
Automatic Driving Environment Perception Algorithm Series: Attention Mechanism Part 1
Author: Engineer in the Witch’s Tower
Foreword:
As the author of this series, my Zhihu ID is “Engineer in the Witch’s Tower”. I am a perception algorithm engineer/leader in an automatic driving technology company.
This series of articles focuses on the knowledge related to the “automatic driving environment perception algorithm” and is written by the invited author “Engineer in the Witch’s Tower”. It is exclusively published by the media “Yan Zhi New Energy Vehicles”.
As a column that focuses on automatic driving environment perception, the introduction to this part of the content is essential. There are many articles about attention mechanisms and Transformers, and some of them are well-analyzed and explained.
One of the core tasks of automatic driving environment perception is “object detection”, so this article will focus on introducing it from this angle.
This attention mechanism topic includes three articles:
- In the first article (this article), I will review some attention mechanisms commonly used in visual perception algorithms, especially object detection algorithms.
- The second article will introduce the application and latest progress of Transformers and self-attention mechanisms in the field of object detection, and will also include discussions in the academic and industrial fields in this direction.
- The third article will introduce the recently rising BEV perception method, in which cross-attention mechanism plays a crucial role.
In recent years, attention mechanisms have been popular in the field of artificial intelligence.
The Transformer model based on self-attention mechanism first achieved a significant performance improvement in the field of natural language processing (NLP), replacing the previously commonly used recurrent neural network structure (RNN).
Afterward, the Transformer was also applied to the field of computer vision and demonstrated powerful potential in visual tasks such as image classification, object detection, and semantic segmentation.
In an automatic driving system, visual perception is a critical module, so the Transformer model naturally attracts widespread attention.
Early Attention Mechanisms
The word “attention” has been frequently mentioned in various fields of artificial intelligence in recent years, and people are a bit tired of hearing it.
Actually, attention is not a particularly new concept. Just like convolutional neural networks (CNN), the concept has existed decades ago, but at that time, limited by data volume, computing power, and training methods, its effect was not ideal and did not attract widespread attention.
In the field of computer vision, attention mechanisms have always been one of the popular research topics, but the early research mainly focused on how to extract the salient parts of the data.
This method usually adopts a bottom-up approach, starting from low-level features and using some pre-defined indicators to calculate the salient parts of the image or video data.Here is a typical example: in a photo of animals, the algorithm will identify the animals instead of the background as the salient region.
Although this saliency extraction method has similarities with human perception, it is actually more like a foreground-background segmentation, with the implicit assumption that the foreground is more salient than the background.
This simple data and its simplistic assumptions may not suffice in practical applications.
In actual applications, we usually have a specific task, so saliency extraction also needs to be driven by the task, which is to say, adopting a “top-down” approach.

As mentioned earlier, object detection is one of the key tasks in visual perception. Therefore, this article will take object detection as an example to introduce top-down attention.
Actually, attention has always been studied in the development of object detection, but it was not always apparent.
Before the rise of neural networks, object detection mainly relied on feature and classifier design. To improve the detection efficiency, researchers would first use simple features to filter out most of the background region in the image, and then use complex features to process the remaining region.
This is a typical “from rough to fine” process that was very common in the early development of object detection. Here, the “remaining region” is actually the saliency region, and rapid saliency region extraction can greatly increase the speed of detection algorithms.
Even after neural networks became widely used in object detection, this “from rough to fine” strategy still exists.
Recall the two-stage detector based on neural networks. The goal of the first stage is to obtain the Region of Interest (ROI) in the image, and then process the ROI further in the second stage to obtain information such as the object’s category, position, and size.
Here, the ROI is actually the concept of the saliency region, which is essentially no different from the saliency region obtained by traditional methods using simple features.
However, we need to note that whether it is a traditional method or a neural network-based method, the model is obtained through training, and saliency region extraction is also task-driven and top-down.
Attention Mechanisms in Neural NetworksThrough the analysis above, we can roughly divide attention mechanisms into two types: “bottom-up” and “top-down”.
The former is not associated with specific tasks, whereas the latter is task-driven.
During the Big Data era, what has attracted more attention is the “task-driven” or “data-driven” approach.
The top-down attention mechanism discussed in the previous section, whether applied in traditional or deep learning methods, acts at the ROI level and is a relatively coarse-grained way of expressing attention.
Apart from this method, what people are currently discussing more is a fine-grained attention, which is typically expressed in neural network models as follows:
- Channel attention;
- Spatial attention;
- Branch attention;
- Self-attention;
- Cross-attention.
Let’s now introduce several frequently used attention mechanisms.
Channel Attention
In a neural network model, each layer has multiple feature channels for input and output. Each channel describes different information in the input data, such as the texture, color, and shape of objects. The importance of different pieces of information also varies for different downstream tasks.
Take vehicle detection as an example. It may rely more on shape information, while lane detection may rely more on texture and color information.
For a general object detection network, its feature channels would contain various types of information. When a vehicle appears in the input image, the neural network would automatically assign more weight to the channels containing shape information, in order to better accomplish the task of vehicle detection.
Of course, this is just an intuitive explanation. The actual channel weighting process may be very complex and not necessarily easily interpretable.
This is the basic design motivation behind channel attention.
One thing to note is that the channel weights are not pre-learned but are adjusted online based on input data.
This dynamic attention mechanism enables neural networks to have great flexibility in handling different tasks.
The basic approach of channel attention is to calculate a weight for each channel.
This weight is obtained through global or local operations, by which multiple channels interact with each other. An important step here is “extracting channel descriptive features”, which usually involves global average pooling to obtain a scalar feature for each channel.
Squeeze&Excitation Attention, also known as SE Attention, is a typical method that uses channel attention.
This method performs global average pooling on each channel, compressing the channels down to a scalar value (squeeze).A vector is formed by scalar values from multiple channels, which are processed by fully connected layers (FC) and then transformed into values between 0-1 using the Sigmoid function. These values correspond to the weights of different channels.
This weighting process for channels corresponds to Excitation in SE.
Based on SE Attention, many works have extended it in two main aspects:
- First, the extraction of channel features;
- Second, how to obtain weights from channel features.
For the former, SE Attention uses global mean pooling to extract channel features, which can be seen as a first-order feature extraction method.
Improved solutions typically use second- or higher-order complex features.
For the latter, SE Attention uses fully connected layers to generate weights, so the weight calculation for each channel includes information from all channel features, making it a global calculation method.
Improved solutions usually use 1D convolutional operations for local weight calculation, which means that weight calculation for each channel is only related to its adjacent channels.
Spatial attention is easier to understand than channel attention.
Similar to saliency maps, the basic idea of spatial attention is to assign different weights to different spatial positions to reflect the region that the model focuses on.
The difference is that saliency maps are a bottom-up approach and are not directly related to tasks and data, while spatial attention is completely “task- and data-driven.”
Spatial attention, like the coarse-to-fine strategy in object detection, operates on the spatial dimension.
However, the difference is that object detection uses a hard attention mechanism, that is, it directly discards unattended regions, and this operation is based on the object box. Spatial attention, on the other hand, acts on pixels in the image or feature map, weighting each pixel instead of selecting or discarding some pixels.
Therefore, spatial attention is considered a pixel-level soft attention mechanism.CBAM (Convolutional Block Attention Module) proposes a typical spatial attention calculation method. The basic idea is to use pooling to compress multiple channels of the feature map into a single channel. The resulting single-channel feature map will be processed by convolution and sigmoid operation to obtain a spatial attention map with values ranging from 0 to 1.
As shown in the figure below, CBAM uses both max and mean pooling and then concatenates the obtained features before compressing them into a single channel.

This spatial attention calculation method is similar to channel attention, except that the former compresses the feature map along the channel dimension, while the latter compresses it along the spatial dimension.
Spatial attention is finally presented as a single-channel 2D map, while channel attention is presented as a 1D vector.
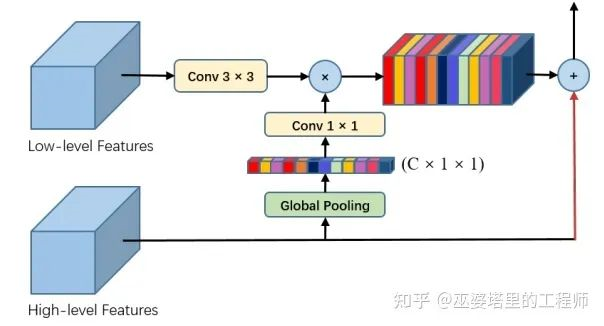
Since spatial attention and channel attention describe different dimensions of data, some researchers propose to combine both. For example, in Pyramid Feature Attention, the low-level features in the main network are used to calculate spatial attention, while the high-level features are used to compute channel attention.
Channel attention is more task-related (refer to the object detection example in the previous section), so it requires high-level features containing more semantic information. The channel attention based on high-level semantic information helps generate spatial attention and also assists in selecting detailed information in a certain extent.
Branch attention
Neural network structures often involve multiple branches, such as the shortcut branches in the ResNet structure, the multiple branches with different convolution kernels in the Inception structure, and the branches with different resolutions in the pyramid structure.
The features of these branches are often combined (concatenated) to form new features. The weights of the combination are learned through network training and fixed to be static, which are irrelevant to the current input data. That is to say, these weights are static.To make feature combinations more flexible and better adapt to the current input data, we can adopt attention mechanisms to dynamically weight different branches in Highway Networks. Similar to ResNet, two branches (one shortcut branch and one normal feature transformation branch) are assigned dynamic weights that are obtained by processing the input data.
In the equation below, x represents the input data and the output of the shortcut branch (without any processing), while H represents the normal feature transformation branch. The two branches are dynamically weighted using T (transform gate) and C (carry gate), both of which are functions of the input data x and thus vary dynamically with the data. In general, we can assume that C and T are related, i.e., C = 1 – T, and the equation below can be further simplified.

In the Selective Kernel Network, different branches use convolutions with different kernel sizes to extract features with different receptive fields. This structure is similar to the Inception network, but the different branches are also combined using dynamically weighted mechanisms.
As shown in the figure below, the features generated by two convolutions with different kernel sizes (3×3 and 5×5) are combined, and a series of processing steps are taken to generate the combination weight. This dynamic combination weight is finally used to combine the features from the two branches.

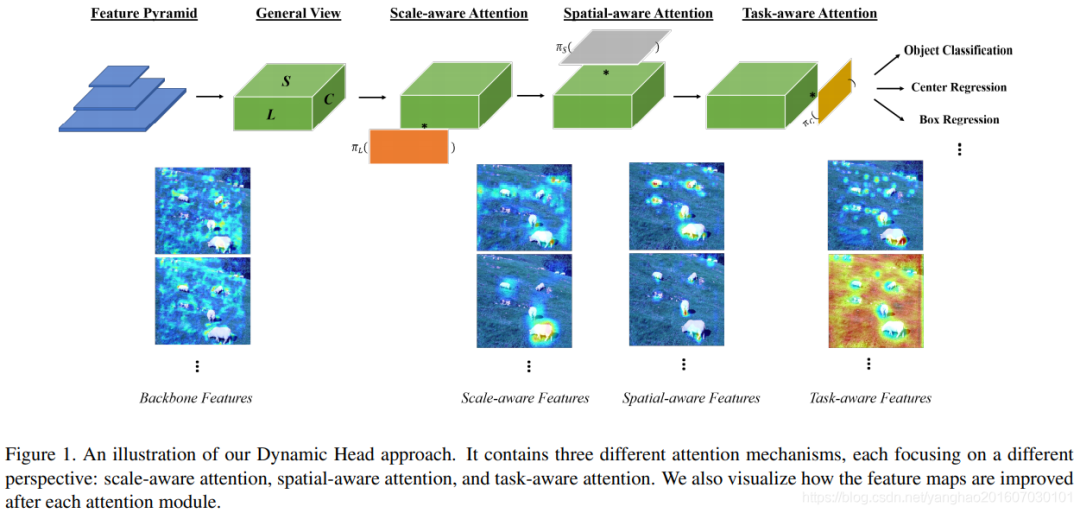
In the Dynamic Head work of the Selective Kernel Network, different resolution features in the pyramid structure are also dynamically weighted, as shown in the Scale-aware Attention in the figure below. This work also uses spatial attention (corresponding to Spatial-aware Attention) and channel attention (corresponding to Task-aware Attention).
Self-Attention# Translation results:
If you’re not familiar with the famous Transformer, Tesla has pushed the application of the Transformer’s ideas to a climax in the market.
The “self-attention mechanism” used in Transformer is mainly based on calculating the correlation between input data and re-encoding input data based on this correlation.
In theory, self-attention does not limit the scope of its operation, and the basic form of its input data is a set of elements. These elements can come from data at different time points in a sequence (time dimension), different positions on an image (spatial dimension), or even from different channels (channel dimension).
In this sense, depending on the input data, self-attention can also be considered spatial attention or channel attention.
Of course, generally speaking, self-attention operations in the visual field are usually performed in the spatial dimension. The self-attention mechanism was first used in the field of natural language processing (NLP) to process text data in sequence form and achieved very good results.
Unlike the RNN commonly used for processing sequential data, the self-attention mechanism does not process data in order, but provides global context for each element in the sequence, meaning that each element is connected to all elements in the sequence.
This ensures that no matter how far apart the elements are in time, their correlation can be well preserved. This long-term correlation is usually very important for NLP tasks.
For example, in the example in the figure above, “it” in the sentence refers to “The animal”, but the two elements are far apart, and it is difficult to establish a connection between them if RNN is used to process them in order.
Self-attention, on the other hand, doesn’t care about the order. When calculating the correlation, the importance of each element is calculated based on the semantic information of the data itself, so it can easily extract the correlation between any two elements.
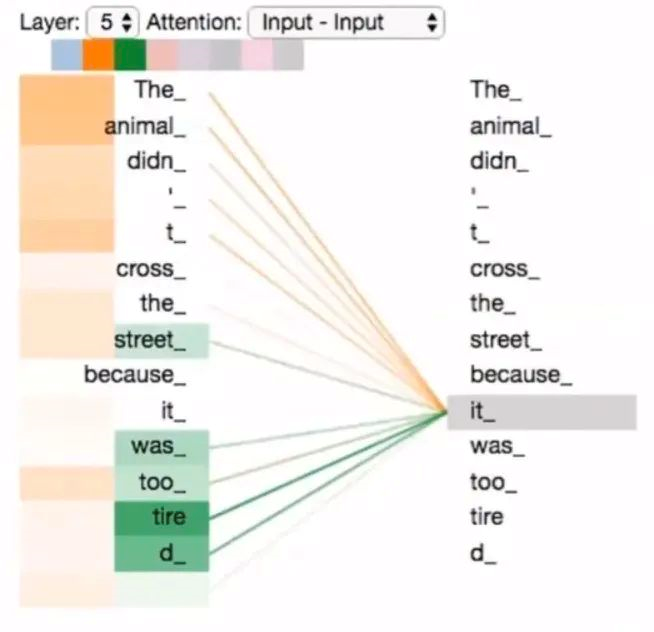
The correlation between each word in a sentence mentioned earlier is an important concept in Transformer, which is the self-attention mechanism.
It is called self-attention because it calculates the relevance between elements in the same sentence and higher relevance elements need to be given more attention.
Still using the example of the sentence in the figure above, each word in the sentence needs to be computed for similarity with all other words (each word has a feature vector).The encoding process of Transformer for each word is to take the weighted average of all words, where the weight is the similarity calculated in the previous step. The representation of each word after encoding is still a feature vector, so the above encoding process can be stacked multiple times to obtain better feature extraction ability.
In the self-attention mechanism, there are three important concepts: Query (Q), Key (K), and Value (V).
Query and Key are used to calculate weights, and then combined with Value to take a weighted average to obtain the final coding output.
The following formula formalizes this process. In self-attention, Q, K, and V all come from the input data X, although they undergo different feature transformations (different W matrices), they are essentially from the same source.
The next section will introduce cross-attention, which is noticeably different from this.

In visual tasks, self-attention mechanism has also achieved great success.
There are two main reasons for this:
First of all, although the image itself is not time-series data, it can be regarded as a sequence in space.
A key step in visual tasks is to extract the correlation between pixels. The ordinary CNN extracts local correlation (also known as local receptive field) through convolution kernels.
Unlike the local receptive field of CNN, Transformer can provide a global receptive field, so the feature learning ability is much stronger than CNN.
Secondly, if we further consider video input data, it is time-series data itself, so it is more suitable to use Transformer to process it.
In the example in the following figure, Transformer is used to complete the task of image classification.
The image is evenly divided into small blocks and arranged in a spatial sequence to form a sequence of image blocks. The pixel values (or other features) of each image block form the feature vector of the image block. After encoding by Transformer and then concatenating, the feature of the entire image is obtained.
The specific structure of the encoder is given on the right side of the following figure, and the key part is a multi-head attention module.
Simply put, multi-head attention is actually an assembly of multiple self-attention modules, and these modules are independently encoded to extract different aspects of features. While increasing the encoding ability, it can also be implemented on computing chips in a parallel way, which is very efficient.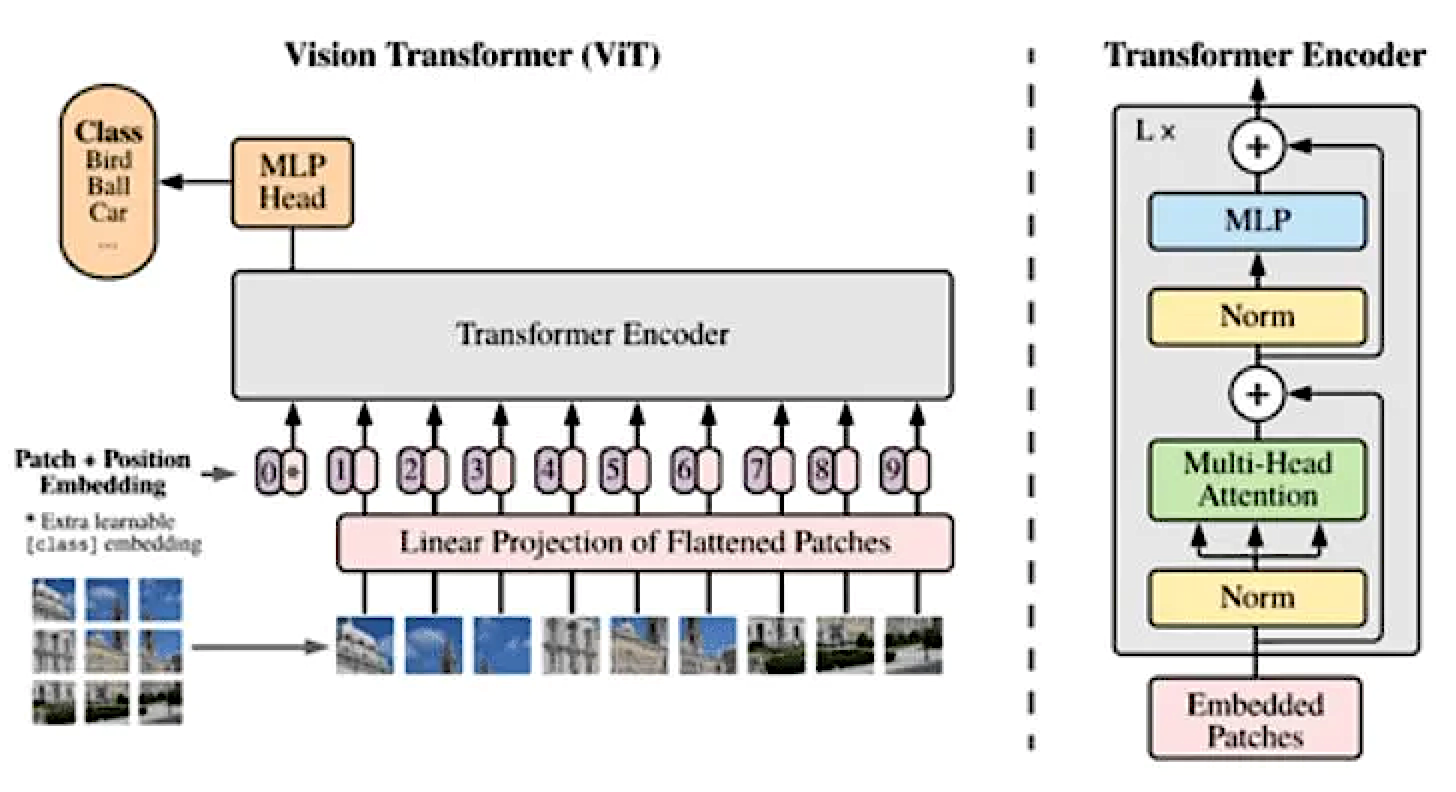
The basic principle of self-attention mechanism and its typical applications in natural language processing and computer vision tasks were briefly reviewed above. The application of self-attention mechanism in object detection tasks will be detailed in the second article of this series.
Cross-Attention
While self-attention extracts the correlation within the same data, cross-attention extracts the correlation between different data.
These data can be different modalities, such as text, speech, and image.
In the application of autonomous driving environment perception, we are generally concerned with data from different sensors. One of the core tasks of perception is to effectively merge these data.
Cross-attention is very suitable for this task, especially when fusing data from different sensors into a unified coordinate system.
In the current autonomous driving system, the collaboration of multiple sensors has become a standard configuration. Even the pure vision solution currently adopted by Tesla includes multiple cameras installed at different locations on the vehicle in its perception system.
For L3/4 level systems, lidar and millimeter-wave radar are currently considered essential configurations.
Different sensors use different coordinate systems, for example, cameras use perspective coordinate systems, while lidar and millimeter-wave radar usually adopt a bird’s eye view coordinate system (BEV).
Sensor fusion requires a unified coordinate system. BEV corresponds to the world coordinate system, which is more suitable for the needs of autonomous driving systems.
Therefore, we generally need to convert image data from different cameras or perception results obtained from image data to the BEV coordinate system before fusing them with data or results from other sensors.
The former corresponds to feature-level fusion, while the latter corresponds to decision-level fusion.
Choosing feature-level fusion or decision-level fusion has always been a hot topic in perception field discussions.
Currently, decision-level fusion is more commonly used in industry. Its advantage is that the independence of different sensors is relatively strong, and the requirements for space and time alignment accuracy are relatively low, so the system design is relatively simple.
In the past two years, with the concept of BEV perception proposed by Tesla at AI Day, feature-level fusion has also gradually become popular, and industrial solutions have also gradually moved in this direction.
The core idea of Tesla’s BEV perception is to use “cross-attention mechanism” to establish a correspondence between image space and BEV space.Each position in the BEV space can be represented by a weighted combination of all position features in the image, of which the corresponding position weight is larger.
This weighted combination process is automatically implemented through cross-attention and spatial encoding, without the need for manual design, and is completely end-to-end learning according to the task to be completed.
Of course, this BEV perception system also includes temporal fusion, camera calibration, and data annotation.
In academia, there have also been a lot of work related to BEV perception recently, one typical method is BEV Former.
Its basic idea is to use the spatial cross-attention mechanism to fuse image data from multiple cameras.
As shown below, the input data are images from multiple perspectives (transformed into image features by the backbone network), and the output result is the fused feature in the BEV view.
To complete this task, it is necessary to define the BEV grid, which will serve as the Query in the attention mechanism and is a set of learnable parameters.
Looking back at self-attention, the Query, Key and Value all come from the input data (image). In cross-attention, the BEV grid from another coordinate system serves as the Query, which is why it is called cross-attention.
In theory, each grid of Query can be associated with features from every perspective and position. But in reality, each grid position only needs to correspond to a portion of the perspective, because a grid position is not visible on all images in all perspectives.
In addition, a grid only needs to correspond to a local area of the image. If it corresponds to the entire image, the computation will be very large, and it is not necessary for the large-scale data in autonomous driving.
Therefore, BEV Former uses Deformable Attention to define this local correspondence relationship.
The above briefly reviews the design motivation of the cross-attention mechanism and its typical application in BEV perception.
The third article in this series will provide a detailed introduction to BEV perception, including some methods that are not based on attention mechanism.
Conclusion
As the first article on attention mechanisms, this article first reviews the history of attention mechanism research, and then introduces the commonly used attention mechanisms and their application in environmental perception.
The main points can be summarized as follows:- Attention mechanism is not a new concept. In the field of computer vision, research on saliency (bottom-up attention) dates back to early times. The strategy commonly used in object detection, from coarse to fine, can also be regarded as a kind of attention (top-down hard attention).
- Attention mechanisms in neural networks generally refer to top-down, or task/data-driven soft attention mechanisms, including channel attention, spatial attention, branch attention, self-attention, and cross-attention.
- Self-attention in Transformers and cross-attention in BEV perception are two types of attention mechanisms that have received significant attention in research. The former is commonly used for feature extraction in visual perception, while the latter is commonly used for feature-level fusion in multi-sensor perception.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.