
Author: Winslow
Refer to the previous article: Tesla AI Day for Non-Experts (Part 1)
The original author of this article @cosmacelf is a technical writer on Reddit. The original title and link are as follows:
“Layman’s Explanation of Tesla AI Day”
https://www.reddit.com/r/teslamotors/comments/pcgz6d/laymansexplanationofteslaai_day
Text:
2100 words in total
Expected reading time: 10 minutes
The following diagram shows the overall architecture of a visual recognition system. However, this is only the recognition process, and the system only knows what is in the image, not yet the architecture for driving and control.
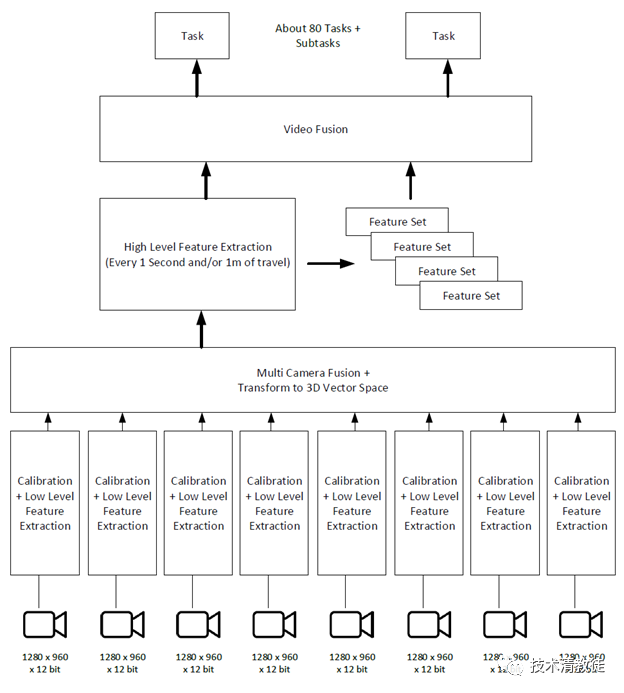
At this point, it may seem a bit complicated, but don’t worry, we will explain how it works step by step below. Each of these boxes will contain several to dozens of neural networks, and these neural networks are connected to each other in very complex ways.
The eight cameras in the car will be adjusted to output a “standard” image that is stable through a “calibration neural net”. After this adjustment, the “standard” image should be consistent with the image taken by all Teslas driving on the road.
When a car owner buys a new Tesla, the AP system will adjust the camera parameters using the calibration neural net within a few days to ensure that the vehicle can output stable standard images in the future. After completing this process, the car can accurately know the difference between each camera and the standard (baseline). Due to tolerance and other reasons during installation and manufacturing, each camera may be slightly offset or angled. However, the car must know these subtle errors to make the images output to the neural network consistent with those of other Teslas. Only when the images output by the car to the neural network are standard images, can the neural network effectively recognize the contents of the images.After the reset of the cameras, the AP system of the vehicle will eliminate unmeaningful standard image content from the captured images, and keep the important meaningful image content. This reduces or compresses the massive image data to a suitable size for subsequent processing.
Next, the content captured by the eight cameras will be fused into a panoramic view, and a 3D vector space will be generated to simulate the real world.
For the human visual cortex, generating a three-dimensional vector space based on a two-dimensional image is an easy task that we do every day without even realizing it. Take the following picture as an example:

For instance, you should be able to see that the red light is behind these three connected cars, and that the American flag and the car with the top light are approximately the same distance away, while the car with the top light is far behind this white small truck.
Tesla’s neural network also needs to perform relative positional calculations to output a three-dimensional world with vector coordinates, and label each object accordingly.
The output three-dimensional vector space model from Tesla is a raster with a certain density, and each raster has distance data. This is similar to the point cloud data generated by LIDAR.
Additionally, Tesla’s three-dimensional vector space also includes velocity data for moving objects, locating curbs and drivable road surfaces, and these are all labeled with different colors and higher resolution. This visual system is more complex than a LIDAR-enabled system, and the model it outputs includes some occluded objects, such as a pedestrian behind a car that is currently not visible to the car’s camera, but this visual system can use a video memory module to keep track of these occluded targets.
We know that Tesla’s neural network system is very complex. Like the human visual cortex, these neural networks search for useful information from high-order to low-order.
Here’s an example: we want to know what’s in the box of the blurry 10×10 pixels in the image below.

Your brain knows that this obscure set of pixels is most likely on the road, and is located at the point where the image is about to disappear, indicating that it’s very likely a taillight of a car.
When the camera fusion and three-dimensional vector space are created, Tesla adds time and location based on the video memory module.
The advantage of adding the latter is that it can become similar to the way humans drive, because the environment of this world is designed and constructed for human driving. Humans have memories.

Taking the example in the above picture: when we are preparing to turn left, we will switch the car to the left lane, but when the car reaches the intersection, it’s often been several seconds since we saw the left-turn arrow. At this time, we need to evoke our memory to make sure we remember that the car is in the left-turn lane.
Tesla’s vision system creates a snapshot list of key information to remember these graphical identifications. This is very similar to our own driving, although we may not remember this list, our subconscious is indeed guiding our driving in a similar way.
This video memory module is also used to track the obscured targets mentioned earlier. For example, when Tesla’s car is driving on a multi-lane road and a car is driving on the two lanes to the left of the car, but 3 seconds later, it’s blocked by a car right next to our car on the left. Then, this video memory module can help the neural network remember that there is a car being blocked there and then estimate the approximate location. Having this information is crucial for path planning in certain situations.
Tesla’s video memory module with a snapshot list of key information is very powerful. It’s uncertain whether other self-driving companies have similar functional modules (mainstream self-driving companies use pre-made high-precision maps, which should have more comprehensive information, but the production and updating of high-precision maps are very difficult, and it’s not clear whether other companies have the tracking capability of obscured targets).Tesla’s vision system outputs a set of three-dimensional vector space data, which includes snapshots of the current image and a series of key information. This set of three-dimensional vector space data is input to about 80 neural networks, which Tesla refers to as “tasks”. Each task does a very specific thing, such as locating and recognizing traffic light signals, identifying traffic cones or barrels, identifying “Stop” signs, or recognizing vehicles and their speeds, and so on.
The output data is finally summarized as meaningful information, such as: there is a red light at a distance of 30 meters from now, or the car in front 30 meters away is likely to want to stop.
In the following sections, we will discuss Tesla’s path planning and control in detail.
(To be continued)
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.