
The Recap of The 6th Mado AI Day
On the just-concluded 6th Mado AI Day, Gu Weihao, CEO of Mado Zhixing, once again shared a series of latest achievements, thoughts, and new discoveries. What achievements has Mado, which was just established over a thousand days ago, made? What is the next step? Below, let’s review and summarize this Mado AI Day.
Large-scale models
Firstly, at the beginning, Gu Weihao once again emphasized the leading position of the Transformer network based on the Attention mechanism in processing large-scale two-dimensional images. Here, we can simply review the architecture of the Transformer network model. Mado Zhixing introduced the advantages of this network model in the field of image processing in great detail at the end of last year.
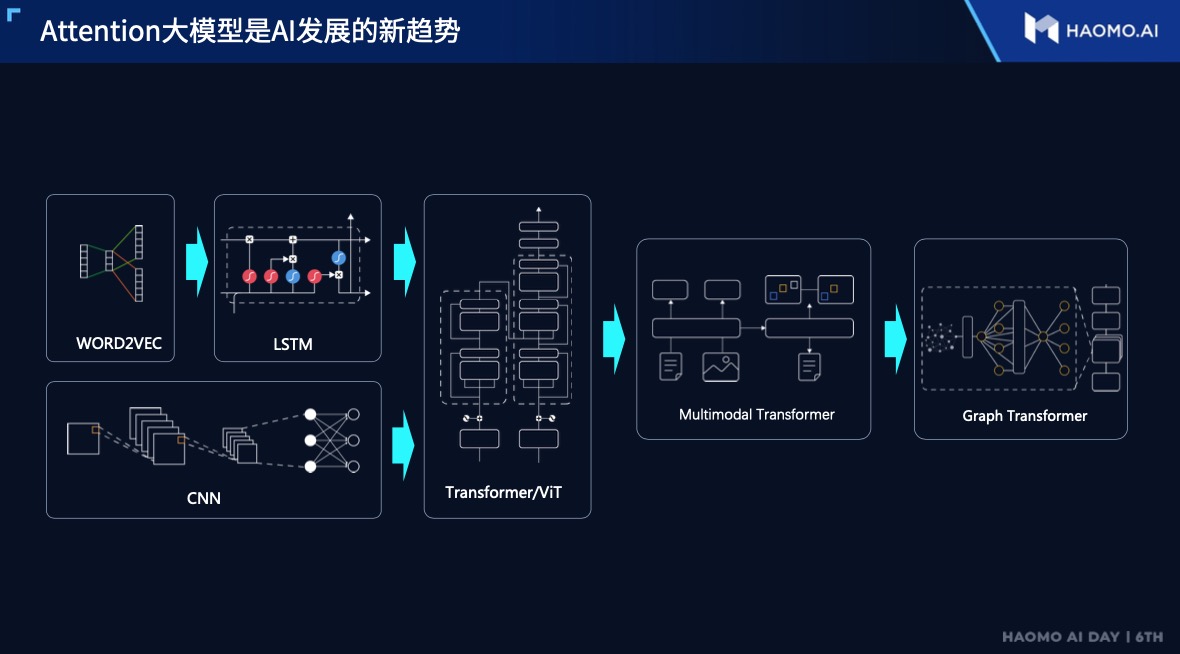
Transformer was first proposed by Google team and used in the NLP (natural language processing) field to process sequence text data. Subsequently, this network model architecture was transplanted to visual processing tasks, and research has shown that the larger the data, the better the Transformer processing effect, which is in line with the current development of the automatic driving route.
Transformer is a network model based on the Attention mechanism, which replaces the original RNN.
What is Attention? In simple terms, the essence of Attention is to let the system focus on key information in different environments and backgrounds. The core logic is from focusing on the global to focusing on the key points.
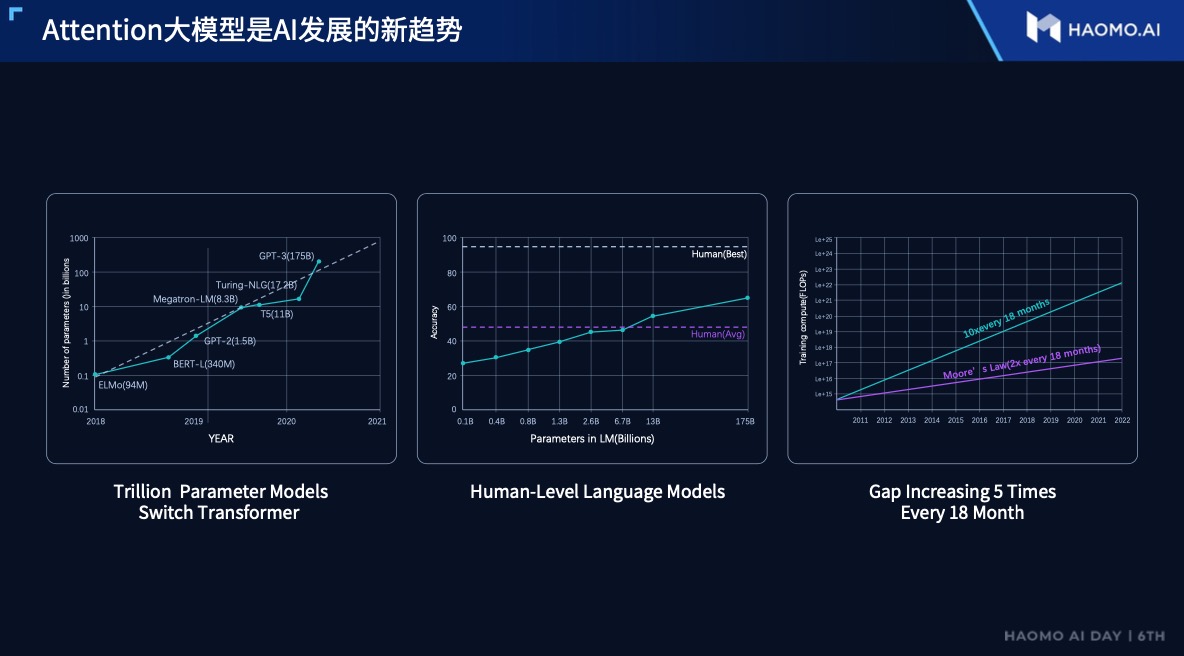
Since 2020, the Attention mechanism has made significant breakthroughs in the field of computer vision, from Google’s VIT to MSRA’s SwinTransformer, easily topping various rankings. People began to notice that the Transformer structure based on the Attention mechanism seems to be an effective general AI model paradigm.Two years ago, Momenta began developing a Transformer model based on the Attention mechanism for autonomous driving. However, it was discovered that the computational power required for a typical Transformer model is 100 times that of CNN, yet only 6.9% of the computational power contributed to 94% of the value, and a lot of weakly correlated and low-value operations caused much waste in multiplication and power consumption.
In order to reduce the overall cost of autonomous driving, Momenta needs to build a low-carbon supercomputer center. Additionally, this type of model architecture needs to be deployed on-board vehicles, requiring modifications and chip design to improve computational efficiency. High data requirements of large models necessitate efficient organization and utilization of data in order to increase iteration speed.
New models bring new requirements for chips. Research and industry are both exploring this field, for example, a new batch of lightweight models that merge CNN and Attention to reduce computation. However, Momenta has not gone into detail on improving chips or models and has focused more on data.
On the data front, Google released PaLM today, an AI NLP model with 540 billion parameters and a training corpus of 780 billion tokens, but so-called high-quality data accounts for only 5%. Momenta believes that in order to widely apply Attention in autonomous driving, at least 100 million kilometers of autonomous driving mileage data is required, and different types, pixels, and angles have great value for large models.
Therefore, Momenta draws the conclusion that assisted driving is the only way to achieve autonomous driving, because only assisted driving has the ability to collect sufficient scale and diversified data.
Is a data-driven era coming? Currently, Momenta’s assisted driving products have produced 17 million kilometers of real mileage. The MANA data intelligence system has accumulated over 310,000 hours of learning, and end-to-end logistics automatic delivery vehicles have delivered nearly 90,000 items to users.
According to Gu Weihao, intelligent driving has entered the 3.0 era. The 1.0 era refers to the hardware-driven era, the 2.0 era is the era when most car companies develop software by themselves, and the 3.0 era is the data-driven era.

In addition, in order for autonomous driving to enter cities, the ability to handle many scenarios will become crucial. For example, the autonomous driving ability in narrow spaces, maintenance roads, densely populated areas, and heavily obstructed areas are all important factors that affect the overall performance of the system. For Momenta, improving the ability of the MANA data intelligent system is directly related to improving the system’s overall performance.
In terms of perception, the industry mostly adopts supervised learning. Although Momenta uses automatic labeling, the time and cost are still high, and it is difficult to process all unlabeled data.
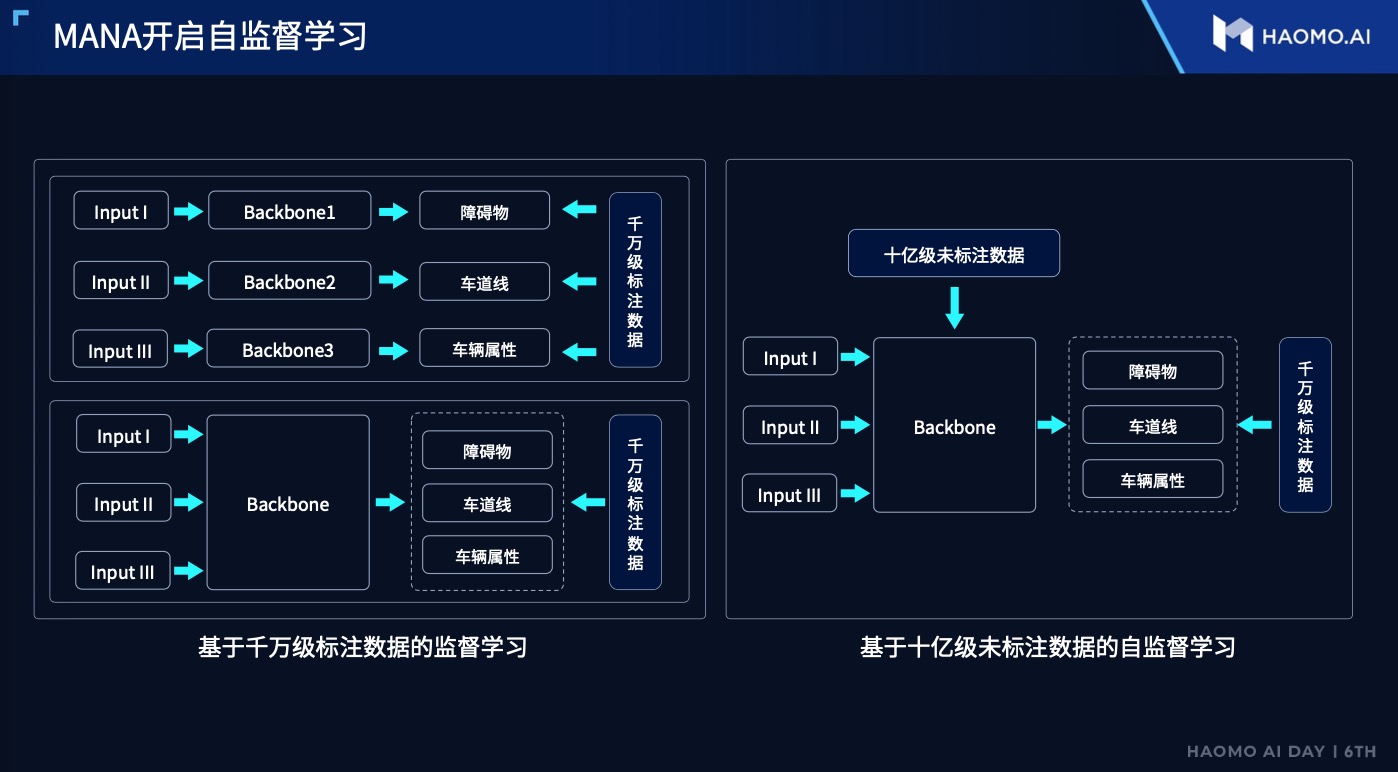
To address this issue, Momenta has developed a self-supervised learning method. Momenta uses a large amount of data to pre-train the model, and then uses supervised data to fine-tune the model for specific tasks, thereby improving the model’s effectiveness.
Specifically, a large amount of data is used to extract BEV features from images. At the same time, Momenta hopes to reconstruct 3D scenes based on BEV features. This training process does not require labeling, since the input is multimodal sensor information, and the output is 3D reconstruction. Then, the follow-up scene can be inferred based on the 3D reconstruction information.

After training is completed, Momenta will fine-tune the model with specific tasks, such as lane lines, obstacles or vehicle attributes, based on the specific scenario. Momenta claims that, with the existing supervised training methods, even after 70 rounds, only a level of 70-80% accuracy can be reached. However, with the new self-supervised method, higher accuracy levels can be achieved within several rounds with additional data, and the efficiency is at least tripled.
In addition, there is still a well-known safety issue in the current advanced driver assistance system. Although it has been developed for many years, the system still cannot guarantee 100% safety in some special scenarios, such as static objects. When the system needs to make “emergency corrections” for these issues, it often encounters difficulties. For example, the system has accumulated a huge amount of information, but suddenly needs to respond quickly to a new case, which may weaken its performance in other scenarios. For example, if the system dramatically improves its response to trucks, it may lead to a significant decrease in its effectiveness for ordinary cars. This phenomenon is called “catastrophic forgetting” in the industry.
One solution is to retrain all the data, although it is effective, the cost is too high. Therefore, Horizon Robotics proposes a new incremental learning method for “catastrophic forgetting.” For example, when there are new issues, scenarios and bad cases, Horizon Robotics will couple them with old models. Of course, the ultimate goal is to obtain a new model, but Horizon Robotics selects a small amount of data for training, and then outputs and compares the new and old models simultaneously. In this way, the parameters are optimized “locally.”
Low Confidence in High-Precision Maps
Horizon Robotics has long advocated the slogan of “heavy perception and light map,” the reason is that the update frequency of high-precision maps is low. Gu Weihao provided a set of data. The total length of highways in China is 300,000 kilometers, and the length of normal roads is even more than tens of millions of kilometers. It is impossible to rely solely on surveying vehicles to update and maintain high-precision maps and provide them as prior information to the intelligent driving system.
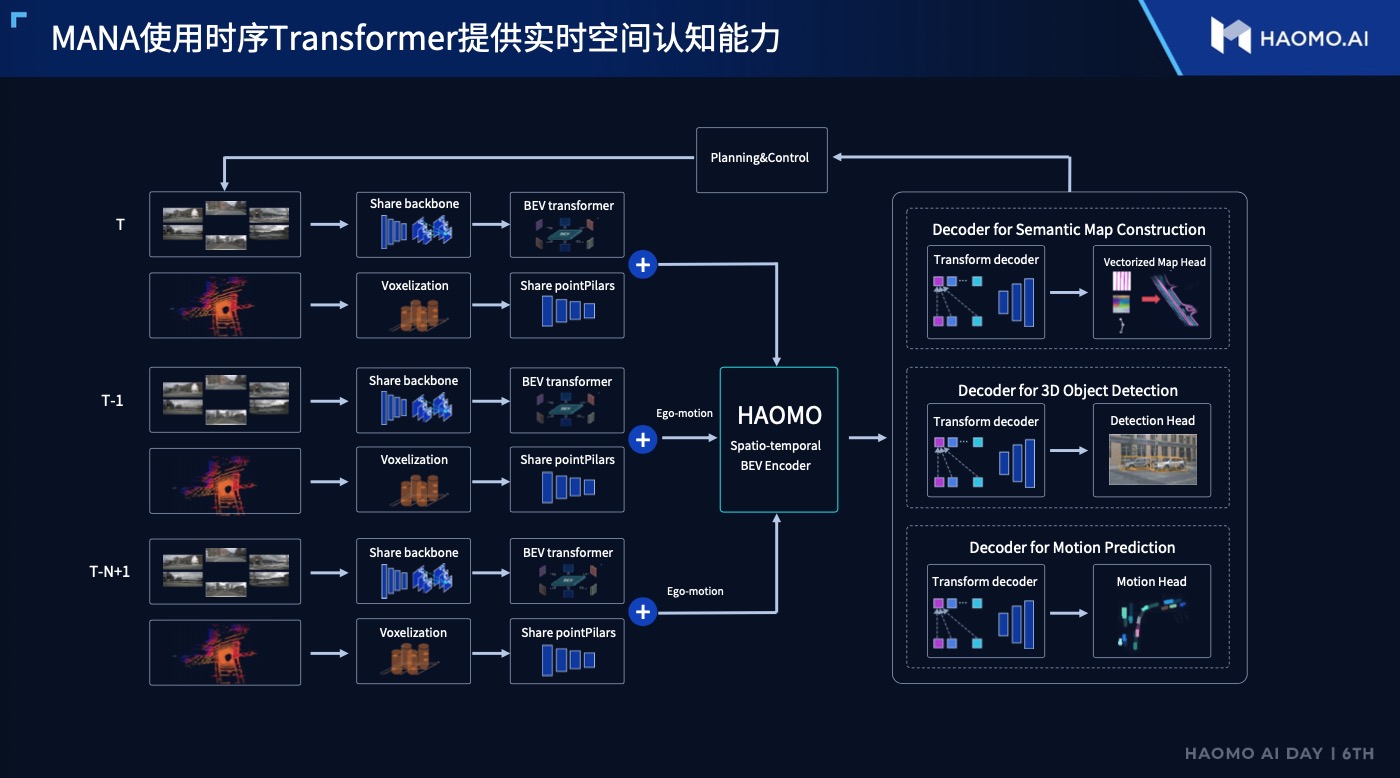
In addition, we also heard another interesting point of view. Gu Weihao said that you can view Lidar as a sensor, but due to its frequent “construction,” its “perception data” is very unstable and unreliable, so its confidence level is low.
Horizon Robotics prefers to rely on the real-time perception ability of single vehicles. The solution is to use the Transformer to build a strong spatiotemporal understanding ability and eliminate jitter in comprehensive long-term multi-frame information in real-time mapping technology.
 Like Tesla, Momenta also employs time-series Transformer models for virtual real-time mapping in the BEV surround space, which stabilizes and enhances the perception output of the lane markings.
Like Tesla, Momenta also employs time-series Transformer models for virtual real-time mapping in the BEV surround space, which stabilizes and enhances the perception output of the lane markings.
When it comes to map issues, Ai Rui, the Vice President of Autonomous Driving Technology of Momenta, mentioned that high-precision maps have always been limited and slow to open up. As an autonomous driving supplier, Momenta must break down the barriers of maps in order to get on board and obtain more data.
No Interactions Can Be Missed
Elon Musk had already refuted the Lidar route long ago, saying that roads are designed for human drivers and that we humans don’t drive with Lidar.
Momenta CEO Gu Weihao also stated that the interactions between vehicles are designed for humans, which makes it easier for drivers to exchange information with each other.

When the taillights of a vehicle in front shine brighter, we know the driver has stepped on the brakes; when the turn signals of other vehicles light up, we know that they will be turning. This information is extremely important for driving. Likewise, such information can be obtained by the vehicle system.
During the AI DAY in the first half of this year, Momenta introduced how to obtain traffic light information in urban environments without relying on high-precision maps and V2X communication. At this year’s AI DAY, Momenta stated that it is upgrading its perception system in vehicles in the hopes of incorporating specialized recognition of the status of vehicle signals, including turn signals and brake lights. In the future, Momenta will even consider incorporating sound interaction. Other vehicles’ honk sounds are actually a form of information.
Simulation Can Be More Realistic, and Driving More “Human-like”
As autonomous driving enters cities, the Momenta team encountered a very tricky scenario in simulation–intersections. In high-speed scenarios, just adding 2-3 cars in the scene can simulate the real environment, but in city intersections, there are a large number of traffic participants active in the area, which results in unsatisfactory simulation effects.

To solve this kind of situation, Momenta partnered with Alibaba and Deqing government to record real traffic flow around the intersection 24/7 using roadside devices. By importing the data into the simulation engine through log2world, they obtained a 24-hour real traffic flow simulation. According to Momenta’s actual test, importing real environment data into the simulation engine greatly improves the entire algorithm.# Moovita’s Improvements
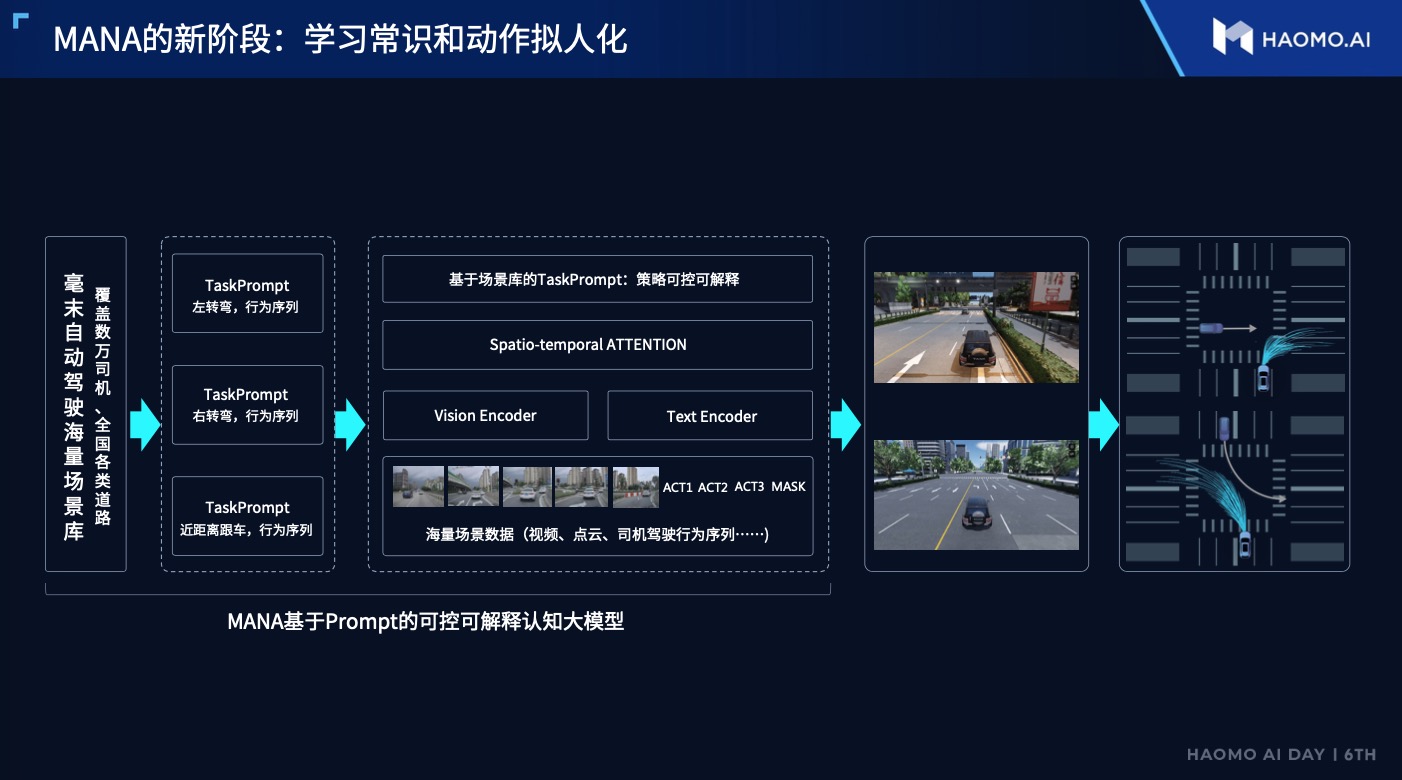
In addition to simulation, Moovita has also optimized the cognitive issues to make the driving behavior infinitely closer to that of humans.
According to AI Rui, if only the safety of the system is considered without considering comfort, the solution is actually simple. However, products that are uncomfortable are not acceptable to users.
To make the driving behavior more human-like, Moovita has deeply interpreted the massive amount of human driving data across the country, constructed a scenario library, and conducted training respectively. By comparing it with human driving behavior, Moovita has improved the detail performance of the system.
Super Computing Center
At the end of last year, Moovita revealed its plan to build its own super computing center.

At today’s AI DAY, Gu Weihao revealed the latest progress of the super computing center. Moovita’s goal is to meet the needs of a model with 100 billion parameters and a data scale of 1 million clips, while reducing overall training costs by 200 times.
Training a large model requires massive computing power. Taking training a large model with 100 billion parameters and 1 million clips as an example, it requires thousands of GPU cards to train for several months, and the time cost is very high.
Therefore, how to improve training efficiency and reduce training costs is the top priority for popularizing autonomous driving.
It is worth mentioning that AI Bo said that although Nvidia has cut off the supply of A100/H100 GPUs to the Chinese market, the impact within a short period is not significant. Firstly, because Nvidia is unlikely to abandon the Chinese market in the short term, and secondly, because building a super computing center is not necessarily based on Nvidia’s solutions.
Five Functions of Urban NOH
At the AI DAY in the first half of the year, Moovita announced the ten typical scenes of Urban NOH and summarized 5 main functions through these scenes.

The five major functions include intelligent recognition of traffic lights, intelligent turning left and right, intelligent lane changing, and intelligent obstacle avoidance (divided into dynamic and static).
These five functions are also the basic functions of Urban NOH. Gu Weihao said that since the system is still in the process of user “running in,” human intervention is still required in many scenarios. For example, although it is required to stop at a red light, go on green light, and slow down at a yellow light, users still need to gently accelerate after the green light comes on.
The intelligent left and right turning logic is based on human experience to plan the route. When encountering pedestrians and non-motor vehicles while turning, they will actively avoid them, but when encountering motor vehicles, they will play games.
The intelligent lane change integrates the vehicle’s surrounding perception. The system will travel according to the established navigation route, actively change lanes at intersections or seek higher traffic efficiency, and observe the behavioral trajectory of traffic participants behind. When the lane change space changes, the system can also actively accelerate or decelerate.

When the system encounters an obstacle, it will first identify the obstacle type to decelerate or detour. If it is a static obstacle, the system will judge whether the space meets the detour condition. If it does not meet the condition, it will wait.
The difficulty of avoiding dynamic obstacles is greater, and the width of lanes in cities varies. If it is a narrow lane and there is a preceding car crossing the line, the system will still actively decelerate and then judge the detour condition.
As mentioned earlier, light interaction will also be added. When the car’s turn signal and brake light are on, the system will judge the intention and decelerate or overtake to ensure driving safety and commuting efficiency.
Final Thoughts
Unlike Tesla’s AI DAY, Haomo’s AI DAY is held quarterly.
We often joke that the AI DAY held quarterly brings us practitioners multiple times more workload, but we sincerely appreciate a technology company frequently sharing its achievements.
In these 1,000 days, Haomo has completed the mass production of NOH, and for Haomo, 1,000 is also a new starting point, because from the perspective of urban NOH, that is, urban navigation and driving assistance, the competition has just begun.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.