The Pursuit of Computing Power: A Misunderstanding in the Automotive Industry
Author: Su Qingtao
30 TOPS, 100 TOPS, 200 TOPS, 500 TOPS, 1000 TOPS, 2000 TOPS… If we solely rely on news reports, we would believe that the consensus among automakers is that “the larger the computing power, the better” and their pursuit of larger computing power is relentless.
The “internal competition” downstream also affects the upstream. In the past few years, some chip manufacturers have been hijacked by automakers’ “computing power anxiety” and rushed to launch large computing power chips. Some manufacturers even “pre-released” chips before they were available to gain a “first-mover advantage”.
However, privately, there are few algorithm engineers or product managers from autonomous driving startups, or algorithm engineers from automakers who agree that “the greater the computing power, the better.” On the contrary, many believe that pursuing large computing power is not only a kind of “intellectual laziness,” but also a manifestation of “inadequate training”.
In fact, chip manufacturers’ attitude towards the current computing power “arms race” is quite subtle — on the one hand, they are active participants (either voluntarily or involuntarily), on the other hand, they do not want to be constantly hijacked by the “trends”. Companies like Horizon Robotics and Mobileye have been desperately “anti-internal competition” in the past year.
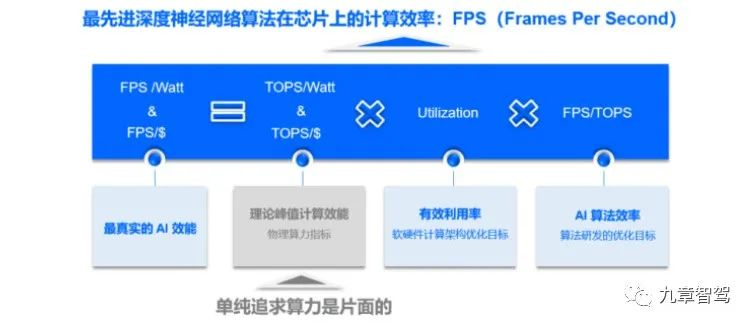
They believe that the quality of a chip cannot be judged solely by its physical computing power, but by the efficiency of advanced algorithms running on the chip, that is, the frame rate per second (FPS) for accurate image recognition. Of course, this requires strong hardware and software coordination to support.
The author also found that some chip manufacturers who have repeatedly emphasized “my computing power is the strongest” and publicly dissed the idea of “improving hardware performance through algorithm optimization” in the past few years are now frequently emphasizing “I also have software capabilities.” It can be seen that even chip manufacturers with full confidence in their computing power will eventually discover that the realization of chip performance still depends on software.For automakers, whether they are willing to admit it or not, they have to accept a fact: AI computing relies not only on chips, but also on algorithms. If the algorithm ability is not strong enough, the computing power of “super high configuration” chips may be greatly wasted; On the other hand, if the algorithm ability is strong enough, it can save a lot of money spent on “buying TOPS”.
“Stacking computing power is a manifestation of insufficient internal cultivation”
At a small salon before New Year’s Day, “Nine Chapters Autonomous Driving” had a discussion with some front-line personnel in the autonomous driving industry on the topic of “computing power arms race”, and their answers were as follows:
A product manager of an unmanned driving company:
I think a key reason for the insufficient use of computing power is that too many sensors have been stacked. But do we really need so many sensors? In fact, everyone has not touched the performance boundary of each sensor. Perhaps the ability of this sensor has not been fully utilized, and new sensors are used to “make up for” it. I think it is better to explore the performance boundary of each sensor and maximize its function before discussing whether to add sensors. This can also save a lot of computing power.
An algorithm engineer of an autonomous driving company:
As a software engineer, I don’t care about these numbers like 500 TOPS or 1000 TOPS because they are not very useful. You may upgrade your computing power, but if your software architecture is still stuck in the old version of three or four years ago, the performance of the computing power cannot be fully utilized, no matter how powerful the computing power is. In fact, by adjusting the software architecture, this problem can be avoided.
The CTO of a leading autonomous driving company:
Stacking sensors and computing power is indeed a headache for me. Investors often ask me how I view this issue, and my answer is usually: “Thinking that the bigger the computing power, the cooler it is, is a kind of thinking laziness.” But there is a real problem that the valuation method used by VCs in the past has been completely broken in the autonomous driving industry. They do not have a good way to judge “who is cooler”. Therefore, companies also feel that investors attach great importance to this indicator, and this phenomenon of stacking hardware appears.
In fact, we use eight 2M cameras + five millimeter wave radars + one lidar, which can support autonomous lane changing at high speeds, but 30 TOPS computing power is enough. Because, as long as the algorithm is good, the existing computing power can be “fully utilized”. In many cases, we do not need too much computing power.#Algorithm optimization
We have done a lot of work around algorithm optimization. Next, we will consider how to integrate the scheduling of computing power with specific driving tasks — each calculation is linked to a specific driving task and the model based on that task. For example, when we need to make a left shift, we will focus the computing power resources on this specific task. Similarly, when we need to maintain lanes, we will focus the computing power resources on this specific task. This is called “driving task-driven optimization of computing power usage.”
Currently, computing resources are not linked to specific functions. Therefore, people are accustomed to talking about peak computing power in a general way. But when all tasks can be finely processed, how much computing power do you need? When computing resources are focused on a specific basic function, we may not necessarily need to perform such frequent detection or use such complex models. We only need to ensure safety, and the demand for computing power will decrease.
Senior engineer at a certain engineering machinery company said:
Recently, we were in communication with an autonomous driving company, and they mentioned a way to improve the utilization rate of computing power and save computing power. For example, the lidar rotates 360 degrees, but when it is fused with the left camera, the lidar only needs to provide the point cloud scanned to the left.
Product manager of a certain automaker’s autonomous driving product:
Stacking sensors and computing power, this hardware arms race has PR value greater than the actual value. Many outsiders only look at these external indicators because they cannot see and understand more things. As a result, they will think that the larger the computing power, the more powerful it is. I think that the 1,000 TOPS of computing power mentioned by some car companies are definitely wasted. In the mass production project that a certain technology giant cooperated with some car companies, the computing power of the autonomous driving calculation platform was over 300 TOPS, but it was enough. Tesla also only used 144 TOPS.
Product manager at a certain L4 autonomous driving company:
In my opinion, excessive stacking of computing power should be a manifestation of insufficient internal skills training. I am not sure how much my algorithm can be optimized, so I don’t know if 200 TOPS or 500 TOPS are enough, and I have no idea at all. On the surface, it is called “hardware pre-embedded”, but in reality, it is because of concerns that poor algorithm optimization will lead to a “computational deficit”.
In the article “What jokes are you making to say that this car chip giant is falling behind,” by Udota, published on January 9th, the author also mentioned the following information: According to an experienced automotive chip engineer, most car manufacturers have encountered various problems during the testing process with powerful Nvidia Orin, mainly manifested in the fact that “car manufacturers do not have enough talent and ability to fully release the performance of the chip,” and the reason is that “there are too few engineers who have the ability of collaborative software and hardware tuning.”According to Annon Shashua, the founder and CEO of Mobileye, only by deeply understanding the interaction between software and hardware can we determine what kind of core should support what kind of algorithm. Therefore, using a large computing power chip is not something that can be achieved simply by “overlooking costs”. If the software capability cannot keep up with the hardware, no matter how strong the hardware performance is, it is expected that it will not be able to fully utilize it. On the contrary, if the algorithm is strong enough and can be efficiently utilized, the performance of a low TOPS chip may not be inferior to that of a high TOPS chip.
At a pre-holiday salon, an industry researcher also said that when he sees “1000 TOPS”, his first reaction is whether the software capability can keep up? The utilization of such a large physical computing power depends on the cooperation with software algorithms.
Although large computing power chips are often associated with the concept of “hardware embedding”, the so-called “hardware embedding” seems to be a false problem. The hardware is not static but iterates rapidly. If you have “embedded” 1000 TOPS, and then a 2000 TOPS chip comes out when your data and algorithms do not yet need 1000 TOPS computing power, then your 1000 TOPS computing power will be “obsolete before being used”.
Currently, the industry generally evaluates the physical computing power/theoretical peak computing power of AI chips in units of TOPS. However, people gradually realize that in actual scenarios, the theoretical peak computing power (the number of physical multipliers multiplied by the highest frequency) is basically impossible to be fully released, and the effective utilization rate of computing power is very low. For example, a chip with theoretical peak computing power of 16 TOPS may have a difference approaching 80% when calculating different models.
In late May 2020, when Nvidia officially launched the Orin chip with a computing power of 200 TOPS and the computing platform based on it with a computing power of 2000 TOPS, Zositech R&D published an article “The Lie of Computing Power (TOPS) in Autonomous Driving”. The core viewpoint of this article is: “High TOPS are all theoretical values of computing unit (PE), not the real value of the entire hardware system. The actual value and the theoretical value differ greatly. In the worst case, the actual value is only 1/10 or even lower than the theoretical value. For example, the theoretical computing power of Google’s first-generation TPU is 90 TOPS, but the worst actual value is only 10 TOPS; the theoretical computing power of Nvidia Tesla T4 is 130 TOPS, but the actual value is only 27.4 TOPS.”
The autonomous driving engineer Yin Wei from a certain automaker mentioned in the article “The True and False TOPS – Don’t be too picky” that:
“The TOPS advertised are often the theoretical values of the computation units, rather than the real values of the entire hardware system. The real values depend more on the internal SRAM, external DRAM, instruction sets, and model optimization. In the worst case, the real value is 1/10 or even lower than the theoretical value, with only 50% utilization. For example, Nvidia Tesla T4’s theoretical computing power is 130 TOPS, but the actual value is only 27.4 TOPS.”
(How is the actual computing power of Tesla T4 calculated to be 27.4 TOPS? ResNet-50 requires about 7 billion MAC operations per second, and Tesla T4 can process 3920 images of size 224*224 per second when running ResNet-50. 3920 images/second x 7 billion operations/image = 27.4 trillion operations/second = 27.4 TOPS.)
It can be said that the peak computing power only reflects the maximum theoretical computing power of AI chips, rather than the processing power in actual AI application scenarios, which has great limitations.
Yin Wei explained in the article:
“If we only look at it statically, the main factor determining the real value of computing power is the memory (SRAM and DRAM) bandwidth. The theoretical value of Google’s first-generation TPU is 90 TOPS computing power, but the worst actual value is only 10 TOPS computing power, which is 1/9 of the theoretical value. This is mainly because the first-generation memory bandwidth is only 34GB/s, and the matching between computing power and memory is not good enough.”
“But if we look at it dynamically and do not consider the algorithm used (the first-generation TPU is more oriented towards a mainstream algorithm), memory and computing power cannot be matched well either.”
“The algorithm’s demand for memory bandwidth is usually expressed in terms of” operational intensity “, which is the number of OPs/byte. This means that on average, how many times the computational operation can be supported for each unit of data read in the algorithm. The higher the operational intensity, the lower the requirement for memory bandwidth, and the higher the utilization of computational units.” Yin Wei concluded that the improvement of computational unit utilization can be divided into three stages:
-
When the operational intensity of the algorithm is low, the computational performance is actually limited by the memory bandwidth, and many computational processing units are idle.
-
As the operational intensity of the algorithm increases, i.e., the algorithm can perform more operations under the same amount of data, the number of idle computational units becomes less and less, and the computational performance will increase.### 3. With increasing computational strength and decreasing idle computing units, eventually all computing units are used up. At this point, the computational strength cannot continue to increase, or rather it encounters a “ceiling” determined by physical computing power (rather than memory bandwidth).
Yin Wei believes that both hardware and software need to be considered together (such as algorithm compatibility, reducing memory access to improve utilization, etc.) in order to fully utilize the system’s performance.
Among all car companies, Tesla is the one that understands this concept the most thoroughly. According to Fortune, Jim Keller’s chip design philosophy at Tesla was: 1. Deeply understand Tesla Autopilot’s algorithm operation mechanism; 2. Reduce or eliminate modules in general chips (such as Nvidia chips) that are not related to Tesla software.
It is precisely because of his deep understanding of algorithms that Jim Keller was able to make the FSD chip very efficient. It can be said that understanding algorithms is the true barrier to AI chip design work.
Horizon Robotics: Competing based on real AI performance, not just hardware muscle
In fact, over the past five years, Horizon Robotics Founder and CEO Yu Kai has repeatedly emphasized that “algorithm capability is the real barrier to chip design.” Yu Kai said: “A chip cannot only rely on hardware performance. Architecture design and insight into algorithms are constantly driving the real performance evolution of AI chips, reshaping Moore’s Law.”
In a speech in mid-June 2021 regarding this round of “computing power arms race,” Yu Kai said: “Top chip companies cannot simply talk about this story with how many TOPS they have. What does 1000T mean? It’s not your utility, performance, or user value, it’s a cost for car companies.”
Before this, Yu Kai had mentioned to me: “In fact, computational power does not have a very high technical threshold. Increasing chip area or adopting a more advanced process is enough. But spreading computational power does not really create user value. The true value lies in how fast the most advanced neural networks can run on this chip, in other words, real AI performance.”
In May 2021, at a forum hosted by Automotive Business Review, Yu Kai cited a specific example in his speech: the Ideal ONE equipped with two Horizon Journey 3 chips in the upgraded version; someone said that “a single chip has only 5 TOPS, and the two chips add up to only 10 TOPS,” but the product manager of Ideal Auto said, “although its single chip computational power is only 5 TOPS, it truly achieves real-time computation for 8 megapixel cameras.”
Yu Kai emphasized: “We don’t just compete based on hardware muscle. We place more value on real AI performance.”# Horizon Co-founder and CTO, Dr. Huang Chang, discovered in his research on convolutional neural networks that the best neural network calculation efficiency in the period between 2014 and 2019 varied by 100 times, which means that the calculation efficiency doubled every 9 months (the required computing power for the same calculation was reduced by half). This speed is much faster than the “doubling every 18 months” of chip computing power.
Huang Chang believes that the algorithm evolution speed is far faster than the hardware improvement speed, leading to a disconnect between the methods for evaluating the performance of AI chips and the development of algorithms. However, if a reasonable evaluation method is not mastered, it is difficult to design good AI chips. Therefore, the industry urgently needs a more reasonable performance evaluation method to help users choose suitable AI chips.
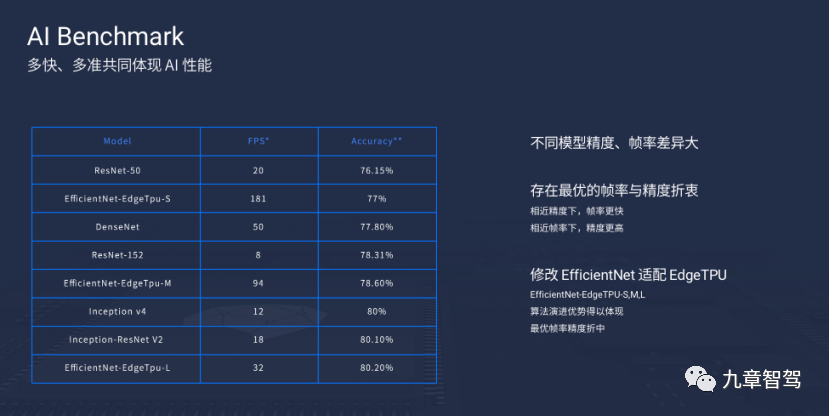
- FPS- The Real Performance of AI Chips
What is the “real performance” of AI chips? Yu Kai said: The world’s most advanced network algorithms can run at a sufficient efficiency on the chip through your architecture, through your edge device, and through your dynamic runtime library- how many frames can be accurately recognized per second?
In August 2020, Dr. Huang Chang proposed the concept of MAPS for the first time at the AI Chip Session of the Global AI and Robotics Summit, which comprehensively answered the above questions. MAPS stands for Mean Accuracy-guaranteed Processing Speed, which evaluates the average processing speed of data by the chip according to the characteristics of the application scenario with guaranteed accuracy.
Usually, to pursue accuracy, speed has to be sacrificed. Therefore, achieving high computation speed under the premise of guaranteed accuracy is quite difficult.
The unit of measurement for MAPS is FPS, which stands for Frame Per Second, i.e. “how many frames can be accurately recognized per second”. Higher FPS represents faster perception and lower latency, which means higher safety performance and driving efficiency. Obviously, compared with TOPS, FPS is a more valuable performance indicator.
MAPS is actually a quantitative result of the best solution obtained by testing a large number of models’ speed (in proportion to physical computing power * actual utilization) and accuracy. It is more focused on enabling users to intuitively perceive the real computing power of AI chips through visual charts.
Dr. Huang Chang believes that “when evaluating the performance of AI chips, we should pay attention to the speed and accuracy of AI tasks, i.e. ‘how fast’ and ‘how accurate’. The MAPS evaluation method focuses on the real value to users, intuitively displaying the changes in the trade-offs between ‘fast’ and ‘accurate’ for each chip, and evaluating the average processing speed of the chip within a reasonable accuracy range.”### In showcasing the true AI performance of chips, the MAPS evaluation method still leaves room for improvement. This “room for improvement” refers to the possibility that even after a chip has been manufactured, its actual FPS performance can still be enhanced, as algorithms continue to progress, and their precision or speed can be improved. This makes it possible for the FPS of the chip to continue to improve.
2. How to calculate the “real AI performance” of a chip?
The following formula has been summarized by Horizon Robotics: real AI performance = physical computational power (peak power represented in TOPS) * effective utilization of computational resources * efficiency of AI algorithm.

What do the parameters in the above table stand for? We will explain them below one by one:
(1) “Theoretical peak computing performance” is usually referred to as “physical computing power” or “peak computing power”.
(2) Effective utilization refers to the utilization rate of the computational resources (multipliers) in the chip.
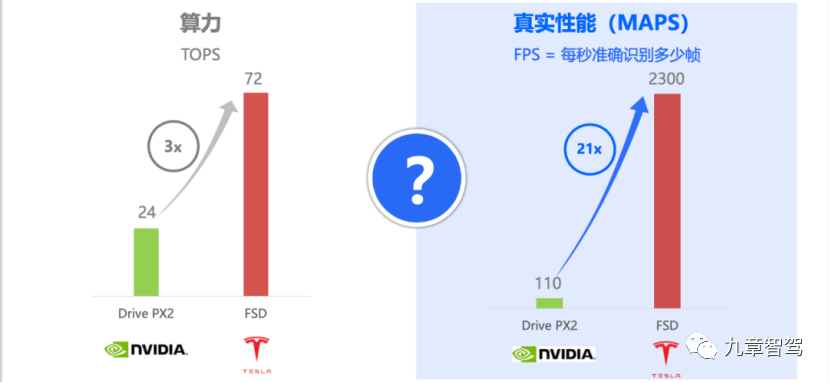
In Hardware 3.0, Tesla replaced Nvidia’s Drive PX2 with its self-developed FSD chip, increasing its computing power from 24 TOPS to 72 TOPS. However, the efficiency of running the same model has increased by an astonishing 21 times. Specifically, when it comes to Hardware 2.0, it could only process 110 frames per second, while now it can handle up to 2300 frames.
Aside from the tripling of absolute computing power, the additional improvement comes from the utilization rate of the computing power increasing by almost twice.
The most significant factor that affects the utilization rate of computing power is architecture. In order to achieve higher utilization of computing power, more efficient utilization of memory bandwidth, and eliminate unnecessary precision requirements, large-scale high-parallel computing becomes a necessary consideration for architecture design.
In order to achieve this goal, Horizon Journey 5 adopts Bayesian architecture. Bayesian architecture is based on large-scale heterogeneous near-storage computing, highly flexible and large-concurrency data bridges, and pulse tensor computing core technologies, which can execute more tasks with less memory and higher MAC utilization rate, thus pushing parallel computing to its extreme.# The Importance of Algorithm for Chip Architectures
From a deeper perspective, the quality of chip architecture depends largely on the ability of algorithms. Therefore, the better a chip team understands the algorithm, the more likely they are to create an optimal chip architecture, and ultimately, increase the utilization rate of computing power.
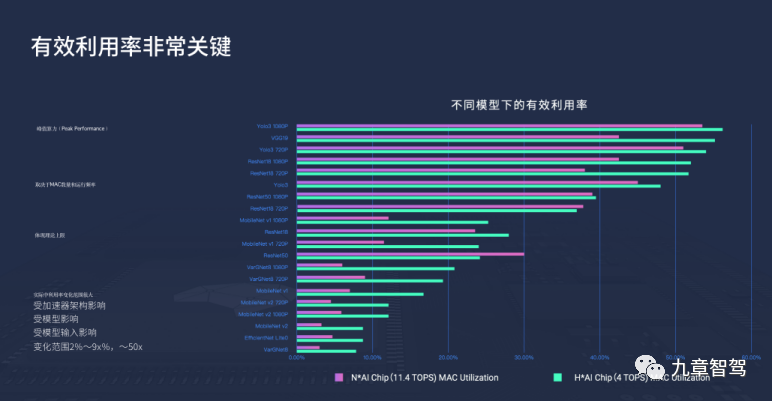
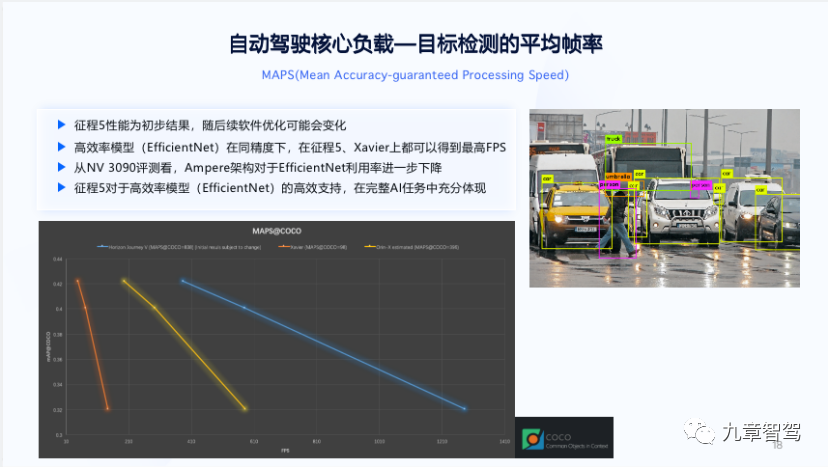
From the above figure, it can be seen that there may be significant differences in the utilization rate of computing power for the same chip when matched with different algorithm models.
During the live course on the evening of January 20th, Dr. Luo Heng, the BPU algorithm manager at Horizon Robotics, emphasized, “We not only look at the algorithm itself, but also its impact on chip architecture. This allows us to quickly focus on it when the MobileNet (depthwise conv) algorithm was first introduced.”
As a chip company with a strong algorithmic gene, Horizon Robotics has set unique algorithm models for autonomous driving scenarios from Journey 1. Furthermore, they predicted the trend for key algorithm development and incorporated its computing characteristics into the design of Bernoulli, Bayesian, and other chip architectures proactively, thus achieving high efficiency in computing resource utilization.
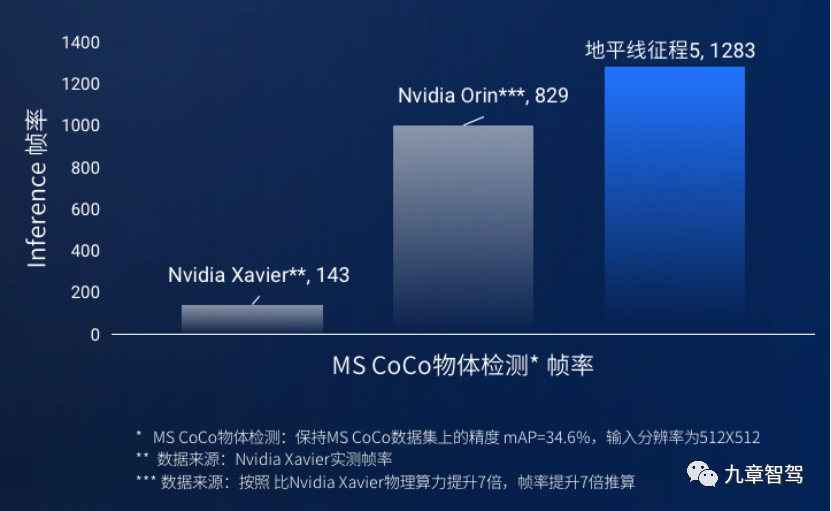
Typically, when running deep neural network algorithms, GPU utilization rates do not exceed 50%, while Journey 3 and Journey 5 have achieved utilization rates of over 90%.
According to information provided by Horizon Robotics, as a dedicated processor architecture for high-level autonomous driving, “the Bayesian architecture can ensure that after a long research and development cycle, the Journey 5 chip can still quickly adapt to the latest mainstream algorithms when officially launched. It can continuously maintain a high effective utilization rate along with algorithm iteration, which truly benefits end-users from the advantages of algorithm innovation.”
(3) The efficiency of AI algorithms is equivalent to what Yin Wei mentioned in his article, “The higher the computational intensity of the algorithm, the lower the idle rate of computing resources.”
Regarding the impact of algorithm efficiency on chip computing efficiency, Dr. Luo Heng gave an example in the live course:
In 2016, Google developed a voice recognition algorithm, WaveNet, which can distinguish between a sales call from a human or a robot. However, at the beginning, this algorithm was weak and resulted in low computing efficiency of GPUs. For example, if a person spoke for 10 seconds, it would take the algorithm several minutes to recognize it, making it impossible to communicate. Later, Google made some optimizations to the algorithm, and the computing efficiency increased several thousand times. At this point, GPUs (TPUs) could calculate the 20-second conversation within 1 second.The most widely used convolutional neural networks in deep learning computing have undergone their most significant changes since their inception, as of 2016-2017, with the advent of depthwise conv. This method achieves high accuracy with fewer calculations.
As shown in the figure below, the same chip (TPU) has significantly different accuracies and frame rates when paired with different algorithm models (far left).
In addition, in the first half of 2021, computer scientists from Rice University in the United States confirmed that a deep neural network training algorithm designed specifically for CPUs, called the sub-linear deep learning engine (SLIDE), trains 15 times faster than GPU algorithms! The emergence of this algorithm even proves that deep learning technology can still be accelerated without relying on professional acceleration hardware such as GPUs.
Take the Horizon chip as an example. The chip design was initially considered to ensure better applicability of future automatic driving related algorithms on BPU and provide the best performance in FPS unit.
Through soft and hard collaborative optimization of algorithms, compilers, and computing architectures, parallel computing is fully utilized and software and hardware coordinated organizational culture, and horizon has ultimately achieved a significant improvement in AI computing efficiency.
At this point, the author recalls a story:
Previously, an engineer from a certain car company complained to the author, “Horizon chips do not have enough computing power.” At the time, the author asked, “Did you write the algorithm yourself or did Horizon provide it?” He said, “We did it ourselves because the previous generation of algorithm migration had some challenges.”
The sequel to this story is that the car company later decided to develop perception algorithms in partnership with Horizon.The car manufacturer has surely realized this: the stronger the algorithmic ability, the less computational power is needed to solve the same problem.
This is easy to understand: a good algorithm is like a good mathematical formula. Even if a person’s IQ (computational power) is not very high, they can quickly arrive at the answer using a good formula. On the other hand, poor algorithms are like bad formulas. Even very intelligent people need to spend more time to arrive at the answer to the problem.
“Algorithmic ability is more important”: A consensus among chipmakers
Horizon is not the only company that holds a similar view. In fact, Mobileye, which has intense positive competition with Horizon in the market, also has a “highly consensual” stance with Horizon on the opinion that “computational efficiency is more important than computational power”.
In September 2020, on the eve of the Beijing Auto Show, Erez Dagan, Mobileye’s Vice President of Product and Strategy, responded to media questions about “your computational power is not as good as others”: “Using just one number to measure a chip is not feasible. The load-bearing capacity of a SoC chip is also very important. Rather than saying that TOPS is a truly technical indicator, it is a unit for manufacturing marketing gimmicks.”
Also at the same time, Hu Zhengnan, the former Dean of Research Institute of Geely Automotive, who had just become “intimate comrades in arms” with Mobileye, spoke up for Mobileye’s views in an interview with New Intelligence Driving, saying: “Chips are not only a reflection of computational power, but more importantly, of their underlying algorithms and library files. Therefore, we are more willing to believe in platforms with accumulated experience in this area. With the improvement of semiconductor technology, computational power will not be a bottleneck in the future. How to bring real value to customers using the TOPS parameter is the key.”
During the CES period in early 2021, Erez Dagan was asked again about “how to view the computational power of ET7 planned to reach 1016 TOPS” and “how to match computational power and demand”. This time, Erez Dagan’s response was: “I would like to reiterate that TOPS numbers are just a thing of the past in a numerical competition. If you need a very powerful computer, it means you actually don’t know what you want, and everything is still in the exploration stage. Once you need to meet economic requirements, you need to find a balance in processing speed, customer demand, and solution costs. This is the real difference in the automotive product business, rather than advertising, showmanship, or just being in the research stage.”In 2022 CES, when unveiling EyeQ Ultra, Amnon Shashua, the President and CEO of Mobileye, didn’t wait for others to “challenge” them and instead proactively “diminished” themselves by saying “176 TOPS sounds like a small number, probably only one fifth of the computing power claimed by its competitor Nvidia. But the key is not just about computing power, it’s about efficiency.”
Shashua said that TOPS is a very insufficient measure of computing power. “The models we integrate into the EyeQ chip are very complex, far from being quantified by a single measure.”
Mobileye believes that they can run the entire SuperVision system on two EyeQ5 chips at a magnitude much lower than other competitors’ computing power or TOPS indicators, thanks to their inherent advantages in chip software and hardware co-design.
Another chip manufacturer, Ambarella, also emphasizes the advantages of software and hardware co-design.
At CES 2020, Ambarella launched its new CV2FS and CV22FS, without disclosing its computing power measured in TOPS, only saying that it “can perform computer vision processing on videos with a resolution of 8 million pixels or higher at 30 frames per second”, which is equivalent to the FPS that Horizon has always been promoting.
The newly released CV3 at this year’s CES measures AI computing power in eTOPS, which means “how many TOPS it is equated to”. Feng Yutao, General Manager of Ambarella China, explained that if the same neural network algorithm can be run as fast, it can be said that this is how many eTOPS it is.
Feng Yutao recently emphasized in an interview with the media that “visual algorithms will be the core competitiveness of CV3”; “achieve higher computing power and efficiency through various technologies such as visual algorithms and self-developed IP cores”, as well as the concept of “algorithm priority”.
Another phenomenon that is extremely important but has not received much attention yet is: as a chip giant that has led the trend of “software-hardware decoupling”, Nvidia’s emphasis on software is also increasing. In fact, the company is transforming itself into a “software company”.
In November 2021, Nvidia CEO Huang Renxun mentioned in an interview with The Next Platform that “three-quarters of the employees in the company are responsible for software development”.
Huang Renxun said:
“The value we provide is obviously mainly reflected in software. The hardware that users purchase only corresponds to the initial performance plus a certain performance upper limit. However, users will gradually gain 3 times, 4 times or even 10 times of subsequent performance improvement during the entire usage cycle. All of this can be achieved through software updates.”> “You can create the world’s most powerful chip and insert it into a computer… but then what? What do you accelerate with it? If there’s nothing to accelerate, how do you talk about acceleration? The difficulty of accelerating computing lies in the high requirements it places on hardware and software coordination. Ultimately, software reflects the way we see the world and reflects our operational strategy.”
After this year’s CES, I posted this on my WeChat moments:
Three to four years ago, when Horizon Robotics proposed “improving the utilization of multipliers and improving the real performance of chips through software capabilities/optimized architecture,” some chip companies that started later dissed this point of view on many occasions, and even stopped short of calling it a “scam”…
However, in the past year or two, large companies like Nvidia have also emphasized this point of view in public occasions (ME should have been talking about it all along)… At this point, chip manufacturers that originally dissed Horizon Robotics’ “hardware performance improvement through software capabilities” are also saying “I have software capabilities.”
Whether voluntarily or involuntarily, continuously improving software capabilities and using them to “add” to hardware will become a required course for every AI chip manufacturer.
Unfinished Thoughts: “Algorithms” and “Computational Power” and “Software and Hardware Integration” in Life
Over the past few years, I have become accustomed to using the thinking of “algorithms and computational power” to explain many phenomena I observe in life, and have also written many inspirational essays. Looking back now, these essays have stood the test of time.
These essays help some newcomers to understand the relationship between algorithms and computational power, so I have decided to share them here:
-
For a period of time, I compared my own growth trajectory with that of some classmates while pondering the relationship between computational power and algorithms. I made a very interesting discovery:
Me: In high school, my studies were not particularly diligent. I stumbled into “Northwest University” during college entrance exams, but due to severe lack of confidence, I “fled Beijing, Shanghai, and Guangzhou” after graduating from college, and was “uncompetitive” for the first nine years after graduation. In the ninth year after graduation, I returned to a first-tier city, and in the tenth year, I entered the autonomous driving industry, which has a high density of talent and information, and my competitiveness rapidly improved.
-
Classmates of the first category: They studied much harder than me in high school, but their exam scores were much lower than mine. The university they eventually attended was also inferior to mine, and it was a university in a third-tier city. But after graduating from college, they boldly went to work in a first-tier city. Soon, their overall cognitive level was much higher than mine, and their overall competitiveness was much stronger than mine – at least in the first eight years after graduating from college. For many years, they have been the objects of my admiration.
The second type of student, who did not work as hard as me, but still got into the same university as me or even better ones; during university, they did not study as hard as me, but their exam scores were higher than mine; after graduation, I could only resort to selling insurance, while they easily secured prestigious job opportunities.
Of course, in the 5-8 years after graduation, I have encountered various extreme conditions and had to complete many transformations beyond my expectations, while they have been enjoying life in their comfort zones. However, in my recent conversations with them, I have found that their overall competitiveness is no longer as good as mine.
If we simply judge based on the diligence level in high school and the university they finally got into, then the “computing power” (intelligence) of the first type of student is obviously weaker than mine, and the “computing power” of the second type of student is far superior to mine. So, why was the former much more competitive than me (for the first 9 years) after graduating university, while the latter was “not so outstanding”?
The fundamental reason is that compared to me, the first type of student went to a first-tier city with a more complex “scenario” and a larger scale of “data” after graduating, which made their “algorithm” iterate much faster than mine. In contrast, I cowardly fled to a small city with a simpler “scenario” and a smaller scale of “data”, resulting in a slow iteration of my algorithm.
(The quotation marks around “scenario” here refers to the working environment and content that a city can provide, “data” refers to various information, knowledge, and interpersonal relationships that the individual encounters while living and working in that city, and “algorithm” refers to the way of thinking and cognitive level. The same applies below.)
As a result, even though my “computing power” was stronger than that of these types of students, their “algorithm” was stronger and therefore their “computing power utilization rate” was higher, leading to a higher “FPS value.”
Of course, in the ninth year after graduation, I also returned to a first-tier city with a more complex “scenario” and a larger scale of “data”, especially since I later joined the autonomous driving industry with more abundant “data,” which narrowed the gap between my “algorithm” and that of the first type of student.
As for the second type of student, they have not been exposed to a single scenario and high-quality “data” in the past few years, so their “algorithm” has not been well-trained, leading to a serious lack of “computing power utilization rate.” Meanwhile, I was fortunate enough to integrate into the autonomous driving industry with a complex industry chain and a high density of talents. This kind of “application scenario” not only provided me with ample “high-quality data” (facilitating me in training my “algorithm” intensively), but also continuously provided me with “open source algorithms” (the thinking patterns of CEOs and engineers), which made my “algorithm” iterate faster.
A good “algorithm” can greatly improve my “computing power utilization rate.” As a result, even though my computing power is weaker, my “FPS value” is higher.## 2. I once doubted that my understanding of “integration of software and hardware” was the result of being brainwashed by Yu Kai. Once it was classified as “brainwashed”, I couldn’t help but question whether it was a fraud and whether the other party’s viewpoint was determined by his own position, so I was cautious.
But one morning, I suddenly remembered that my initial understanding of “integration of software and hardware” actually came from my observations of heart disease, mental illness, and depression from 2006 to 2008- the mental stimulation or disorders often lead to physiological disorders. The relationship between psychology and physiology is similar to that between software and hardware.
Also, in recent years, I have been pondering a question: the state of a person’s mind will affect the performance of his or her physical functions.
I was very bad at sports since I was little, which greatly affected my self-confidence. I always thought that my physical fitness was poor and I couldn’t do anything. Later, I found out that my mental state was better than that of most people, which also kept me energetic all the time, and I didn’t feel tired even when I worked all day long. On the contrary, most people who are younger than me and have a better physical fitness than me cannot achieve this because their mental state is not as good as mine.
Corresponding to the relationship between software and hardware, this is similar to “my computing power is not high, but due to good algorithms, the utilization rate of algorithms is high, so it can achieve greater FPS”, while those people who have good physical fitness but poor mental state are like “the physical computing power is powerful, but the FPS is small”.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.