Author: Su Qingtao
On April 19th, at the Meow AI DAY, I didn’t have time to watch the live stream. I originally planned to only release a “simple piece of news” afterwards, but it turned out that Gu Weihao’s speech was especially “hardcore” and worth reading carefully. In the week before and after this press conference, Meow’s Technical Director Pan Xing also had a communication with the media. After sharing, he accepted a group interview from the media, and both the speech and the interview were full of practical knowledge.
After I made some brief comments on my circle of friends, quite a few people privately asked me, “Where can I find the speech manuscript?” In response to the needs of readers, I decided to digest these practical knowledge and sort out some of the highlights. This article covers:
1) Meow’s data intelligence system MANA
2) Transformer, the key weapon for leveraging data advantages
4) Introducing deep learning algorithms in decision-making process
5) How to use the data collected by L2 vehicles for L4
6) Can data from various scenarios be “linked”
7) “Grading” the ADAS capabilities from a user perspective
8) Open business models
In the process of writing this article, I consulted many times with Xie Haijie from Meow’s marketing department, and also referred to and quoted a lot of content from the article “Meow’s Perception Architecture in Evolution – Transformer’s Application in Meow” published by Cheyou Intelligence in December last year and the article “We Studied the Secrets of Tesla’s and Meow’s Automatic Driving Algorithms” published by Yanknow New Energy in March this year. I express my gratitude to the authors of these two articles.
Data Intelligence System MANA
Basic Concept
In Q4 2021, Meow’s Autonomous Driving Data Intelligence System MANA was released. MANA is a whole set of data processing tools based on massive data, including data annotation, algorithm models, test verification system, simulation tools and computing hardware. MANA is the core driving force for the evolution of all of Meow’s products.
The MANA system consists of four subsystems: TARS, LUCAS, VENUS, and BASE.
Among them, TARS is Meow’s algorithm prototype developed in the vehicle side, including TrasView (perception), TrasGo (cognition), planning decision control, Map (map positioning), Meta (simulation engine), and more for the vehicle side algorithm service.
LUCAS is the application of algorithms in various scenarios, including core capabilities such as high-performance computing, diagnosis, verification, and conversion. VENUS is the data visualization system, including the execution status of software and algorithms, restoration of scenarios, and data insights. BASE includes data acquisition, transmission, storage, calculation, and new data analysis and data services.The characteristic of the MANA perception system is that it “designs a Neck network to extract global information for global tasks”. This is actually very important because global tasks (such as detecting drivable roads) rely heavily on understanding the scene, which in turn relies on extracting global information.
Up to now, MANA has completed over 190,000 hours of learning time, equivalent to 20,000 years of driving experience for human drivers.
Typical Applications of MANA
(1) Data labeling
Data labeling accounts for a high proportion of the cost of data processing. Therefore, reducing labeling costs by increasing automation is a direction that many companies are striving for. Currently, Momenta’s level of data labeling automation has reached 80%. In terms of implementation, Momenta uses two stages of “coarse localization of targets” and “precise attribute estimation”.
In the “coarse localization of targets” stage, the first branch uses a high-precision 3D obstacle detection network and 3D obstacle tracking algorithm to detect and track 3D targets; the second branch uses 2D spatial convolution and 1D temporal convolution inside the spatio-temporal pyramid network to detect the motion attributes of 3D targets, and the system then aggregates and categorizes the results detected by these two branches.
In the “precise attribute estimation” stage, the system differentiates static objects from dynamic objects based on the classification results of the object’s motion state and uses different strategies for precise attribute estimation for different types of objects.
Labeling static obstacles is relatively simple, but labeling dynamic obstacles requires detailed labeling of some key attributes unique to dynamic obstacles, such as the orientation angle, motion posture, and speed. For the precise attribute estimation of dynamic objects, it is necessary to estimate the object size and pose, which is the focus and difficulty of automatic labeling.
Momenta’s solution is as follows:
1) During the relative motion between the ego vehicle and the target object, the system observes the target object from multiple angles and dimensions, and uses the temporal information provided by multiple frames of point cloud data to perform motion detection of obstacles.
2) Then, using a target-centered cross-time point cloud aggregation method to compress these point clouds so that they become dense point clouds from sparse point clouds.
3) After point cloud compression, using an improved PointNet network for accurate 3D box regression to achieve precise pose estimation of the object’s motion trajectory through global optimization.
Currently, this method has entered Momenta’s production process.
(2) Data storage
There are currently two main challenges in data storage: how to reduce costs and how to better process data in combination with the characteristics of autonomous driving.To reduce storage costs, Haomo has built the LUCAS data mining system, which selects valuable data from the massive data feedback from users, and then sends data to where it needs to be sent, trains what needs to be trained, uses what needs to be used, and caches what needs to be cached.
Regarding this data, Haomo will manage it in levels based on its value – mainly based on dimensions, such as data freshness, urgency of demand, and data usage. They will categorize data into categories such as accidents, after-sales, takeovers, somatosensory, products, and research and development, based on the demand of automated driving. Due to different demands, different categories of data have different lifecycles, effectiveness requirements, processing flows, and processing costs. Different strategies will be adopted for storage.
The automated screening methods combined with the level storage strategy naturally reduce the storage cost of data.
(3) Data Fusion
To better fuse visual and lidar data, Haomo has introduced the Transformer algorithm into its data intelligence system MANA.
In December 2021, Gu Weihao introduced on the Haomo AI DAY that the MANA system uses the Transformer to fuse visual and lidar data at the bottom layer, thereby achieving three-dimensional deep perception of space, time, and sensors.
Unlike post-fusion at the target level, Haomo uses the Transformer to perform pre-fusion on the feature vectors extracted from images and point clouds, and then predicts targets through a neural network. This approach can not only solve the fusion relationship between multiple cameras, but also effectively improve the effect of visual detection through the lidar.
Transformer, the Key Weapon for Leveraging Data Advantages
Definition and Advantages of Transformer
Transformer was born around 2017. It is an algorithm designed by Google for natural language processing (NLP), and its core is the attention mechanism.
The attention mechanism means that in a sentence or image, Transformer will establish relationships between words, between a segment of the image (pixels) and other pixels, in order to determine the relationships between these words and the relationships between these two pixel areas.
Before the advent of Transformer, people generally used the “encoder-decoder” structure based on recurrent neural networks (RNN) to complete sequence translation.The obvious drawback of the architecture based on RNN is that it belongs to a sequence model which requires processing information in a serialized manner, ensuring that the attention weight is determined after the sequence is fully input into the model. To put it simply, RNN needs to view the sequence “from start to finish.”
For example, when facing the problem of machine translation of “A magazine is stuck in the gun,” should “magazine” be translated as “杂志” or “弹匣”? When humans see the word “gun,” they will translate “magazine” as “弹匣.” However, for machines, it is not that simple.
The RNN-based machine translation model needs to process all words step by step from “magazine” to “gun,” and when they are far apart, the information stored in RNN will be constantly dilute, making the translation often unsatisfactory and very inefficient.
This architecture has a lot of time overhead in both training and inference, and it is difficult to achieve parallel processing. At this point, engineers have come up with a solution, which is to add an “attention mechanism” to the standard RNN model.
This attention mechanism comes from the human brain’s attention mechanism. When the human brain receives external information, such as visual and auditory information, it often does not process and understand all of the information, but only focuses on parts that are prominent or of interest, which helps to filter out unimportant information and improve information processing efficiency.
At the time, the Google team gave the RNN model with the added attention mechanism a new name: Transformer.
Because the attention mechanism is introduced, Transformer does not care about the order, and the importance of each element when calculating the correlation is based on the semantic information of the data itself. Therefore, it can easily extract the correlation between elements that are arbitrarily distant. This ensures that the correlation between elements can be well preserved regardless of how far apart they are in time sequence.
For example, in the sentence “The animal didn’t cross the street because it was too tired,” which “it” represents “animal” or “street”? Humans can easily judge, but it is difficult for machines (if using RNN to process). However, the attention mechanism of Transformer can connect “it” with “animal.”
After achieving widespread application in the natural language processing field, Transformer has also been successfully applied to many visual tasks, such as image classification, object detection, and has achieved good results.Why are algorithms originating from natural language processing field also applicable in visual tasks?
The main reason is that although images themselves are not time series data, they can be viewed as a spatial sequence. A key step of visual tasks is to extract correlations between pixels. While ordinary CNNs extract local correlations (also known as local receptive fields) via convolution kernels, Transformers can provide “global receptive fields”. Therefore, the learning ability of features is much higher compared to CNNs.
It can be said that although Transformers are not designed for graphics processing, its ability to reveal the nature of inherent relationships in information is more profound than CNNs.
Research has shown that when the training dataset grows to include 100 million images, the performance of Transformer begins to exceed CNN. And when the number of images increases to 1 billion, the performance gap between the two becomes greater.
Simply put, Transformers have significant redundant advantages in handling massive amounts of data.
Tesla was the first to use Transformers in perception algorithms because Tesla had extremely large amounts of data. Now, Horizon Robotics hopes to become the second after Tesla.
The application of Transformers in Horizon Robotics’ autonomous driving
In Tesla’s FSD application, the role of Transformers is very limited. It only utilizes the Transformer technology to capture the “self-attention” relationship for full-frame relations of image information and the description and transformation of “cross-attention” relationships between differently angled image information.
However, in Horizon Robotics, according to Gu Weihao’s description at the AI Day in December last year, Transformers not only completed the conversion of the bird’s-eye view (BEV) visual field of pure visual information, but also completed the fusion of heterogeneous but complementary sensor information between cameras and lidars, namely, the fusion of “cross-modal” raw data.
Horizon Robotics also proposed to integrate Transformers into its data intelligence system MANA, and gradually apply it to practical road perception problems, such as obstacle detection, lane detection, drivable area segmentation, traffic sign detection, etc.
(1) Using Transformers for temporal and spatial pre-fusionAccording to the information revealed at the last AI DAY, in the self-driving scheme of Horizon Robotics, the camera-based visual perception and the Lidar-based laser perception are completely independent of each other before their respective recognition results come out. The two stacks are completely independent, without intersection or fusion, that is, there is no so-called “front fusion” technology.
The advantage of this approach is that the two systems can provide backup capabilities for each other due to their independent operation, as emphasized by Mobileye. The disadvantage is that the complementary nature of the two heterogeneous sensors, Lidar and camera, cannot be fully leveraged to extract the most valuable fusion information jointly from their raw data.
In addition, Gu Weihao once said that there is a problem of “discontinuous sensing in time and fragmented sensing in space” in the existing perception system.
The “fragmented sensing in space” refers to the fact that the multiple sensor entities installed around the vehicle, due to the installation angles, cannot achieve continuous coverage and unified recognition in the spatial domain. The direct result is that many cameras only see a part of the target, which makes it difficult to make correct detections based on the incomplete information, and the subsequent fusion effect cannot be guaranteed. Alternatively, an oversized object captured by multiple sensors may be wrongly identified as multiple targets (this problem was also widely existent in the early version of Autopilot until it became 3D-ified).
The “discontinuous sensing in time” refers to the fact that the recognition of cameras and Lidar is implemented in frames that are discontinuous in time, and no time-domain network spanning multiple frames is designed to solve this problem. For instance, using a separate object tracking module to concatenate the object detection results of individual frames is actually a post-fusion strategy, thus failing to make full use of useful information in the time domain.
How to solve these two problems? Horizon Robotics’ answer is to use Transformer for front fusion in both time and space.
In space, Transformer is used to perform front fusion on the feature vectors extracted from images and point clouds, and then the fused features are used for object prediction through a neural network. This approach not only solves the association between multiple cameras, but also effectively improves the performance of visual detection through Lidar.
Similarly, in the time domain, multiple feature vectors from different frames are fused via front fusion, followed by neural network prediction, which improves the prediction continuity in time.
For example, Transformer can be used in the recognition of lane lines to fuse the lane lines captured by multiple cameras in space into one, thereby solving the problems of “fragmented sensing in space” and “discontinuous sensing in time”.The role of Transformer in spatial fusion is different from its role in general visual tasks, such as image classification and object detection. The main function of Transformer in spatial fusion is not to extract features, but to perform coordinate transformations, which is completely data-driven and task-specific.
Regarding the issue of “discontinuous perception in time”, without high-precision maps as prior information, complex lane markings may jump due to perceptual noise. For example, in the previous frame, the lane marking was 50 centimeters to your left, but one second later, it may jump to 45 centimeters to the left, causing the entire lane marking to shake. When users experience this in the real car, they will feel that the car is “wobbling”.
Through Transformer’s attention mechanism, the system can correct the noise caused by this perceptual jump, thus achieving a stable output in time. With this mechanism, the system can see the entire output of the lane marking on a farther visual field, as well as the topological structure of the lane itself, thus achieving more precise output and making the entire lane marking “what you see is what you get”, making it easier for downstream planning and decision-making.
Regarding the issue of “fragmented perception in space”, the image above shows the lane markings seen only through perceptual sensors in Momenta’s autonomous driving system without high-precision maps.
There are changes in the lane markings on this section of road, some disappearing while others appearing. The bottom image shows a roundabout. Further ahead, there are changes in the road shape, with a merging lane and a disconnected lane marking segment. There is no lane marking in the middle of the intersection, and after crossing the intersection, the road shape enters a roundabout on the left.
There are a total of six cameras on the car, and all six cameras can see the lane markings, some on the side, some in front, and some in rear. In such a complex situation, using Transformer’s attention mechanism, the system can effectively solve the problem of stitching data from multiple cameras.
Without using the Transformer model, one can only perform post-processing on the data from different sensors as usual. At this time, it will be affected by sensor calibration errors, and the stitched lane markings might not be coherent.
Pan Xing mentioned that the reason for using lane markings as an example is that, compared to highways, lane markings are the most typical perceptual challenge with the most changes in cities.
 # Neat Lane Lines on Highways and Complex Lane Lines in Cities
# Neat Lane Lines on Highways and Complex Lane Lines in Cities
The lane lines on highways are very neat and of high quality, with a high level of regularity and continuity. However, lane lines in cities are more complex and often blurred. The government may not have had time to repaint them, or old lane lines may still remain after repainting, leading to overlapping with the new ones. At times, a road that starts with two lanes may end up having three at an intersection, or the alignment may not be precise, leading to the risk of going off-road when driving straight.
When faced with such complex lane line problems, using large models, especially attention-based models like Transformers, has a significant advantage in solving these problems.
In fact, not just lane lines, but all types of obstacles and other traffic elements will gradually be incorporated into Transformer’s processing range.
How to Achieve Urban Autonomous Driving Without High-definition Maps
Perception Challenges of City Autonomous Driving
City and highway scenes have many differences, the most notable of which are multiple intersections, lane changes, and congestion. Traffic lights at intersections are an unavoidable topic.

At an irregular intersection, there are many traffic lights, and you can see them on the left, right, pedestrian crossing, or directly ahead. Which one controls your lane is a difficult problem.

Usually, many autonomous driving companies solve these problems during testing by using high-definition maps. These maps provide information on where traffic lights are located in specific computer coordinates, and which lane is controlled by each light. Additionally, during monitoring, you can easily determine the distance to the next traffic light by comparing it with the map.
However, for mass-produced vehicles, the current state has not yet approved high-definition maps for use in urban areas. Even if approved, it would take time to implement. Robotaxis typically require only high-definition maps of three to fifty kilometers on a few streets, while mass-produced vehicles need high-definition maps for hundreds or even thousands of cities.
Initially, high-definition maps may only be available in a few large cities such as Beijing, Shanghai, Guangzhou, and Shenzhen, with expansion gradually occurring in other cities.In terms of high-precision maps, in the future, after compliant city-level high-precision maps are introduced, Momenta will also use high-precision maps on NOH in cities to further ensure the precision of vehicle perception. However, at present, in cities lacking high-precision maps, how can smart assisted driving vehicles solve the problem of traffic lights?
No high-precision maps available, what to use?
Since there is still a lack of city-level high-precision maps, Momenta’s approach is to improve perception algorithms through training.
We still use the problem of traffic lights as an example. It is difficult to collect traffic light data from all over the country for training. Momenta’s approach is to build various traffic light scenarios under different lighting and weather conditions through a simulation platform and use these scenarios for model training.
To expand the sample size of training and compensate for the problem of uneven data samples in real scenes, Momenta obtains a large amount of synthetic data under different lighting and backgrounds through a 3D simulation engine.
However, the quality of synthetic data is usually not as good as that of real data. The main difference lies in the inconsistent feature space and probability distribution. The inconsistency in the feature space can be understood as the distortion of vehicle data due to rain or dust on traffic lights, while the inconsistency in probability distribution refers to the difference in picture style, such as the obvious artificial feeling in simulation pictures, which is different from the real world regarding lighting and color.
If these two “inconsistencies” are not solved, synthetic data cannot be fully utilized. Therefore, to use synthetic data to the greatest extent, it is necessary to minimize the “inconsistency” between synthetic data and real data in feature space and probability distribution, thereby enabling the objective function f to have the minimum prediction error in real scenes and further improving the accuracy of traffic light recognition.
For reducing the inconsistency between the probability distributions of the two, Momenta uses the mixed transfer training method in the field of transfer learning, which “directly makes up” for the missing data samples in real scenes using synthetic data and continuously adjusts the training strategy to reduce the feature space distribution difference between the two.
The visualization of the feature space in the figure below on the right shows that after directed data augmentation and mixed training, the feature space of synthetic data is closer to the feature space of real data.

When it comes to simulation data and synthetic data, it is necessary to introduce a concept: transfer learning.
Transfer learning is a professional concept in the field of artificial intelligence. Simply put, it is the ability of a machine to “apply learned knowledge to new domains,” enabling it to transfer knowledge learned during task A to task B.The goal of transfer learning is to transfer knowledge from one task to another, using one or more tasks to assist another target task.
Hamo uses a hybrid transfer learning approach, which is a kind of transfer learning, and the transfer efficiency of the model will be significantly higher than that of a single transfer learning model. The mixed transfer learning of perceptual data should be combining synthetic data with real road data to improve the value of synthetic data, then using synthetic data to train the algorithm model, and then applying this algorithm model to real road conditions.
As mentioned earlier, there are mainly two types of problems regarding traffic lights: “Recognition” and “Binding”. “Recognition” is easy to understand, while “Binding” refers to how to distinguish which road is controlled by “which traffic light” in the case of many traffic lights. This is actually a problem of confirming the topological relationship between traffic lights and roads. For this, Hamo designed a dual-stream perception model, which decomposes traffic light detection and binding into “what” and “where” two channels.
Among them, the “what channel” is mainly responsible for the recognition information of traffic lights, including the detection and classification of traffic light boxes, to output information on the color, shape, and orientation of traffic lights. The “where channel” is mainly responsible for binding traffic lights, that is, outputting the traffic light group of the target lane. Here, Hamo will express the relationship between the traffic light and road structure by training a convolutional neural network to generate feature maps.
Finally, Hamo will combine the two using the “Spatial Attention Mechanism“. The purple part in the spatial attention module corresponds to the frequently appearing position of the traffic light in the image. Thus, Hamo’s dual-stream mode will output the traffic light passing status of the target lane after binding roads. It should be noted that the model of the “Spatial Attention Mechanism” is independent of the lane recognition model introduced above.
Pan Xing said that with this method, Hamo’s autonomous vehicles can process and recognize traffic lights purely based on perception without high-precision maps, as well as know the relationship between the traffic light and the road. “No matter where the traffic light is, as long as it is “bound,” the system can find the topological information of the traffic light on the road.”
According to Gu Weihao’s disclosure in the speech, “Based on this method, Hamo has conducted extensive testing, and under different cities, distances, turns, and lighting conditions, it can accurately recognize traffic light signals.”### The Technical Barrier of the “Strong Perception” Route
In his speech, Pan Xing referred to the Maopost route as the “Heavy Perception” route. So, what is the barrier of this technology route?
Pan Xing explained, “The core difficulty here is the accuracy of the perception algorithm. If the accuracy of the perception algorithm is not high, in our solution, even if you get the topology information right, the car won’t drive properly, let alone the fact that the topology information itself is also inaccurate.”
Why is the emphasis on the accuracy of the perception algorithm and not the accuracy of the sensors? Pan Xing says that the perception system’s ability to see road type changes, accurately operate the distance between the lane lines and the car, and the lane line’s curvature depends mainly on the algorithm.
Is Maopost Similar to Tesla?
When it comes to autonomous driving in cities without high-precision maps, Tesla is an unavoidable topic.
Tesla has always emphasized that it does not use high-precision maps, and many people have been misled. In fact, Tesla really doesn’t use high-precision maps as a “component,” but they did crowdsource the mapping and then used the data from the crowdsourced maps to train the perception algorithm. It can be understood that their perception output results naturally include some map information.
In simple terms, we can understand that Tesla has “integrated the high-precision map function into the perception algorithm.”
As the ability of top-tier car companies’ autonomous driving algorithms increases, this route may become a trend in the future.
Deep Learning Algorithm Introduced in Path Planning
As we drive from the highway into the city, we inevitably encounter much more complex scenarios. For example, when we try to make a left turn at an intersection, we need to wait for the car turning around in front of us and observe the dynamics of oncoming straight-ahead cars and interacting with other right-turning cars.
In the past, when dealing with these scenarios, many rule-based judgments (if…else…) and parameter settings were written during the testing phase. However, in the city, there is basically an intersection every one or two kilometers. Can you write so many rules?
Moreover, writing too many rules may lead to self-contradiction — some researchers wrote thousands of rules and became confused. The more rules there are, the more likely they are to cause logical explosion, making it increasingly difficult to maintain and reconcile. Even the well-written rules can become invalid when a new traffic participant or disturbance factor is suddenly introduced.
To address this pain point, Maopost’s approach is to provide a vehicle-side model through TarsGo, learn human driver actions in these scenarios through modeling and stereotyped learning, and then use a new model to replace some of the original if…else… rules.
In fact, as early as AI DAY in December 2021, Gu Weihao mentioned the introduction of digital scenario and large-scale reinforcement learning to the decision-making phase.Digitizing scenes means parameterizing different scenes on the road. The advantage of parameterization is the ability to effectively classify scenes for differentiated processing. Once various scenes are digitized, artificial intelligence algorithms can be used to learn.
In general, reinforcement learning is a good choice for completing this task. Correctly evaluating each driving behavior is key to designing reinforcement learning algorithms in decision-making systems. The strategy adopted by Momenta is to simulate human driver behavior, which is also the fastest and most effective method.
Of course, data from just a few drivers is far from enough, and a massive amount of manual driving data is the foundation for using this strategy. This is also Momenta’s advantage – Momenta has a module called LUCAS Go, which will provide TarsGo with valuable human driving data.
In this process, interpretable labeling plays an important role. Through interpretable labeling, the reasons behind the driver’s decision-making behavior can be explained, making the reasoning results of cognitive decision-making algorithms “understandable”.
For example, at intersections, the vehicle needs to interact and compete with other vehicles. Therefore, it is not enough to just know how to operate the vehicle, you also need to understand the other vehicles’ reactions in this situation, such as why the car made a certain movement, why the driver operated the vehicle in a certain way, whether to overtake or change lanes next, etc.
However, other vehicles’ behavior is difficult to predict, and their performance varies under different circumstances. If effective interpretable labeling cannot be carried out, it may lead to difficulty in model convergence during training and the incorporation of some poor driving habits.
Therefore, to obtain this data, it is necessary to do human-interpretable labeling of the driver’s behavior and intentions. For example, if a vehicle suddenly deviates to the right, it may be because the driver calculated that a large vehicle was accelerating from the left. The vehicle should be able to provide weight probabilities for various factors that affect its decision-making, rather than being an unexplainable black box.
In this process, Momenta uses Alibaba’s M6 model. M6 is currently the largest multimodal pre-training model in the Chinese community with a parameter scale of over 10 trillion. Initially, it was mainly used for applications in e-commerce such as image recognition, natural language processing, and image generation, including video understanding.
M6’s application in the field of autonomous driving marks the popularization of AI model capabilities – autonomous driving companies can not only use their own data collection vehicles and users’ vehicles to iterate the capabilities of autonomous driving, but also use Alibaba Cloud’s data in smart cities to train and learn traffic flow data at intersections, etc.
Using a multimodal model pre-trained by M6, the system not only predicts how human drivers drive, but also provides a textual explanation of their actions in a format that humans can understand.
Then, through data post-processing, the system can classify, clean and filter these explorable problems to ensure that the data used for training autonomous driving algorithms is clean, adheres to human driving habits, and is socially acceptable.
Pan Xing said that through the expected data, they can train a vehicle-side intelligent algorithm to replace a large number of rules, and then iterate on the autonomous driving algorithm.
At the end of last year, the CEO of a leading new car manufacturer said in a speech: “Judgment and decision-making have not really given instructions to cars today, because deep learning has not been used yet, and even machine learning hasn’t been used yet. ” However, from this point of view, the decision-making algorithm for MayAuto autonomous driving may have surpassed these leading new contenders.
How to use L2 data to achieve L4?
As of April this year, six production car models (Tank 300, Latte, Macchiato, Haval Beast, Tank 500, etc.) have used the MayAuto smart driving system, and the total driving mileage of users has exceeded 7 million kilometers. According to the plan, the number of passenger cars equipped with MayAuto’s intelligent driving system will exceed one million in the next two years.
This driving mileage is the foundation for MayAuto’s emphasis on “data advantages.” However, none of the production cars on the road are equipped with lidar. Can this data be used directly to train L4 algorithms? If not, what kind of optimization is needed? On April 13th, I asked Pan Xing this question.
Pan Xing’s answer was that it is difficult to achieve autonomous driving with 2D data only. To truly bring out the value of this data, 3D information must be obtained from the 2D data. Therefore, whether visual data can be annotated as data with 3D information is an important threshold for advancing towards higher-level autonomous driving capabilities in the future; if you cannot cross this threshold, the value of such data will not be that great.
Can data from different scenes be connected?
Currently, in addition to passenger car autonomous driving, MayAuto is also focusing on end-to-end logistics delivery (not only with wire-controlled chassis, but also with algorithms). In this case, can the data obtained in different scenarios be connected?The answer from Pan Xing to this question is: These data can definitely be connected, but there are still significant differences in the type and location of sensors between logistics vehicles and passenger vehicles. In addition, although the areas where logistics vehicles and passenger vehicles are currently operating are very close, there are still some differences. Therefore, to make good use of this data, some technical means are also needed.
Grading ADAS Capabilities from a User’s Perspective
Mao Maofang believes that the current grading of ADAS has great confusion and is not based on the perspective of the user experience. Therefore, they propose to understand the product capabilities grading from the user’s perspective, allowing users to have a relatively accurate understanding of a vehicle’s accessibility.
Recently, Mao Maofang developed an “environmental entropy” pointer for the ability to assist driving. This is a function related to the number of traffic participants, relative distance, relative position, and direction of movement of the vehicle’s surrounding environment. Based on this function, the traffic environment is defined into 7 levels to compare the test and capabilities of Mao Maofang’s products and those of the industry.
Especially after entering the city, the usage rate of ADAS will significantly increase. Mao Maofang hopes to give users a sense of stability and to define this ability standard together with industry practitioners. Of course, Mao Maofang will also continually improve the accessibility of automated driving.
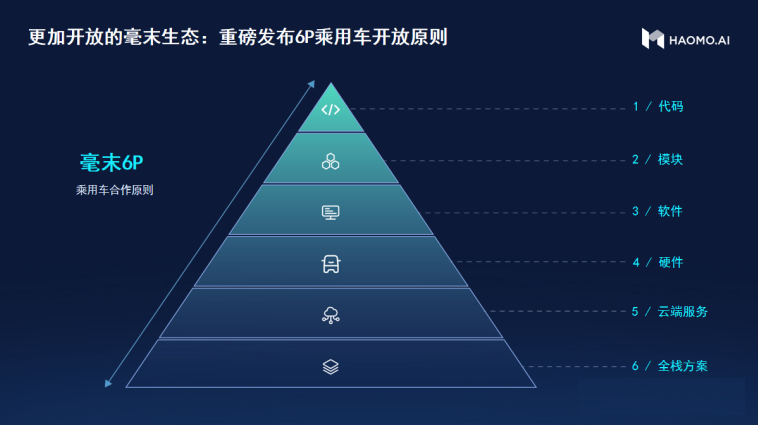
Open Business Model
Currently, Great Wall Motors is Mao Maofang’s sole customer in the passenger car field. However, Mao Maofang plans to open up their technology to other original equipment manufacturers.
How can Mao Maofang cooperate with other automakers? Mao Maofang Intelligent Driving has designed a “6P Open Collaboration Model.” That is, the cooperating party can choose to adopt Mao Maofang’s full-stack technology solutions, cooperate with Mao Maofang in data intelligent cloud services, cooperation at the software or hardware level, or functional module level cooperation; they can even choose to customize with Mao Maofang at the source code level.
Mao Maofang’s “6P Open Collaboration Model” is a possibility for open exploration and cooperation between the six product levels, from full-stack solutions to the source code.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.