
Evolution of Tesla Perception Technology
It has been over four months since the Tesla AI Day, where many cutting-edge ideas and detailed technical solutions were introduced, and it has become a hot topic and direction of study for practitioners in the global autonomous driving industry. During this time, I have repeatedly watched the AI Day videos and read many articles analyzing and interpreting them in both Chinese and English. I have been hoping to have the opportunity to share my understanding and interpretation of the AI Day in an article, but due to procrastination, even though it took me so long, the technological innovations demonstrated by Tesla at the AI Day are still at the forefront of autonomous driving visual perception technology. Therefore, I hope to use this article to help more people understand the latest developments and trends in autonomous driving perception technology.

Evolution of Tesla Perception Technology
Through Tesla’s frequent technical sharing, it can be seen that Tesla’s perception technology undergoes a major overhaul every once in a while. According to the Tesla perception technology solutions disclosed at the time of writing this article, I divide the iterative update process of this technology into three important stages: the first evolution represented by HydraNet, the second evolution represented by BEV Layer, and the third evolution represented by the spatiotemporal sequence feature processing module. Each of them will be introduced in detail below.
HydraNet: Multi-task Network with Shared Features
Up to now, most network models in academic research, constrained by limited resources and time, use a publicly available dataset to design a network architecture similar to the one shown in the figure below – which has a Backbone, Neck, and Head for feature extraction and task specific output.
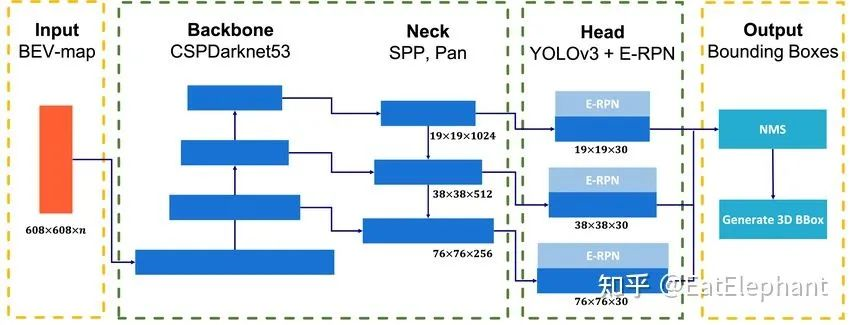 However, for AI to enable cars to understand the traffic environment and complete autonomous driving under human-established traffic facilities, it must simultaneously handle numerous perception tasks (such as vehicle, pedestrian, and bicycle detection, lane line and drivable area segmentation, traffic light and sign recognition, visual depth estimation, and abnormal obstacle detection, etc.). It is impossible to design a separate network for each task using limited on-board computing resources. Additionally, it has been found that the backbone and neck, which are located at the lower levels of the network, mainly extract visual features with universality. Sharing multi-head networks for feature extraction in the perception module of autonomous driving can reduce repetitive feature extraction computation and enable relatively independent optimization of each head’s performance, while the backbone parameters remain unchanged or participate to a lesser degree in updating to meet the needs of autonomous driving.
However, for AI to enable cars to understand the traffic environment and complete autonomous driving under human-established traffic facilities, it must simultaneously handle numerous perception tasks (such as vehicle, pedestrian, and bicycle detection, lane line and drivable area segmentation, traffic light and sign recognition, visual depth estimation, and abnormal obstacle detection, etc.). It is impossible to design a separate network for each task using limited on-board computing resources. Additionally, it has been found that the backbone and neck, which are located at the lower levels of the network, mainly extract visual features with universality. Sharing multi-head networks for feature extraction in the perception module of autonomous driving can reduce repetitive feature extraction computation and enable relatively independent optimization of each head’s performance, while the backbone parameters remain unchanged or participate to a lesser degree in updating to meet the needs of autonomous driving.
Tesla also used this technique before thoroughly refactoring the code for developing FSD, which is currently the technological level achieved by most leading autonomous driving companies. The difference between Tesla and other companies at this stage mainly lies in the number of different types of heads. Based on Andrej Karparthy’s technical sharing in the first half of 2020, Tesla had more than 1,000 heads to solve various autonomous driving perception tasks, which can be classified into more than 50 major perception categories, including but not limited to:
-
Moving Objects: Pedestrian, Cars, Bicycles, Animals, etc.
-
Static Objects: Road signs, Lane lines, Road Markings, Traffic Lights, Overhead Signs, Cross-Walks, Curbs, etc.
-
Environment Tags: School Zone, Residential Area, Tunnel, Toll booth, etc.Tesla named its neural network model HydraNet to symbolize one backbone and multiple heads, due to its numerous heads. However, during a recent interview with Lex, Elon Musk expressed his dislike for the name HydraNet, saying that one day it will be renamed for FSD’s neural network. In a previous article, I provided a detailed introduction to HydraNet’s features, as well as Tesla’s best practices and challenges in training HydraNet. If interested, please refer to the following article for interpretation: Further Research on Tesla Autopilot Technology Architecture, and I will not repeat the details here.

BEV Layer: FSD’s Spatial Understanding Ability
Both the Autopilot prior to FSD’s release and the current mainstream autonomous driving perception neural network structure, such as HydraNet, adopt a shared backbone and multiple heads structure. However, their problem is that the entire perception is carried out in the Image Space where images are located. The Image Space where the camera image is located is a 2D pixel world, while all autonomous driving decision-making and path planning are carried out in a 3D world where the vehicle is located. The mismatch of these dimensions makes it exceptionally difficult to achieve autonomous driving directly based on perception results.
For example, most novice drivers experience difficulty constructing a spatial connection between their vehicle and its surroundings when they first learn to back up using a rearview mirror. As a result, novice drivers are prone to making mistakes and causing collisions when relying on the rearview mirror. This is caused by a lack of spatial understanding ability to convert the image plane observed in the rearview mirror to the vehicle’s coordinate system space.
Therefore, an autonomous driving AI that can only perceive in the camera image plane is like a novice driver lacking spatial understanding ability, making it difficult to complete the challenge of driving the vehicle. At this point, many companies choose to use sensors with depth measurement capabilities, such as millimeter wave radar and LIDAR, to help the camera convert the perception results of the image plane to the 3D world where the vehicle is located. This 3D world is called the vehicle coordinate system in professional terms, and if ignoring the elevation information, many people also call the flattened vehicle coordinate system BEV coordinate system (i.e. bird’s-eye view coordinate system).
 However, as Elon Musk said, humans are not Superman or Batman with laser eyes or equipped with radar. But through the images captured by their eyes, humans can still build a 3D understanding of the surrounding world and master the ability to drive well. Therefore, to use only the eyes (camera) for autonomous driving like humans, it is necessary to have the ability to convert 2D image planes into 3D vehicle spaces.
However, as Elon Musk said, humans are not Superman or Batman with laser eyes or equipped with radar. But through the images captured by their eyes, humans can still build a 3D understanding of the surrounding world and master the ability to drive well. Therefore, to use only the eyes (camera) for autonomous driving like humans, it is necessary to have the ability to convert 2D image planes into 3D vehicle spaces.
The traditional solution uses camera extrinsics and the assumption of a ground plane to project the perceptual results of the image plane back into the vehicle’s BEV coordinate system using a method called IPM (Inverse Perspective Mapping). Tesla’s original solution was also done this way. However, when the ground does not meet the plane assumption and the correlation between multiple camera views is affected by various complex environmental factors, this type of method becomes increasingly difficult to maintain.

Due to the difficulties encountered by the IPM method, Andrej Karparthy and his team began to try to directly complete the space transformation from the image plane to the BEV in the neural network. This change became the most significant difference between the FSD Beta released in October 2020 and the previous Autopilot products.
Because the images input into the visual perception are already in the camera’s 2D plane, and the 2D image plane and the vehicle’s BEV exist in non-uniform sizes and dimensions. The most important thing to perform image plane to BEV space transformation inside the neural network model is to find a way to perform spatial scale transformation of the feature map inside the neural network.
The mainstream neural network operations that can perform spatial scale transformation mainly include the Fully Connected Layer in MLP and the Cross Attention in Transformer, as shown in the following figure (image reference from towardsdatascience.com/). Both methods can change the spatial scale of the input to achieve the purpose of scale transformation.
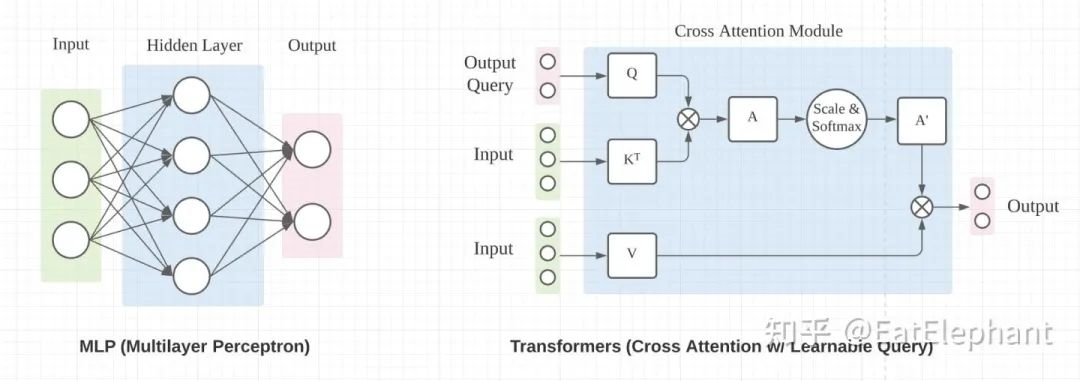 The goal was to explain the BEV transformation as clearly as possible without relying too heavily on formulas, but BEV transformation itself is a mathematical transformation at the scale level, which is difficult to explain without using formulas. Here, the formulas are used to illustrate the BEV transformation.
The goal was to explain the BEV transformation as clearly as possible without relying too heavily on formulas, but BEV transformation itself is a mathematical transformation at the scale level, which is difficult to explain without using formulas. Here, the formulas are used to illustrate the BEV transformation.
Fully Connected Layer:
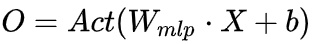
Ignoring the non-linear activation function and bias, we have:
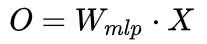
Cross Attention:

Here K and V are obtained by linearly transforming the input X, and Q is the index quantity of the output space map transformed by linearly transforming the input image. The formula can be modified slightly to obtain:
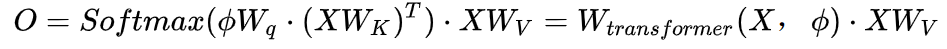
The process of performing the BEV transformation is actually the process of using either of the two operations to transform the feature map layer in the 2D image space of the input to the feature map layer in the BEV self-vehicle coordinates. Therefore, assuming that the scale of the feature map layer in the image space is the scale of X after multi-layer CNN feature extraction, which is the height multiplied by the width of the image, the scale of the BEV space in which O is located is a grid space established within a certain range in front, back, left, and right of the self-vehicle position.
The main difference between the Fully Connect Layer and Cross Attention is actually the coefficient W that acts on the input X. Once the Fully Connect layer’s W is trained and its training is over, it will remain fixed and unchanged during the Inference phase, whereas the Transformer’s X coefficient W, which uses Cross Attention, is a function of both the input X and the index image, and can change during the Inference phase depending on the differences between the output X and index image, which might make the model more expressive. For this reason, Tesla actually uses the Cross Attention method to implement the BEV layer in their solution.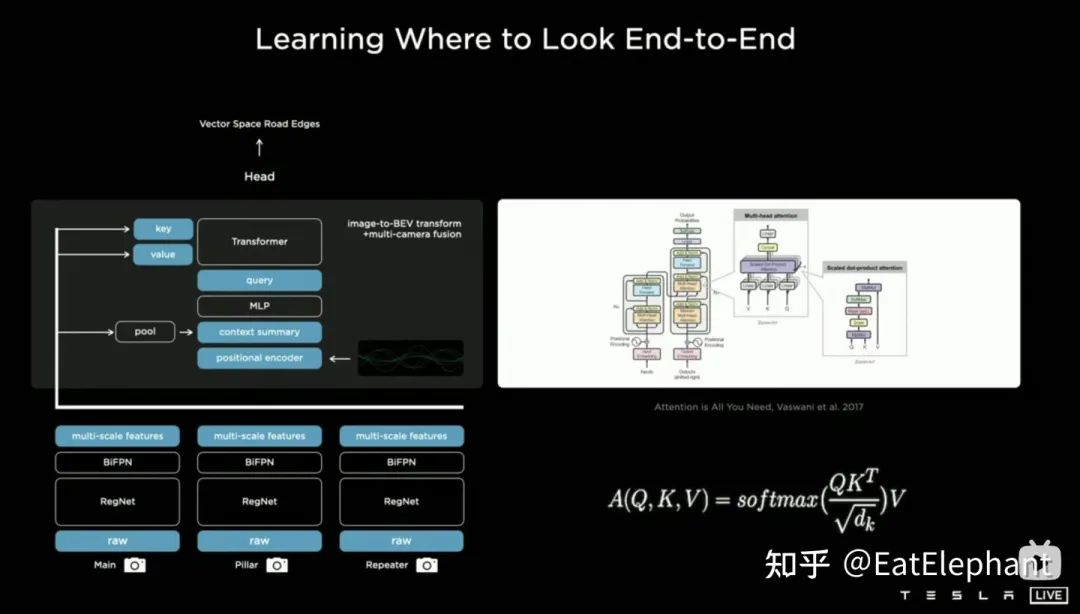

The above two images demonstrate the implementation of Tesla’s BEV Layer based on Transformer. Firstly, multi-scale feature map layers are extracted from different cameras through CNN backbone network and BiFPN. These layers are used to generate the Key and Value required in the Transformer via MLP layer, and on the other hand, they are globally pooled to obtain a global Description Vector (i.e., Context Summary) of multi-scale feature maps. Meanwhile, by rasterizing the target output BEV space and encoding each BEV grid positionally, these positional encodings are concatenated with global Description Vector, and then the Transformer’s required Query is obtained through another MLP layer. In the Cross-Attention operation, the scale of Query determines the output scale of the subsequent BEV layer (i.e., BEV grid scale), and Key and Value are located in 2D image coordinate space. According to the principles of Transformer, the influence weight that each BEV grid receives from pixels in the 2D image plane is established by establishing a relationship between the BEV and the input image through Query and Key, and using these weights to weight the Value obtained from the features in the image plane, and finally obtaining the Feature Map in the BEV coordinate system, thus completing the mission of the BEV coordinate transformation layer. Subsequently, various perception functional heads based on the BEV Feature Map can be used for perception directly in the BEV space. The perception results in the BEV space are unified with the coordinate system of decision-making and planning, so perception and subsequent modules are closely connected by the BEV transformation.“`markdown
Through this method, the actual changes in camera extrinsics and ground geometry are internalized into the parameters of the neural network model during the training process. One problem here is that there are slight differences in the camera extrinsics of different cars using the same set of model parameters. Karparthy added a method that Tesla uses to address such differences during the AI Day: they use the calibrated extrinsics to convert the images captured by each car to the same standardized virtual camera layout by removing distortion, rotating, and restoring distortion, thus eliminating the small differences in camera extrinsics of different cars.

In addition to the advantage of using perception output directly for decision-making and planning, the BEV method is also a very effective multi-camera fusion framework. Through the BEV method, it is possible to estimate and track large nearby objects that are difficult to correctly associate across multiple cameras more accurately and stably, and this scheme also makes the algorithm more robust to short-term occlusion or loss of one or several cameras.

Spatiotemporal Feature: Adding Short-term Memory to Autonomous Driving Intelligence
“`# BEV’s use has established Tesla FSD’s leading position in visual perception, yet relying solely on HydraNet and BEV still results in the problem of continuous information loss due to the use of only multiple images at a single moment as sensory input. Much of human perception of speed and space comes from the time dimension. For example, a seasoned driver can complete a driving task well in a familiar environment, but if the video taken in this environment is split into random single frames and the driver is asked how to steer the car or accelerate or brake in one of the frames, the driver would probably be puzzled. The reason why seasoned drivers cannot give driving instructions based on single frame images is that the human brain, familiar with continuous data processing, cannot form a good spatial concept or process time-related information such as surrounding objects’ speed and trajectory in a single frame image, thereby rendering our driving ability unable to function properly.
Similarly, FSD also needs to have the ability to process continuous spatiotemporal sequence data in order to correctly handle common flickering traffic lights in urban environments, distinguish temporarily parked vehicles from stationary ones on the roadside, predict relative speeds of surrounding objects and the self-driving car, predict possible trajectories of surrounding objects based on historical information, handle short-term occlusion issues, and remember recently encountered speed signs, lane directions, and so on. In other words, FSD needs to be endowed with short-term memory.

However, how human memory works remains one of the unsolved mysteries in neuroscience, and therefore AI algorithms still cannot replicate the human brain’s long-term memory capacity. Nevertheless, Tesla hopes to give the perception model short-term memory capabilities by training the neural network with video clips that contain temporal information instead of plain images, using two separate feature queues respectively for the temporal and spatial dimensions in the neural network model. As for why spatial feature queues are needed, Karparthy gave an example: if a car reaches a traffic light intersection and stops, and the car sees arrows indicating the direction of each lane allowed to drive in before reaching the intersection, the directional information of each lane observed in previous moments will eventually be forgotten if we rely solely on the temporal queue, especially when the red light lasts for a very long time. However, if we introduce the spatial queue, the memory of the observed lane driving direction before reaching the intersection can be retained regardless of how long the car stops at the red light.
 When it comes to fusing temporal information, Tesla has tried three mainstream approaches: 3D Convolutional Neural Networks (CNN), Transformers, and Recurrent Neural Networks (RNN). All three methods require the combination of ego-motion information with single-frame perception. According to Karparthy, only four-dimensional ego-motion information including speed and acceleration, which can be obtained from an IMU, was used. This information is concatenated with the feature map (20x80x256) in a Bird’s Eye View (BEV) space and positional encoding to form a 20x80x300x12-dimensional feature vector sequence. The third dimension is composed of 256 visual features, 4 kinematic features (vx, vy, ax, ay), and 40 positional encoding features, making 300 = 256 + 4 + 40. The last dimension represents 12 down-sampled frames in the time and spatial dimensions.
When it comes to fusing temporal information, Tesla has tried three mainstream approaches: 3D Convolutional Neural Networks (CNN), Transformers, and Recurrent Neural Networks (RNN). All three methods require the combination of ego-motion information with single-frame perception. According to Karparthy, only four-dimensional ego-motion information including speed and acceleration, which can be obtained from an IMU, was used. This information is concatenated with the feature map (20x80x256) in a Bird’s Eye View (BEV) space and positional encoding to form a 20x80x300x12-dimensional feature vector sequence. The third dimension is composed of 256 visual features, 4 kinematic features (vx, vy, ax, ay), and 40 positional encoding features, making 300 = 256 + 4 + 40. The last dimension represents 12 down-sampled frames in the time and spatial dimensions.

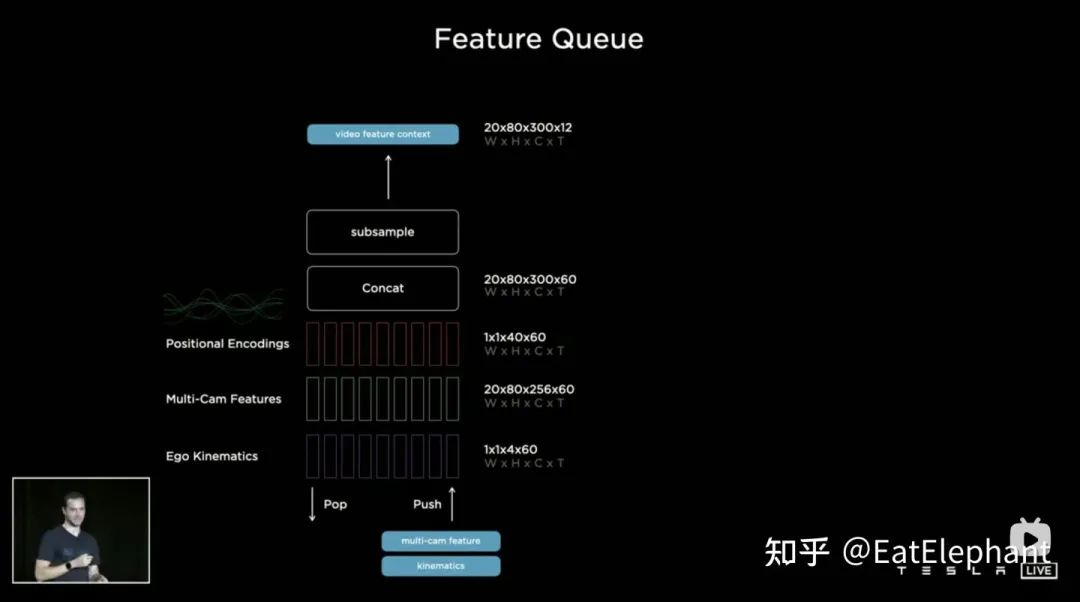
All three methods-3D CNN, Transformer, and RNN-can handle sequential information, with different advantages and disadvantages for different tasks. At AI Day, Karparthy shared another simple yet effective and interestingly explainable approach, called the Spatial RNN. Unlike the three methods mentioned above, Spatial RNN can preserve the input order due to the serial nature of RNNs for sequence processing. Therefore, the BEV visual feature does not require positional encoding before being fed into the RNN network, and only 20x80x256 BEV visual feature map and 1x1x4 ego-motion information are included in the input.
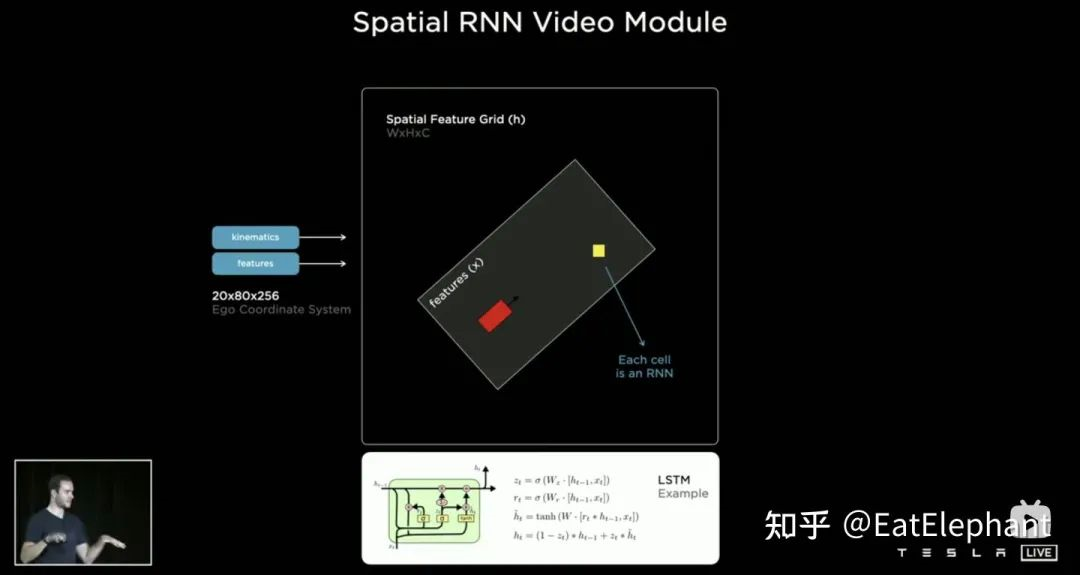 Spatial features in CNN often refer to features on the width and height dimensions of the image plane. In Spatial RNN, Spatial refers to two dimensions in a local coordinate system based on the BEV (bird’s-eye view) coordinate of a certain moment. Here, we use the RNN layer with LSTM as an example, as LSTM has strong interpretability. The advantage of LSTM is that it can preserve the encoding of the states of the variable length N moments in the Hidden State (i.e., short-term memory), and the input and Hidden State can determine which part of the memory state needs to be used or forgotten at the current moment. In Spatial RNN, Hidden State is a rectangular grid area larger than the BEV grid space with the size of (WxHxC) (as shown in the figure, WxH is greater than the size of BEV 20×80), and the motion information of the ego vehicle determines which part of the grid of Hidden State is affected by the front and rear BEV features, so that the continuous BEV data can update the large rectangular region of Hidden State, and each update location matches the ego vehicle’s motion. After continuous updates, a Hidden State feature map similar to a local map is formed, as shown in the figure.
Spatial features in CNN often refer to features on the width and height dimensions of the image plane. In Spatial RNN, Spatial refers to two dimensions in a local coordinate system based on the BEV (bird’s-eye view) coordinate of a certain moment. Here, we use the RNN layer with LSTM as an example, as LSTM has strong interpretability. The advantage of LSTM is that it can preserve the encoding of the states of the variable length N moments in the Hidden State (i.e., short-term memory), and the input and Hidden State can determine which part of the memory state needs to be used or forgotten at the current moment. In Spatial RNN, Hidden State is a rectangular grid area larger than the BEV grid space with the size of (WxHxC) (as shown in the figure, WxH is greater than the size of BEV 20×80), and the motion information of the ego vehicle determines which part of the grid of Hidden State is affected by the front and rear BEV features, so that the continuous BEV data can update the large rectangular region of Hidden State, and each update location matches the ego vehicle’s motion. After continuous updates, a Hidden State feature map similar to a local map is formed, as shown in the figure.
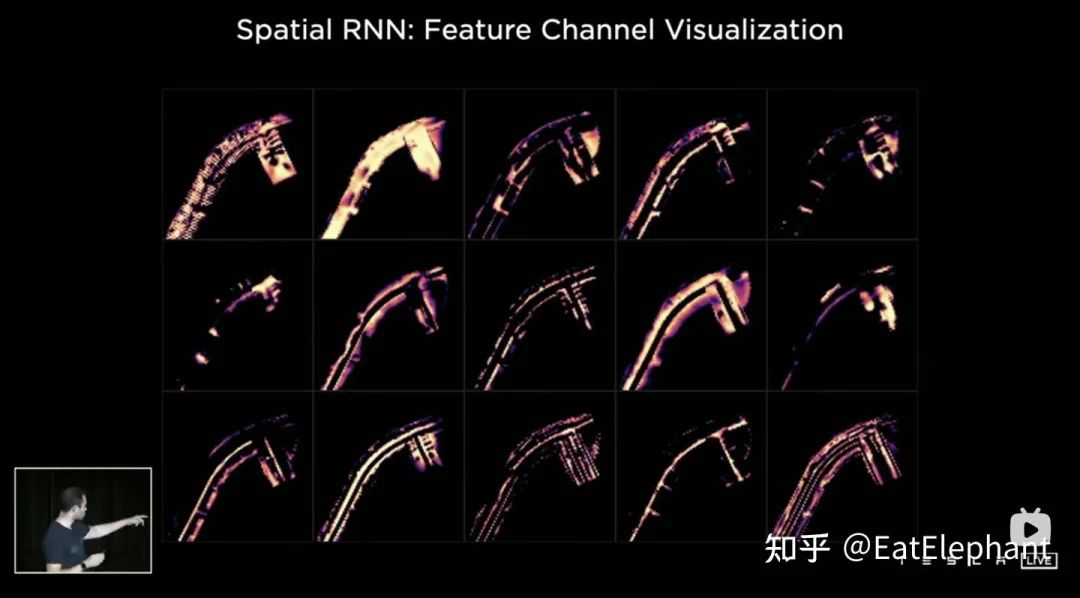

The use of time series queue gives the neural network the ability to obtain continuous perception results between frames. Combined with the BEV, FSD (full self-driving) can cope with blind spots and obstructions, and selectively read/write local maps. It is precisely because of such real-time map-building abilities that FSD can perform self-driving in cities without relying on high-precision maps.
 ## One More Thing: Photon to Control, Tesla’s Secret Weapon to Replace ISP
## One More Thing: Photon to Control, Tesla’s Secret Weapon to Replace ISP
At AI Day, Tesla’s perception technology stack for FSD was introduced in great detail. However, due to time constraints, not all the perception technologies used in FSD could be covered. Students who have been following the FSD Beta testing will find an often-misunderstood feature description in each version’s FSD Release Note, as shown in the figure below:

The literal meaning of photon-to-control is from photons to vehicle control, but even as an industry practitioner in the field of autonomous driving, I find it difficult to understand its specific meaning. It seems that no other autonomous driving company has used similar technology, and even the specific meaning of this technology is unknown.
Fortunately, Lex Fridman, a podcast host whom I like very much, conducted a two and a half hour-long interview with Elon Musk on his show not long ago, during which Elon discussed Photon-to-Control, thereby bringing this unique Tesla visual processing technology to the surface.
It turns out that most autonomous driving companies use an ISP (Image Signal Processing) module to adjust the image after obtaining raw image data from sensors, such as performing white balance, dynamic range adjustment, filtering, and other operations to obtain the best image quality before sending the adjusted image to the perception module for processing. This step is crucial for the autonomous driving perception module because our eyes are an incredibly complex visual sensor that can dynamically adjust the received images based on the actual surrounding environment, such as adjusting exposure to adapt to brightness changes, adjusting focus to focus on objects at different distances, among other things. In contrast, autonomous driving systems try to use the ISP module to approach the performance of the human eye. However, the original purpose of ISP was to obtain a beautiful picture in a constantly changing external environment. Still, there is currently no consensus on the image form that autonomous driving needs most, which sometimes makes it difficult for the ISP to process image data, and more often, it can only adjust the processing effect of the ISP based on human judgment.However, Musk believes that the most primitive form of data captured by cameras is the counting of visible light photons through CMOS sensors that have reached the sensor through the lens. Regardless of the processing method used by ISP, part of the original image information will be lost in essence. Therefore, Tesla started to try using the images obtained from the raw photon count as neural network input, which not only saves the computing power required by ISP, reduces the latency, but also maximizes the information obtained from the sensor. According to Musk, even in low-light conditions, the reflection of pedestrians can cause tiny photon changes in the raw photon count images. The final result is that the perception system using photon as input not only responds faster and has lower latency, but also achieves ultra-long night vision range far beyond human eyes, and is as powerful as science fiction.
All of this may seem a bit sci-fi at first, but the related update content of photon-to-control found in Tesla FSD’s official Release Note undoubtedly proves that this is the technology that Tesla has already applied to its product features. Of course, it can be imagined that such raw photon data may be difficult to annotate using traditional methods, so it may not completely replace ISP in the short term. However, Tesla’s attempts in these cutting-edge directions can greatly inspire other practitioners in this industry.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.