
If you happened to catch the live stream of Tesla AI DAY on social media today and entered at around 2 hours and 6 minutes, chances are you, like me, were blown away by what you saw in the following minutes.
The surprise came first from the sci-fi like humanoid robot shown in the image below. It’s called Tesla Robot and it’s the Easter egg of this AI DAY event – a robot that shares visual cameras and neural network computing chips with Tesla cars.


Just as my anticipation was skyrocketing, hoping to see the robot walk on the stage and say “So it is with considerable pride that I introduce a man who’s been like a father to me – Elon Musk,” I witnessed the following scene:

Seeing this awkward COS dance, some of the audience who, like me, were expecting more, may have had the following doubts in their hearts:
“What?”
“Is this it?”
“RNM, refund!”

But jokes aside, if you watched the AI DAY live stream from beginning to end, you should know that this dance was one of the few lighthearted moments in the 3-hour event.
The amount of information density, breadth of technical fields covered, and heavy accents in the event were so great that it might take me weeks to fully understand, but in this article, we’ll briefly summarize the key points.
The Foundation of Autonomous Driving
One Key Ability: Vision
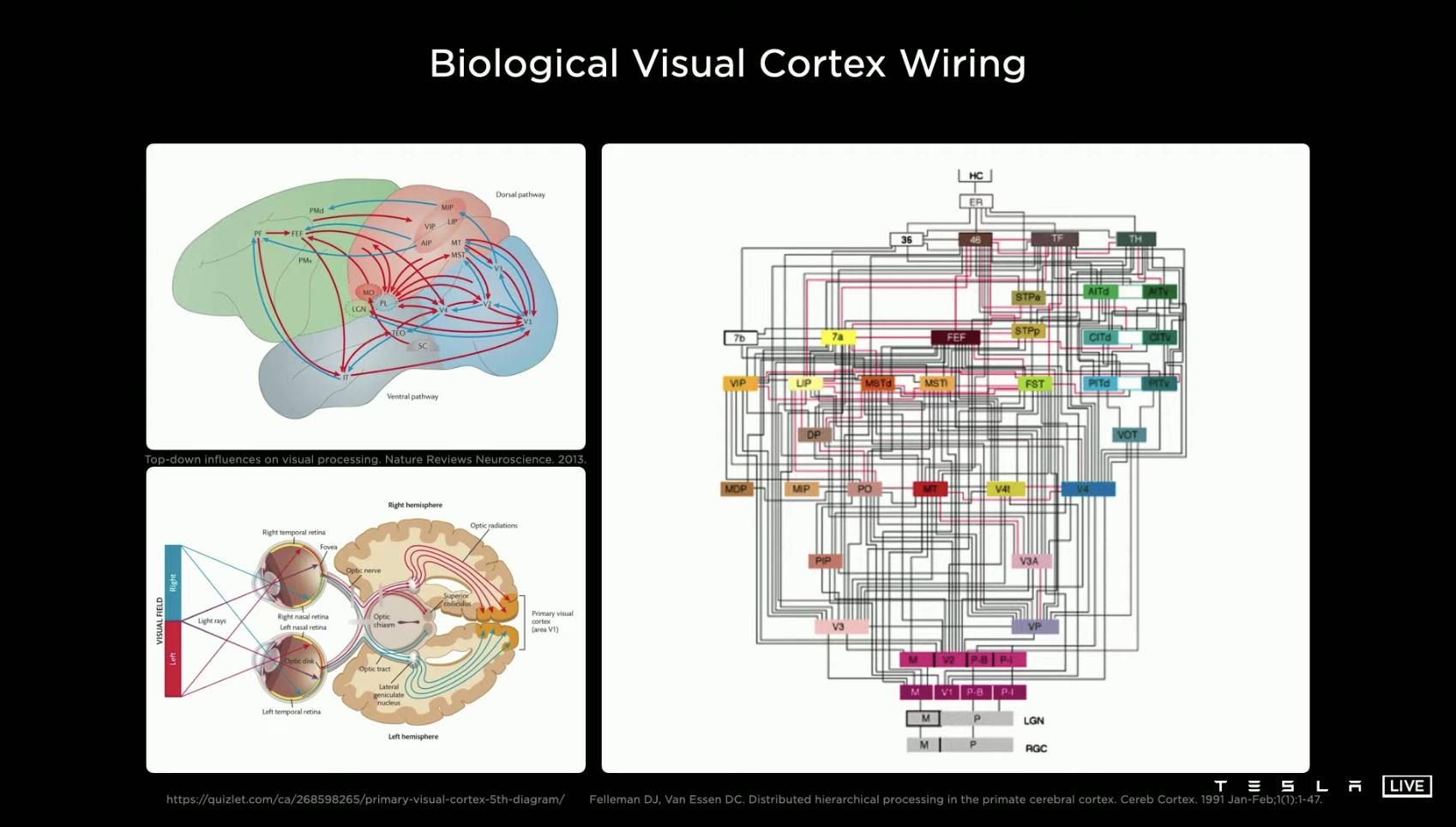
The beginning of the event was quite familiar, with Tesla’s AI Director, Andrej Karpathy, on stage introducing what Tesla is working on: developing a computer neural network system based on vision that’s similar to the human brain.
The best substitute for eyes is hard to find, but in Tesla’s current models, this function is fulfilled by 8 ADAS cameras that provide a 360-degree vision around the car.
After that, the whole system still needs a series of complex neural networks such as retina, binocular vision, optic nerve tract, etc. which mainly need to be implemented through software and algorithms.
In the process of recognizing visual features, the brain reads information through the retina, while computers recognize them by comparing the arrangement of pixels. Tesla has divided and coordinated different regions in the software feature extraction layer of this process, so as to combine the environmental conditions to infer those less obvious features in the recognition of features, such as the vehicle in the picture with almost mosaic resolution.
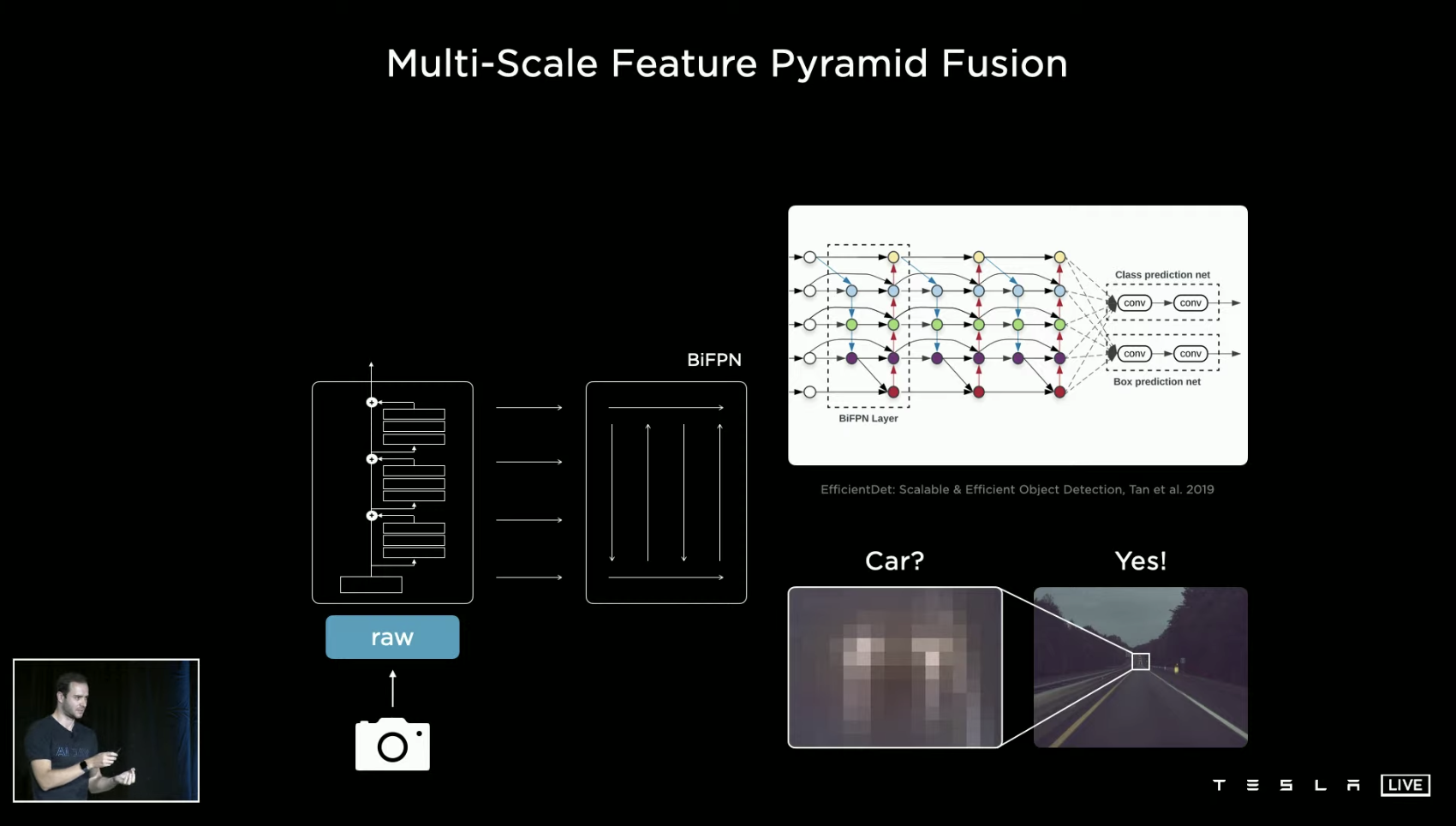
For different types of features, such as traffic lights, traffic lines, and traffic participants, Tesla has established many feature recognition instructions, which can perform feature recognition in a multitasking processing style on the same material. Tesla calls this set of recognition network “HydraNet”.
Then there is the “occupancy tracker” in the old version software, which can achieve cross-screen image stitching with a time axis, forming an environmental modeling around the vehicle. However, there are two problems: one is that the environmental modeling workload is huge, and it is very complex to implement this step through C++ software code, and the other problem is that the modeling accuracy is not enough.

Therefore, Tesla hopes to change its strategy. The original method was to predict each picture of each camera first and then stitch and fuse the information, while the current method is to directly stitch the materials of the eight cameras together and fit them into a real-time stereo space and then perform various predictions.
This process looks simple but is difficult to implement. After solving many key difficulties, the multi-camera vision finally made significant improvements in perception accuracy.

However, there are still problems that cannot be solved through multi-camera vision, such as predicting features when they are obscured and continuously memorizing the road signs that have already passed.
 ## Tesla’s Perception and Control Capabilities
## Tesla’s Perception and Control Capabilities
Tesla has implemented two important capabilities in its autonomous driving system: perception and control. Let’s explore each of them in detail.
Perception
Tesla has incorporated features that allow for predictions based on the movement of objects over time and the memory of distance markers on roads. This enables the system to “guess” the movement trajectory of objects after they have been temporarily occluded based on their pre-occlusion trajectory. Additionally, the system can remember various distance markers along a particular stretch of road.
Furthermore, the system incorporates a “Spatial RNN” neural network that selectively predicts and records certain environmental features within the vehicle’s visual range. For example, if the system detects an obstruction of the road due to another vehicle, environmental features beyond the obstruction are not recorded until it clears. Multiple trips using the recorded environmental features can then produce a feature map.
All of these measures result in a significant improvement in depth and velocity detection. In the below diagram, the green line represents the data from the millimeter-wave radar, while the yellow line represents the data from a single camera’s visual prediction, which is subpar. But the data from the blue line – produced by the multi-camera visual prediction – is almost identical to that of the radar, making it evident that the multi-camera visual solution can replace the millimeter-wave radar.
Finally, while Tesla’s perception capabilities are impressive, there is always room for improvement. The team is exploring strategies for pre-fusion perception and handling data cost more efficiently.
Control
The core goal of Tesla’s vehicle control is to balance safety, comfort, and efficiency. The primary challenges are localized optimal solutions and an overwhelming number of variables during actual vehicle operation. Planning what the vehicle should do for the next 10-15 seconds requires significant real-time computing.
For example, in the scenario depicted in the diagram, the vehicle needs to turn left twice and merge onto the blue line lane after the intersection. The system needs to ensure that the maneuver is executed smoothly while accounting for various factors:1. Two cars are rapidly approaching from the back of the left lane;
- Before the next intersection, two lane changes must be successfully carried out within a short distance.
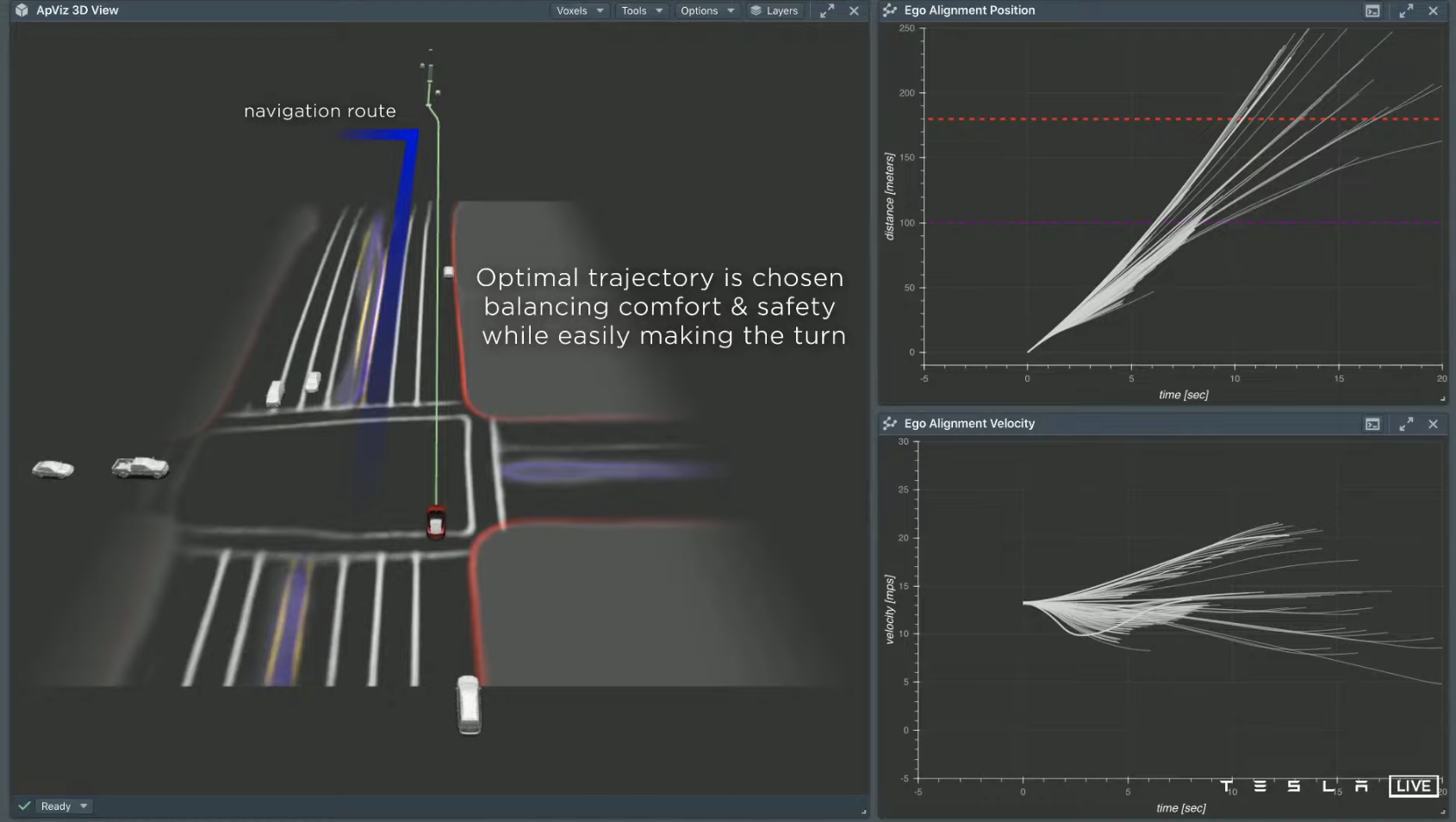
The system simulates multiple strategies and selects those that can meet the above requirements. In actual driving, in addition to planning its own driving path, it is also necessary to predict the paths of other traffic participants. The path optimization is carried out in accordance with the principle of “safety, efficiency, and comfort balance” in the feasible strategies. After the planning is completed, the remaining task is to control the vehicle to travel according to the planned route.
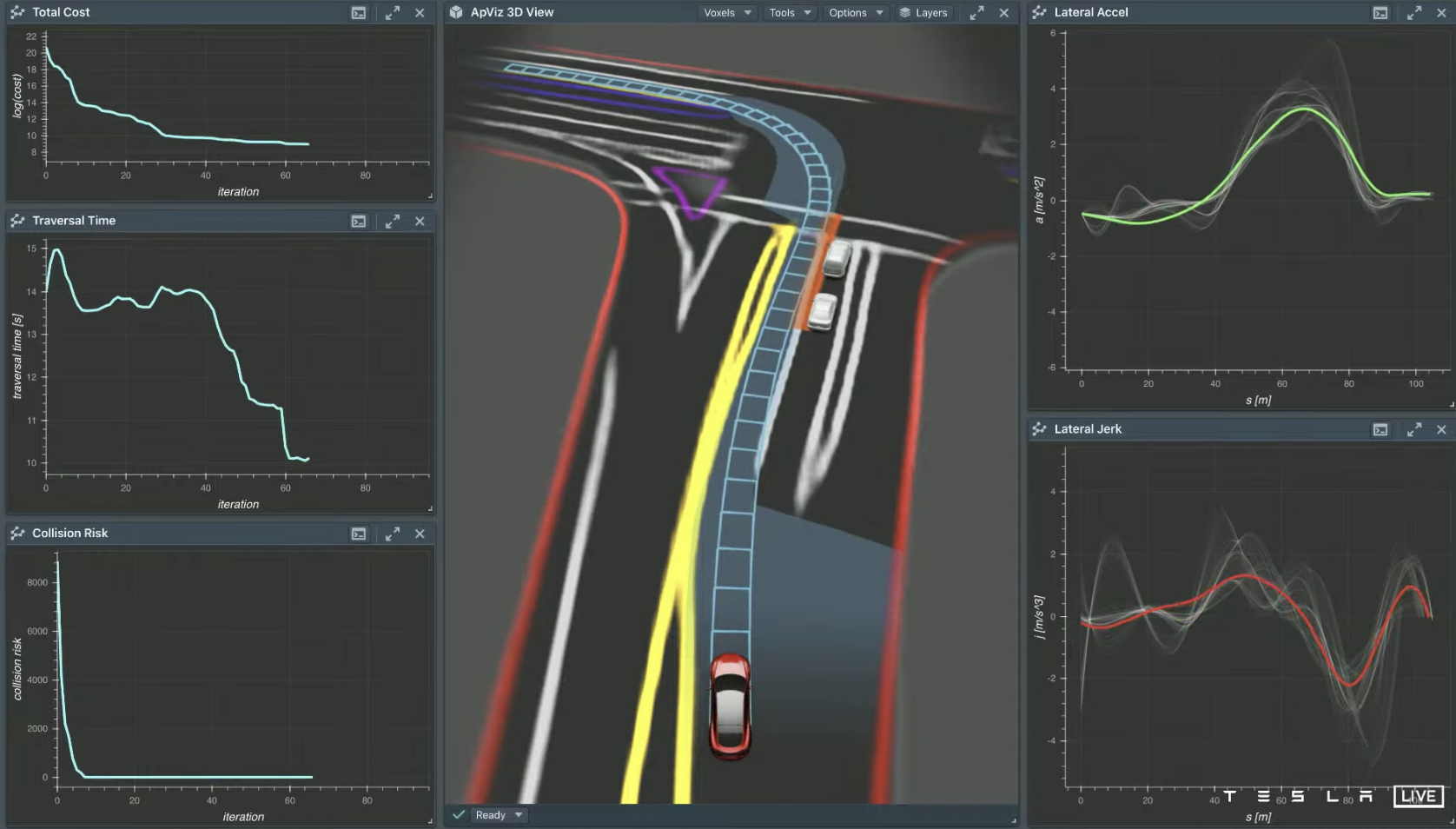
However, in more open and unordered road scenarios, the complexity of control and regulation will be greatly increased. For example, in the parking lot scene shown in the figure below, if the path search logic is set to the Euclidean distance algorithm, the system needs to try 398,320 times to successfully find the path to enter the parking space.
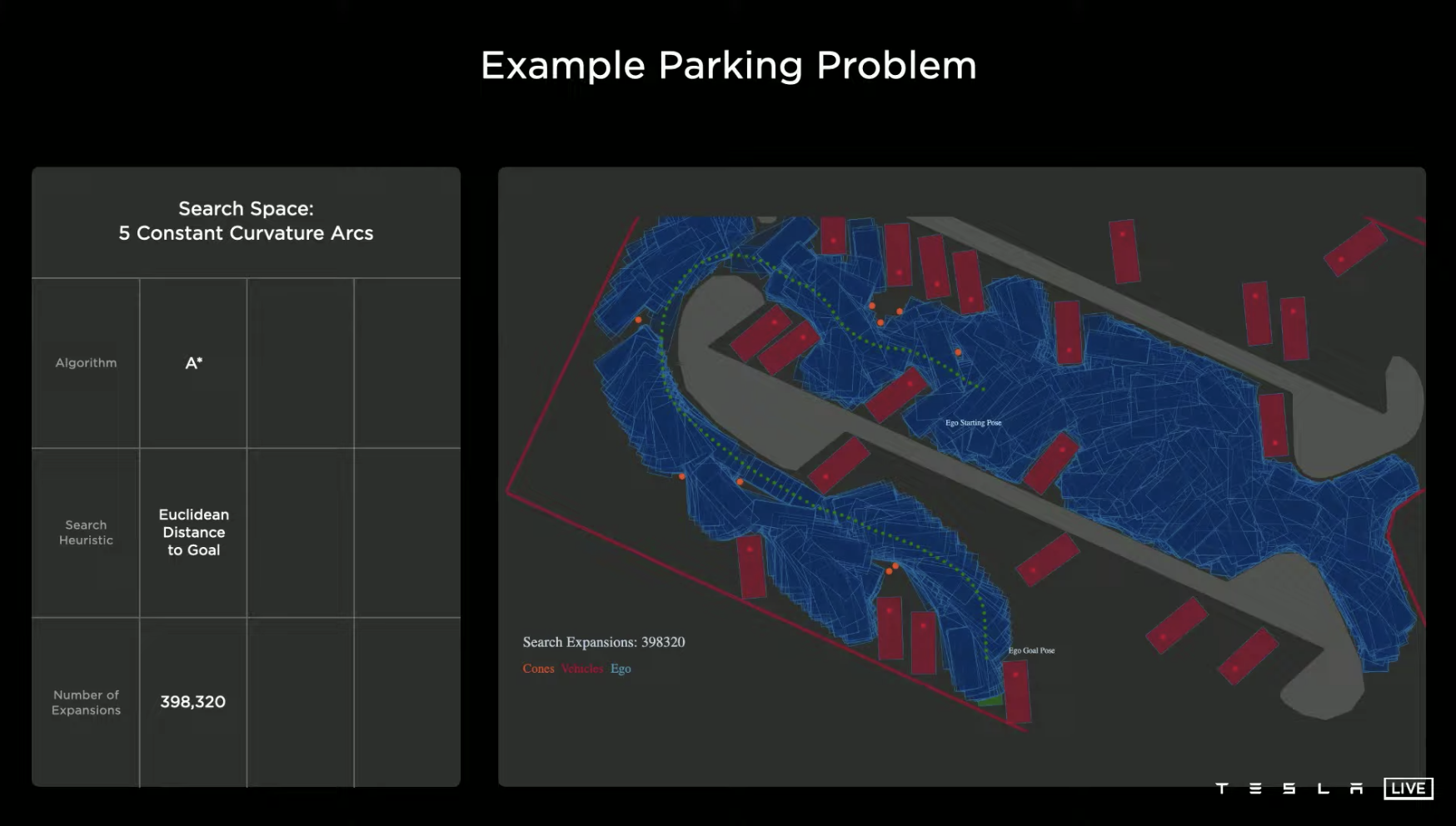
If some optimization is done and a “follow the landmark guidance direction of the parking lot” is added to the search logic, the system can find the path to enter the parking space after trying only 22,224 times, which reduces the trial and error times by 94.4% compared to the first strategy.
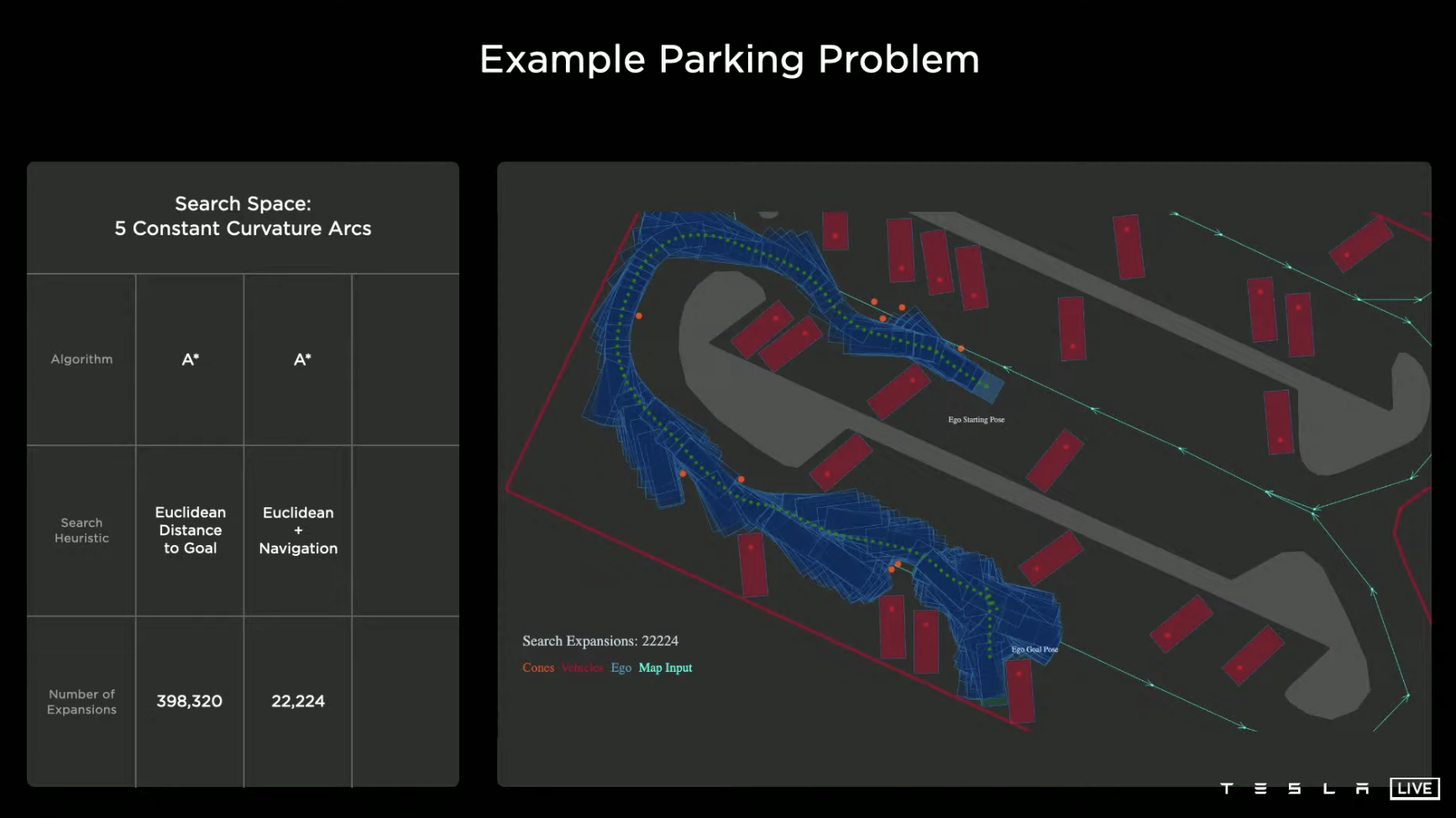
Next, going deeper, if the algorithm is changed to Monte Carlo tree search, and the logic is changed to neuron network strategy and value equation, the system only needs to try 288 times to find the path to enter the parking space, reducing the trial and error times by 98.7% compared to the already optimized second strategy.
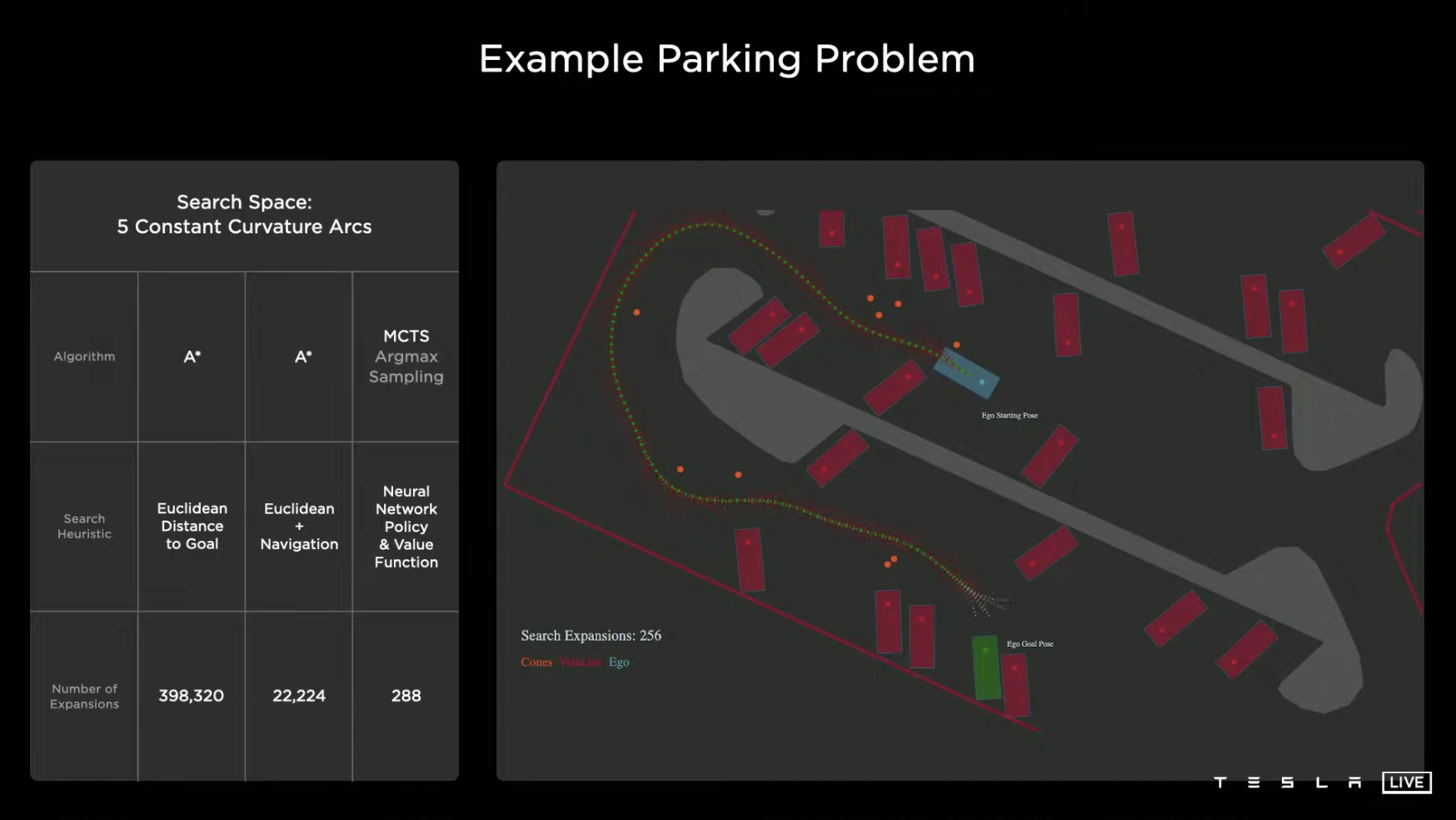
This case also shows that the logic and algorithm used in the control and regulation system in different scenarios have a very significant impact on the final computation. If the method is correct, success will come with half the effort.
Below is the autonomous driving framework diagram achieved through the two key abilities of perception and control, and this article will not elaborate further.
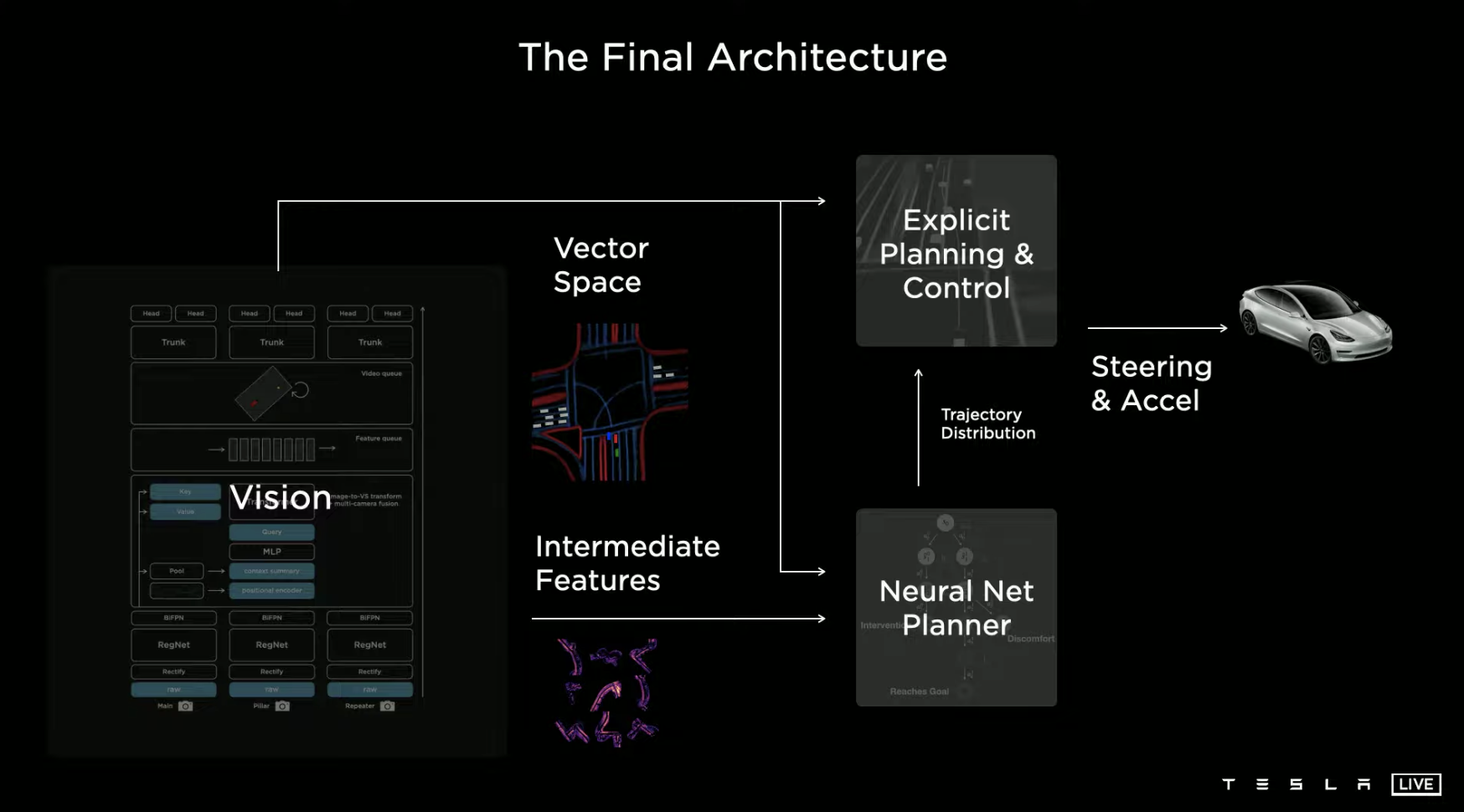
AI Driving SchoolWith the framework in place, the next step is to train the neural network to higher capabilities. This is similar to how humans need to accumulate driving experience and learn driving skills after having eyes for perception and a brain with limbs as the control system. Teaching machines to drive also requires an AI driving school, and the standards of Tesla’s AI driving school are naturally high.
Data labeling is a big job
Before feeding data into the system for learning, it needs to be labeled. Tesla has an in-house team of 1,000 data labeling experts who do not outsource any part of the process.
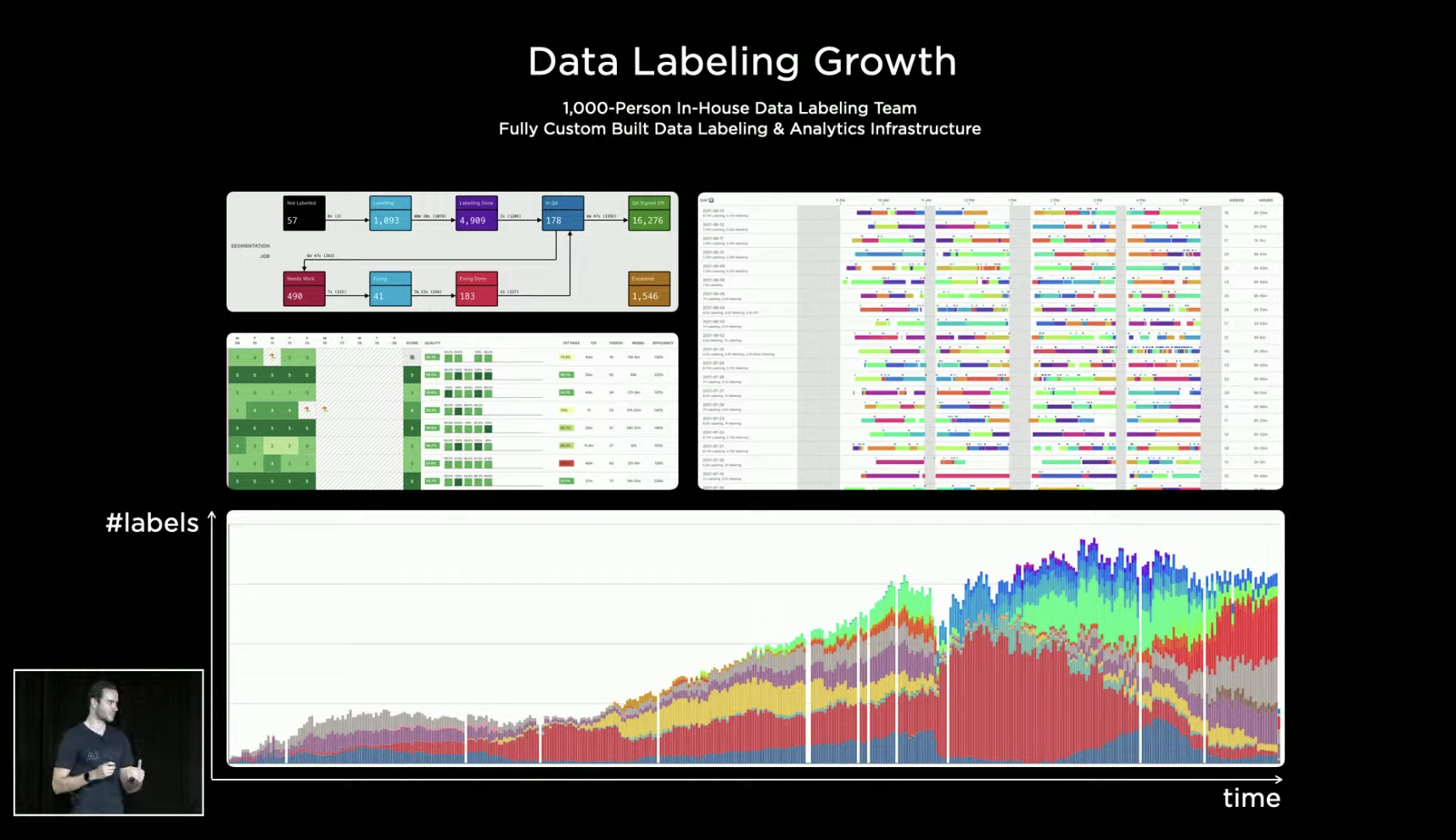
As time goes on, Tesla’s labeled data increases over time, and the types of labeling have evolved from initially labeling 2D images to directly labeling 4D spaces with time coordinates.

However, the focus of data labeling is still on automatic labeling. For example, after inputting driving materials, the system can automatically label lane lines, shoulders, road surfaces, sidewalks, and more.
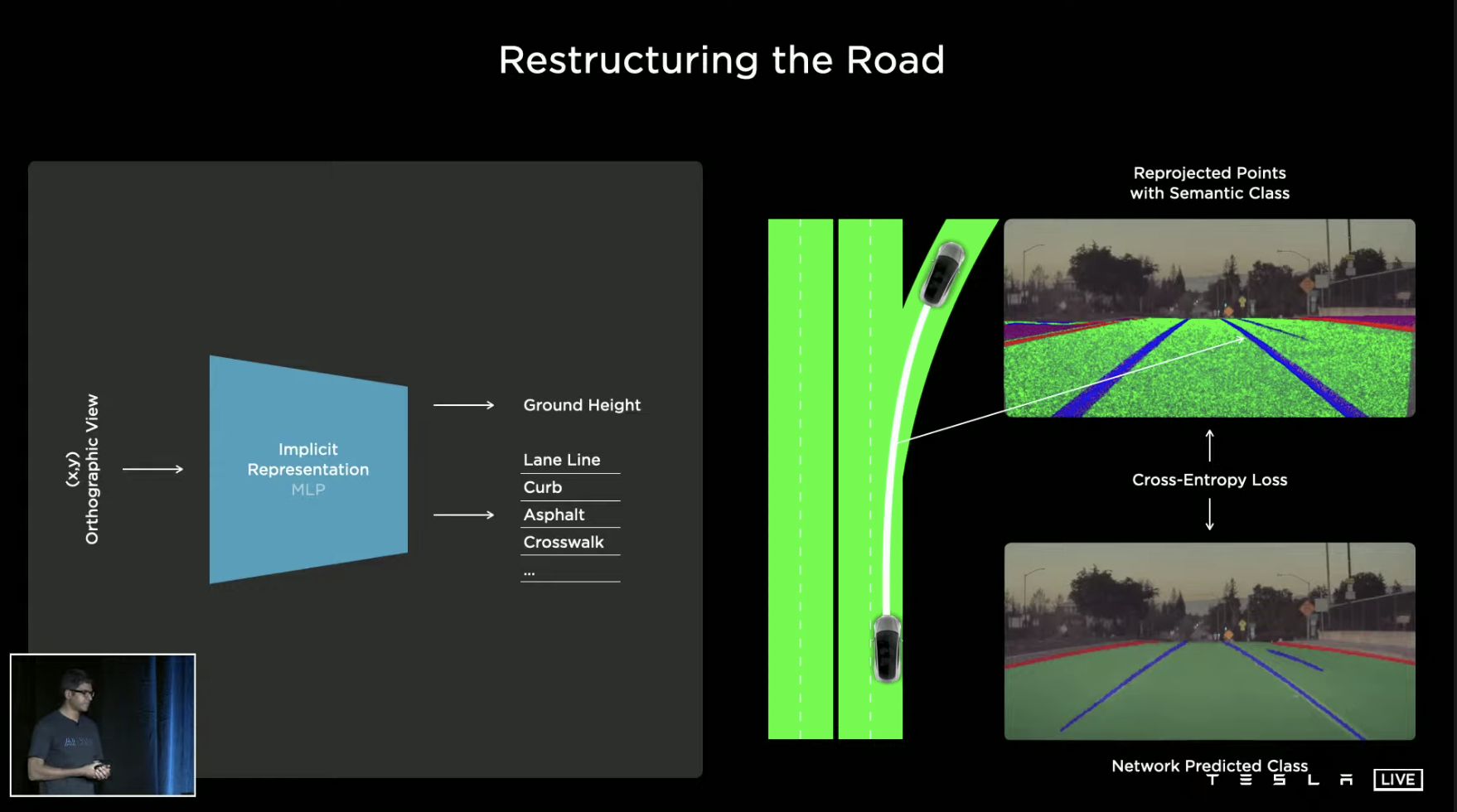
On this basis, when enough models of Tesla vehicles pass through the same area, the roads of this specific area can be marked. The data marked in this way can be used for model reconstruction of the road environment.

This data is not used for high-precision maps nor is it saved continuously in the vehicle system; it is only used for training. To ensure the quality of the reconstructed road model, manual optimization is still required to remove some noise.

The labeled features are not limited to commonly seen lane lines and shoulders, but also include fences, roadblocks, and more.
Another method that is very useful for predicting occlusion in the control algorithm is occlusion perspective labeling. The actual occluded object in the green circle in the image below will be marked in a perspective view. The system can learn how the object moves when it is occluded and develop corresponding learning strategies.
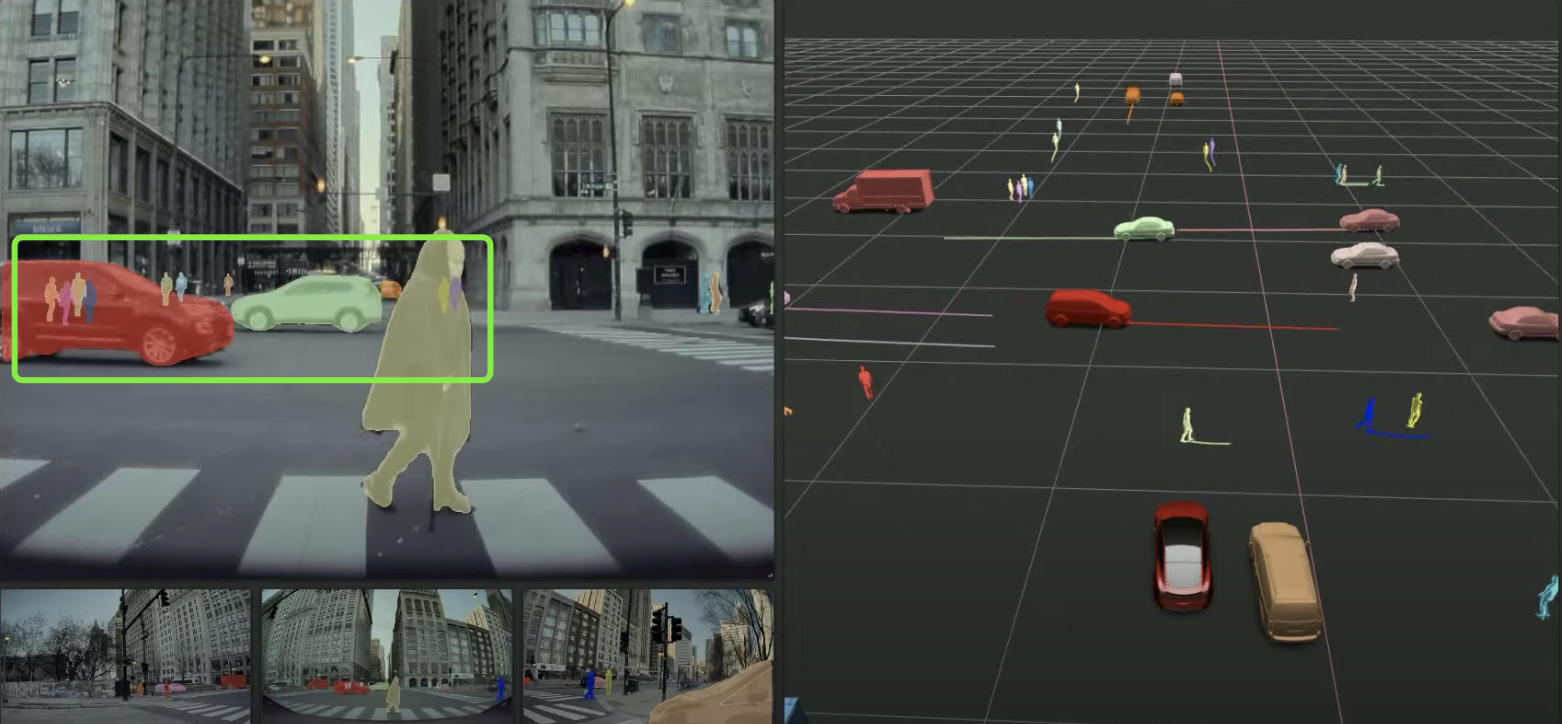
Using these labeling methods, a very realistic environment model can ultimately be constructed. With such modeling, concrete and targeted algorithm training can be conducted.

In the case of handling a scenario, similar scenarios can be searched from the vehicle’s tagged data. For example, in cases where the front vehicle is obstructed by smoke or other interfering factors, 10,000 actual scenarios can be found in the queue after a week of searching, and these “similar exam questions” can be used for fast generalization training of the neural network.

Besides real exam questions, simulation exams should also be taken
In the 2019 Autonomy Day, Musk said that Tesla not only trains algorithms through collecting real road environments but also conducts a large number of simulation tests, and the simulator developed by Tesla may be one of the best in the world.
During this AI Day, the company introduced this system, and Tesla first explained three situations where the simulator is helpful:
- Rare or unusual scenarios, such as the owner running with a pet on the highway as shown in the picture;
- Scenarios whose features are difficult to tag, such as people crossing a road with no traffic lights;
- The end of a certain road.

In summary, my understanding is that abnormal behavior scenarios, scenarios whose features are difficult to tag, and rarely visited scenarios can be supplemented by utilizing customizable simulators.
Moreover, due to the high degree of customization in the simulator, challenges can be artificially created during sensor tests, such as setting noise, exposure, reflectivity, thermal convection refraction, dynamic blur, optical distortion, etc., to verify the system’s anti-interference capacity.
To simulate more scenarios, the simulator has already created models of thousands of vehicles, pedestrians, and other props and the total length of the roads in the simulator is over 2,000 miles.
The process of scene reconstruction is then formed: first encounter a real scenario, perform the first-level reconstruction through automatic tagging, and then recreate the scenario in the simulator based on the first-level reconstruction.

In such a Tesla AI driving school, the company continuously collects various “real exam” materials from vehicles on the road. After being tagged and simulated, these materials become “simulation exam questions”. The system improves its experience by practicing and facing “simulation exam questions” with zero loss, and its ability to handle “real exam questions” also improves. According to the “syllabus” set by the developers, some “advanced exam papers” for special scenarios can also be created.### Current Training Equipment
The FSD Computer, also known as HW 3.0, currently used in Tesla vehicles, should be quite familiar to everyone. This SoC chip with dual 72 TOPS computational power was born in 2019 and serves as the core computing unit of the vehicle, using an architecture specifically designed for neural network acceleration computation. We won’t go into too much detail about other content in this article.
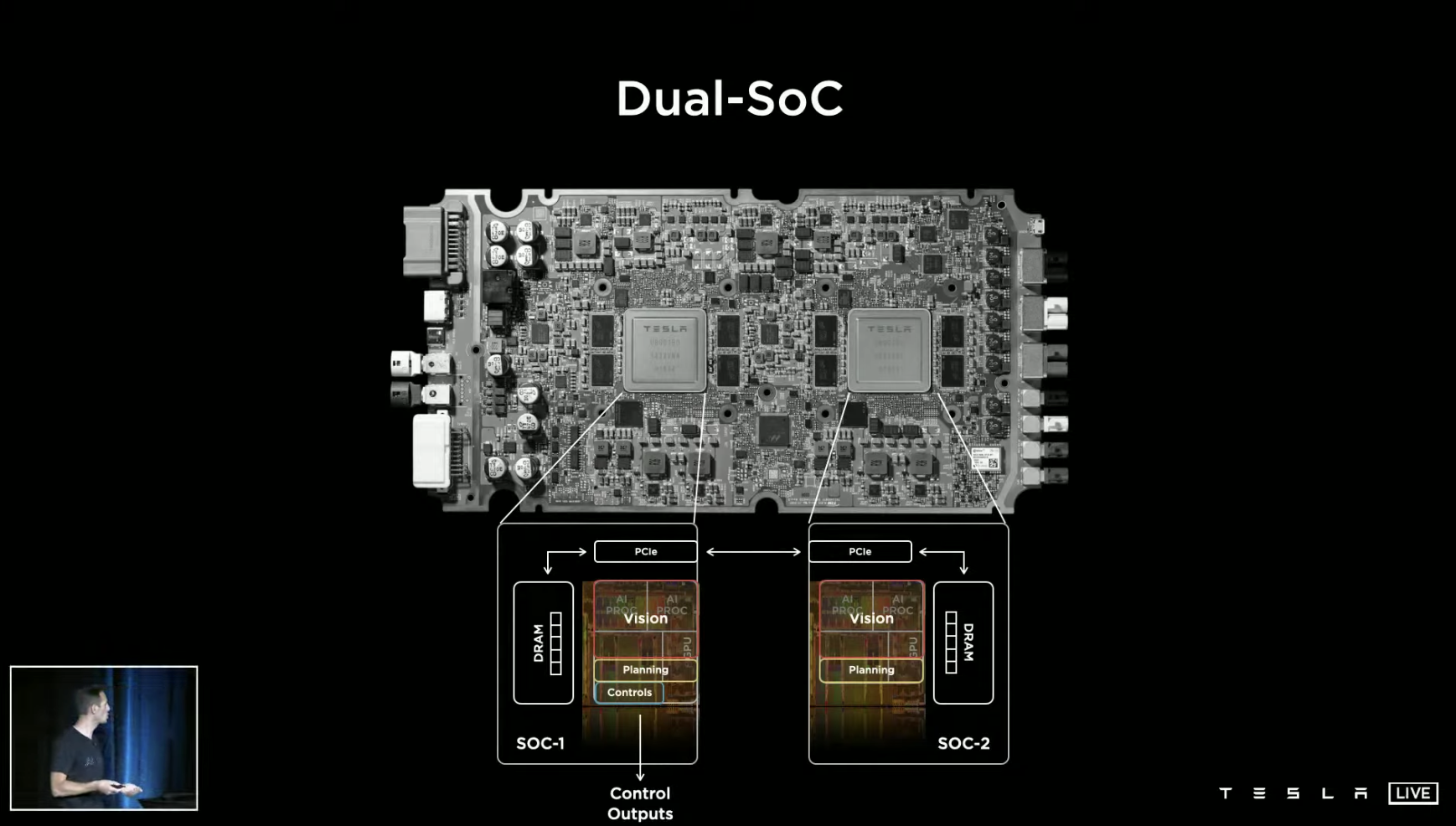
In terms of AI validation testing, Tesla has prepared over 3,000 FSD Computers, specialized device management software, and customized testing plans. Over 1 million algorithm validation tests are run every week.

For neural network training, Tesla uses three major computing centers. One center has 1,752 GPUs for automatic tagging, while the other two centers, used for training, have 4,032 and 5,760 GPUs, respectively.
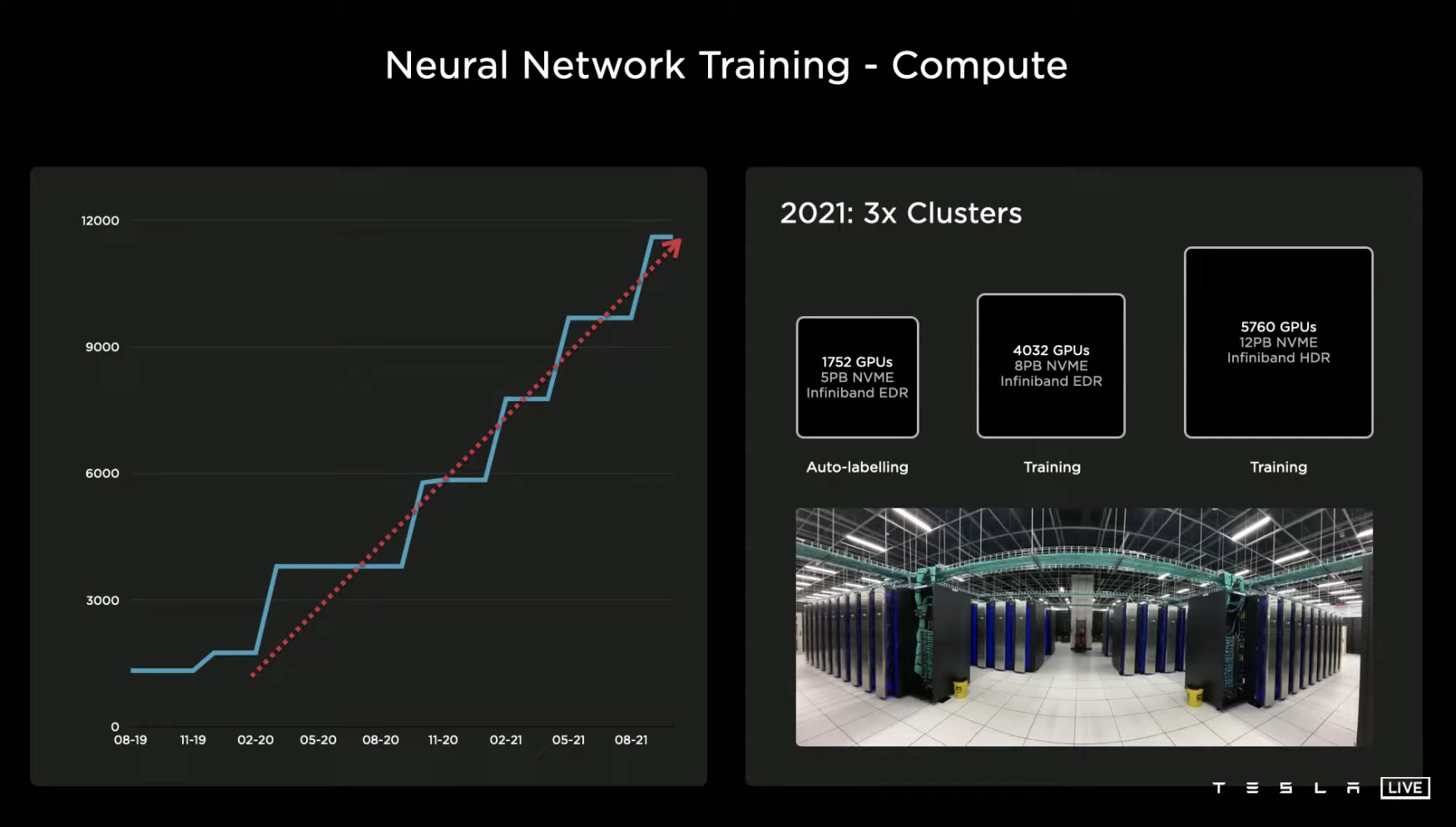
Objectively speaking, the performance of these computing centers is already quite powerful, but they are still not enough for Tesla. As a result, Tesla has designed its own hardware specifically for machine learning training.
Dedicated Supercomputers and Robots
A super fast training computer
There have been rumors about Dojo for some time now. Let’s start with the original goal of its development: the three directions were the most powerful AI training performance, the ability to drive larger and more neural networks, and high energy efficiency and low cost.

One extremely important point in the detailed design concept of the D1 chip is “dedicated chip for dedicated use,” where all aspects such as placement, bandwidth capacity, and node architecture revolve around achieving the best neural network training. Finally, the single 7nm D1 chip has a floating-point computation power of 362 TFLOPs under BF16/CFP8, and 22.6 TFLOPs under FP32.
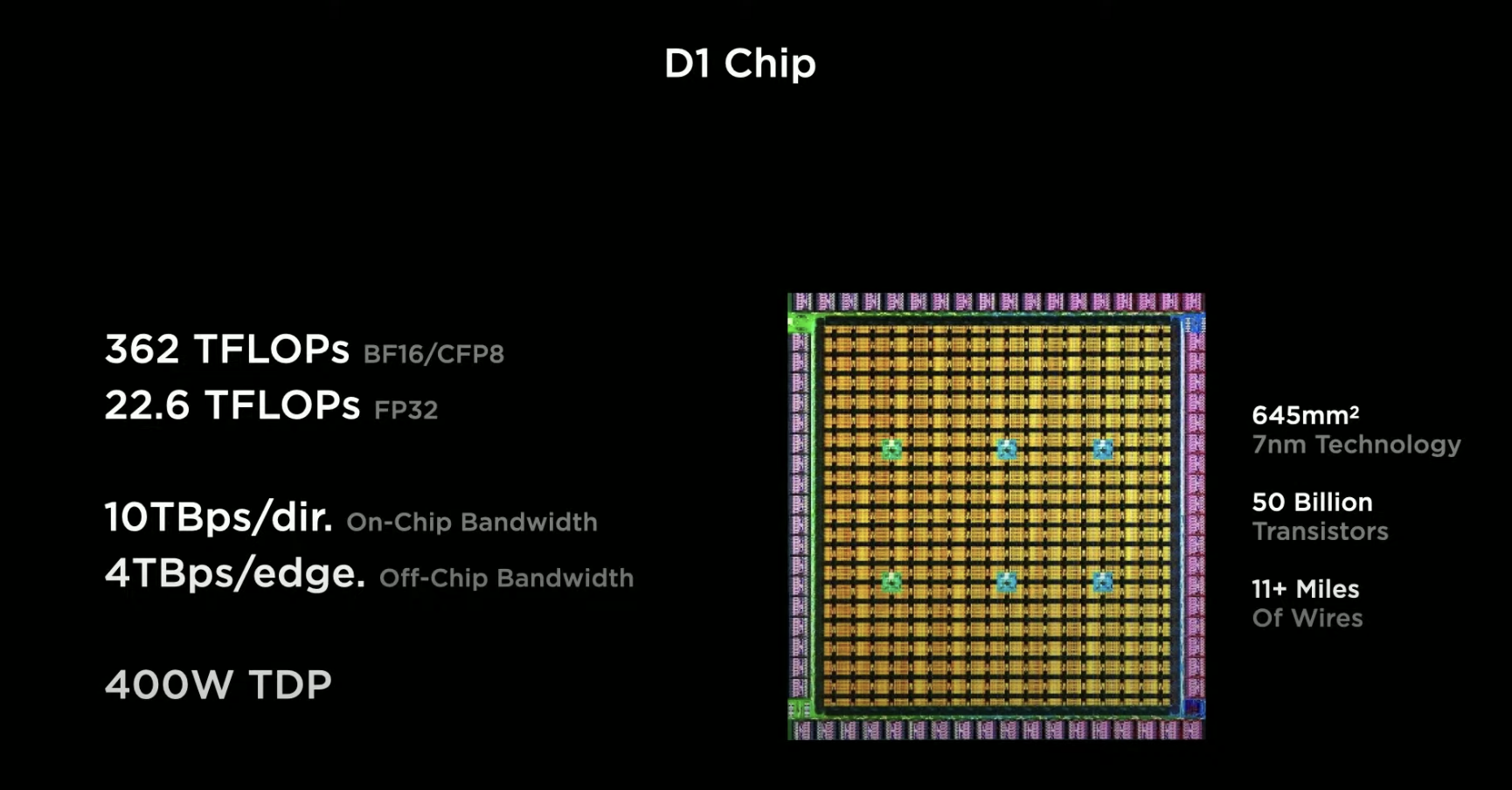 # Translation
# Translation
The computing power of one “Calculation Brick” made up of 25 D1 chips can reach 9 PFLOPs, with I/O bandwidth reaching 36 T/s and a heat dissipation capacity of 15 kW.
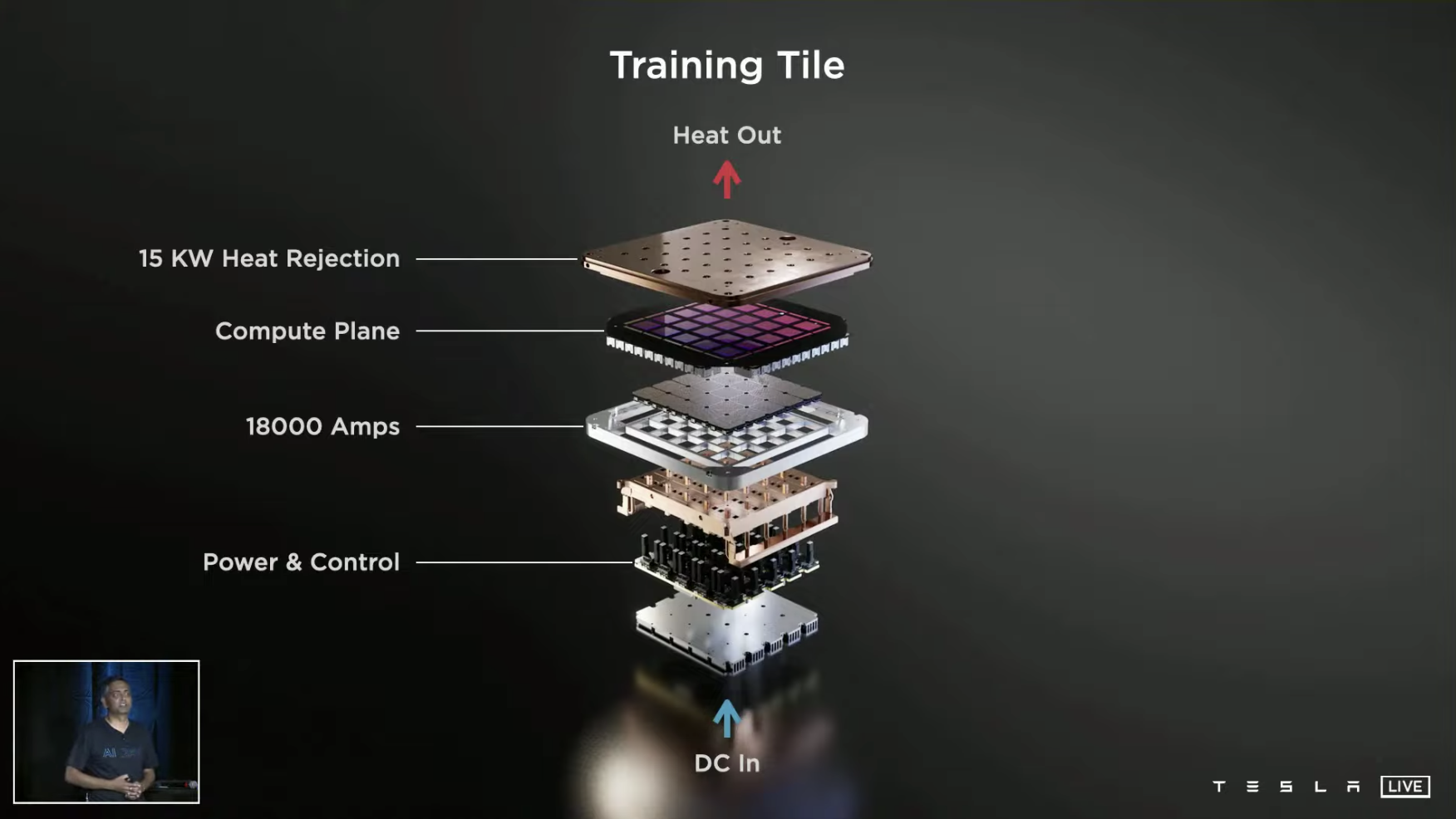
With 120 such “Calculation Bricks” in a supercomputer system, the computing power can reach 1.1 EFLOPs, for an increase in performance of 4x at the same cost, with a 30% increase in energy efficiency and an 80% reduction in footprint.

I cannot describe what this concept is anymore; I cannot understand it myself, but I am greatly impressed.
Tesla Bot
Finally, there is the robot from the beginning, with a human COS performance, and the actual Tesla Bot parameters are shown in the image.

Unexpectedly (but also not unexpected), this robot uses Autopilot cameras for visual perception and the FSD Computer for its computing core.

Therefore, there is an amazing fact: in multi-camera neural networks, neural network normalization, automatic labeling, algorithm training and other related contents, Tesla Bot has a considerable amount of pre-existing technology; although no robot has been built yet, it may already have the strongest scaling advantage among all intelligent robots in the world.
In my opinion, this is equivalent to a silent death sentence for competitors.
Conclusion
If you have already forgotten the title of the article by the time you reach this point, it means you have already agreed with the content that the title wants to convey.
In fact, Tesla’s visual perception solution can do much more than the general public thinks, and the strategy for scaling effects has already begun to appear in neural network-based visual solutions.
It must be said that Tesla did indeed hype up its capabilities very early on, but the depth and speed detection, which are the weakest aspects of visual perception, only surpassed the millimeter wave radar in the past few months, and when it will be available in China is still unknown.
As a domestic consumer, I may not experience the convenience brought by these technologies for a long time, but whether it is the implementation of the technical route or the layout of long-term strategic planning, Tesla is still in a leading position, and with the support of Dojo, this gap may widen.Then, about Tesla’s Dojo supercomputer and robots, it is another way of reducing training marginal costs through economies of scale, and the economies of scale of the two complement each other. Defeating different opponents in the same way may also be the most profound feeling that AI DAY has given me.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.