
How Tesla Builds Neural Networks
In his past three years of speeches, Andrej Kaparthy, Tesla’s Director of Artificial Intelligence, has demonstrated how Tesla applies AI to its Autopilot system. From his presentations, we can learn how Tesla builds its neural network architecture.
Tesla’s core perception technology uses cameras instead of lidar, high-precision maps, or even millimeter-wave radar. Therefore, all features of Autopilot rely on computer vision calculations based on raw images from eight cameras around the car. These features include autonomous driving, active safety (e.g. detecting pedestrians when the autonomous driving mode is off), and automatic parking (searching for parking lots).

Tesla uses eight cameras to sense information around the car, covering every area without any blind spots.

Eight cameras fused together can effectively locate and identify obstacles. However, according to the recurrent neural network architecture with 16 time steps and a batch size of 32, for each forward propagation, 4,096 images need to be processed. A MacBook Pro cannot handle such a huge amount of image processing, and two GPUs cannot accomplish it either.
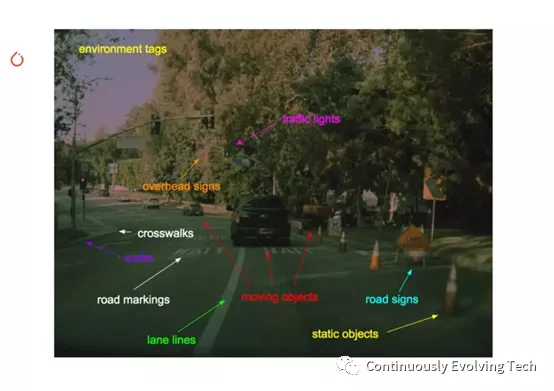
Although neural networks can theoretically perform object detection from images collected by cameras, ensuring safe driving requires detecting many objects around the car, such as lane lines, static objects, road signs, and crosswalks. As a result, Autopilot needs to perform multiple tasks at the same time, facing the challenge of parallel processing of dozens of tasks at any given moment. According to Karpathy, there are “almost 100 tasks.”
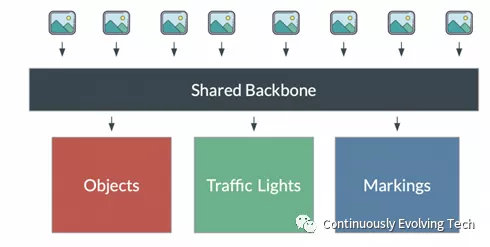
Tesla’s Hydra NetsKarpathy mentioned that due to the large number of tasks to be processed, it is impossible for every task to have its own neural network operation. Instead, some operations need to be shared among a backbone network. Therefore, Tesla AI team constructed a large object detection network called “Hydra Nets” (Hydra representing a nine-headed monster). Of course, in order to continuously improve the performance of HydraNet, massive data is required for training.
HydraNet has a shared backbone and multiple “heads,” with each head responsible for multiple tasks. For each detection task, it may have multiple sub-tasks, and if they are all listed, the number can even reach thousands. As shown in the figure below, eight images use the shared backbone for synchronization and fusion.
The advantage of HydraNet is that it can fine-tune the neural network for specific use cases (such as pedestrian detection) without disrupting other tasks (such as lane recognition), and the overall architecture can achieve more efficient inference.
Evolution of Hydranet
At the CVPR 2021 Autonomous Driving Workshop held in July of this year, Karpathy detailed how Tesla developed a deep learning system that only requires video input to understand the environment around the car. He mentioned that Hydranet has been extended in the past year or so, with the branches of the head that have now become the backbone further branching out to terminals.
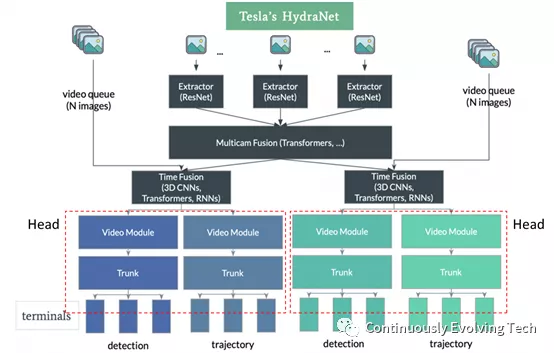
Referring to the figure above, the overall algorithmic framework is as follows:
-
First, the eight camera images are processed by an image extractor to extract features, using an architecture similar to ResNet.
-
Multicam fusion: It can be understood as spatial fusion, which combines all eight images into one super image. For this, Hydra uses an architecture similar to Transformer, which is an incremental information that Karpathy shared at the conference and will be further explained in the following context.- Time fusion: adding a time dimension to merge images together. If there is a video sequence containing N frames, for example, and they wish to merge them in 2 seconds, assuming the camera works at 36 frames per second, then N would be 72. Time fusion is achieved using 3D CNN, RNN, and/or Transformer.
-
Output split into different Heads: each Head is responsible for a specific use case and can be fine-tuned separately. Previously, Hydra’s Heads were relatively simple, but now they have been expanded to include both stems and terminals, which provide a deeper and more specific understanding of use case types. Each terminal can handle its own task, such as pedestrian detection or traffic light recognition.
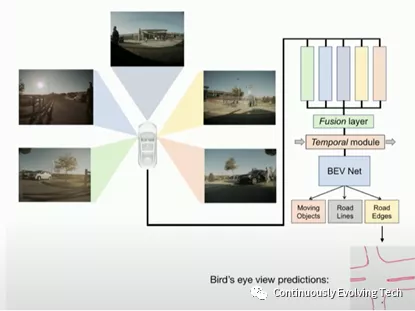
Finally, Hydra outputs the Birdeye View, which converts 3D space into a 2D top-down view that shows segmentation results for road edges, barriers, and passable areas.
Transformer: Leaving Convolution Behind
As mentioned earlier, at the 2021 CVPR conference, Karpathy added Transformer to Hydranet. Here is more information about it:
Transformer was introduced in 2017 as a simple and scalable model that achieves SOTA results in language translation. They were quickly applied to other NLP tasks and achieved state-of-the-art results, with larger models producing even more accurate outcomes.
In the computer vision (CV) field, CNN has been the dominant model for visual tasks since 2012. As more efficient structures emerge, CV and natural language processing (NLP) are converging. The use of Transformer to complete visual tasks is a new research direction that aims to reduce structural complexity and explore scalability and training efficiency.
There are mainly two types of transformer architectures used in computer vision: pure Transformer and hybrid structures that combine CNNs/backbones with Transformers.
- Pure Transformer: Vision Transformer is a Transformer structure based solely on self-attention, without using CNNs, and is the focus of our discussion.- Mixed type (CNNs + Transformer): DETR is an example of a mixed model structure that combines convolutional neural networks (CNNs) and Transformers. CNNs are used to learn the two-dimensional representation of images and extract features.
Vision Transformer (ViT) directly applies the pure Transformer architecture to a series of image blocks for classification tasks, obtaining excellent results. It also outperforms state-of-the-art convolutional networks on many image classification tasks, while significantly reducing the required pretraining computing resources (at least 4 times less).
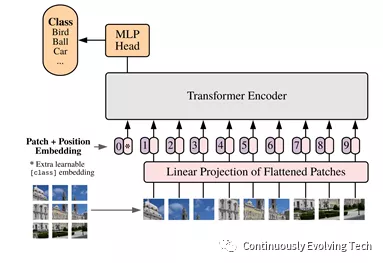
The main idea of the ViT is to divide the image into fixed small blocks, forming image sequence patches, and then input the linear projection of these small blocks together with their image position into the Transformer, and the remaining steps are standard Transformer encoders and decoders.
ViT (vision transformer) also has different model sizes, including base, large, and huge, as well as different numbers of transformer layers and heads. For example, ViT-L/16 can be interpreted as a large (24-layer) ViT model with a 16 × 16 input image patch size.
The smaller the input patch size, the larger the computing model, because the number of input patches is N = HW/P*P, where (H, W) is the resolution of the original image and P is the resolution of the patch image. This means that a 14 x 14 patch is more expensive to compute than a 16 x 16 image patch, as shown in the following result comparison table:
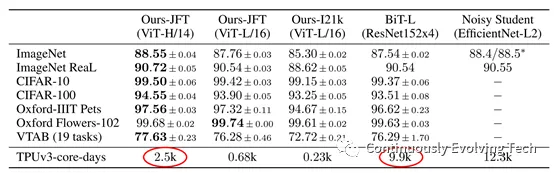
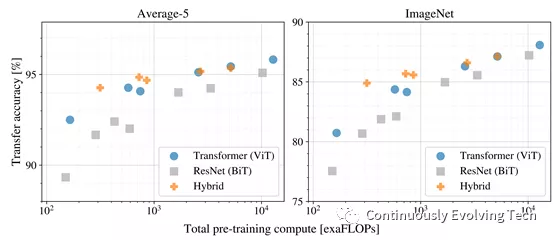
The above Benchmark results for image classification show that Transformer outperforms the existing SOTA models on multiple popular benchmark datasets.The performance and cost of ViT were compared with different architectures of ResNets and Hybrids, and ViT usually outperformed ResNet with the same computational budget. For smaller model sizes, the improved hybrids slightly surpassed ViT, but for larger models, the gap disappears and ViT leads again. Overall, the pure Transformer architecture (ViT) is more efficient and scalable in terms of size and computational scale than traditional CNNs (ResNet BiT).
The characteristics of ViT can be summarized as follows:
-
Using Transformer architecture (pure or hybrid)
-
Input images are tiled into multiple patches
-
Outperformed SOTA on multiple image recognition benchmarks
-
Cheaper pre-training on large datasets
-
More scalable and computationally efficient
Due to the advantages of Transformer, the Tesla Autopilot team has shown a strong interest in it and started to apply it in their networks, and “Upgrade All NNs” mentioned by Elon Musk on Twitter may also refer to the application of Transformer.
Data Engine: Tesla’s Powerful Advantage
The Real World is Complex and Diverse
Fully autonomous driving requires a series of tasks to be detected, including accurately and reliably detecting roads and road markings, determining the position of the vehicle on the road, detecting traffic signs, and detecting other vehicles, pedestrians, and any other objects on the road.
Taking the detection of speed limit and parking signs as an example, if you come from a machine learning background, the first intuition might be that modern deep neural networks should be able to handle the challenge easily, as traffic signs are rigid flat objects with convex, hole-free, standard shapes and designed for high contrast and easy recognition, which seems to be one of the easiest object detection tasks to solve. But reality is much more difficult than usual. Two main challenges are:
-
The classification of traffic signs is extensive and constantly evolving, with each country/region adopting different additional content for traffic signs, and the classification method is not fixed as new changes arise over time while old ones are discarded.
-
Even with the knowledge and maintenance of classification methods, the appearance of traffic signs can differ by a large margin due to occlusion, lighting, and specialized situations when road maintenance companies install these signs.

Even a seemingly standard road sign can be so complex. Considering that there will always be scenarios that have never been encountered before on the road, the situation is extremely complicated. In April 2019, during Autonomy Day, Tesla summarized the long tail of road scenarios:

Operation Vacation: Tesla’s AI Method
Neural networks used for applications such as autonomous driving are developed by training machine learning models. The performance of a deep learning system is usually limited, at least in part, by the quality of the training set used to train the model. In many cases, a lot of resources are invested in collecting, organizing, and annotating training data. The workload required to create the training set can be large and often tedious. In addition, it is usually difficult to collect data for specific use cases that the machine learning model needs to improve.
Tesla has the ability to iteratively get real-time data from a fleet of millions of cars. However, even with a Shadow Model, the amount of data is still very large, and there are only about a few dozen core algorithm engineers at Tesla. How do they deal with such a large amount of data?
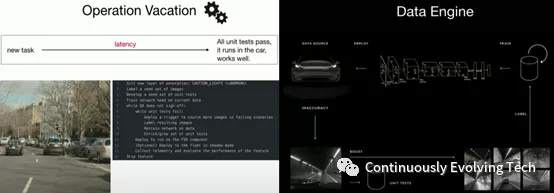
Operation Vacation: Karpathy drives his engineering team to focus on building a general AI infrastructure, trying to develop as many automated machines as possible to support the development of new tasks, effectively collect data, tag data, train, and reliably test models so that models can be updated to detect new objects and managed by separate production and tagging teams. This allows Tesla’s AI team to remain agile and efficient – and jokingly said that sometimes the team may take a vacation, and the system can self-improve without any engineers.The core of Operation Vacation is the Data Engine: the goal of the data engine is to ensure the most efficient way to collect data, which is the process of repeatedly applying active learning to obtain additional examples in the case of detector behavior mismatch. For example, in the task of detecting caution lights, the seed set of the image must be marked first to have a seed set with unit testing. Then the network Head is trained on the current data, and if it fails on the testing set, they will initiate the data engine to acquire more data to improve accuracy. A similar trigger will be trained offline and pushed to Tesla’s millions of vehicles on the road to obtain more images in the failure scenario. These harvested images are then labeled and input into the training set. The network is trained again, and the testing set is also enriched. These processes are iterative, and the accuracy can be increased from 40% to 99%. The data engine helps to accumulate large datasets in the long-tail distribution, covering the extreme long-tail required for reliable execution of models in the real unconstrained world. The core principle of the data engine is simple, with the main steps being:
a) Tag the initial dataset with the new object class;
b) Train the model to detect new objects;
c) Evaluate the effect;
d) Look for cases of poor performance;
e) Add these to data unit testing;
f) Deploy the model under a shadow model to the fleet to obtain similar edge cases;
g) Retrieve examples from the fleet;
h) View and label the collected data;
i) Retrain the model;
j) Repeat steps f-i until the model performance is acceptable.
However, nothing is too perfect, and Karpathy acknowledges in his speech that there is no method that can work perfectly: flicker detection in models, Bayesian perspective of neural network uncertainty, sudden appearance of detection, and differences between given map information and expected detection.
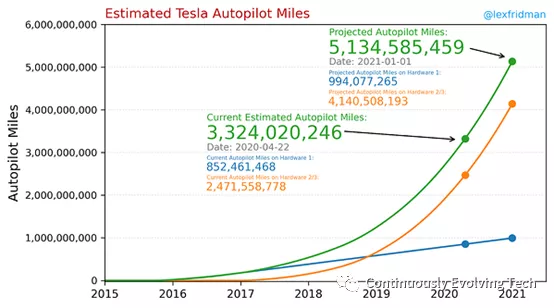
The core principle of the data engine is not unique to Tesla: it is inspired by active learning, which has been a popular research topic for years. Tesla’s competitive advantage is an unparalleled data collection scale. This is Lex Fridman’s estimate of Tesla Autopilot mileage, which shows that Tesla has collected over three billion miles in Autopilot, at least 100 times more than Google Waymo currently leads.
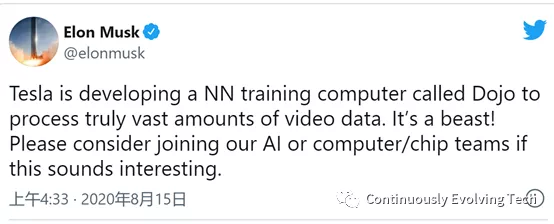
Training of Neural Networks: Expecting the Power of DojoIt is extremely difficult for anyone to train such a massive multi-task model like Tesla, which has 48 networks and over 1000 perception outputs. Running one round of training requires 70,000 GPU hours, totaling nearly 8 years. In addition, the model training process requires multiple iterations, tuning, and other processes. In order to improve training efficiency, Tesla developed its own Dojo Computer dedicated to training. Musk once said on Twitter that Tesla is developing a neural network training computer called Dojo to process truly massive video data, which is a beast.
We haven’t seen much public information from Tesla on how Dojo trains neural network models so far. However, it is certain that the network training is done using the PyTorch framework (PyTorch is very mature, search for it if you don’t know). The chip used by Dojo is undoubtedly an AI chip, replacing the original GPU. The picture released on the AI Day invitation that Musk calls the Dojo supercomputer’s self-developed chip should be the one.

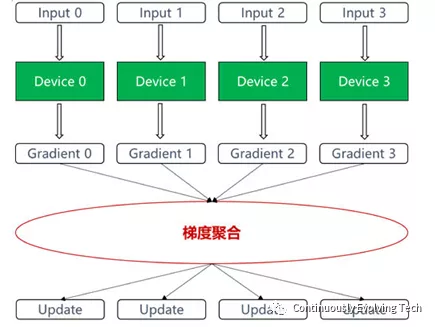
Regarding the training framework of Dojo, we refer to Huawei’s training guide for using the Shengteng AI chip with the PyTorch framework. In a large-scale AI training cluster, data parallelism is used to complete the training. Data parallelism means that each device uses the same model and different training samples. The gradient data calculated by each device need to be aggregated and updated after parameter updating.
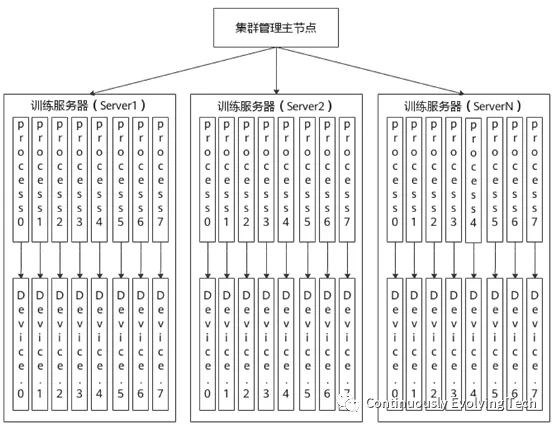
 Tesla currently uses a large training cluster consisting of thousands of GPUs, which is a typical cluster network configuration for servers. The training server cluster is composed of a cluster management master node and a group of training servers, and the maximum supported limit for Huawei Servers is 128, each of which contains 8 Ascend AI processors, forming a powerful server cluster. The cluster management master node supports the management of the cluster and devices within the cluster, and also supports distributed job management within the entire cluster. Training jobs are distributed to the training servers by the cluster management master node, and the job agents on the servers start the corresponding number of training processes according to the device quantity specified by the app, with one process corresponding to one AI processor.
Tesla currently uses a large training cluster consisting of thousands of GPUs, which is a typical cluster network configuration for servers. The training server cluster is composed of a cluster management master node and a group of training servers, and the maximum supported limit for Huawei Servers is 128, each of which contains 8 Ascend AI processors, forming a powerful server cluster. The cluster management master node supports the management of the cluster and devices within the cluster, and also supports distributed job management within the entire cluster. Training jobs are distributed to the training servers by the cluster management master node, and the job agents on the servers start the corresponding number of training processes according to the device quantity specified by the app, with one process corresponding to one AI processor.
For Tesla, the “Dojo chip” has already demonstrated significant innovation in encapsulation technology, and its powerful computing power is just the tip of the iceberg. We look forward to Tesla sharing more details on how it makes the Dojo chip unleash its “beastly” power.

🔗Source: Continuously Evolving Tech
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.