
Translation
Today, we begin a series of discussions specifically focusing on a particular machine learning problem, which is often supplemented by synthetic data: object detection. In this first article of the series, we will discuss what object detection is, where data is coming from, and how to make your network detect object bounding boxes.
Problem Setting: What is Object Detection
If you have experience in computer vision or have heard about the wonders of modern deep learning, you may be familiar with image classification problems: how to distinguish between cats and dogs?
Although this is just a binary classification (a yes/no question), it is already a very complex problem. Real-world images “live” in a high-dimensional space, with millions of features: mathematically, for example, a one-million pixel color photo is a vector of over three million numbers! Therefore, the focus of image classification is not on learning the decision boundary (separate classes) but rather on feature extraction: how can we project this huge space onto something more manageable while keeping the separation plane relatively simple?
This is precisely why deep learning has been so successful: it does not rely on hand-crafted feature like SIFT used in computer vision before, but learns its own features from scratch. The classifiers themselves are still very simple and classical: almost all deep neural networks used for classification have a softmax layer, i.e. basic logistic regression. The key is how to convert the image space into a representation that is expressive enough for logistic regression, and this is where the other parts of the network come in. If you look at some early papers, you can find examples of people learning deep neural networks to extract features and then applying other classifiers, such as support vector machines:
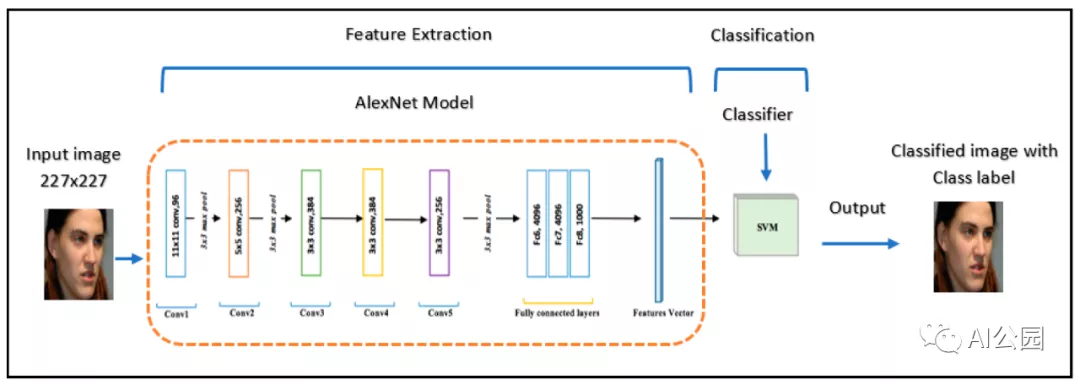
But so far, this has been rare: once we have enough data to train state-of-the-art feature extractors, doing simple logistic regression at the end is easy and sufficient. In the past decade, people have developed a plethora of image feature extractors: AlexNet, VGG, Inception, ResNet, DenseNet, EfficientNet……Translate the Chinese text in the Markdown below into English Markdown text, retaining the HTML tags inside the Markdown and showing only the corrected and improved parts in a professional manner.
To explain all of them thoroughly, relying solely on a blog post is far from sufficient. However, a common approach is to have a feature extraction backbone followed by a simple classification layer. Then you train the whole thing end-to-end on a large-scale image classification dataset, typically ImageNet, which is a massive human-annotated and curated dataset with over 14 million images and nearly 22,000 categories organized into a semantic hierarchy:

Once you’ve done this, the network has learned how to extract informative and useful features from real-world photographic images, so even if your classes don’t come from ImageNet, it typically becomes a matter of adapting to this new information. Of course, you still need new data, but it’s typically not millions of images. Of course, unless it’s a completely novel image domain like X-rays or microscopes, where ImageNet wouldn’t be of much help.
But vision doesn’t work this way. When I look around, I don’t just see a single label in my mind’s eye. I am differentiating between different objects within my field of view: I see a keyboard, my own hand, a monitor, a coffee cup, a webcam, and so on, basically all at the same time. I am able to differentiate among all of these objects from a single static image.
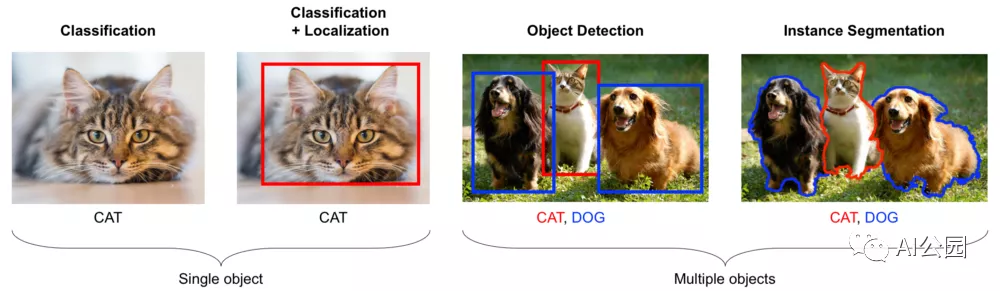
This means that we need to move beyond classification, where you assign a single label to the entire image (you can assign multiple multilabel classification models, but they’re still tagging the entire image), to other problems that require a finer-grained analysis of the objects in the image. People typically distinguish several different problems:
Classification, as we discussed above.
Classification + localization, where you assume there is a single centric object in the image and you need to locate it by drawing a bounding box around it.
Object detection, our topic for today, requires finding multiple objects in a single image and drawing boxes around them.
Finally, segmentation is a more complex problem, where you need to find the actual contours of the objects, that is, essentially dividing each pixel of the image into either an object or the background. There are also several different types of segmentation (semantic segmentation, boundary segmentation, and instance segmentation).
Explained with cats and dogs:
Mathematically speaking, this means that the output of the network is no longer just a class label. It is now several different class labels, each having an associated rectangle. The rectangle is defined by four numbers (the coordinates of two opposite corners, or one corner plus width and height), so now each output is mathematically four numbers and a class label.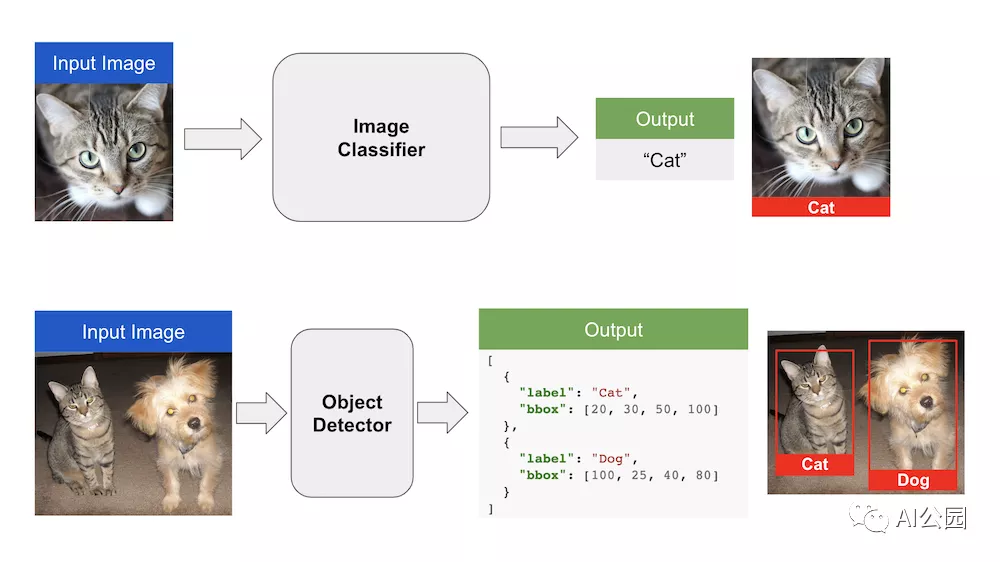
From a machine learning perspective, before we start thinking about how to solve a problem, we need to find data. The basic ImageNet dataset is not useful: it is a classification dataset, so it has labels like “Cat,” but it doesn’t have bounding boxes! Manual annotation is now a more difficult problem: you have to provide a bounding box for each object, not just click on the correct class label, and there may be many objects in a photo.
Here’s an example of annotation for a general object detection problem.
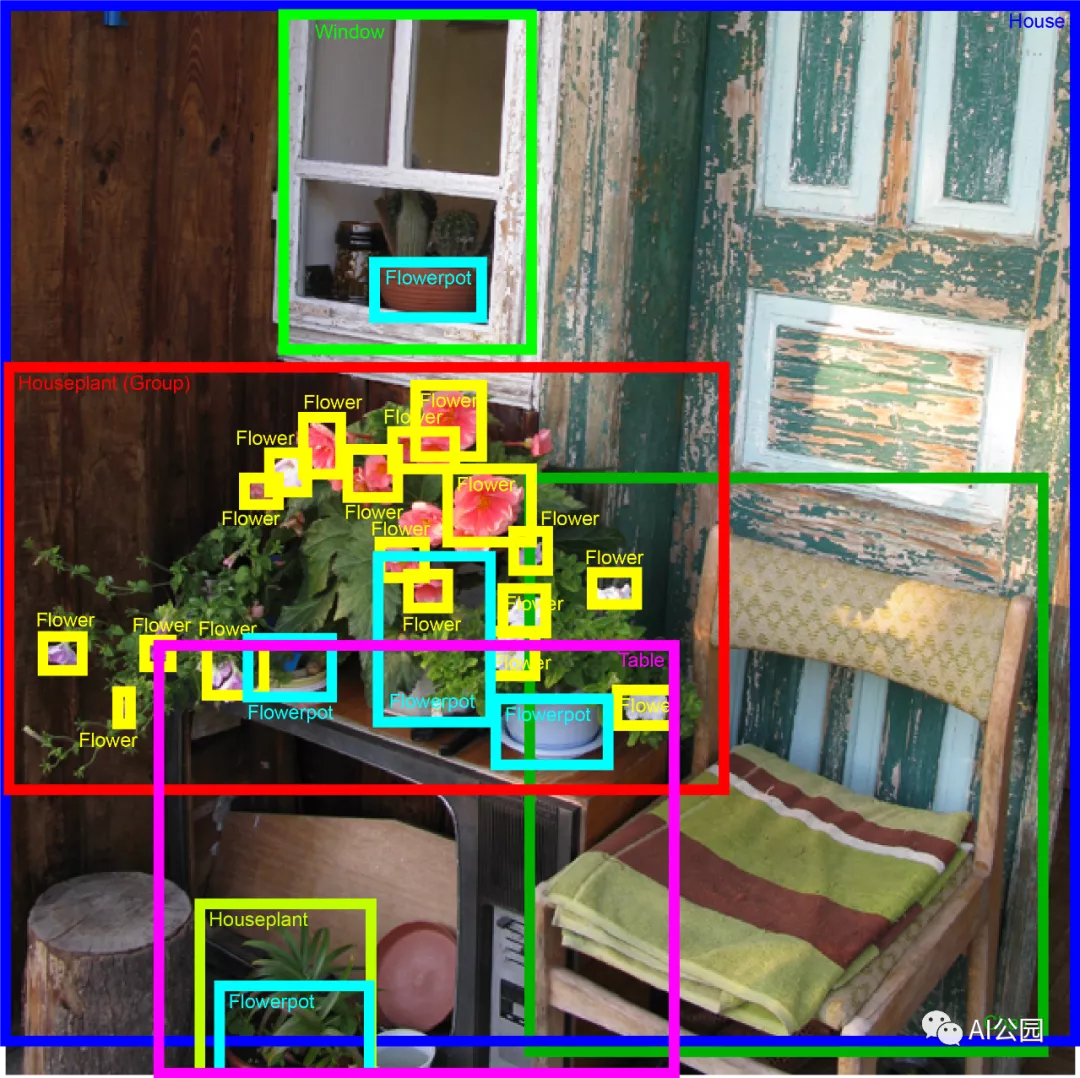
You can imagine that manually annotating an image for object detection takes several minutes, not just a few seconds like for classification. So where do large datasets like this come from?
Object Detection Datasets: Real
Let’s first look at what kinds of object detection datasets we have that use real objects and artificial annotations. First, let’s quickly review the most popular datasets.
The ImageNet dataset, as a key part of the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), is popular and was used in a series of competitions held from 2010 to 2017. The ILSVRC series has witnessed some of the most interesting advances in convolutional neural networks: AlexNet, VGG, GoogLeNet, ResNet, and other famous architectures made their debuts here.
A relatively little-known fact is that ILSVRC has also had an object detection competition all along, and the ILSVRC series was actually developed in collaboration with another famous competition, the PASCAL Visual Object Classes (VOC) Challenge, held from 2005 to 2012. These challenges also featured object detection from the very beginning, which is where the first famous dataset comes from, commonly known as the PASCAL VOC dataset. Here are some example images for the “airplane” and “bicycle” categories:

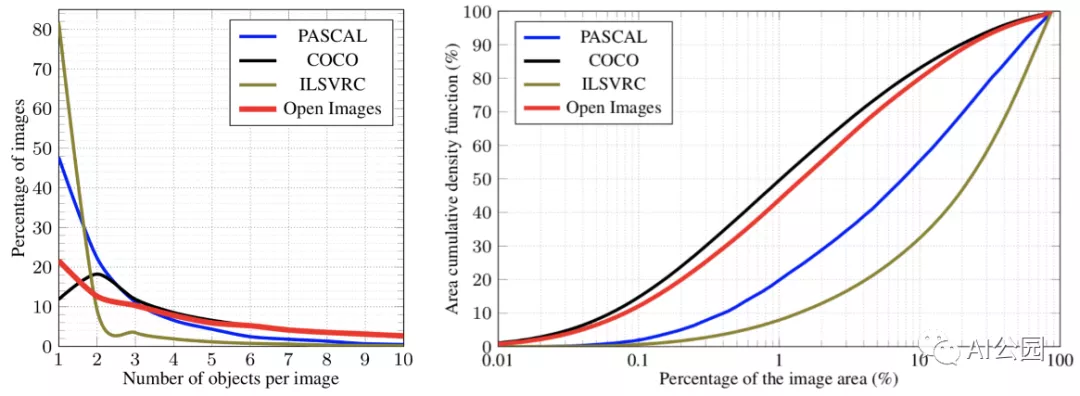
 According to today’s standards, PASCAL VOC is quite small: 20 classes, only 11,530 images, and 27,450 target annotations, which means PASCAL VOC has less than 2.5 targets per image. Targets are usually large and prominent in photos, so PASCAL VOC is an “easy” dataset. Nevertheless, for a long time, it remained one of the largest manually annotated object detection datasets and was used by default in hundreds of object detection papers.
According to today’s standards, PASCAL VOC is quite small: 20 classes, only 11,530 images, and 27,450 target annotations, which means PASCAL VOC has less than 2.5 targets per image. Targets are usually large and prominent in photos, so PASCAL VOC is an “easy” dataset. Nevertheless, for a long time, it remained one of the largest manually annotated object detection datasets and was used by default in hundreds of object detection papers.
The next step in terms of scale and complexity is Microsoft Common Objects in Context (Microsoft COCO) dataset. So far, it has surpassed 200K labeled images with 1.5 million target instances, providing not only bounding boxes but also (fairly crude) segmentation contours. Here are some sample images:

As you can see, targets are now more diverse, and they can come in very different sizes. This is actually a big problem for object detection: it is difficult to make a single network that can detect objects of vastly different sizes at the same time, which is why MS COCO has proven to be a more challenging dataset than PASCAL VOC. Nevertheless, the dataset is still very relevant, with competitions held each year in object detection, instance segmentation, and other tracks.
The last general object detection dataset that I want to discuss is currently the largest available dataset: Google’s Open Images Dataset. So far, they have reached Open Images V6, with around 1.9 million images and 16 million bounding boxes over 600 object classes. This is equivalent to 8.4 bounding boxes per image, indicating a complex scene and a more evenly distributed quantity of objects:
These example images look interesting, diverse, and sometimes very complex:

 Actually, the reason why Open Images became possible is because of the progress in object detection itself. As mentioned above, manually drawing bounding boxes is very time-consuming. Fortunately, to some extent, existing object detectors have become so good that we can delegate the task of drawing bounding boxes to machine learning models and only use humans to verify the results. In other words, you can set the model to a relatively low sensitivity threshold so that you don’t miss any important information, but there may be many false positives. Then manually annotate and reject incorrect bounding boxes.
Actually, the reason why Open Images became possible is because of the progress in object detection itself. As mentioned above, manually drawing bounding boxes is very time-consuming. Fortunately, to some extent, existing object detectors have become so good that we can delegate the task of drawing bounding boxes to machine learning models and only use humans to verify the results. In other words, you can set the model to a relatively low sensitivity threshold so that you don’t miss any important information, but there may be many false positives. Then manually annotate and reject incorrect bounding boxes.
As far as I know, this paradigm shift occurred around 2016 after Papadopoulos et al.’s paper. It’s easier to manage, which is why Open Images became possible, but there is still a lot of work to be done for human annotators, so only giant companies like Google can provide such a large-scale object detection dataset.
Of course, there are more object detection datasets, usually used for more specific applications: these three cover the main datasets for general object detection. But wait, this is a blog about synthetic data and we haven’t said a word yet! Let’s address that.
Object Detection Datasets: Why Synthetic Data?
With datasets like Open Images, the main question becomes: why do we need synthetic data for object detection? Open Images looks almost as big as ImageNet, and we haven’t heard much about synthetic data for image classification.
For object detection, the answer lies in the details and specific use cases. Yes, Open Images is large, but it doesn’t cover everything you might need. A fitting example: suppose you are building a computer vision system for an autonomous car. Sure, Open Images has the “Car” category, but you need more detail: different types of cars in different traffic situations, street lights, all kinds of pedestrians, traffic signs, and so on. If you only need an image classification problem, then you can create your own dataset for each new class containing a few thousand images, manually label them, and adjust the network for the new class. It’s not that easy to work with in object detection, especially segmentation.
Consider the latest and largest real-world autonomous driving dataset: Caesar et al.’s nuScenes, which, by the way, has been accepted by CVPR 2020. They created a complete dataset consisting of 6 cameras, 5 radars, and 1 lidar, and fully annotated it with 3D bounding boxes (which are the new standard for moving toward 3D scene understanding) and human scene descriptions. Here’s a sample of the data:
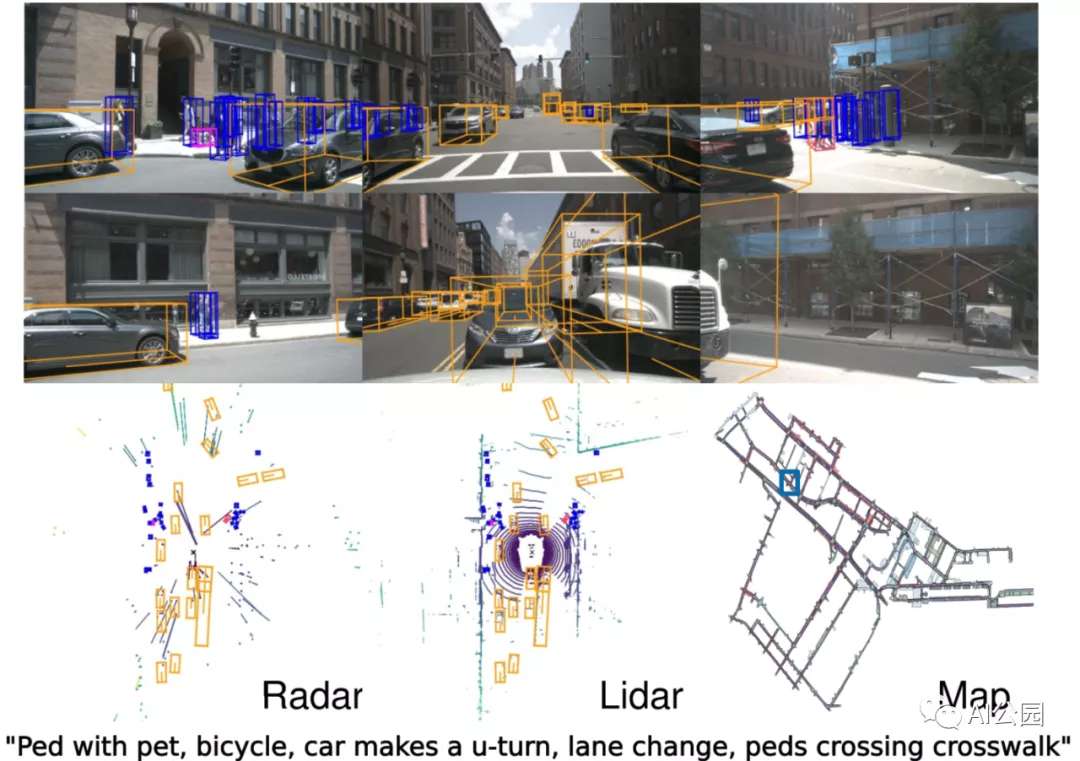
All of this was accomplished in the video! The nuScenes dataset contains 1000 scenes, with keyframe sampling occurring every 20 seconds at a frequency of 2Hz, resulting in a total of 40000 very similar 40 annotated images (from the same scene). Labeling this type of data is a massive and expensive undertaking.
Compare this to the ProcSy autonomous driving synthetic dataset. It features pixel-perfect segmentation (using synthetic data, there is no distinction, you can simply request segmentation bounding boxes), built city scenes and traffic with depth maps using CityEngine, which were then rendered using Unreal Engine. It looks like this (with segmentation, depth, and occlusion maps):

In the paper, different segmentation models were compared for performance under adverse weather conditions and other factors that may complicate the problem. For this purpose, they only needed a small sample of 11,000 frames, which you can download from the website above (by the way, the compressed file is 30GB). They report that this dataset was randomly sampled from 1.35 million available road scenes. But the most important part is that the dataset is program-generated, so it is essentially a potential infinite stream of data that you can alter the map, traffic type, weather conditions, etc.
This is the main feature of synthetic data: once you invest in creating (or more accurately, finding and adjusting) 3D models of the target you are interested in, you can have as much data as possible. If you make extra investments, you can even turn to full-size interactive 3D worlds, but that’s another story.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.