
The content of this article is sourced from 42how and has been translated by ChatGPT
Deep Blue defeated chess champion Kasparov with a score of 3.5:2.5, AlphaGo won over world Go champion Ke Jie with a score of 3:1, Libratus won against top Texas hold’em players, and AlphaStar defeated top players of StarCraft II with a total score of 2:0…
In the past few decades, AI has continued to challenge human understanding and defeated top human players in various games. Last Thursday, Sony announced a major breakthrough:
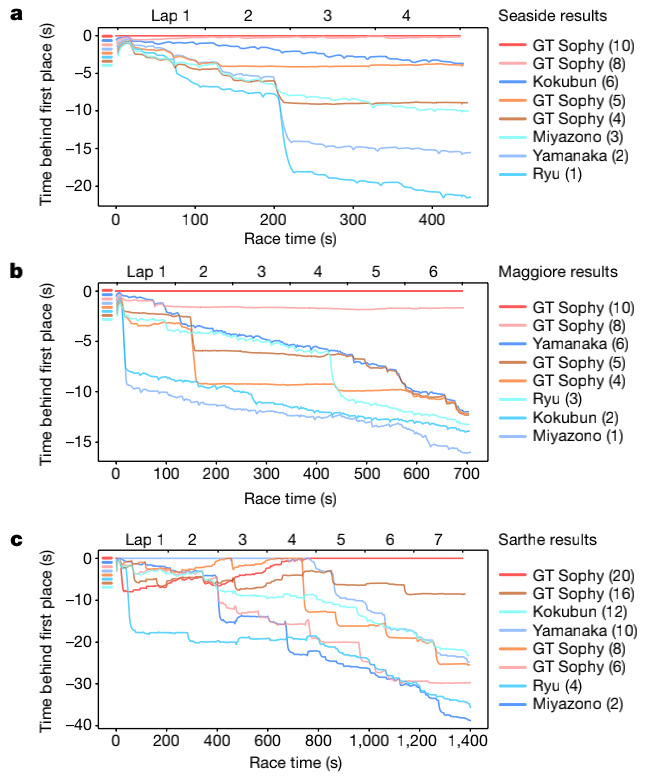
On February 9th, Sony announced the development of an AI named GT Sophy, which performed remarkably as an AI driver in Gran Turismo Sport (GT Sport), a racing game developed for the PS platform. GT Sophy defeated TAKUMA MIYAZONO, the first GT Championship triple crown winner in history, RYOTA KOKUBUN, the 2020 FIA Gran Turismo Nations Cup World Champion, TOMOAKI YAMANAKA, the 2019/2020 GT Championship winner, and SHOTARO RYU, the 2019 GT Championship runner-up.
This achievement also made the cover of the journal Nature.

If you have any knowledge of this game, you probably know that GT Sport is completely different from entertainment-oriented games such as Need for Speed and Forza Horizon 4. In GT Sport, Sony reproduces the real-world racing environment as accurately as possible, including the car’s load, gear ratio, power output, tire grip, and even air resistance.
Top racers will achieve “reflexive conditioning” during training, making instantaneous reactions and adjustments to information such as throttle opening, tire slippage, entry and exit timing, and road feedback, ultimately pushing the car to its limit.

However, it cannot be denied that the underlying logic of this information is based on physics, which humans cannot match in terms of control ability. Furthermore, GT Sophy has precise track maps, load on each tire, and the exact status of other vehicles, making it even more formidable.In order to ensure a fair match between AI and top human drivers, researchers have adjusted GT Sophy’s reaction time to 100 milliseconds, 200 milliseconds, and 250 milliseconds, while human drivers have a reaction time of approximately 150 milliseconds after training. Additionally, GT Sophy’s input is limited to 10 Hz, whereas the theoretical maximum input value for humans is 60 Hz.
How has GT Sophy performed in actual races?
Impressive Control Techniques
In racing, taking the “outer-inside-outer” line is the shortest way to complete a lap. Although sticking to the inside of a corner seems like the shortest distance, it will cause a huge difference in the speed of entering and exiting the corner, which is not conducive to acceleration after leaving the corner.
Due to lateral acceleration, the speed of a vehicle on arcs with larger radii will be much faster than on arcs with smaller radii. Therefore, taking the “outer-inside-outer” line through a corner can be seen as the vehicle traveling over a larger radius arc, minimizing the loss of speed.
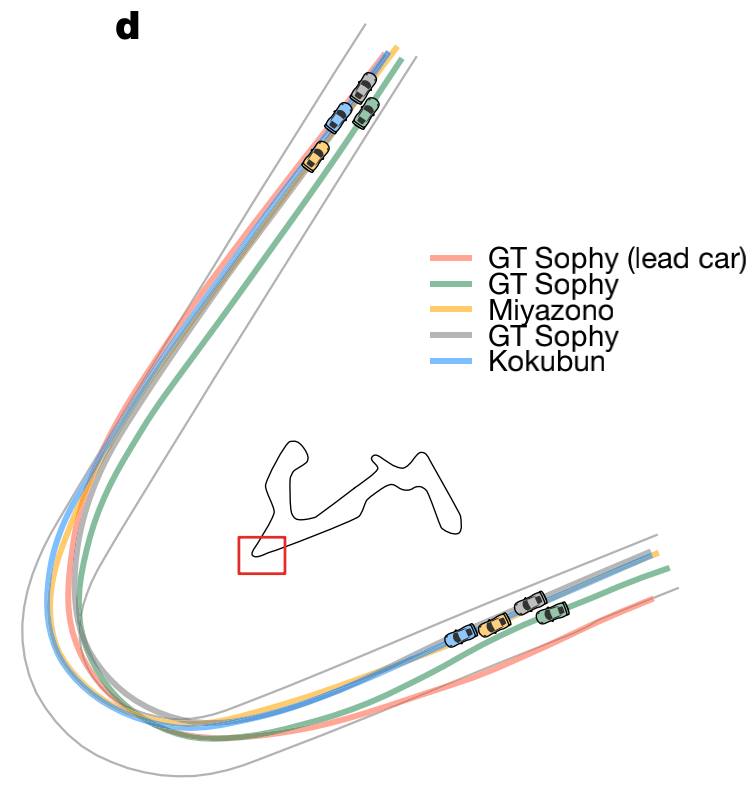
In the live race performance of GT Sophy, we can clearly see that the AI driver sticks closely to the outer edge of a corner before entering, accelerates immediately after entering, and skims over an almost perfect arc.

The whole process is very smooth, and the loss of speed is minimized. In continuous corners, GT Sophy even significantly passes over the shoulder to ensure the shortest route.
Sharp Overtaking in Corners
When a racing car is traveling at high speed, there is a positive pressure zone at the front of the car, while the airflow separates at the rear of the car to form a negative pressure zone. The pressure difference between the front and rear is the main source of aerodynamic drag.

We can see that GT Sophy tightly follows the car in front on straight sections, where it is in the vacuum zone created by the car in front, reducing the drag. When entering a corner, GT Sophy turns left in an attempt to overtake, but the car ahead cuts off the line, leaving no space for overtaking on the right. Without hesitation, GT Sophy chooses to attack to the left after slightly slowing down and completes the overtake.
Throughout the entire process, GT Sophy not only needs to consider the optimal route for itself, but also needs to quickly respond to opponent’s behaviors and give corresponding strategies. This kind of duel between two vehicles has a high degree of uncertainty, but we can see that GT Sophy’s performance is outstanding.
Good SportsmanshipFollowers of racing sports must remember the collision between Hamilton and Verstappen in the F1 Italian Monza Grand Prix on September 12th last year, which led to both cars retiring.

The reason was that Verstappen, who had a better tire temperature, attempted to overtake Hamilton in the corner. However, just as Verstappen was about to complete the pass, Hamilton turned his car and directly blocked Verstappen’s racing line, inevitably causing a collision between the two.

In order to prevent such extreme driving behavior, Sony’s staff specially trained GT Sophy in the rules of track etiquette. As can be seen in the demonstration video, when GT Sophy’s white Porsche 911 overtook its opponent, it did not block the opponent’s racing line like Hamilton did, but left enough space for the opponent to drive through. This courteous operation allows GT Sophy to perform with a human-like “temperature” in the race.
Astounding Technology, What’s the Principle?
GT Sophy’s stable and fierce performance against top human drivers amazed me when I watched the video of the race. So, what created this powerful AI driver?
Limitations in Deep Learning & Reinforcement Learning
Before explaining the deep reinforcement learning technology used by GT Sophy, it is necessary to first explain the concepts of “deep learning” and “reinforcement learning” that we often talk about.
Simply put, artificial intelligence includes machine learning, and both deep learning and reinforcement learning belong to the scope of machine learning.
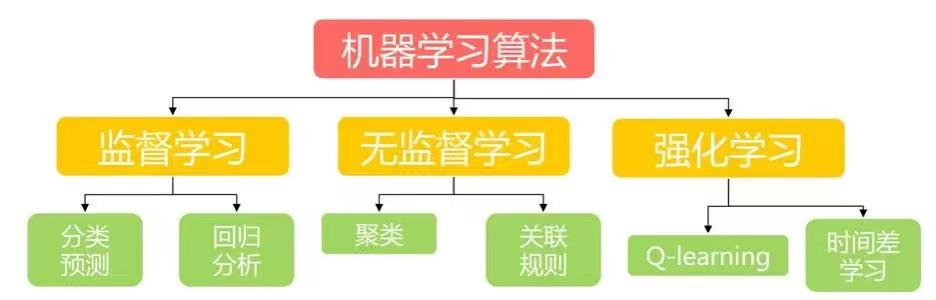
Deep learning can be simply divided into supervised learning and unsupervised learning, both of which essentially teach algorithms to find patterns in large amounts of data and eventually be able to recognize things on their own. In the process, the function, as an intermediate link, needs to fit the relationship between the input data and the output results as accurately as possible. This is exactly the strong point of neural networks with powerful fitting ability.
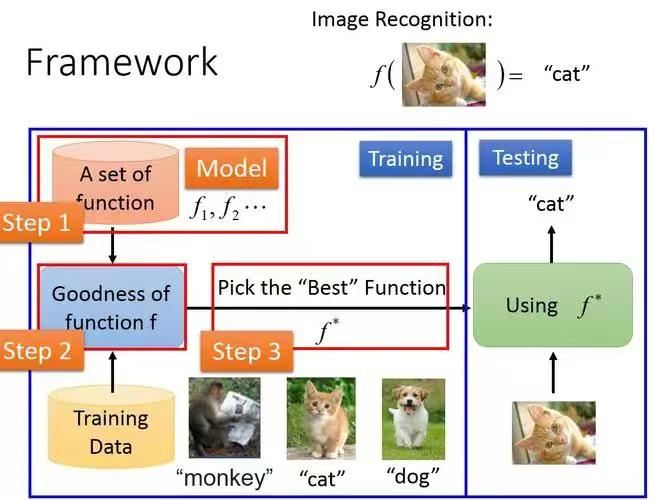
To give a simple example, if you want to teach AI to recognize cats and dogs, the first method is to teach it to recognize the difference between the two through feature labeling in a large number of cat and dog photos. The neural network continuously learns and finally fits multiple “universal approximation functions” until it can infinitely approach the output target. This belongs to “supervised learning” in deep learning.# Unsupervised Learning and Deep Reinforcement Learning in Autonomous Driving
In contrast to supervised learning, unsupervised learning allows AI to discover patterns in massive amounts of data. AI groups items that it considers similar without knowing whether they are cats or dogs.
The characteristics of deep learning make it ideal for object recognition tasks. In recent years, neural network models have become increasingly mature, and their accuracy in recognition tasks has approached that of humans. However, this is only part of the “perception” aspect of autonomous driving, and the role of pure deep learning in the “decision-making” aspect is limited.
Before explaining deep reinforcement learning, let’s first clarify two basic concepts in reinforcement learning: Environment and Agent. The agent is in an environment, and each state represents the agent’s perception of the current environment. The agent can only affect the environment through actions. When the agent performs an action, the environment will transition to another state with a certain probability. At the same time, the environment will provide the agent with a reward based on an underlying reward function.
In interacting with the environment, AI needs to constantly change its behavior policy and make the best response strategy to changes in the environment to maximize the expected reward.
Think carefully about our own learning process. Isn’t it familiar? Yes, the paradigm of reinforcement learning is very similar to the human learning process, so it is also seen as the hope of achieving general AI.
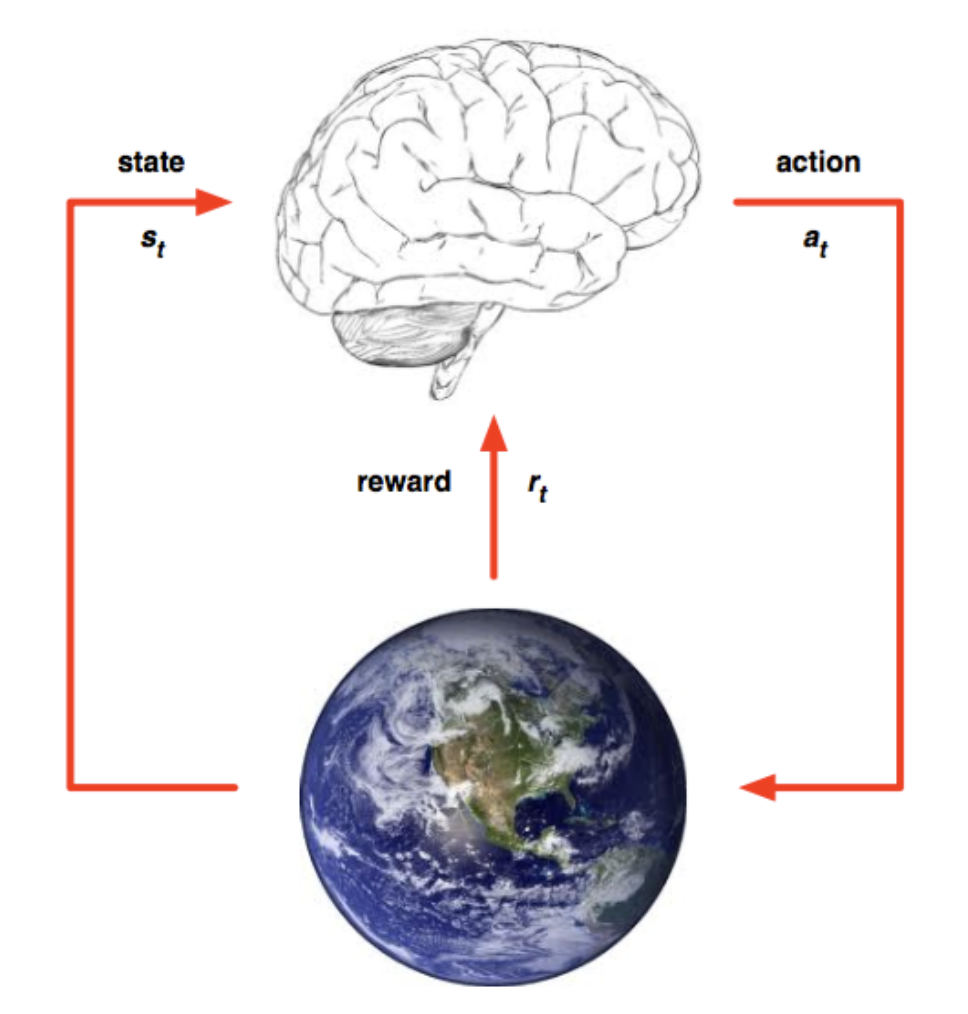
As you may have noticed, in the context of autonomous driving, the changes in the environment are too complex. Changes in opponent actions, the driver’s own operations, and changes in the racetrack all affect the results. Traditional reinforcement learning can only look for cases that are similar to the current state in experience and imitate them to make decisions, with little generalization and prediction capabilities.
Enter Deep Reinforcement Learning
GT Sophy combines the advantages of deep learning in function fitting and reinforcement learning in decision-making, applying deep learning to predict trends in expected rewards and ultimately achieving better performance in unknown environments.
Let’s take a closer look at how GT Sophy does it:
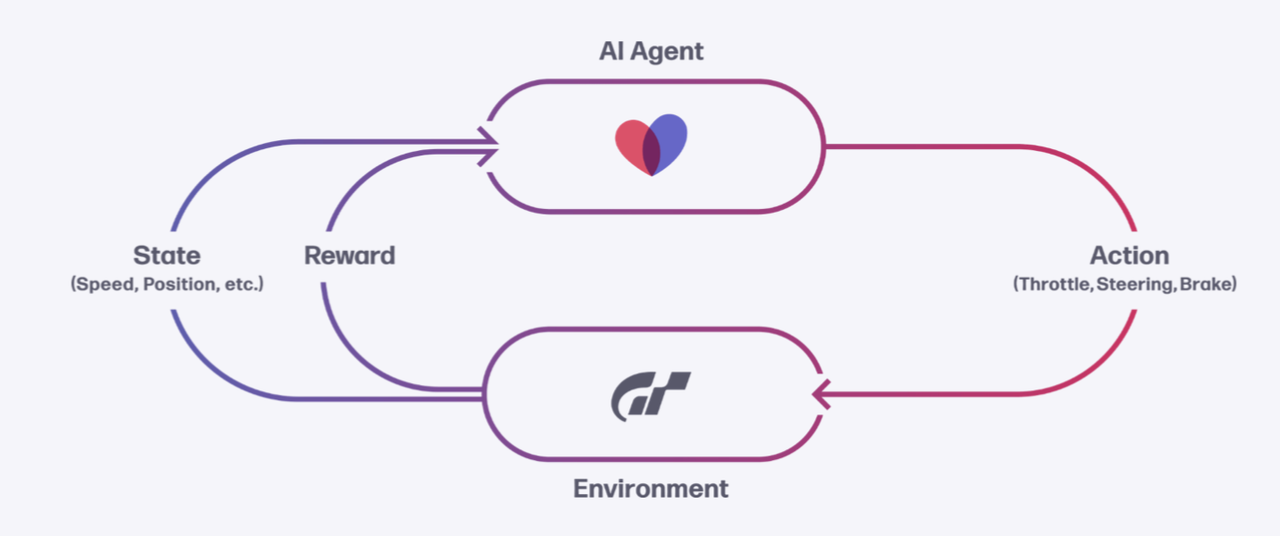
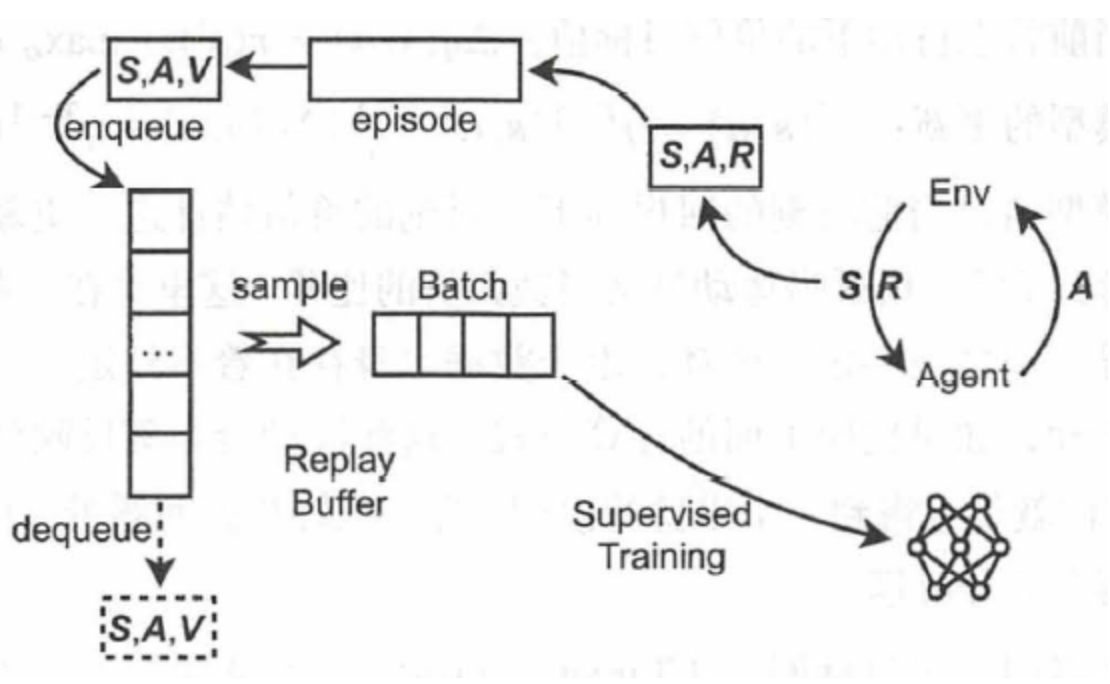
The above figure contains several basic settings of reinforcement learning:
-
Agent and Environment represent the intelligent agent and the interactive environment.
-
Action: All actions taken by the agent, including throttle, steering, and braking, etc.- State: All the perceivable features of an agent, including the speed, position, and track condition of a vehicle;
-
Reward: The designed reward or punishment.
Based on this, we can extend an advanced concept in reinforcement learning: “Policy.”
Policy refers to the action decision-making that an intelligent agent needs to make under a given state (State). It can be viewed as a mapping from State to Action, which is a function.
In the game GT Sport, the game scene is the Environment, GT Sophy is the Agent, the various states of the racing car are the State, the operation of the racing car is the Action, and how to operate the racing car is the Policy.

To know how to make the best action decision, it is necessary to predict the impact of the current perceived state and action on the future, and under the reference of the reward function, the Agent will ultimately give a decision.
Traditional reinforcement learning uses tabular representation when representing states and actions, which makes this method unsuitable for large-scale action and state changes. Moreover, if a state has never appeared before, the algorithm will have no idea how to handle it.
In other words, traditional reinforcement learning guides the next learning based on the conclusions drawn from past events. But think about how humans handle things? Humans compare the current situation with similar situations in their memory. If it is similar, they adopt similar methods and do not rigidly follow previous methods.
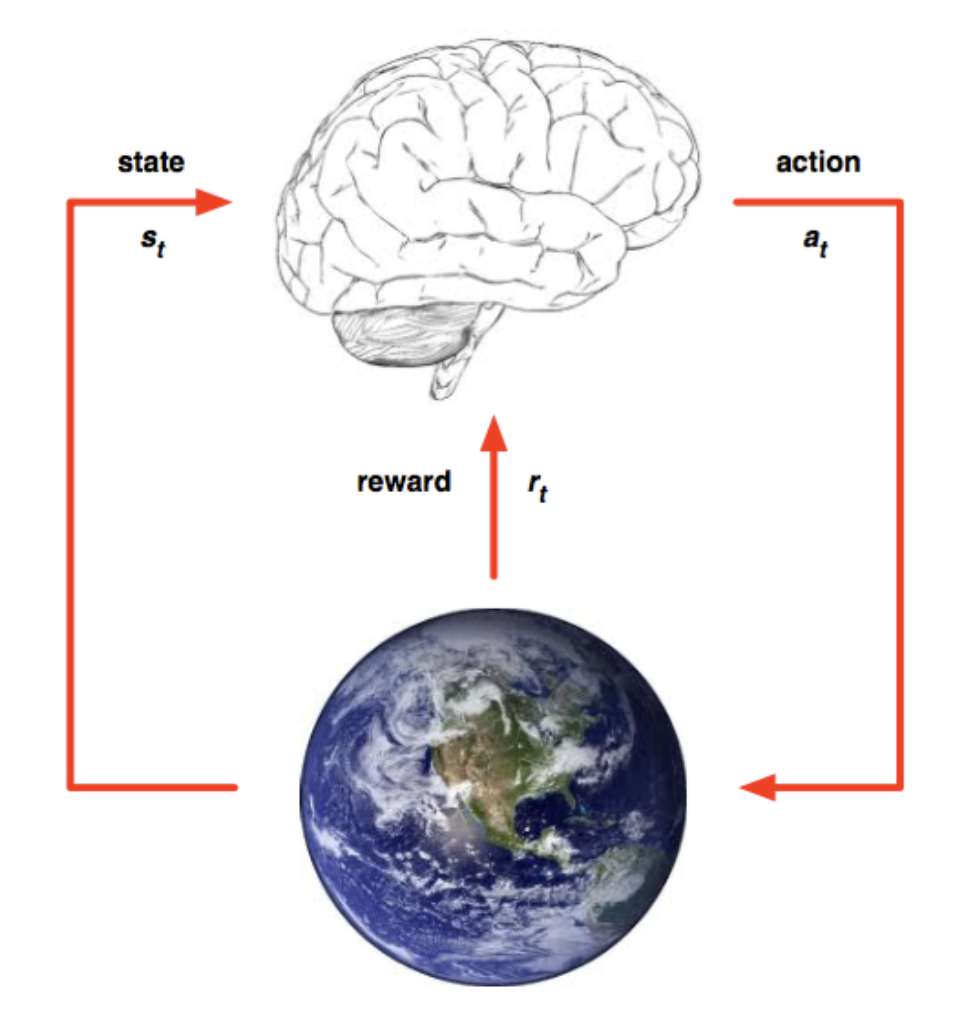
The innovation of GT Sophy is that it can fit the model regardless of whether it has perceived the same state before, and similar states can produce similar action results. All inputs can produce results.
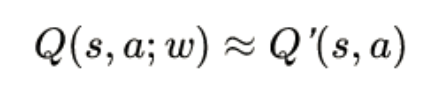
Guided by the reward and punishment functions, GT Sophy evaluates the resulting behavior mentioned earlier. If it receives a positive reward, it will use it as experience and continuously approach the perfect operation behavior; if it receives a negative punishment, GT Sophy will adjust its parameters and continue to try until it receives a reward. This allows GT Sophy to quickly grow and accumulate experience in the environment on its own.“`
These allowed GT Sophy to learn to complete the entire track within a few hours, surpassing over 95% of human drivers. And after 45,000 hours of training, GT Sophy had surpassed 177,000 players on the selected three tracks.
However, setting only a reward mechanism for lap time improvement would cause GT Sophy to become lazy. If the opponent is fast enough, GT Sophy will choose to follow him instead of taking the greater risk of trying to overtake him. GT Sophy will evaluate the most effective way to obtain rewards.
Researchers changed the settings of the reward and penalty functions and set the distance between GT Sophy and its opponents as directly proportional to the reward. Conversely, if an opponent approaches from the rear, the penalty is also directly proportional to the distance that he approaches GT Sophy.
But this led to another problem. Due to the change in settings, GT Sophy’s driving behavior became too aggressive. Additionally, racing games are not zero-sum games like chess and can result in both sides benefiting or losing.
For example, if GT Sophy follows too closely and the opponent chooses a braking point earlier than it, a serious collision will inevitably occur. Finally, the researchers chose to set any collision as a penalty.
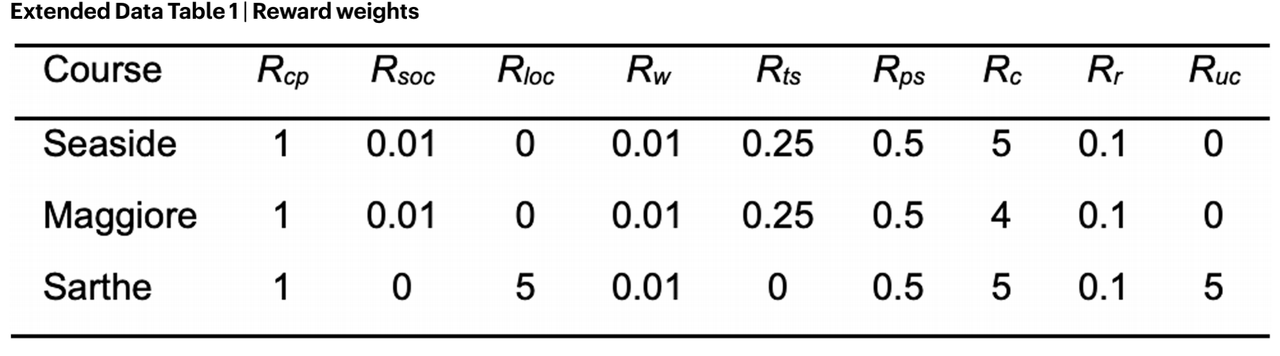
The image above illustrates the different parts and weights of GT Sophy’s reward/penalty functions:
- Rcp: Degree of improvement in GT Sophy’s driving trajectory;
- Rsoc or Rloc: Penalty for leaving the track;
- Rw: Penalty for hitting the racetrack wall;
- Rts: Penalty for slippery tires;
- Rps: Reward for overtaking;
- Rc: Penalty for colliding with opponents;
- Rr: Penalty for rear-end collisions;
- Ruc: Non- aggressive driving collision penalty (to prevent GT Sophy from being too conservative due to fear of impact).
The refinement of these reward and penalty functions and the researchers’ continuous subtle adjustments to the parameters ultimately allowed GT Sophy to learn racing etiquette while maintaining the fastest lap time.
As mentioned earlier, although GT Sophy can collect data and complete iterations on its own, the lack of scenarios may cause it to exhibit “bias.” For example, if the opponent always chooses to stick to the right in a turn during training, GT Sophy can only learn to overtake to the left.
To address this issue, researchers have developed a “mixed-scene training” process. During competitions with human players, researchers identify scenarios in which GT Sophy performs poorly and set specific training for those scenarios.
“`
In the end, GT Sophy achieved overwhelming advantages in all three tracks that served as competition maps.
Sony’s autonomous driving technology reserve?
At the 2022 North American CES conference, Sony Chairman, President, and CEO Kenichiro Yoshida announced that Sony Group would establish a new department – Sony Mobility Corporation, which is expected to be established in the spring of this year. Kenichiro Yoshida stated that “We are exploring the commercialization of Sony electric cars.”
This also means that Sony has officially confirmed its entry into the automobile manufacturing sector. So, to what extent can the technology reserve of GT Sophy’s achievements help Sony’s future autonomous driving?
First of all, we need to throw a jug of cold water: in the game, information such as the map, road material, and information on the current status of other cars are all known perfectly by the algorithm. The weather conditions are not extreme either, which means that the information sensed by autonomous driving is near-perfect. In reality, various car companies have been struggling to improve sensor accuracy, sensor fusion, and other issues.
Moreover, as a driving scenario, the racetrack is highly consistent, with no traffic lights, complex road routes, pedestrians, or as many corner cases as in actual driving.

These factors allow GT Sophy to defeat humans in the racing simulator in a very short period of time, and greatly reduce the workload of the algorithm training process. However, this does not mean that the birth of GT Sophy is useless.
Ashok, the regulatory, automatic labeling, and simulation manager at Tesla, demonstrated Tesla’s decision-making performance in two complex scenarios at last year’s AI DAY: “Three Cars Meeting” and “Parking Automatically in the Parking Lot,” and the vehicles using the same deep-reinforcement-learning technology as GT Sophy achieved almost perfect automatic decision-making in these two scenarios.
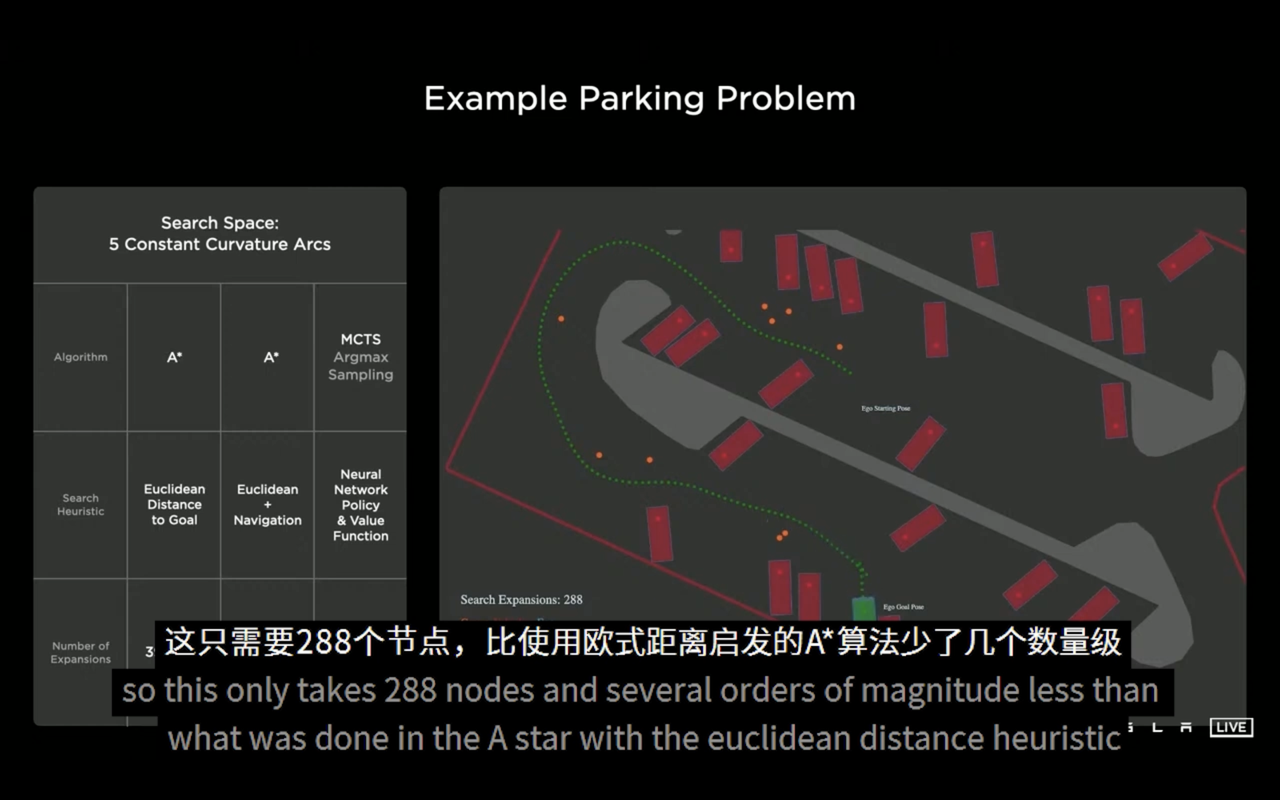
In the “Parking Automatically in the Parking Lot” scenario, the vehicle that used the deep-reinforcement-learning algorithm based on the Monte Carlo tree framework performed better in the path planning process than the vehicle that used the traditional A* algorithm, and the search efficiency improved more than 100 times.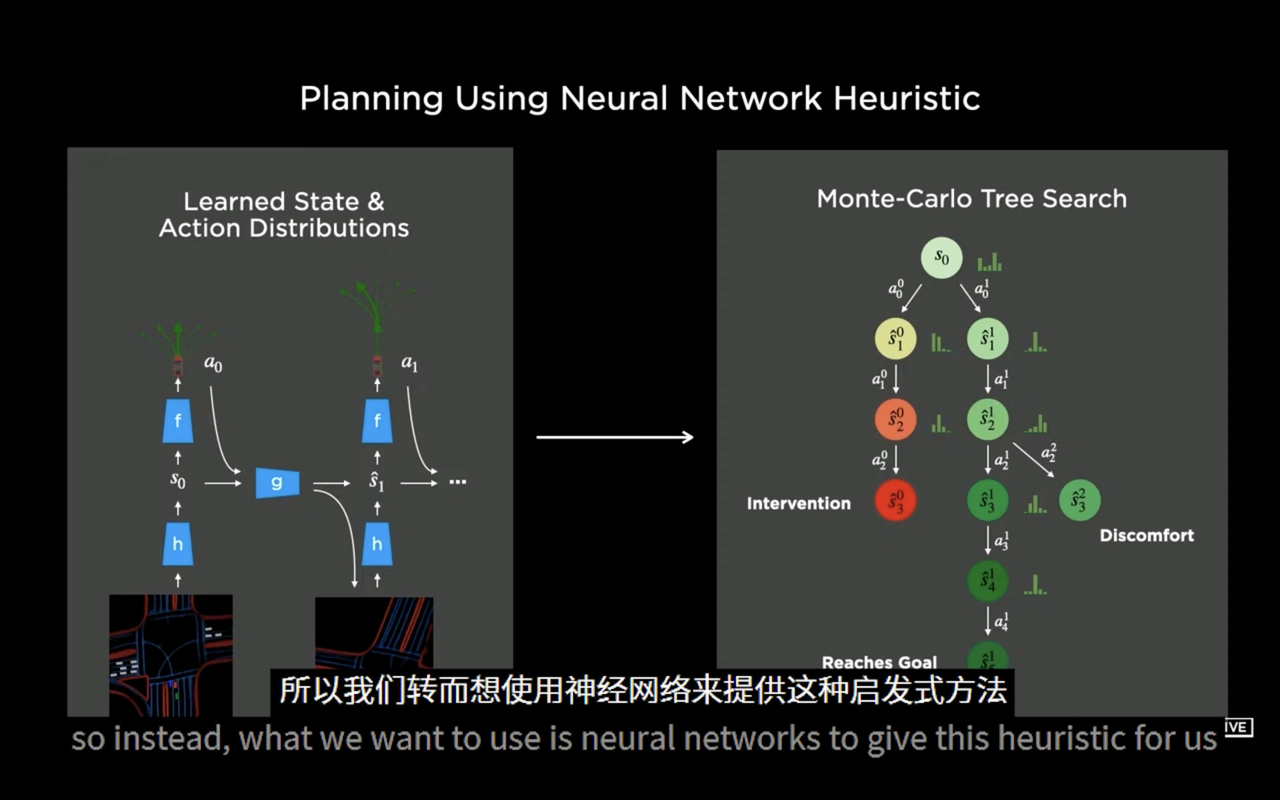
Tesla’s solution using deep reinforcement learning technology for autonomous driving decision-making performs well and has been implemented. This proves that this technology indeed has a very broad prospect, and currently, all autonomous driving companies have taken this as their R&D direction.
Speaking of Sony’s car manufacturing, as early as 2014, Sony commercialized the vehicle-mounted CMOS image sensor. In September 2021, Sony Semiconductor Solutions Group announced that their sensor IMX 459, designed for high-precision laser radar, can achieve a recognition accuracy of 15 cm at a distance of 300 meters. About 100,000 pixels of 10 square micrometers each were mounted on a chip with a diagonal distance of 6.25 mm, meeting the high-precision and high-speed measurement needs.

In the 2020 and 2021 CES exhibitions, Sony stated that the VISION-S prototype car will be equipped with 40 sensors and can achieve L2+ level advanced driving assistance.


Although Sony has not explicitly stated that the results of GT Sophy will be applied to car manufacturing, Chris Gerdes, director of the Stanford University Automotive Research Center, said:
“The success of GT Sophy on the track shows that someday neural networks will play a bigger role in autonomous driving software than they do now.”