

On October 23, 2020, the second day of the small-scale push of FSD Beta software, Tesla owner Kim Paquette uploaded a video on Twitter. In the video, her Model 3 passed through a roundabout under unmanned takeover, including a decently handled parking yield, and happily patted the Model 3’s steering wheel after smoothly passing through the scene.
In another video, netizen Brandonee916 uploaded the brand-new visualized UI to the network. The colorful developer form UI displays the intersection environment in full view. Netizens in the comments couldn’t help but exclaim that the perception range of the new software has been greatly improved.
On the evening of the 22nd, a Model X user and his good mate witnessed their car complete its first smooth unprotected left turn at an intersection. After the vehicle passed through the unmarked area of the intersection and accurately entered the left turn lane, the two celebrated by high-fiving each other in the car.
The long-awaited street driving function suddenly “succeeded at one stroke” on FSD Beta, and for a time, an atmosphere of excitement and excitement spread among Tesla users and fan groups with more and more demonstrations of FSD beta videos.The excitement is not only due to the outstanding performance of FSD Beta street driving function, but also because people feel that the “Full Self-Driving” under the meaning of FSD name seems to be really coming.
Behind this is the largest update in the history of FSD, or more precisely, “Rewrite”.
Prelude since 2016
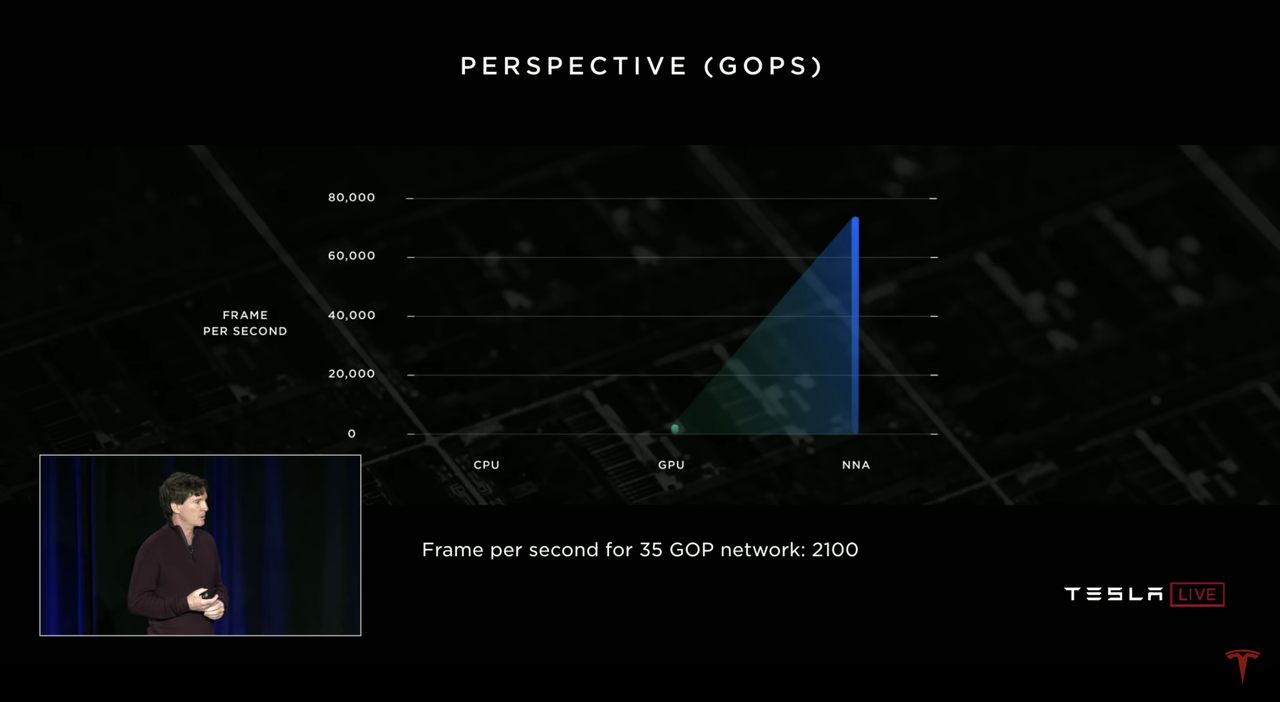
On April 22, 2019, Tesla announced its own HW 3.0 autonomous driving chip at the autonomous driving day, and the most dazzling hardware parameter is the 72 TOPS computing power brought by two neural network chips.

The hardware introduction mentioned that under the acceleration operation of the neural network, the image processing capability of this HW 3.0 chip is 2,100 FPS. In comparison, the GPU with floating-point operation capacity of 600 GFLOPS can only achieve 17 FPS. The image processing advantage of the neural network is obvious.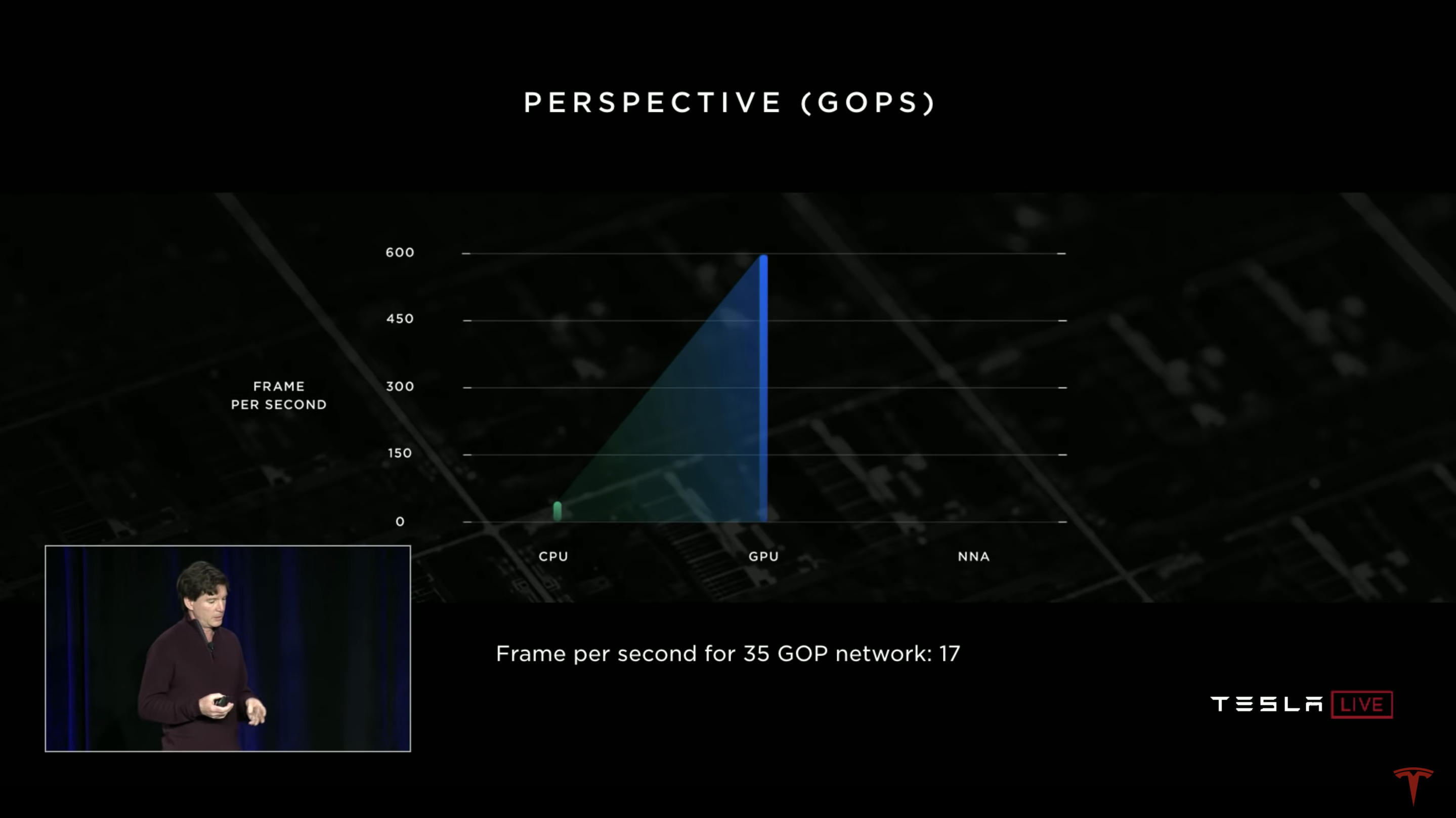
In order to create the strongest self-driving chip in the industry, Tesla has invited several master-level professionals during the research and development preparation stage.
HW 3.0, the industry’s first car-grade self-driving chip designed for neural network operations, was launched in 2016. That year, Tesla welcomed Pete Bannon, a former Apple chip architect who had been working in the semiconductor industry for 40 years and was the key researcher who led the development of the first 64-bit architecture mobile processor for the iPhone 5S. In 2015, legendary chip architect Jim Keller also left Nvidia to join Tesla.
Under the leadership of these masters and the joint efforts of Tesla’s elite team, the HW 3.0 self-developed chip project only took 3 years from recruiting personnel to researching and developing the chip, to large-scale production and installation on vehicles, and to this day, the HW 3.0 chip still has the highest computing power among car-grade self-driving chips on the market.But the FSD feature did not experience a significant improvement after the HW 3.0 chip was introduced in 2019. However, as indicated in the HW 3.0 release conference, this is due to the fact that the chip was designed specifically for neural network creation. It was not until the introduction of the rewritten FSD Beta software that the FSD function was transformed from its original structure to a neural network structure.
This rewrite is of great significance to the FSD function, as the new software, with the help of neural networks, significantly improves Tesla’s vision program. In fact, if you read through the entire article, you will realize that it is the modification of this software that made it possible for Full Self-Driving to become a reality.
For human, by human
At the 2019 Tesla Autonomy Day event, Tesla’s Director of AI, Andrej Karpathy, emphasized that “those of you who have driven here today in a car rely on the cooperation of vision and neural networks, not on laser beams emitted from your eyes to perceive the road.”
Also on that day, Elon Musk mentioned a real-world problem: “All the roads in the world are designed for human drivers.”The underlying meaning behind these statements is that “driving is a human behavior, and roads are designed for humans. If an autonomous driving system can possess the same perception and driving logic as humans, then it will be a universal solution for autonomous driving”. In a sense, Tesla has done just that.
“Vision is the best perception” according to Musk, who has publicly expressed disgust towards LIDAR-based perception systems for autonomous driving. He said, “with LIDAR, you can only know that there is something there, but you cannot know what it is, it’s like a cane for the blind”. He even doubts the value of LIDAR in the field of autonomous driving, stating that it is “expensive and unnecessary”, analogous to buying a RED camera for monitoring. “They’re all gonna dump LIDAR, mark my words,” is what he said at the Autonomous Driving Day.
As a company with the most advanced and aggressive configuration for visual perception systems, all current Tesla models for sale are equipped with eight cameras in six directions. Musk believes that “vision is the most information-dense and volumetric way to perceive driving. Many pieces of information such as lights, colors, two-dimensional patterns, object types etc., are all included in the perception of vision”. Humans rely on vision to complete driving tasks.Although this is the case, almost all of the professional players in the Robotaxi industry are using LIDAR solutions. The capabilities demonstrated by FSD prior to the update cannot support Musk’s “vision is king” rhetoric.
So, was Musk’s vision incorrect?
At this point, I do not believe so. This is because Tesla’s ability to perceive vision in the previous version of FSD was still far from Musk’s vision, or rather, far from the level perceived by human eyes. The vision-based approach is convincing, but Tesla’s exploration is not complete.
In fact, this seems to be proven by the fact that FSD Beta has demonstrated amazing progress in visual perception without any hardware upgrades.
However, what happened behind the scenes?
Dimensionality Expansion Vision in Neural Networks
At the ScaledML2020 conference in February this year, Tesla’s senior director of AI, Andrej Karpathy, spent 30 minutes using his usual lightning-fast pace to introduce Tesla’s autonomous driving content. The third chapter is called “Bird’s Eye View Networks”.
Previously, Tesla’s visual recognition prediction was done like this:Firstly, 2D images of the road environment are captured by the vehicle’s cameras, and then these images are sent to the feature extraction section, namely “Backbone”. Then, features are recognized and distinguished in the 2D pixel space, which helps to predict the road environment.
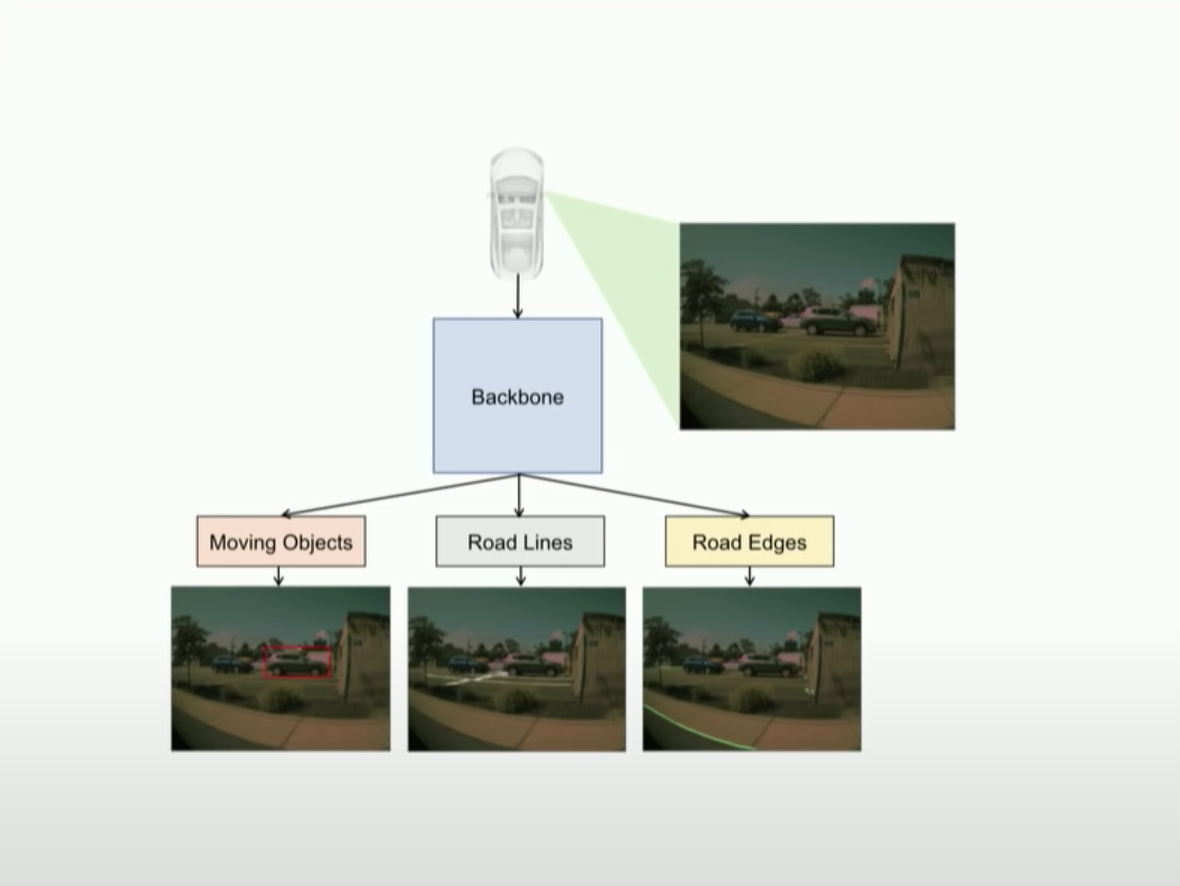
For example, road shoulder detection has the following actual effect:

“You just can’t drive on this raw prediction of these edges and these 2D pixel coordinate systems,” said Andrej. These rough road shoulder images and 2D pixel coordinate systems alone cannot be used as driving references.
Therefore, Tesla developed the “Bird’s Eye View” based on this foundation.
Still relying on cameras, capturing 2D images. However, this time Tesla uses 5 cameras from different directions, and “project them out to 3D” from the captured 2D images. These simulated 3D materials are merged in a “Occupancy Tracker” (physical modeler?), and then are projected from top to bottom onto the Z+ plane, just like a bird’s-eye view.
On one hand, this data will be displayed in a visualized form on the central console UI, and on the other hand, this environmental modeling data will also serve as a reference for driving decisions.
“It sounds like there’s nothing to the “merging” of different cameras, but in reality, it is not.” Andrej said that the perspectives of different cameras are different, and the contours of the same features in different frames are not consistent. The merging process needs to match and align various features. At the same time, the time axis of materials from different perspectives needs to be matched well. And while the vehicle is driving, the environment constructed in the “past” needs to be continuously merged with the environment constructed in the “present”.
3D + time axis, this is what Musk called “4D vision” on the day of autonomous driving.Andrej expressed that in the process of writing the “Occupancy Tracker” code, a large number of machine learning network hyperparameters need to be set for the splicing part, and there are a lot of error-prone codes, which makes his work extremely complex and difficult.
Therefore, the software team hopes to use another way to replace the “Occupancy Tracker” to perform environment modeling for detection.
Software 2.0
The Autopilot software stack consists of 1.0 code and 2.0 code, which are responsible for processing signals from various sensors, including cameras, millimeter-wave radar, ultrasonic radar, and IMU inertial measurement unit data. After the software processing, the raw sensor data is finally output as driving decisions such as acceleration and steering of the vehicle. You can simply think of the software as the brain of an autonomous driving system.
The 1.0 part is determined functional code created by human programmers using the C++ language, and the aforementioned “Occupancy Tracker” belongs to the 1.0 code. According to the official description, this part is all “dead code”.The 2.0 part is completely different. According to Andrej, the 2.0 part is like a compiler that can process input datasets and output neural network code. Moreover, you can run the code library of the 1.0 software under the code library of the 2.0 software. As the 2.0 software continues to “swallow” and absorb the 1.0 software, more and more “dead code” of the 1.0 software is gradually replaced by neural networks.
And the neural networks with deep learning capabilities can perform the tasks of the “dead code” of the original 1.0 software even better than before.
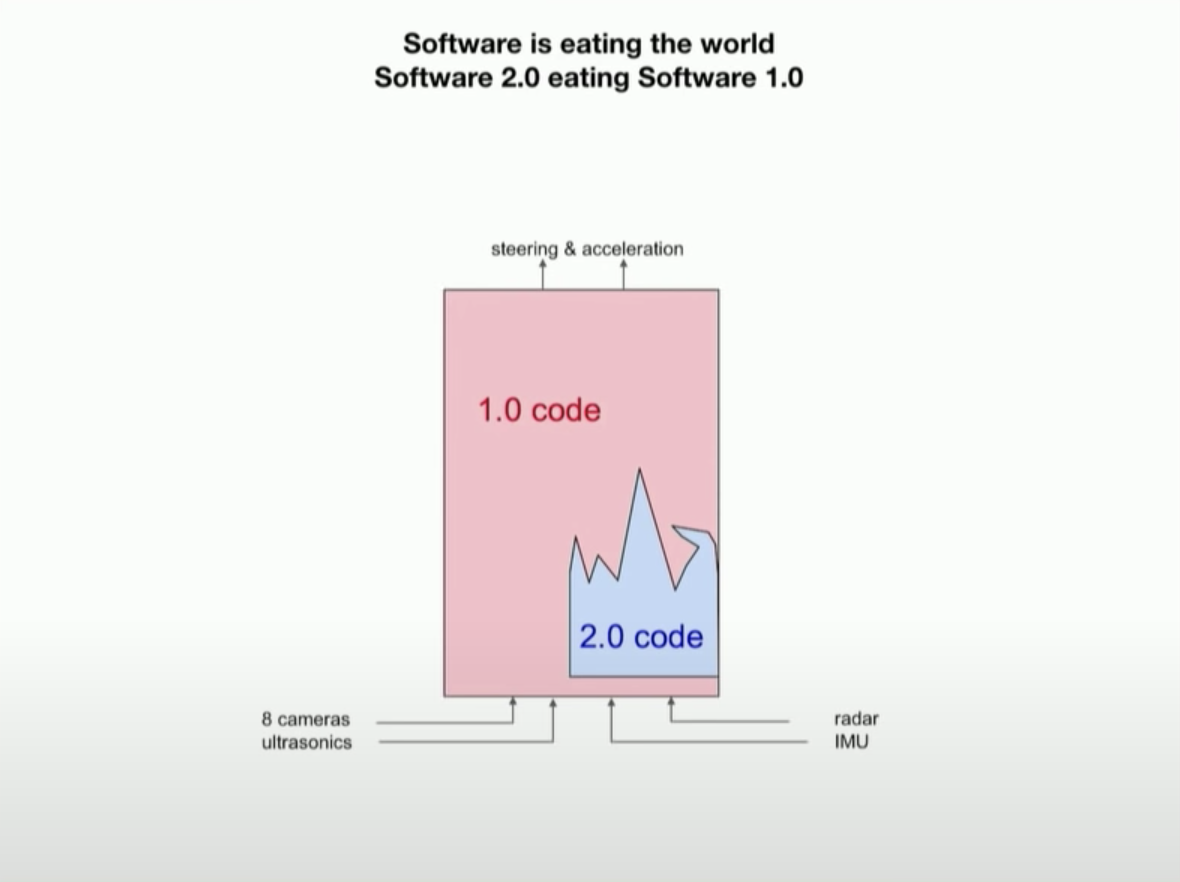
Taking 4D vision as an example, the perception of the neural network structure is already vastly improved.
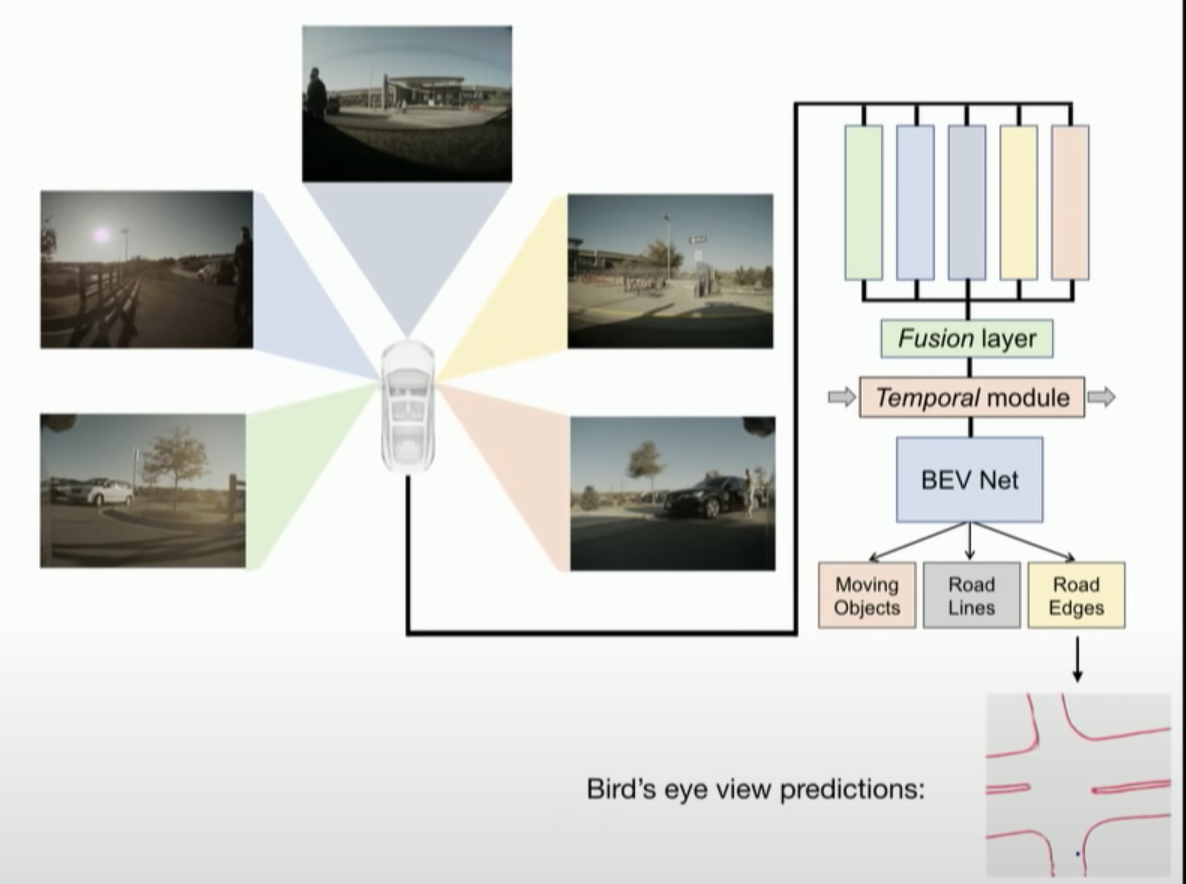 The system still utilizes images from 5 directions captured by cameras, and then the materials still need to go through the feature extraction part. However, unlike before, the 2D-to-4D environment stitching and modeling work is no longer done by “Occupancy Tracker”, but instead by a set of neural network fusion layers.
The system still utilizes images from 5 directions captured by cameras, and then the materials still need to go through the feature extraction part. However, unlike before, the 2D-to-4D environment stitching and modeling work is no longer done by “Occupancy Tracker”, but instead by a set of neural network fusion layers.
The fusion layers stitch the 2D images between cameras into 4D and transform them into a “bird’s eye view”, completing the rough modeling. Then it is further optimized into fine modeling through the “Temporal module” for smoothing.
The materials for fine modeling are decoded by the “BEV (Bird’s Eye View) Net” and constructed into the environment features for driving decision-making displayed on the central control.
As for road contour detection, the raw materials go through layers of processing to produce a Z+ downward projection of the road environment. Based on this projection, the environment prediction has achieved a noticeable improvement.

The above figure shows the different camera views captured by the Tesla vehicle at an intersection, and several road contour images from different sources are depicted in the lower part of the figure. The small blue dot in the figure represents the position of the vehicle.The Chinese Markdown text translated into English Markdown:
The image in the bottom left corner is the actual outline of the intersection, while the one on the bottom right is the intersection outline constructed under 2D vision. You can see that the surrounding environment contour of the vehicle is somewhat similar, but the prediction far away from the car is almost completely distorted. Using the term “high myopia” to describe it is not an overstatement.
Andrej bluntly stated that the environmental prediction data based on this kind of result is garbage with no value. Concerning this result, Andrej also pointed out the reason: “Depth of field recognition in 2D vision is pixel-based, and its accuracy coverage range is very small. The accuracy of the near-end is reasonable, but the pixels in regions farther away from the car, especially near the horizon in the picture, are calculated with a slight error, which may cause road prediction deviation of several meters. Implicitly, this is the “congenital disability” of 2D pixel depth recognition.
You should also be able to guess that the outline in the middle matches the actual intersection outline very closely, constructed by an improved 4D vision. From 2D to 4D, the key to curing myopia is in the middle, in the 3D.
Save the Day with Depth Curve Calculation
Earlier, it was mentioned that depth of field calculation was a weak point in 2D vision. The industry’s standard approach to this is to delegate depth calculations to other sensors, such as LIDAR, and then fuse the perception data.
Although Tesla has always been tough and refused to use LIDAR, they secretly created an “image version of LIDAR” solution in the FSD Beta.Tesla developers have a new idea: the previous depth estimation based on computer vision failed mainly due to “the expression form of data,” that is, the restriction of the 2D pixel coordinate system on the maximum capability of vision.
Their solution is to use imaging to “imitate” the LIDAR. The specific steps are as follows:
- 1. Measure the pixel depth from the camera image through the visual depth estimation method;
- 2. After obtaining the pixel depth, back project the 2D image into a 3D point cloud to obtain “Pseudo-Lidar” data;
- 3. Analyze the obtained Pseudo-Lidar data using the algorithm for LIDAR data to construct a new depth prediction.
This novel “imitating” approach helps Tesla produce 3D predictive effects like a LIDAR device without the hardware. The step of back projecting the pixel depth into a 3D point cloud is critical.The new approach offers a higher upper limit than before, but the degree to which the “class” can approach this limit still depends on the precision of the initial data, such as the pixel depth of field. It is the master data for all subsequent data and serves as the original benchmark for depth of field measurement.
At the 2019 Tesla Autonomy Day, Andrej briefly introduced how the Tesla team optimized this process through neural network self-learning.
The basic idea is that the neural network system generates continuous depth of field predictions for the entire frame in unmarked video footage, which are then continuously matched and compared frame by frame with the actual video footage. The basic prerequisite for achieving continuous matching is that the initial depth of field calculation of the original image is correct, or that the precision is OK.
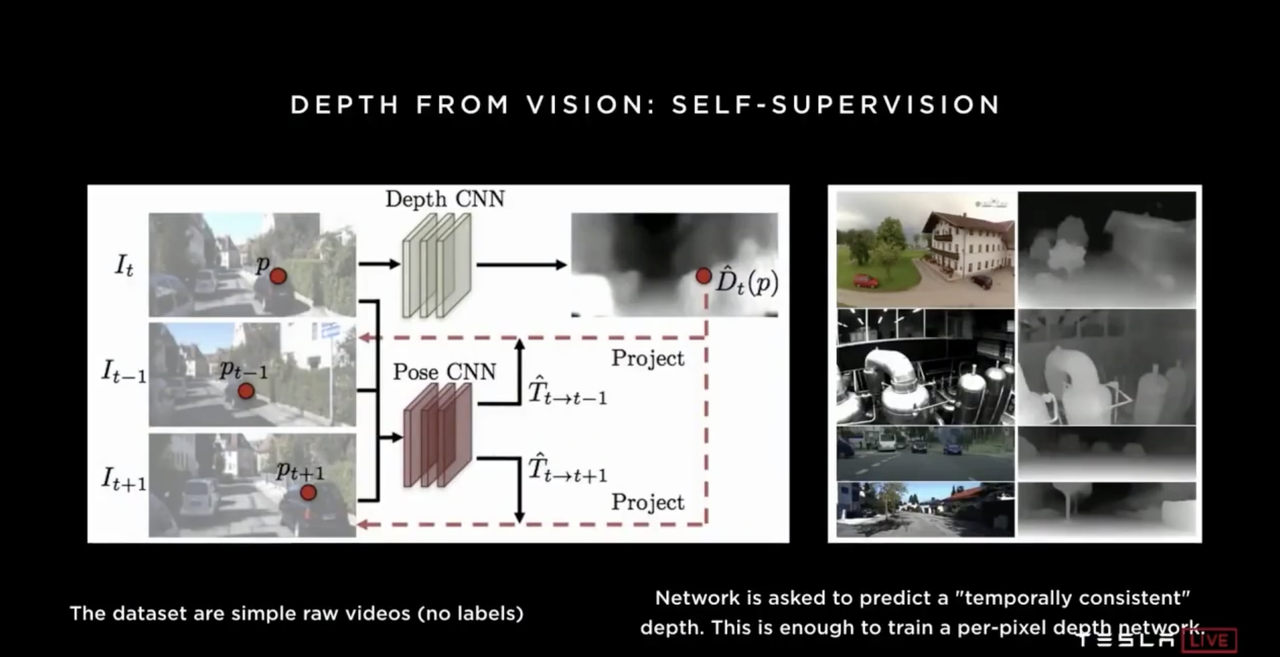



In validation, Tesla marks the position of objects measured by radar as points and the position of objects measured by vision as cubes. In the official demo materials, both methods have shown good matching for tracking.

Therefore, when faced with Tesla’s test vehicles equipped with lidar seen on the internet, don’t be so sure that Tesla has shifted to lidar technology. Perhaps they are testing the matching of the distance measurement between their pseudo-lidar vision solution and the actual lidar solution.
 Another interesting thing is a 2019 report by THE ROBOTREPORT, in which a research team at Cornell University proposed a plan to improve visual perception accuracy using pseudo-lidar, the idea of which is different from Tesla’s. However, after comparison and validation by these researchers, the visual plan with the pseudo-lidar method is very close to the real lidar in terms of position detection accuracy.
Another interesting thing is a 2019 report by THE ROBOTREPORT, in which a research team at Cornell University proposed a plan to improve visual perception accuracy using pseudo-lidar, the idea of which is different from Tesla’s. However, after comparison and validation by these researchers, the visual plan with the pseudo-lidar method is very close to the real lidar in terms of position detection accuracy.
In addition, the researchers mentioned in the interview that if environment materials can be analyzed under “Bird’s eye view” instead of relying solely on the front camera, the accuracy can be improved by more than three times.
With the same technical terminology, similar methods, and consistent conclusions, the relationship between this research team and Tesla is intriguing. However, what can be seen is that there are already people who have thought of it together with Tesla on the road of exploring visual solutions.
Even with the strongest brain, we still need to learn
Humans are naturally equipped with vision but not naturally able to drive, and the process from not being able to drive to being able to do so actually mainly increases two types of abilities in the brain:
- 1. Recognition and prediction of the road environment
- 2. Gradually familiarizing with driving logic
The logic of FSD, based on neural networks for learning to drive, is different from this.#### HW 3.0 Chip: Tesla’s Strongest Brain in Mass Production Vehicles
The HW 3.0 chip gives Tesla’s production vehicles the strongest brain, while 4D vision allows for better and more accurate perception. However, when it comes to perception, there must be both “sensation” and “knowledge”. Tesla’s neural network includes visual nerves as well as thinking nerves. Like humans, they also need to learn and accumulate cognition. The expectation for Autopilot FSD is to make it become a driver that can drive on all roads in the world, which means there are a lot of things FSD needs to learn.
“Perception and prediction of road environment” for computers, simply put, is visual image recognition and prediction, recognizing various features on the road, including but not limited to road lines, road signs, road space, static objects, and dynamic objects. Like humans, the neural networks recognize features through “accumulated experience”.
Two Terms You Need to Know
Before we talk about Tesla’s machine learning system, there are two things to introduce: “queue” and “shadow mode”.
 The “Queue” refers to Tesla’s own on-road vehicles associated with this system, with about 1 million in February this year. This number will continue to expand with the increase in deliveries.
The “Queue” refers to Tesla’s own on-road vehicles associated with this system, with about 1 million in February this year. This number will continue to expand with the increase in deliveries.
For the system, these vehicles distributed around the world are like intelligent terminals. The road data collected by the on-board cameras can be uploaded to the system (note: Tesla’s collected data is de-identified, and the system does not know which car the data comes from, which can protect users’ privacy).
In other words, through the “Queue”, the system can collect a large and diverse amount of road data.
The “shadow mode” is relatively special. In the “Queue” vehicles, there is actually a “clone brain” in addition to the main brain, which can also obtain various sensor data of the vehicle and output various predictions and driving decision instructions.
However, unlike the main brain of the vehicle, the neural network in the “clone brain” may be a test version of the system, and the predictions and instructions it makes will not be used for vehicle control. Therefore, even if the prediction and instructions of this test-version neural network are wrong, it doesn’t matter as the system does not execute them.System will record the actual accuracy of the predictions and instructions generated by the “shadow mode”, and use it to evaluate the effectiveness of the beta version neural network testing. For the high error rate predictions corresponding to certain road sections, the system will record the relevant materials for subsequent neural network training and testing.
Tesla has prepared a closed-loop system named DATA ENGINE for machine learning of neural networks, which has a clear structure and a very sophisticated mechanism.
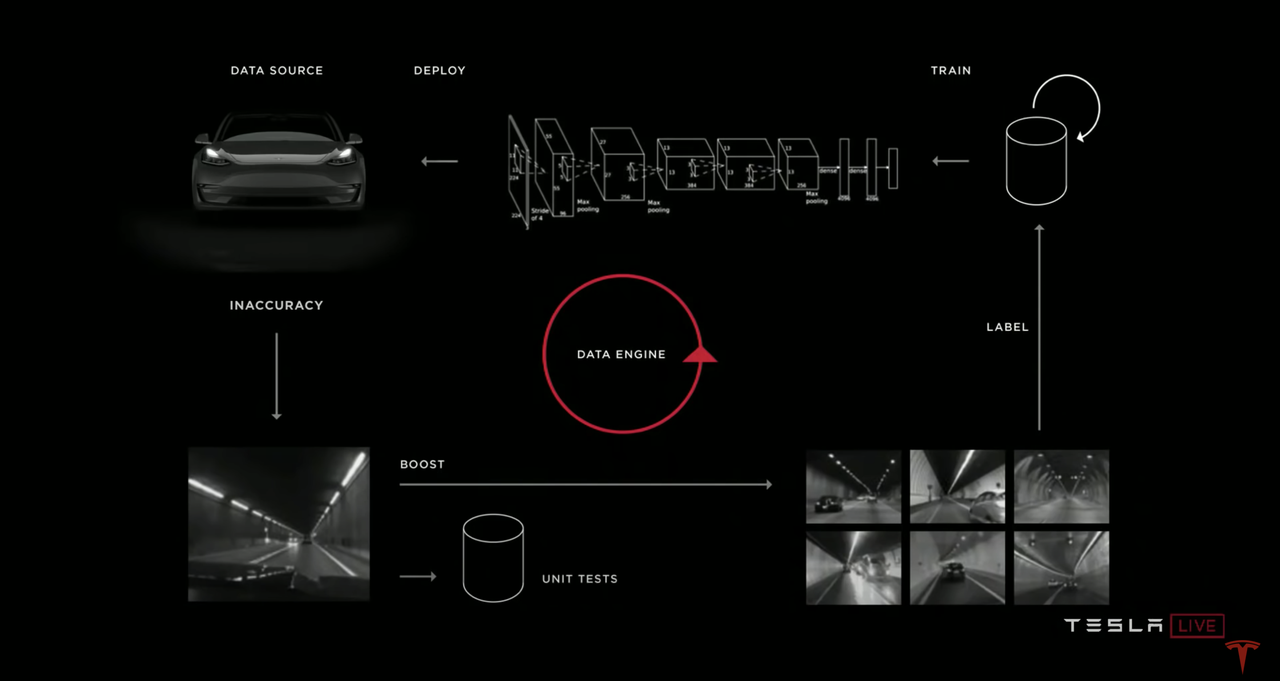
The system mainly operates like this: certain Autopilot materials that cannot be properly passed through the scenes are uploaded, some of which have high error rates in “shadow mode”, and I call this part of the material initial material.


After that, the system will not only add the initial materials into the “Unit Testing” material library, but also search the “Queue” for similar materials and request to return these materials, which can be called the Selection Materials. The number of selection materials is quite substantial, but their match with the initial materials is not very high. After screening and marking, the selection materials with high match degree will also be put into the “Unit Testing” material library. In this way, the system quickly collects a large number of “Unit Testing” materials for scenes similar to the source scene of the initial materials.
Then, Tesla will use the “Unit Testing” materials to carry out specialized offline training and testing for the neural networks. After being trained and passing the “Unit Testing”, the relevant neural networks will have stronger processing capabilities for the source scenes of the “Unit Testing” materials.
After passing the “Unit Testing”, the neural networks will be sent down to the “Queue” for verification in “Shadow Mode” by Tesla. For insufficient performance, the above process will continue to cycle.
Behind the process, there are data and training mechanisms, as one of the core functions of neural networks is image feature recognition. Therefore, many contents in the deep learning process of Tesla’s neural networks are related to this.Here is the English Markdown text with HTML tags retained:
To recognize the stop sign, the first step is to manually mark the stop sign in the material, so that the system can understand the pattern and identify the location of the red and white pixels as the stop sign.
Once this process is completed, the system can recognize the stop sign with a high degree of similarity to the image material.
However, in the real world, there are many complicated situations.


Taking stop signs as an example, there are many different styles of stop sign patterns, and they appear in various forms with many bizarre scenes, such as being covered, with lights, or with limited triggering conditions, etc.
Non-linearly Correlated “Broad-Mindedness”To enable the system to recognize these differentiated common features, there is only one way – collecting materials from these scenarios and using them to train neural networks.
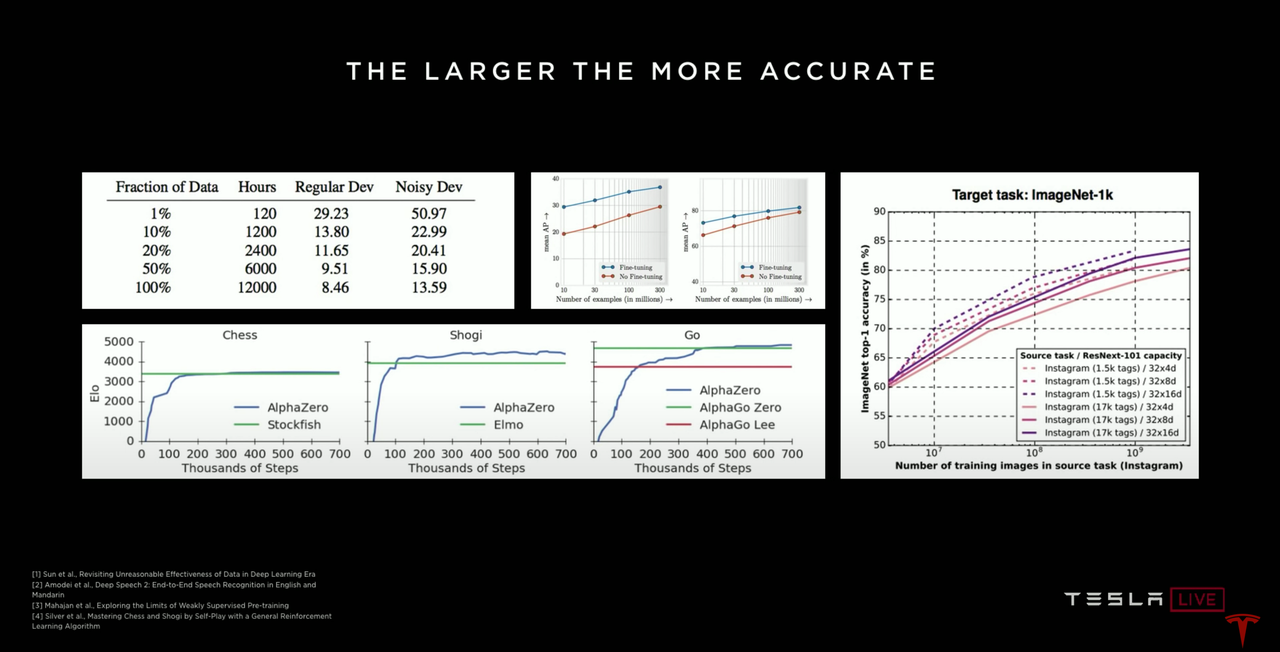
In short, the more materials you collect and the wider range of scenes they cover, the more versatile the trained neural network will be, and the more scenarios it can handle.
However, there is an issue that cannot be ignored during this process – the effectiveness of the data.
At the initial stage of neural network development, there are not many scenes for it to learn, so it is not difficult to find materials for “unit testing”. But as the neural network learns more scenes and gains more experience, it can recognize most scenarios, and therefore, much of the data collected at this time is repetitive and useless.
The neural network cannot learn new skills without being provided with “unit testing” materials that are different from before.
These rare and different scenarios are commonly known in the industry as corner cases.
 In the process of machine learning, the number of corner cases decreases as the learning progresses, or to put it another way, the amount of total data needed for neural networks to improve increases exponentially.
In the process of machine learning, the number of corner cases decreases as the learning progresses, or to put it another way, the amount of total data needed for neural networks to improve increases exponentially.
This is why “mileage” is crucial in all autonomous driving systems.
Tesla announced in April that they had collected driving data of 3 billion miles, whereas Waymo announced in January that they had only gathered 0.2 billion miles for comparison.
Not only manufacturing, automation is also necessary in other areas.
Tesla’s entire neural system is composed of 48 neural networks and 1,000 independent neural networks.
To train and test neural networks for identifying single features, Tesla has specifically established “unit tests”.
“Unit tests” were inspired by the testing-driven development process; it can be understood as a multi-scenario recognition test for neural networks.
Within this test, Tesla would provide a variety of scenarios and the neural network must achieve the corresponding accuracy in all aspects to pass the test.
 For the single scenario that did not pass the test, developers will continue to train the neural network on the materials of that scenario until its recognition accuracy meets the set requirements.
For the single scenario that did not pass the test, developers will continue to train the neural network on the materials of that scenario until its recognition accuracy meets the set requirements.
When the neural network passes all established tests, the neural network for this particular feature recognition has completed the process from creation to being pushable to the shadow mode.

However, as mentioned earlier, there are about 1,000 types of features that the system needs to recognize, and each one requires such “unit testing”, requiring 70,000 GPU hours of training.
Compared to some companies using a large workforce in this area, this training task is only handled by a team of dozens of elite members within Tesla.

Behind such training efficiency is a highly automated training mechanism.
For this reason, the Tesla AI team is working hard to build a modular “fast-training system” for training neural networks, which includes various types of initial templates for neural networks.If the new neural network being developed belongs to one of the major categories, simply select the corresponding template for customized matching to quickly generate the initial file.
From there, the “Fast Training System” relies on a data-based neural network learning cycle, which involves searching for training materials, marking features, collecting “unit test” materials, completing the “unit test” process, verifying and looping through shadow modes using as many automated mechanisms as possible.

Ultimately, Tesla hopes that developers will only need to call the template to create a new neural network unit, and the training process will be fully automated by the system under defined settings.
However, the amount of training for neural systems is still enormous.
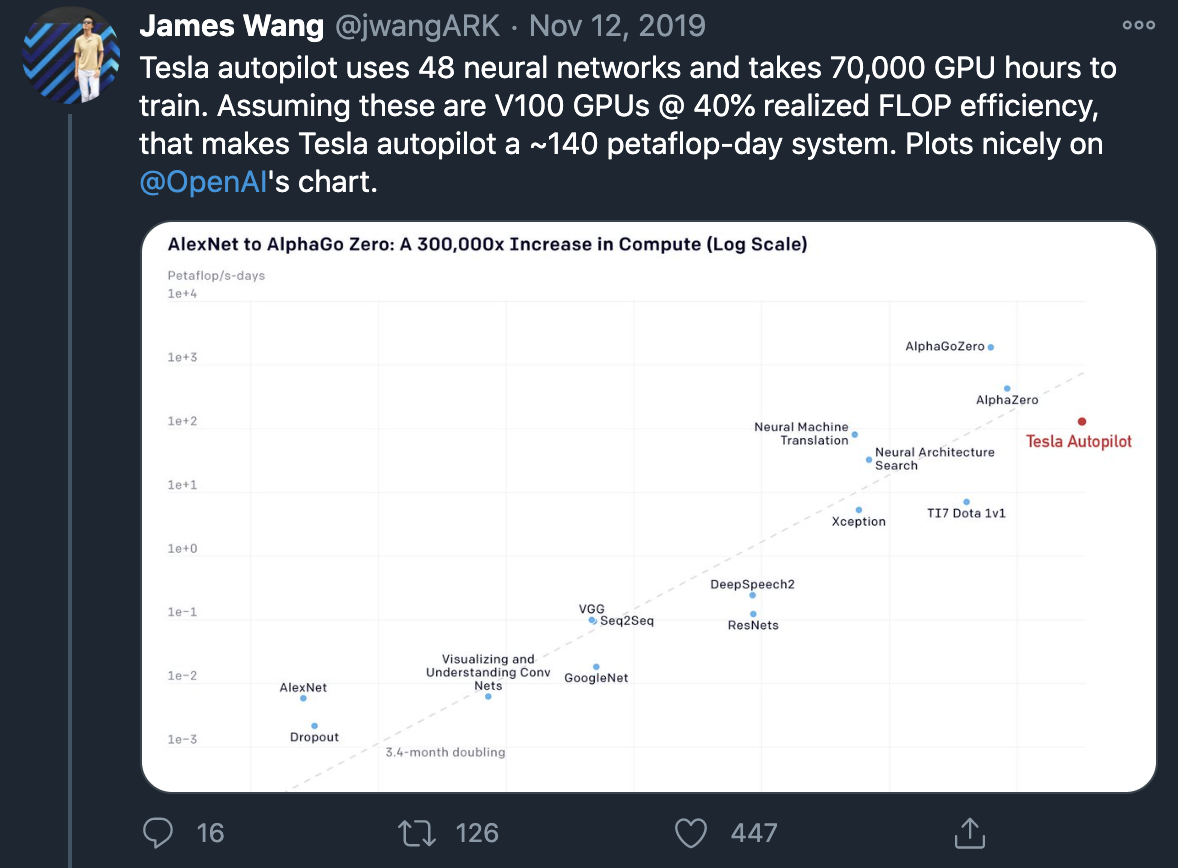
Twitter user James Wang conducted a rough calculation, estimating that if running at a speed of 140 petaFLOP/s using an NVIDIA V100 graphics card with a floating-point operation efficiency of 40%, the daily floating-point computing demand for Tesla would be met.
And to complete such calculations within three days would require over 1,000 V100 GPUs, with a cost of about $15 million for this system.
It can be seen that AI training is both time-consuming and expensive. In the face of this situation, Tesla has prepared dedicated hardware, an extremely powerful supercomputing system.
Dojo: The Ultimate Learning Machine
At the autonomous driving day, Musk revealed that Tesla is building a supercomputer for its own AI training, and plans to use it with related software to achieve automated unsupervised video-level AI machine learning training.
Musk stated that Dojo is not a cluster of GPUs. It will use Tesla’s self-developed chips and computing architecture specifically optimized for neural networks. This supercomputing system is expected to be unveiled next year.In August this year, Musk revealed that the floating-point computing power of Dojo is expected to reach the level of 1 exaFLOP/s. “Exa” is 10 to the power of 18, and currently no supercomputer system in the world has computing power that can reach 1 exaFLOP, with the closest being Japan’s Fugaku supercomputer with data corresponding to 442010 TFlop/s, which is 0.442 exaFLOP/s.
“If there is computing power of 1 exaFLOP/s, completing the neural system training mentioned earlier will take less than 4 hours.”

This may be a bit of an overkill for Tesla, and Musk also stated on Twitter in September that Tesla will launch a commercial server web service after Dojo is completed. This also means that Dojo will bring server business income to Tesla.
An automaker has made what may be the world’s most powerful supercomputer to train its own self-driving system. I thought I had already gotten used to all kinds of “stunts” by Tesla, but this time I was still shocked.Not only because supercomputers are things that only top technology fields like aerospace and aviation will use, but also the software behind it reflects the value of Tesla.
Tesla’s Game of Imitation
All the roads in the world are designed for human driving, and human driving relies on visual perception and accumulated driving experience.
Upon closer examination, human driving requires vision, optic nerves, brains, and driving thoughts, both “hardware” needs, as well as deep learning software needs.
Tesla equips cars with cameras, giving them eyes; Tesla develops neural chips, providing cars with powerful brains; FSD Beta brings 4D vision, enabling the optic nerves in the brain to see a multi-dimensional world; and Software 2.0 continues to learn and increase driving experience through the continuous loop of DATA ENGING.
In order to achieve autonomous driving on roads designed for humans, Tesla imitates the functional structure of humans, imitates their driving behavior, and even imitates their way of progression.
Yes, Tesla’s autonomous driving is actually a carefully planned game of imitation.
As a humanoid driving machine, Autopilot learns from humans as much as possible, and in some aspects, it is even better than its imitated prototype human, such as being able to track dozens of targets under a 360° field of view, having computational power and accuracy stronger than the human brain, and recording over 3 million miles of driving distance in a single day.The largest “queue”, the fastest expanding “queue”, the most material for driving, the fastest growing material for driving, the strongest self-driving chip, the strongest AI training computer, and the AI training system with probably the highest efficiency under this support, from a business competition perspective, there is no one ahead of Tesla.
As the “queue” grows, the positive and negative feedback system driven by the “queue” data that Tesla has built to crack the code of self-driving is running faster and faster, and perhaps this will make the figures behind it further away.
For Autopilot, we have witnessed its birth from 0 to 1, and also witnessed its progress from 1 to 10 and beyond.
No protection left turn, no lane driving, flexible obstacle avoidance, timely parking, timely crossing the line… After the FSD Rewrite, the ceiling has been raised to an unprecedented height, and even a glimpse of light has appeared in the L4 window in the room.
For Autopilot, we have witnessed its birth from 0 to 1, and also witnessed its progress from 1 to 10 and beyond.No protected left turn, no lane markings, flexible obstacle avoidance, timely parking, timely crossing the line… After the FSD Rewrite, the ceiling was raised to an unprecedented height, and even a hint of light was revealed from the unmanned driving window in the room.
The number that cannot reach 100 is getting closer and closer to 100.
But can it be considered Full Self-Driving if it does not reach 100?
I think: No one can completely achieve 100. Full Self-Driving is essentially a pseudo-proposition that can only infinitely approach but never be completely realized.
Because on the road, the scene always appears first, and then the subsequent scene is collected, and the subsequent training and learning process, no matter how large Autopilot’s material library is, it will always be a subset of the real world.
But it doesn’t matter, there are too many things in our lives that cannot reach 100. However, when the number of pixels reaches 1 million, a vivid picture can already be recorded, and when the picture is played at 60 frames per second, it is already a high-fidelity video.
Approaching 100 itself is a very valuable thing, and it is also the goal of technological progress.
Today, a 2K resolution phone has made it difficult for people to see the existence of pixels, and a 240Hz display has made people almost feel the interval between frames.And someday, we will also realize that we cannot perceive the difference between FSD and 100.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.