Introduction

The sensors used in autonomous driving perception technology mainly include cameras, LiDAR and mmWave radar. Each of these sensors has its advantages and disadvantages, and they complement each other. Therefore, how to efficiently fuse the data from multiple sensors has naturally become one of the hotspots of perception algorithm research. This article introduces how to fuse LiDAR and camera in perception tasks, with a focus on the current mainstream fusion algorithms based on deep learning.
The data generated by cameras is 2D images, which have higher accuracy in perceiving the shape and category of objects. The success of deep learning technology stems from computer vision tasks, and many successful algorithms are also based on image data processing. Therefore, image-based perception technology is relatively mature at present. The disadvantage of image data is that it is greatly affected by external lighting conditions and is difficult to apply to all weather conditions. For monocular systems, it is also difficult to obtain depth (distance) information of the scene and objects. The binocular system can solve the problem of depth information acquisition, but the computational workload is high. LiDAR makes up for the shortcomings of cameras to a certain extent by accurately perceiving the distance of objects. However, it is limited by high cost and difficult to meet the requirements of vehicle regulations, making it difficult to be applied in mass production. At the same time, the 3D point cloud generated by LiDAR is relatively sparse (e.g., vertical scanning lines only have 64 or 128). For distant or small objects, the number of reflection points will be very less.
As shown in the figure below, there is a huge difference between image data and point clouds. First, the viewing angle is different. Image data is a two-dimensional representation obtained by perspective projection of the real world, while the 3D point cloud contains three-dimensional information in the real world Euclidean coordinate system and can be projected to multiple views. Second, the data structures are different. Image data is regular, ordered, and dense, while point cloud data is irregular, unordered, and sparse. In terms of spatial resolution, image data is much higher than point cloud data.
!Image source from reference [1]There are two typical tasks in autonomous driving perception system: object detection and semantic segmentation. The rise of deep learning technology originally comes from the field of vision. Object detection and semantic segmentation based on image data have been widely and extensively studied, and there have been many comprehensive review articles on this topic. Therefore, it will not be repeated here. On the other hand, with the continuous popularization of onboard lidar and the release of some large-scale databases, research on point cloud data processing has also developed very rapidly in recent years. Two articles previously introduced the development of point cloud object detection and semantic segmentation, which can be referred to by interested friends. Below, we will mainly introduce different fusion methods for object detection tasks. The fusion method of semantic segmentation can be extended from object detection, so it will not be separately introduced.
![Image source from reference [1]](https://upload.42how.com/article/image_20220111163752.png){kind=link}
Different Fusion Strategies
Object detection strategies are divided into: decision-level fusion, decision+feature level fusion, and feature-level fusion. In decision-level fusion, the object detection results (BoundingBox) of the image and point cloud are obtained separately and then merged after being converted to a unified coordinate system. Most of the methods used in this strategy are traditional methods, such as IoU calculation, Kalman filtering, etc. They are not closely related to deep learning. Therefore, they will not be introduced in this article. The following will focus on the latter two fusion strategies.
Decision + Feature level fusion
The main idea of this strategy is to first generate candidates for objects through a data generation method (Proposal). If image data is used, 2D candidates will be generated, and if point cloud data is used, 3D candidates will be generated. Then, the candidates are combined with another type of data to generate the final object detection result (the data generating the candidate can also be reused). This combination process is to unify candidates and data in the same coordinate system, which can be 3D point cloud coordinates (such as F-PointNet) or 2D image coordinates (such as IPOD).
F-PointNet [2] generates 2D object candidates from image data, and then projects these candidates into 3D space. Each 2D candidate corresponds to a frustum in 3D space and all the points falling into the frustum are merged to be the feature of the candidate. The points in the frustum may come from foreground occlusion objects or background objects, so 3D instance segmentation is needed to remove the interference and only keep the points on the object for subsequent object box estimation (similar to the processing method in PointNet). The disadvantage of this frustum-based method is that it can only process one object to be detected in each frustum, which cannot meet the requirements for crowded scenes and small targets such as pedestrians.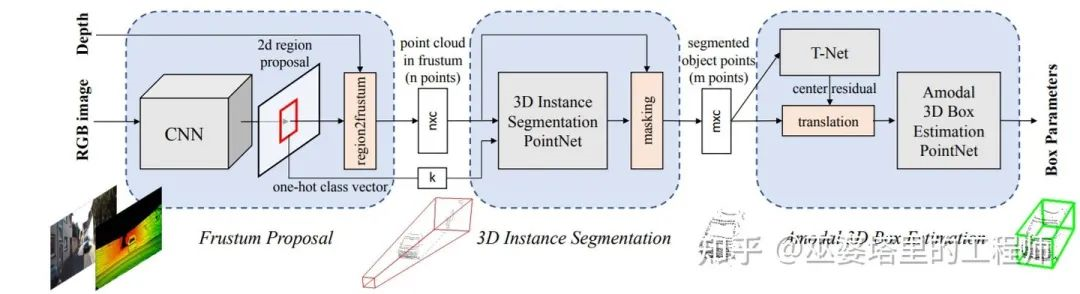
To address the above issue with the frustum, IPOD [3] proposes to use 2D semantic segmentation instead of 2D object detection. Firstly, the semantic segmentation results on the image are used to remove the background points from the point cloud, which is achieved by projecting the point cloud onto the 2D image space. Next, candidate object boxes are generated at each foreground point and NMS is used to remove overlapping candidates, resulting in approximately 500 candidate boxes per frame. Meanwhile, PointNet++ mesh is used to extract point features. With the candidate boxes and point features, a small-scale PointNet++ is used for predicting the category and precise object box (other networks such as MLP are also available). IPOD generates dense candidate object boxes based on semantic segmentation, thus achieving good performance in scenes with a large number of objects and occlusions.
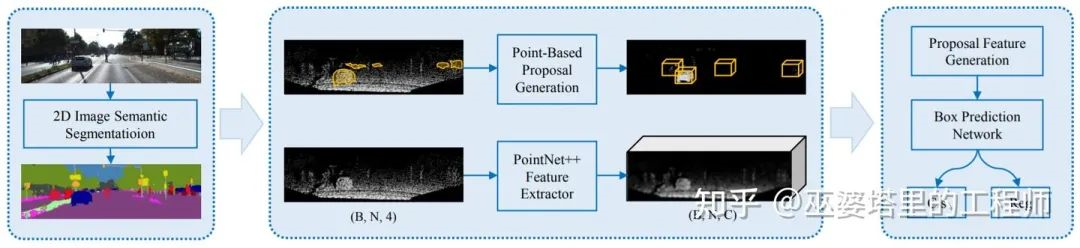
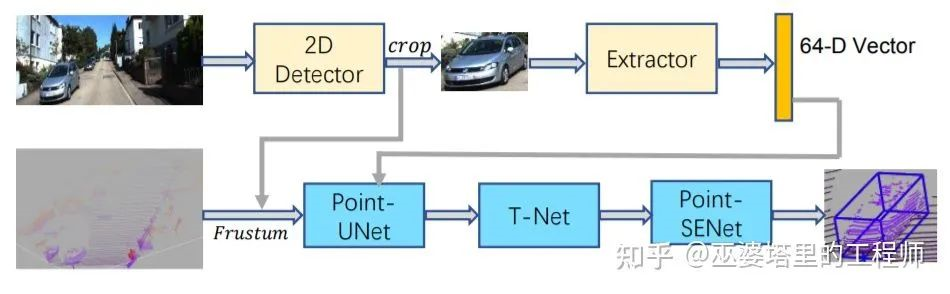
The two methods above both generate candidate boxes through object detection and semantic segmentation results on 2D images, and subsequently perform subsequent processing only on point cloud data. SIFRNet [4] proposes to fuse point cloud and image features on the frustum to enhance the information contained in the frustum, thereby further improving the quality of object box prediction.
In recent years, the selection of object candidate boxes has gradually shifted from 2D to 3D with the rapid development of 3D object detection technology. MV3D [5] is a representative work based on 3D candidate boxes. Firstly, it maps the 3D point cloud to the BEV view to generate 3D object candidate boxes based on the view, which are then mapped to the frontal view of the point cloud and the image view, and the corresponding features are fused. The feature fusion is based on candidate boxes and is completed by ROI pooling.
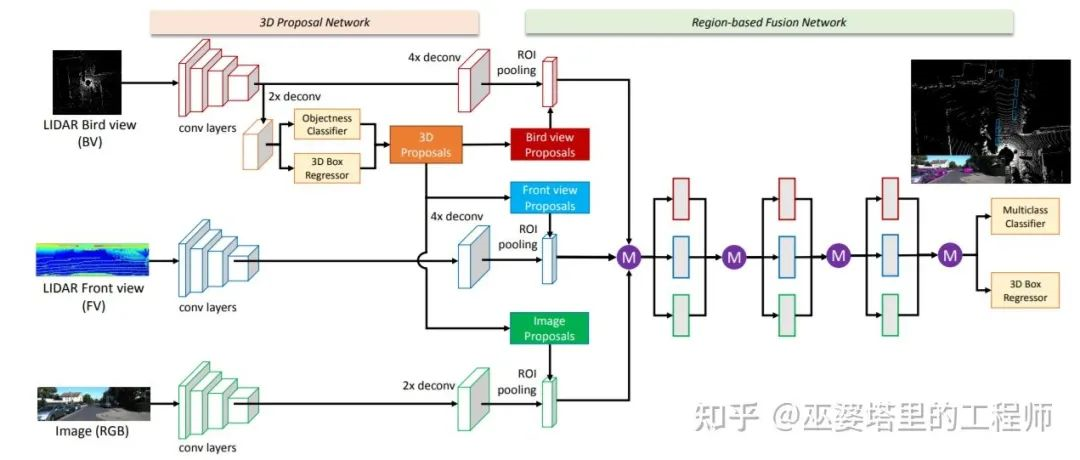 The idea of AVOD [6] is to fuse image and point cloud features based on 3D candidate boxes. However, the original candidate boxes are not generated by point cloud processing, but by uniform sampling in BEV view based on prior knowledge (with a 0.5-meter interval and size equaling to the mean of each object class). Point cloud data is utilized to assist in removing empty candidate boxes, resulting in 80,000 to 100,000 candidate boxes per frame. These candidate boxes are further filtered by fused image and point cloud features and sent to the second-stage detector as the final candidates. Therefore, it can be considered that AVOD’s candidate boxes are generated from both images and point clouds.
The idea of AVOD [6] is to fuse image and point cloud features based on 3D candidate boxes. However, the original candidate boxes are not generated by point cloud processing, but by uniform sampling in BEV view based on prior knowledge (with a 0.5-meter interval and size equaling to the mean of each object class). Point cloud data is utilized to assist in removing empty candidate boxes, resulting in 80,000 to 100,000 candidate boxes per frame. These candidate boxes are further filtered by fused image and point cloud features and sent to the second-stage detector as the final candidates. Therefore, it can be considered that AVOD’s candidate boxes are generated from both images and point clouds.
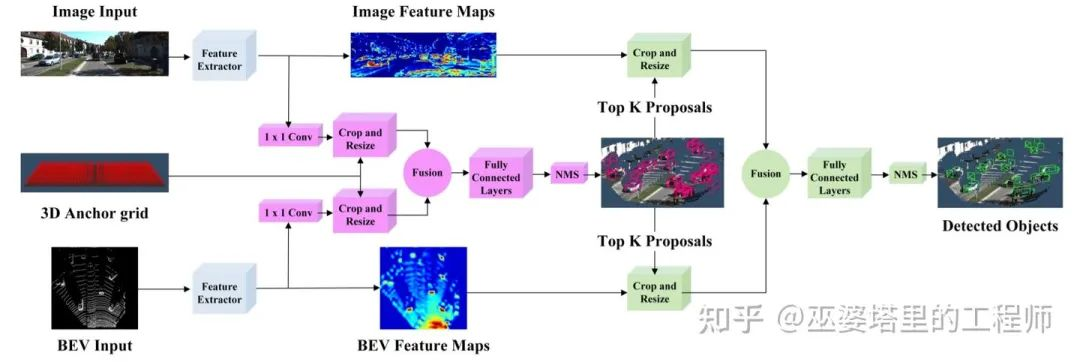
Feature Fusion
The characteristic of decision-making and feature fusion is to fuse different features around the object candidate boxes, typically using ROI pooling (such as bilinear interpolation), which will lose spatial detail features. Another strategy is feature layer fusion, which directly fuses multiple features. For instance, the point cloud is mapped to the image space as an additional channel with depth information to merge with the image’s RGB channel. Although this approach is simple and effective for 2D object detection, it loses much 3D spatial information during fusion and does not work well for 3D object detection. Due to the rapid development of 3D object detection, feature layer fusion is more likely to be accomplished in 3D coordinates, providing more information for 3D object detection.
ContFuse [7] uses continuous convolution to fuse point cloud and image features, and the fusion process is conducted in the BEV view. For a pixel (grid) on the BEV, find its K nearest neighbors in the point cloud data, and then map these 3D points to the image space to obtain the image features of each point. At the same time, the geometric feature of each point is the XY offset from the corresponding BEV pixel. Merge the image features and geometric features as point features, then use continuous convolution to weight the sum (weights depend on XY offsets) to obtain the feature value at the corresponding BEV pixel. By performing similar processing on each pixel in the BEV, a BEV feature map is obtained. ContFuse carries out the above feature fusion at multiple spatial resolutions to improve the detection capability for objects of different sizes.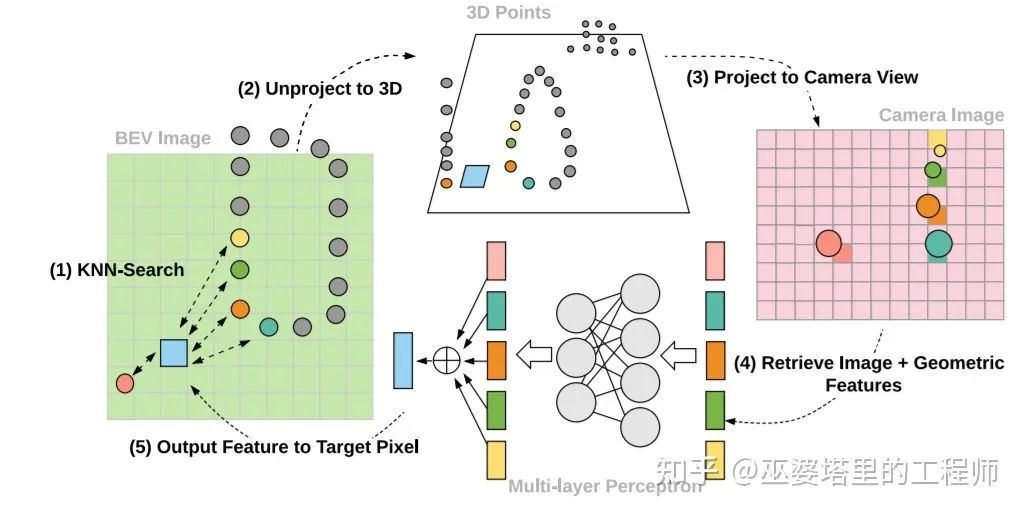
PointPainting [8] projects point clouds onto the results of image semantic segmentation, similar to the approach in IPOD. However, instead of using semantic segmentation to separate foreground points, PointPainting directly attaches the semantic segmentation information to the point cloud. The advantage of this approach is that the fused data are still point clouds (but with richer semantic information) that can be processed by any point cloud object detection networks, such as PointRCNN, VoxelNet, PointPillar, etc.
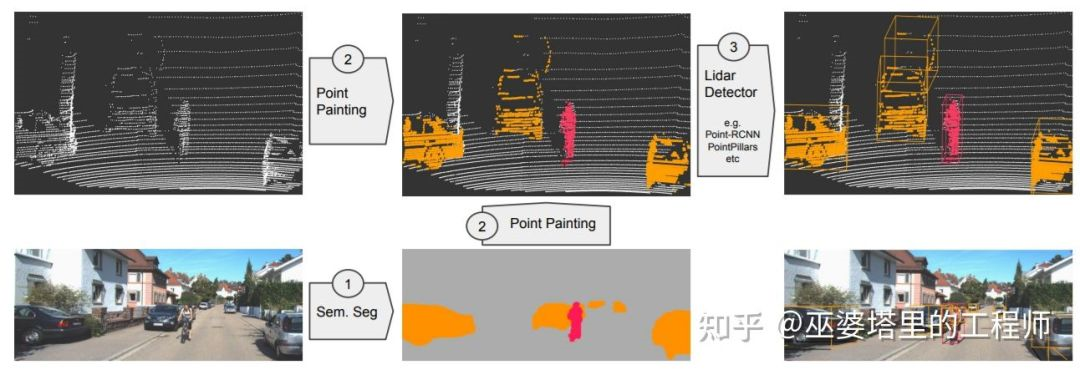
What PointPainting attaches to the point cloud is the semantic information of 2D images, which is already highly abstracted information, while the original image features are discarded. From the perspective of fusion, fusing lower-level features can preserve information to a greater extent and utilize the complementarity between different features, which theoretically increases the possibility of improving fusion performance. MVX-Net [9] uses a pre-trained 2D convolution network to extract image features and then attaches them to every point through the mapping relationship between the point cloud and the image. Afterwards, VoxelNet is used to process the fused point features. In addition to this point fusion strategy, MVX-Net also proposes to fuse at the voxel level. The main difference is that voxels, rather than points, are projected onto the image space, so that the image features are attached to the voxels. From experimental results, point fusion yields slightly better results than voxel fusion, which further suggests that lower fusion levels may lead to better performance.
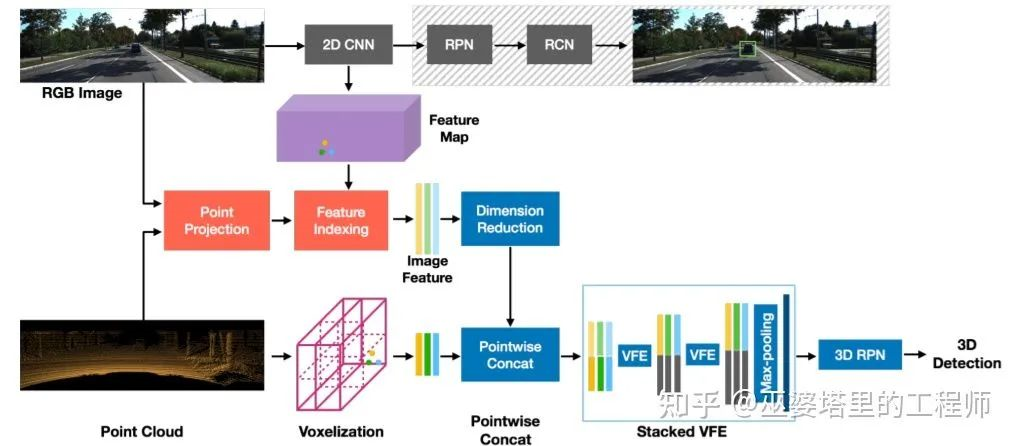 Fusion in semantic segmentation tasks is generally performed at the feature layer. The feature fusion methods introduced before can theoretically be used for semantic segmentation. For example, ContFuse fuses image and point cloud features on BEV grids, which can be used for grid-level semantic segmentation. PointPainting attaches image features to point clouds, enabling any algorithm based on point cloud semantic segmentation to classify each point semantically, and even perform instance segmentation and panoramic segmentation.
Fusion in semantic segmentation tasks is generally performed at the feature layer. The feature fusion methods introduced before can theoretically be used for semantic segmentation. For example, ContFuse fuses image and point cloud features on BEV grids, which can be used for grid-level semantic segmentation. PointPainting attaches image features to point clouds, enabling any algorithm based on point cloud semantic segmentation to classify each point semantically, and even perform instance segmentation and panoramic segmentation.
Results Comparison
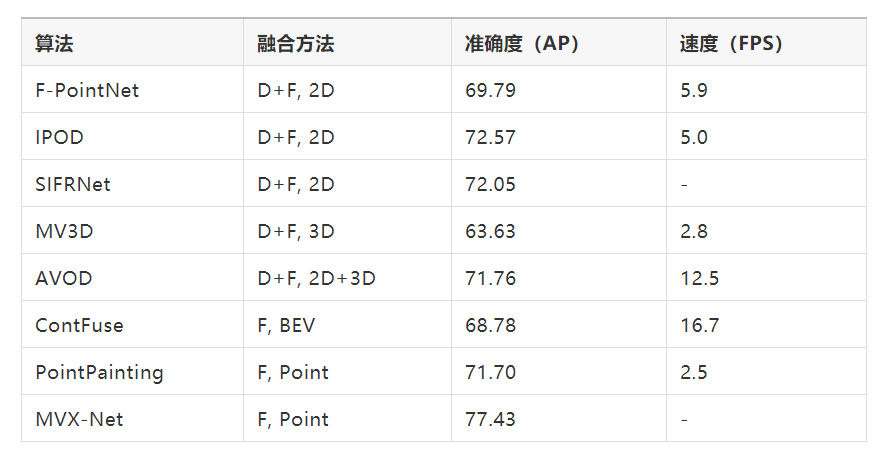
Here, we summarize and quantitatively compare the various fusion methods introduced earlier. The accuracy indicator adopts AP (70% IoU) for 3D vehicle detection in the KITTI dataset, and the speed indicator adopts FPS (due to different hardware, they are not completely comparable). The D+F column in the fusion method section represents decision+feature layer fusion, and the 2D/3D column next represents whether object candidates are extracted from 2D images or 3D point clouds. F represents feature layer fusion, and the BEV and Point columns next represent the fusion positions. Overall, feature layer fusion works better, and fusion based on Point is better than fusion based on BEV.
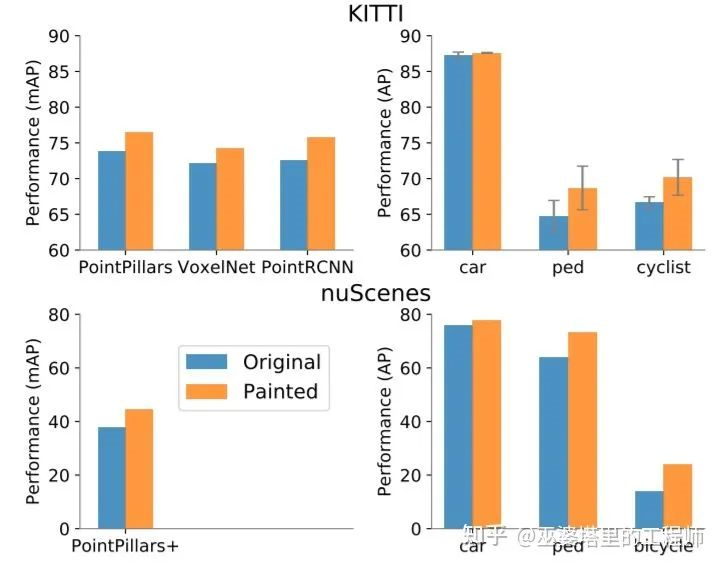
As a comparison, VoxelNet based solely on point cloud data has an AP of 64.17. MVX-Net attaches image features to point clouds and then uses VoxelNet, boosting the AP to 77.43, which is a considerable improvement. Comparative experiments in PointPainting have also shown similar improvements. The following figures show comparison experiments conducted on KITTI and NuScenes respectively. PointPillar, VoxelNet, and PointRCNN, which are commonly used methods for point cloud object detection, have shown significant improvements after combining image features. Especially for pedestrians and cyclists, the improvement is even greater, which proves that high-resolution image features are helpful for detecting small targets.
References
[1] Cui et.al., Deep Learning for Image and Point Cloud Fusion in Autonomous Driving: A Review, 2020.- [2] Qi et.al., Frustum Pointnets for 3d Object Detection from RGB-D Data, 2018.
- [3] Yang et.al., IPOD: Intensive Point-based Object Detector for Point Cloud, 2018.
- [4] Zhao et.al., 3D Object Detection Using Scale Invariant and Feature Re-weighting Networks, 2019.
- [5] Chen et.al., Multi-View 3D Object Detection Network for Autonomous Driving, 2016.
- [6] Ku et.al., Joint 3D Proposal Generation and Object Detection from View Aggregation, 2017.
- [7] Liang et.al., Deep Continuous Fusion for Multi-Sensor 3D Object Detection, 2018.
- [8] Vora et.al., PointPainting: Sequential Fusion for 3D Object Detection, 2019.
- [9] Sindagi et.al., MVX-Net: Multimodal VoxelNet for 3D Object Detection, 2019.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.