The media under Traveling with 100 People focuses on the evolution of the automobile industry chain
Author: Li Yizhi
On August 20th, Tesla’s long-awaited AI Day was held as scheduled. As usual, AI Day, an open event for investors, focused mainly on showcasing technological capabilities, with recruitment being a secondary concern.
However, this year’s AI Day went overboard with showcasing the technology, with a high frequency of proprietary terms and a high density of information. This left netizens who tried to tune in for fun exasperated. The general reaction was as follows:

Nonetheless, AI Day came at a time when Tesla was establishing a new direction for autonomous driving technology. Through this brain-teasing public day, Tesla attempted to explain why they chose to go to the end of the line in the pure visual autonomous driving technology route. And perhaps, they chose this road not only to create autonomous driving cars.
In response to this super difficult AI Day, we launched a technical assault overnight, focusing on four key words: visual neural networks, data sets, Dojo supercomputers, and Tesla Bot. We attempted to clarify the intrinsic connections among them and the Tesla autonomous driving cars for our readers’ reading pleasure.
Tesla’s visual intelligence evolution
Before we delve into AI Day, let’s supplement a little background knowledge.
Starting in May this year, Tesla removed the millimeter wave radar from the new Model 3 and Model Y vehicles delivered in the North American market. From that moment on, Tesla had announced a new visual technology framework, paving the way for “autonomous driving based solely on visual intelligence.”
Tesla CEO Musk has always believed that if humans can drive solely based on visual information, then autonomous driving cars should be able to do so too based on the first principle.
The work on this path is being led by Andrej Karpathy, Tesla’s AI director. In a public speech last year, he gave a hint that Tesla was trying to use visual neural networks to “accurately predict” the speed and distance of objects – the function previously matched by millimeter wave radar.
A year later, Tesla officially waved the banner of “pure visual autonomous driving.”
However, the work done by Tesla’s visual team is far more extensive than merely “removing the millimeter-wave radar.” The “originator” Karpathy described at AI Day the evolution of Tesla’s visual intelligence over the years.Four years ago, when Andrew joined Tesla’s Vision team from Open AI, Tesla’s visual AI technology was not that impressive. At that time, Tesla had developed a neural network that was not too complex in structure, with not too many layers, used for single-frame image processing, and output results such as recognition, tracking, and semantic segmentation on 2D images. Its characteristic was that it was relatively efficient, with a good balance between latency and accuracy, but the performance was not outstanding.
However, when Tesla began to use eight cameras on the car, determined to advance towards FSD (full self-driving), they found that if they followed the original technical framework and let the eight cameras work independently, and then integrate their recognition results to guide driving, the vehicle would not become smarter at all. For example, the “Summon” function was delayed because “simplistic technology cannot handle a complex world.”
Subsequently, Tesla’s Vision team began a large-scale modification of the neural network’s technical framework, decided to merge the information collected by the eight cameras together, and output it as a three-dimensional vector space through a transformer (instead of the original 2D image). As shown in the picture, the vector space output after multiple camera fusion has higher quality, which can help the self-driving car perceive the world and locate itself more accurately.
But this was not the end of the story, because there was no time stamp in this vector space. From the perspective of a self-driving car, it does not know the inherent connection between the scene it saw and the scene it is seeing now, and it has no “memory.” The key work that followed was that Tesla’s Vision team inserted a feature queue in the neural network, which was responsible for recording spatio-temporal information, allowing the later structure to extract memories from it.
With spatio-temporal concepts, self-driving cars can understand not only single-frame images. Based on this, the Vision team developed a video module that converts spatiotemporal features that are frozen at a certain moment into continuous features. It enables self-driving cars to track continuous motion of objects, draw maps of the roads in real-time based on “memories,” and become more intelligent when facing scenes where objects are obstructed.Here is the structure of the visual neural network that Tesla has used to achieve this effect (right image), which has become much more complex compared to the framework four years ago (left image). Andrej’s team is still working on further optimizing the network, such as moving the step of adding spatiotemporal features downwards in the neural network (improving information efficiency) or adding modules at the bottom of the neural network, such as stereovision matching and optical flow (to improve recognition performance and depth prediction accuracy).
In fact, AI Day could be the most difficult event for the public to understand among all of Tesla’s public activities. The content above is already beyond the reach of the general public. However, this complex technical structure has just completed the first step in autonomous driving – perception. Just like humans, autonomous vehicles need to plan driving routes based on perception results before executing actions.
The microphone was then handed over to Ashok Elluswamy, head of Tesla’s autonomous driving planning and control team. He divided the core tasks of autonomous driving into three goals – safety, efficiency, and comfort. Like humans, autonomous vehicles need to plan driving routes based on perception results before executing actions.
The essence of planning is to decompose various complex variables (such as traffic rules, longitudinal and lateral accelerations, distance to obstacles, and action execution time) around the goals of safety, efficiency, and comfort, organize them into a function, and then find the optimal solution or minimum value of the function.
The difficulty of solving such a function that reflects the real world lies in two points:
- It is non-convex (Non-Convex, with multiple local optimal solutions, but these solutions may be very bad for the global optimal goal, and the global optimal solution is difficult to obtain).
- It is high-dimensional (High-Dimensional, with many complex parameter generations). These two characteristics are suitable for two completely opposite problem-solving methods.
Tesla’s team’s approach is to divide the planning task into layers, first using discrete search to screen out a suitable “corridor” to avoid falling into the local minimum value, and then using continuous function optimization to further achieve the global optimum and draw a smooth route.It is worth mentioning that Tesla not only plans its own trajectory, but also plans and predicts the trajectories of other vehicles in its field of vision. This way, Tesla can to some extent understand the driving intentions of other vehicles, and make driving reactions more like those of human drivers.
However, not all scenarios have clear rules. In some non-standard scenarios, it is difficult for humans to design a set of rule-based, globally optimal algorithms. In these cases, Tesla’s planning and control team will allow the neural network to find a heuristic algorithm in a black box way based on a given cost function, input human operating modes, and input simulation data, rather than relying on fully clear rules as described above, to guide the final path planning and reduce the number of trial-and-error attempts in simulating non-standard parking scenarios.
Finally, after the long process of visual recognition, feature extraction, rule-based path planning, and “black box” neural network path planning (which may take only a few dozen milliseconds in computational terms), the autonomous driving car will output motion instructions and move on its own.
In fact, from a technical point of view, Tesla’s vision-based perception and planning technology framework is not particularly remarkable, and there is no new wheel invention. It is engineering innovation rather than theoretical innovation. When introducing Tesla’s planning strategy for non-standard scenarios, Ashok also generously stated that this problem can be solved with technology similar to Google’s second-generation AlphaZero AI.
But, as Andrew pointed out, making this pure vision-based autonomous driving technology work in complex real-world environments is easier said than done. It looks like a big technical patch, but in essence, it is a continuous stream of engineering innovations.
Due to the difficulty of landing for various Robotaxi companies, after this new technology framework is extensively updated to the existing vehicle fleet, Tesla will start exploring the forefront of the practical utility of visual intelligence.
However, since this new technology framework was only established this year, Tesla has only pushed updates to a very small number of FSD Beta users. In addition, the NHTSA (National Highway Traffic Safety Administration) has just launched an investigation into Tesla’s autonomous driving system accidents at its AI Day. Therefore, users cannot expect Tesla’s autopilot capabilities to increase exponentially in the short term.With the advancement of Tesla’s vision technology, particularly the “feat” of replacing the traditionally considered essential millimeter-wave radar with cameras, the team is clearly receiving a positive feedback about the pure visual approach, which has a lot of untapped potential. Tesla holds the most important thing to unearth visual potential: data.
Making Useful Data come faster
If artificial intelligence is a rocket, then data are definitely the rocket fuel – they will be consumed at an extremely fast pace.
And to feed an artificial intelligence that can achieve autonomous driving, a tremendous amount of data is needed. Fortunately, relying on the shadow mode of sold vehicles, Tesla has collected billions of miles of Autopilot driving data. But this data is not readily available and needs to be “annotated” before it can become a training sample, like this.

A few years ago, Tesla collaborated with third parties to outsource the data annotation work, but found that the output of annotated data was of poor quality, so they subsequently built and expanded their own data annotation team. Today, Tesla’s data annotation team has reached 1000 people.
As the team grows, along with the increasing complexity of visual neural networks and the requirement for information processing, the team has also developed tools that allow data annotation work to be converted from 2D images to 3D and even 4D vector spaces. However, the further result was an increase in the workload of data annotation, which is difficult to complete with human resources alone.
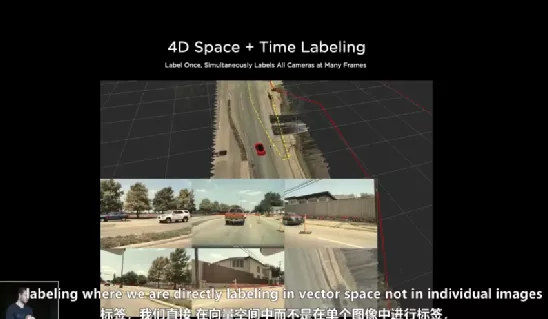
So, Tesla’s AI team began developing automated annotation tools.
According to the team’s AI Day presentation, their tools enable the car to annotate and reconstruct roadways, traffic participants, and obstacles in real-time while driving. As a result, when different vehicles drive on the same road, their annotation/reconstruction data can converge to encompass rich spatiotemporal information on the road.
These complete and high-quality datasets are used to train new neural networks, ultimately resulting in “Tesla driving better with only vision than before”.
For example, when a vehicle removes radar and the lead vehicle is obstructed, the vehicle still achieves accurate tracking of the lead vehicle’s position, distance, and speed. By comparison, addressing this situation with the original algorithm would be somewhat dangerous.
 Actually, in order to train the new neural networks to handle this situation, Tesla collected tens of thousands of video clips with similar scenarios and annotated them. If relying on human labor, these tasks would take several months. However, with the use of automated annotation tools, the work was completed within a week.
Actually, in order to train the new neural networks to handle this situation, Tesla collected tens of thousands of video clips with similar scenarios and annotated them. If relying on human labor, these tasks would take several months. However, with the use of automated annotation tools, the work was completed within a week.
However, even with large amounts of data and efficient automated annotation tools, it does not mean that Tesla has enough data. The complexity of reality is beyond imagination, and in many cases, Tesla’s data collection/annotation automation tools are difficult to use, such as rare scenarios that can hardly be collected (e.g. humans, cars, and dogs running on the highway at the same time), or scenarios that exceed the capacity of automation tools (e.g. dozens or hundreds of people crowded on a street).
At this point, Tesla needs to create new scenes with built-in annotations from the data collected in the past for training purposes–this is called simulation.
According to the introduction, Tesla’s simulation system has several features:
- Accurate simulation of sensors (mainly cameras), including noise, motion blur, lens distortion, etc.
- Realistic image rendering, using technologies including ray tracing and neural network rendering, to make the image effects as close to reality as possible.
- Rich materials. Tesla’s simulation material library includes thousands of different vehicles, pedestrians, and other objects, as well as a simulated road network that is 2000 miles long.
- More targeted. Tesla’s simulation library will focus on recording the real-world scenarios where the self-driving function fails and generate almost identical simulation scenarios for repeated training.
In terms of data volume, there are currently 371 million simulated images with nearly 500 million labels in Tesla’s simulation library. Next, the Tesla simulation team hopes to add more vehicles and pedestrians to the simulation world, add road topology, and apply reinforcement learning.
To achieve the continuous upgrade of autonomous driving capabilities according to Tesla’s established road, continuous automated data annotation and continuous iteration and training of the neural network are required, which require massive computing power.
In fact, in the past few years, Tesla has been expanding its supercomputing cluster. As of 2021, Tesla has built three high-performance computing clusters, consisting of nearly 12,000 high-performance GPUs in total, but this is still far from enough.
The strongest AI supercomputer Dojo: the strongest point is not computing powerIn November last year, Tesla’s global fleet surpassed 1 million vehicles, and its delivery target for this year is expected to be between 800,000 and 900,000 vehicles. Under the massive data generated by nearly 2 million “high-quality data generating machines” day after day, Tesla’s existing computing center is actually inadequate in terms of processing power.
AI supercomputing Dojo is born for this purpose.
Ganesh Venkataramanan, the project leader of Dojo, said that a few years ago, Musk foresaw the explosive growth of data and computing power demands and requested him to lead this project. They set some explicit goals for Dojo: high computing power, high efficiency, and cost-effectiveness.
However, a world-class problem that has always existed in the field of supercomputing is that computing power can easily be increased by stacking chips, but it is very difficult to solve the bandwidth and latency of data transmission. On the contrary, the bottleneck of bandwidth and latency can actually reduce the computing efficiency of the entire supercomputing system, causing the computing power stacked up by brute force to idle.
Solving the bandwidth and latency bottlenecks of Dojo has actually become the critical work of the supercomputing team. In fact, this is also the team’s biggest innovation.
To this end, the main work of the supercomputing team is, on the one hand, to develop appropriate operational units for various level indicators, so that a large-scale global computing task can be decomposed into many parallel local operations to be executed on operational units, thus reducing global data exchange (reducing bandwidth and latency issues); on the other hand, to strive for high bandwidth and low latency performance at all levels of Dojo’s composition (operational units-chips-system), to prevent the occurrence of a bucket effect.
The most basic operational unit, called a training node, is called by the supercomputing team. The main components of a node include a 4-thread super scalar CPU, multiple 8×8 multiplication matrices, SMID units, etc. Their common feature is that they are suitable for parallel computing. On the other hand, the supercomputing team has filled the node inside and around it with lines for data transmission.
As a result, only one minimum node of Dojo has an computing power of 1Tflops (i.e., 10 trillion times per second) in BF16/CFP8 data format, and has a floating-point operation performance of 64Gflops in higher-precision FP32 format (1Tflops=1000Gflops). Each of the 4 edges of this node has a data throughput of 512GB/s per second (for comparison, the bandwidth occupied by a 60Hz, 8-million-pixel high-definition camera is nearly 2GB/s).354 nodes like this are combined together to make up the actual supercomputer chip we can see, D1. The D1 chip is manufactured using 7nm process technology, integrating 50 billion transistors on a 645-square-millimeter die. The internal wiring of the chip reaches 11 miles, while its TDP (thermal design power) reaches 400W, equivalent to a small space heater when running at full capacity.
With such high power consumption, how powerful is the D1 chip really? A single D1 has a floating-point computing power of 22.6Tflops in FP32 format (NVIDIA’s currently most advanced A100 chip used for AI computing has a data of 19.5Tflops), and the bandwidth on each side of the chip is 10TB/s. In terms of bandwidth for data transmission with the outside world, each side of the D1 chip also has a rate of 4TB/s, which is more than twice the performance of the most advanced network switching chips available today.
By the time the D1 was developed, the supercomputer team had solved the bandwidth and latency issues at the chip level quite well. However, the next and more difficult step was to solve the bandwidth and latency issues after the chips were assembled into a module, as the physical distance and connection method between the chips often determine the bandwidth and latency. Since the D1 chip has ultra-high bandwidth, the supercomputer team decided to “eliminate intermediaries” and connect the chips directly to each other.
Therefore, Tesla introduced a brand new InFo-SoW (integrated fan-out system on wafer) technology on the D1 chip, directly carving out 25 D1 chips on a single wafer without cutting them apart for separate packaging, thus maximizing their internal connection wiring and bandwidth. These 25 connected D1 chips make up a training tile. On this entire training tile, the power supply, cooling, and other modules are further packaged.
A training tile with this technology achieves an astonishing 9PFlops of floating-point computing power under BF16/CFP8 accuracy. Of course, Dojo cannot be composed of just one training tile. Therefore, the supercomputer team has developed a connector with a total bandwidth of 36TB/s for each training tile, which can both combine the training tiles and serve as their data channels.This step completed, Tesla will assemble the training blocks into the final supercomputer cluster Dojo. Their plan is to place 120 training blocks containing 3000 D1 chips into 10 cabinets, ensuring that each chip on every training node has high bandwidth and low latency performance. The final computing power of Dojo is 1.1 EPlops at BF16 precision (i.e. 1.1 hundred trillion floating-point operations per second).
What is Eflops, a concept that ordinary people find difficult to comprehend? In daily life, people cannot even grasp the magnitude of “E.” For example, some scholars believe that the total amount of data produced by humans throughout history is only in the hundreds of exabytes.
In addition, the supercomputer team has developed special virtualization tools that allow Dojo to be sliced into multiple smaller Dojos for simultaneous computing of various tasks. With the combination of hardware and software, Dojo is undoubtedly a powerful and flexible computing monster that can greatly ease Tesla’s data storage problems.
It is worth mentioning that some people consider Dojo to be the world’s fastest supercomputer due to its Eflops-level computing power. However, in reality, Tesla has chosen the lower precision BF16 format for promoting this data. According to FP32 precision, Dojo’s computing power can only reach tens to nearly a hundred Pflops, which is one order of magnitude lower than Eflops. Currently, “Fugaku,” the world’s fastest supercomputer, has computing power of more than 600 Pflops under the higher precision of FP64, far surpassing the complete Dojo.
Compared to computing power, Dojo’s greatest feature is its ability to balance high computing power and flexibility by combining different computing chips, and also solving the bandwidth/latency problem.
Of course, if limited to the field of artificial intelligence, Dojo, after assembly, can indeed be referred to as the fastest AI training supercomputer. However, currently Dojo is still in the stage of “about to assemble the first cabinet.” The use of various new technologies also poses significant risks for Dojo, such as the fact that the D1 chip is based on InFo-SoW technology, which TSMC has just started to use, and its yield ramp-up will require a process, so it is very likely that it will take a considerable amount of time for Dojo to be fully assembled.
One More Thing: Tesla bot, moving towards general artificial intelligence?
After Steve Jobs, every memorable press conference should have a “one more thing.”The best “one more thing” for Tesla’s AI Day is arguably the most anticipated form of artificial intelligence, which is robots.
In Elon Musk’s view, Tesla is the world’s largest robotics company, because Tesla’s cars are essentially semi-intelligent robots on wheels. And the perception and cognition of the world by autonomous driving cars can also be applied to robots.
Therefore, at the end of AI Day, Musk announced that Tesla plans to produce a prototype robot, Tesla Bot, next year. It has 40 motion execution units and is designed to look, weigh, move, and even have the same strength as an ordinary person. It will be used to perform dangerous or repetitive work.
It is currently unclear whether this robot will follow Tesla’s traditional delay in production, as Musk’s main goal for announcing it on AI Day was to recruit people for the project. And robot motion control, unlike chassis control for cars, does not have a mature system, which means that the development of Tesla Bot may require some very basic work.
However, one particularly noteworthy point is that Tesla Bot will share the same computing chips (using FSD chips), sensors (using Tesla Autopilot cameras), perception algorithms, and cloud training as Tesla’s autonomous driving cars. Tesla’s goal of a universal robot is clearly stated in its PowerPoint presentation.
The characteristics introduced by the head of the supercomputing team when introducing Dojo can also serve Tesla Bot. For example, he said that Dojo’s chips have “GPU-level computing power and CPU-level flexibility,” and Dojo’s software virtualization can support multiple training tasks at the same time.
One data point is that when humans perceive and recognize the world, 70% to 80% of the data is processed through vision. This means that vision plays an extremely important role in the process of “intelligence” being generated. And Tesla’s continued use of pure visual technology to challenge autonomous driving is, to some extent, reproducing the evolution of intelligence.
Now Tesla is beginning to use visual technology to develop robots, partly answering a question – can humans create a general artificial intelligence or humanoid artificial intelligence through continuous iteration of “visual intelligence”?
The answer may not be revealed until many years later.After AI Day, Tesla has probably anchored a viewpoint in more people’s minds: compared to car manufacturers, Tesla is more like an AI company. Every car manufacturer (of course not only including car manufacturers) is probably feeling the pressure, disturbed by Tesla, and has marked out a development path that is completely different from the past.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.