024, Yuanrong Technology is projected to achieve a 15.3% market share in the domestic urban intelligent driving market.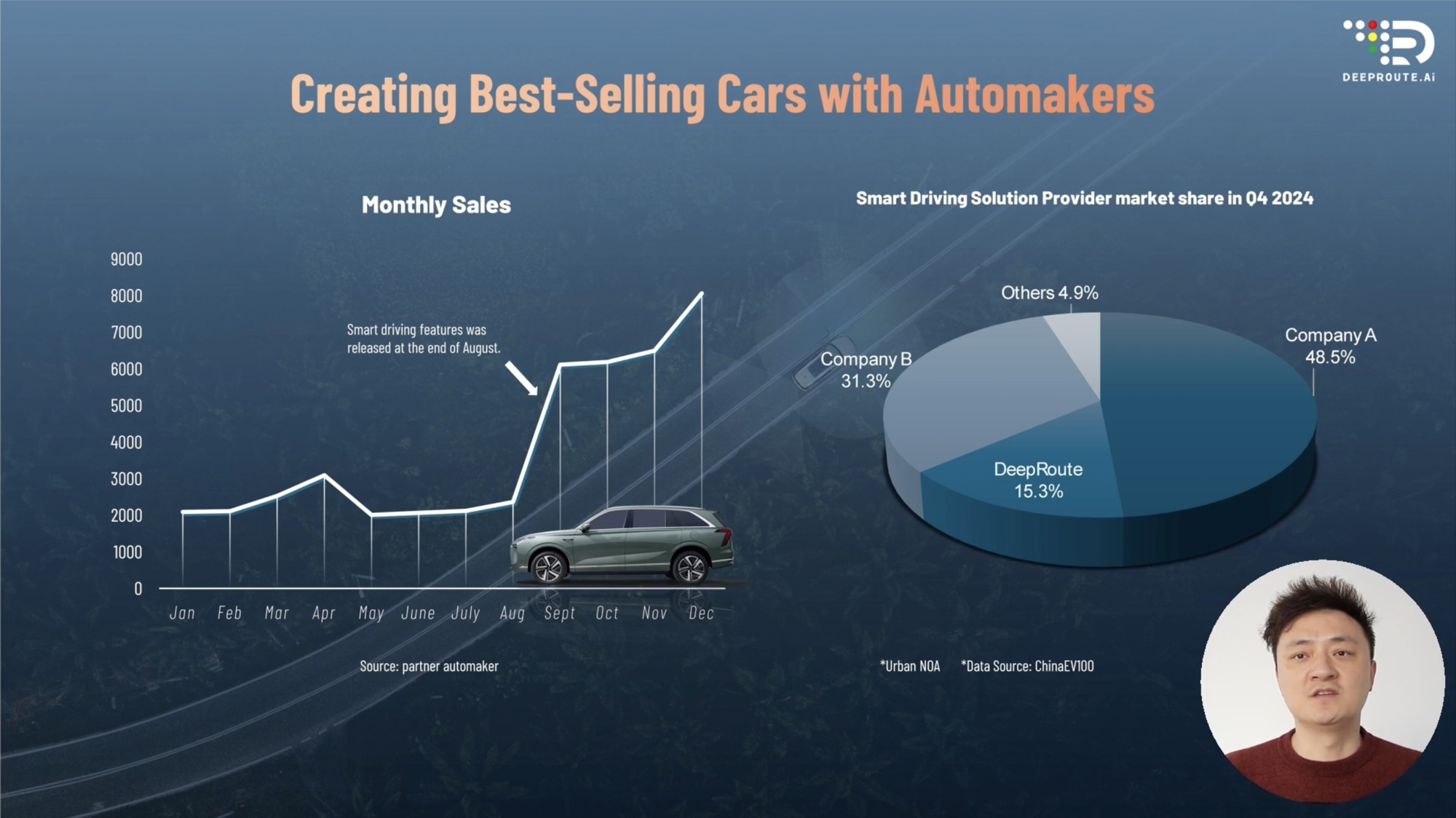
Currently, Weride’s intelligent driving solution is already integrated into over 40,000 vehicles. By the end of February, the total mileage of Weride’s intelligent driving has reached 40 million kilometers. Zhou Guang expects that this year, 200,000 units will enter the market, and by 2026, 500,000 vehicles will be equipped with Weride’s intelligent driving system. Additionally, Weride has begun road testing in Germany.
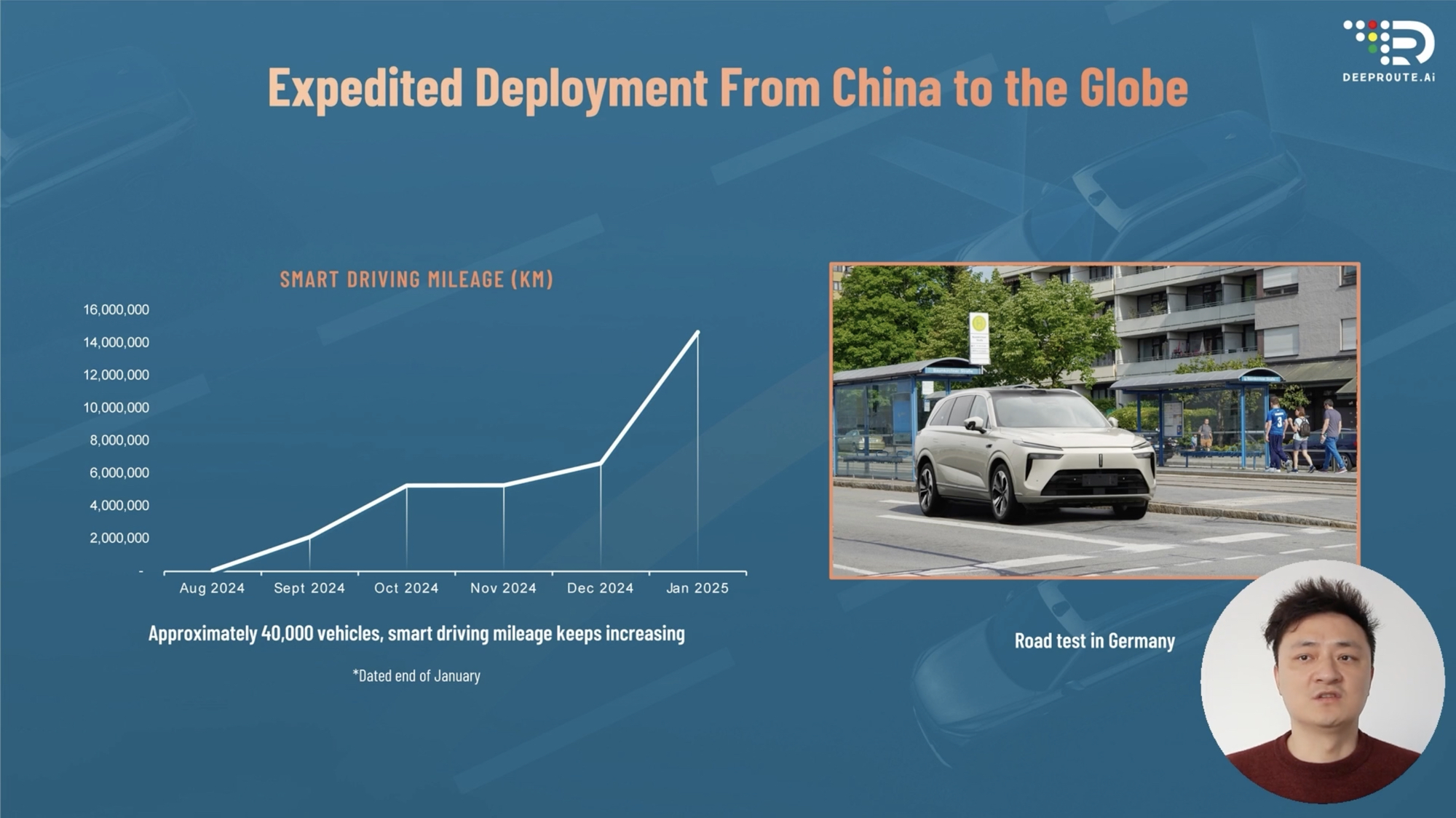
Alongside the rapid integration into vehicles, Weride’s next-generation intelligent driving system is also under development. Last September, Weride began developing the VLA model, aiming to leverage it to handle complex edge cases. According to the schedule, Mid-year the VLA model will be deployed across multiple models.
Zhou Guang presented the architecture of the Weride VLA model:
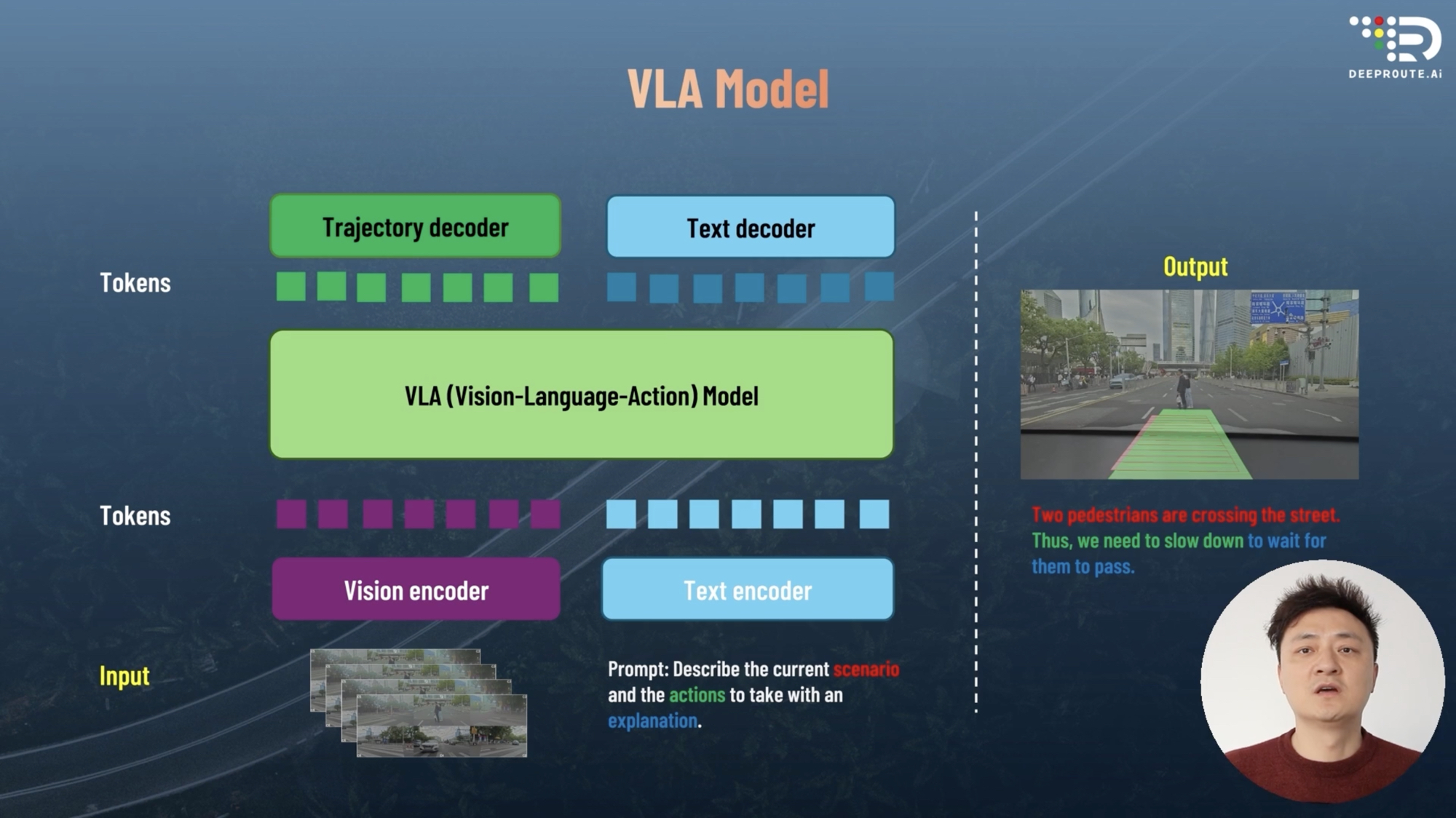
- At the bottom is the Input layer. It includes image inputs from sensors like cameras and textual inputs, which could be instructions from vehicle occupants or information from smart cockpits and navigation systems.
- The next layer consists of visual and textual encoders. The visual encoder processes input images to extract features, while the textual encoder captures semantics to understand text commands.
- Above that is the vision-text fusion, which is the core of the VLA model, enabling the model to comprehend both image and text instructions simultaneously.
- Finally, the output includes driving behaviors and text outputs.
In fact, the VLA model has numerous advantages, one of the primary being its compatibility with existing large language model paradigms. The VLA model also adheres to the Scaling Law, where performance improves with increased model parameters. Moreover, it is enhanced through pre-training, post-training, and continuous training, and is compatible with DPO, RLHF, and GRPO technologies. Additionally, the chain of thought can be directly utilized for inference and decision-making (consideration of tide lanes).

Another core advantage of VLA is its capacity to make intelligent driving more human-like. By incorporating rule-based preferences into the model, VLA aligns with human-expected driving decisions. This means the VLA model can prioritize safe driving behaviors, reducing bad habits in real-world scenarios. Moreover, it can select optimal routes based on human preferences.
Zhou Guang also specifically addressed the challenges of VLA:* Most importantly, the ability for real-time response. Based on the NVIDIA AGX platform, the current generation product VLA processes at approximately 5 FPS, with the next generation platform reaching speeds of 20 FPS.

- Data. A rich collection of real-world data is required, with VLA development prioritizing the use of real-world data, which is far more complex than a simulator.

After the release of the VLA model, Yuan Rong’s next target is the realization of Road Artificial General Intelligence (RoadAGI).
During the speech, Zhou Guang presented a video of an unmanned delivery vehicle equipped with a robotic arm, capable of point-to-point autonomous driving from community to community and shop to shop, much like a delivery person. It navigates through narrow pathways next to gate machines, accurately identifies storefronts, and arrives at the pickup point of the takeaway shop. After the shopkeeper places the takeaway inside, the vehicle delivers the order by traversing sidewalks and crossing streets.

The first delivery was to a takeaway locker. This was a highlight, as a robotic arm inside the delivery vehicle autonomously placed the takeaway into the locker, then closed it.

The second delivery was to a business reception desk. The delivery vehicle navigates the gate, uses a robotic arm to operate the elevator, and leaves the takeaway at the company’s reception.

In the presentation, Zhou Guang did not specify whether this unmanned delivery vehicle will be mass-produced, but such capabilities might be Yuan Rong’s vision for RoadAGI.
SenseTime Yueying Wang Xiaogang: End-to-End Production This Year
At NVIDIA GTC, SenseTime Yueying CEO Wang Xiaogang announced that UniAD has received project designation and will be mass-produced this year.

UniAD is an end-to-end intelligent driving solution developed by SenseTime Yueying. It was proposed in 2022, and officially released in November last year.It is noteworthy that UniAD is developed based on NVIDIA’s Drive AGX platform using MIG technology, supporting both end-to-end and traditional rule-based dual-system operations. According to Wang Xiaogang, SenseTime’s Phantom maximizes the synergy of dual systems on this basis, designing the first mass-produced, extremely safe end-to-end intelligent driving solution, ensuring driving safety in complex interactive scenarios.
Simultaneously, Wang Xiaogang introduced Phantom’s world model, “Enlightenment.” He stated that Enlightenment can comprehend the physical laws and traffic regulations of the real world, generate scenarios with high controllability, and manage scenarios with “element-level” precision, fully meeting the high data quality standards required for end-to-end model training and simulation.

The data production efficiency of Enlightenment is also notably high. Wang Xiaogang mentioned that with just one NVIDIA A100, Enlightenment’s average daily data production capacity is roughly equivalent to the data collection capacity of 100 road test vehicles.
Moreover, through the world model, Enlightenment can achieve diversified and realistic scenario simulations and expert trajectory generation, ultimately forming a closed-loop data and self-iterative capability for end-to-end intelligent driving.
Regarding the comprehensive capabilities of the Enlightenment large model, Wang Xiaogang indicated it could significantly lower the data threshold for end-to-end model training and potentially achieve driving performance far surpassing human capabilities through extensive exploration of various possibilities.
Besides UniAD, Wang Xiaogang also introduced SenseTime’s achievements in smart cockpits — A NEW MEMBER FOR U.
“A NEW MEMBER FOR U” is an emotional companion, released last November. Wang Xiaogang shared that “A NEW MEMBER FOR U” exhibits high sensitivity and interaction enthusiasm, continuously inferring user needs, evolving through memory, remembering user habits, and even proactively reminding children in the car not to eat too much candy.

In terms of experience, “A NEW MEMBER FOR U,” relying on an Always-on framework, achieves zero-copy transfer and supports continuous inference, with an inference speed of up to 96 tokens per second, allowing for more real-time responses in complex scenarios.
Finally, Wang Xiaogang highlighted that by 2026, SenseTime’s Phantom, in collaboration with NVIDIA, will achieve mass production and deployment of cockpit-driving integration products across major car manufacturers, accelerating the entry of intelligent vehicles into the AGI era.
Zhuoyu’s Chen Xiaozhi: Making Intelligent Driving More Personal
At NVIDIA GTC, Zhuoyu AI’s CTO Chen Xiaozhi pointed out an issue — current end-to-end intelligent driving, learned through data training, results in an average driving style. However, in actual driving, everyone has their unique style, indicating a significant gap between end-to-end intelligent driving and real human driving.
Therefore, the goal of Zhuoyue is to enable end-to-end intelligent driving to move beyond its average driving style to meet the personalized driving needs of users that may be aggressive or conservative. This personalization involves three aspects:
- Personalized driving style, requiring the system to understand user driving behavior over a long period;
- Personalized driving style, meaning specific driving actions meet the user’s personalized requirements;
- Support for voice interaction.
Zhuoyue summarizes this technical solution as a “Generative Intelligent Driving Experience.”
To achieve the “Generative Intelligent Driving Experience,” according to Chen Xiaozhi, Zhuoyue first completes intelligent driving pre-training and post-training based on the world model. The pre-training solidifies the basic capabilities of intelligent driving on a weekly iteration pace, while the post-training addresses tail-end problems with daily iterations.
Next is end-to-end prompt reasoning, where users can voice prompt the intelligent driving system, thus allowing it to more clearly understand user intentions and ultimately deduce a driving trajectory that aligns with the user’s intent.
Additionally, Chen Xiaozhi mentioned that the “Generative Intelligent Driving Experience” is applicable to any hardware configuration and has a relatively weak dependency on prior maps.
According to official information, Zhuoyue’s “Generative Intelligent Driving Experience” is built on the NVIDIA DRIVE AGX platform. Additionally, Zhuoyue has developed an integrated large model for both the cockpit and driving domains on this platform. Chen Xiaozhi stated, in simple terms, it essentially means that the intelligent driving domain and cockpit domain share a set of LLM large models.

As for when the aforementioned “Generative Intelligent Driving Experience” will be implemented, Chen Xiaozhi indicated that Zhuoyue will mass-produce it within this year.
Final Note
The NVIDIA GTC conference has witnessed the collective explosion in the Chinese intelligent driving field. This year, VLA models and end-to-end technologies are the core paths to more user-friendly intelligent driving. Companies like LI Auto and Yuanrong Qixing have pioneered the VLA architecture, merging language commands with driving decisions, turning vehicles into true “four-wheeled robots” capable of understanding human intentions.
In this technological revolution, NVIDIA’s computing power base and toolchain play crucial roles, helping automakers bridge the gaps in perception, decision-making, and execution. With VLA being implemented and end-to-end mass production scaling up, by 2025, the intelligent driving competition will focus on scene generalization ability and personalized user experiences. As carmakers and tech companies join forces to break through technological boundaries, intelligent driving is advancing from functional modules toward Artificial General Intelligence (AGI), and the ultimate goal of this transformation may be to redefine the interaction between humans and machines.生关系。
This article is a translation by AI of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.