
Introduction
In recent years, autonomous driving technology and its application have become very hot topics in the technology and industrial fields. Every year, traffic accidents cause economic losses equivalent to about 600 billion US dollars globally. Autonomous driving technology can improve safety, increase the efficiency of the transportation system, and provide users with a safer and more efficient driving experience. In addition to these driving needs, the rapid development of autonomous driving technology in recent years is also inseparable from another key technology, which is artificial intelligence, specifically deep learning. Autonomous driving is a complex technology, and its core includes sensor perception, behavior decision-making, high-definition maps, massive data, high-performance computing platforms, and more. Deep learning has made a breakthrough in sensor perception, which has greatly promoted the development of autonomous driving technology.
Deep learning is a branch of the field of machine learning. In the field of machine learning, there is an unwritten rule: data is king. Without a certain amount of high-quality data, even the best models cannot achieve good results. However, how much data is needed is a difficult question for researchers to answer. With the rise of deep learning technology, we have a clearer understanding of this issue. If it were not for the large-scale ImageNet image database and the image recognition competition based on ImageNet, the stunning performance of the AlexNet algorithm might not have existed, and deep neural networks might not have dominated the field of computer vision perception in recent years, nor would there have been widespread artificial intelligence applications. Therefore, large-scale high-quality data is very important for current artificial intelligence applications.
For autonomous driving technology based on artificial intelligence, data is also one of the core factors for success. Collecting and organizing massive amounts of data is a huge project. If each research institution builds its own database, it will inevitably consume a lot of time and money, and it will not be conducive to the horizontal and vertical comparison of various technologies. Therefore, constructing a publicly available large-scale dataset and using it as a basis for standardized testing (benchmarking) has become an industry consensus. Against this background, as one of the leaders in the field of autonomous driving, Waymo company publicly released a large-scale autonomous driving database in 2020, called Waymo Open Dataset.
Waymo Autonomous Driving Algorithm ChallengeThere are a total of 1150 scenes in the Waymo database, each lasting 20 seconds and including synchronized LiDAR and visible light cameras. These scenes were collected from open roads in different cities and exhibit great diversity. Moreover, the database provides over 12 million high-quality object annotations, which are valuable resources for deep learning algorithms and was the most time-consuming step in constructing the database. Compared to other databases for autonomous driving applications, the Waymo database is unparalleled in terms of data scale, quality, and diversity.
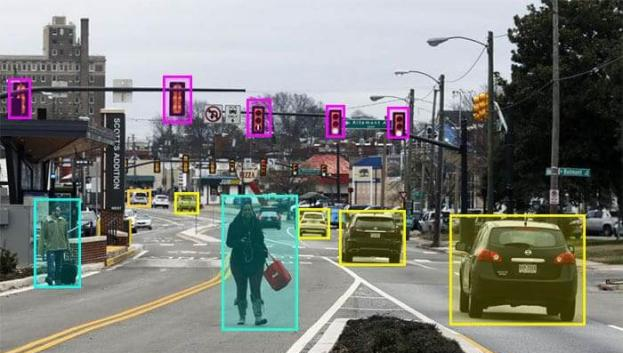
In addition to the database itself, Waymo also organizes autonomous driving algorithm challenges, attracting top research institutions from around the world to participate and partnering with top international conferences in computer vision and machine learning, such as CVPR, to release competition results, introduce winning teams, and detail their algorithms. Waymo’s challenges have become the beacon for autonomous driving research, with industry professionals discussing, researching, and experimenting with the winning algorithms to drive further industry development. This year’s Waymo challenge includes four tasks: dynamic prediction, association prediction, real-time 2D detection, and real-time 3D detection. The latter two tasks correspond to the bottom-level perception tasks for autonomous driving. As shown in Figure 1, the 2D detection task involves detecting the 2D bounding boxes of objects in images, while the 3D detection task involves detecting the 3D bounding boxes of objects in LiDAR point clouds.
As mentioned earlier, deep learning technology first made significant progress in computer vision, with algorithmic maturity for detecting 2D objects in images and many practical applications. Unlike 2D images, LiDAR can accurately measure the distance and 3D shape of objects and is less affected by weather and environment. This is a critical feature for autonomous driving, and in recent years, academia and industry have gradually turned their attention to 3D object detection algorithms based on LiDAR. Unlike the pixel arrangement format used for 2D images, LiDAR data is a 3D point cloud, with density decreasing with distance. Moreover, while 2D images use perspective coordinates, 3D point clouds typically use Bird’s Eye View (BEV) coordinates. These differences make it difficult to apply deep neural networks designed for image data directly to 3D point cloud data. Therefore, while LiDAR is essential for autonomous driving, the design of its perception algorithm still faces significant challenges.
 Since the publication of VoxelNet in 2017, great progress has been made in object detection based on laser point clouds. Major research institutions have proposed their own algorithms, and the reported detection rates continue to improve. Waymo’s 3D object recognition challenge provided these algorithms with a fair comparison opportunity. Especially in this year’s challenge, the evaluation of algorithm speed was added, and it was stipulated that the execution time of all models must be less than 70 milliseconds per frame to be shortlisted. This requirement is closer to real-world scenarios and closer to landing applications. This is also to encourage participants to make efforts in effectively utilizing computing resources. After winning 4 out of 5 challenges in the first competition in 2020, the team from Horizon Robotics once again won the championship, surpassing companies and universities such as Smartmore, University of Texas, etc. Generally speaking, the difficulty of a machine learning competition is the highest in the first few years of its release. As participants become more familiar with the data, a large number of parameter adjustments can be made to improve the algorithm’s performance, but this can lead to overfitting to some extent. In short, the algorithm performs well on this database, but there will be a significant performance decline when processing scenes outside this database. Therefore, winning the first place in the previous two competitions has shown that the Horizon team has a profound and unique understanding of perception algorithms for autonomous driving. Let us now analyze in detail how this winning algorithm works.
Since the publication of VoxelNet in 2017, great progress has been made in object detection based on laser point clouds. Major research institutions have proposed their own algorithms, and the reported detection rates continue to improve. Waymo’s 3D object recognition challenge provided these algorithms with a fair comparison opportunity. Especially in this year’s challenge, the evaluation of algorithm speed was added, and it was stipulated that the execution time of all models must be less than 70 milliseconds per frame to be shortlisted. This requirement is closer to real-world scenarios and closer to landing applications. This is also to encourage participants to make efforts in effectively utilizing computing resources. After winning 4 out of 5 challenges in the first competition in 2020, the team from Horizon Robotics once again won the championship, surpassing companies and universities such as Smartmore, University of Texas, etc. Generally speaking, the difficulty of a machine learning competition is the highest in the first few years of its release. As participants become more familiar with the data, a large number of parameter adjustments can be made to improve the algorithm’s performance, but this can lead to overfitting to some extent. In short, the algorithm performs well on this database, but there will be a significant performance decline when processing scenes outside this database. Therefore, winning the first place in the previous two competitions has shown that the Horizon team has a profound and unique understanding of perception algorithms for autonomous driving. Let us now analyze in detail how this winning algorithm works.
Detailed Analysis of the Horizon Real-Time 3D Detection Algorithm
This Waymo real-time 3D detection challenge evaluated models in terms of both accuracy and speed, and only models with an execution time of less than 70 milliseconds per frame could be shortlisted. Based on the algorithm that participated in the 2020 competition, the Horizon team further optimized the model’s accuracy and speed, and submitted two models. One model (AFDetV2) ranked first in terms of detection accuracy (73.12 mAPH/L2, taking 60.06 milliseconds per frame), and the other model (AFDetV2-base) won first place in terms of speed while maintaining a certain level of accuracy (72.57 mAPH/L2, taking 55.86 milliseconds per frame). It was crowned the “most efficient model.”
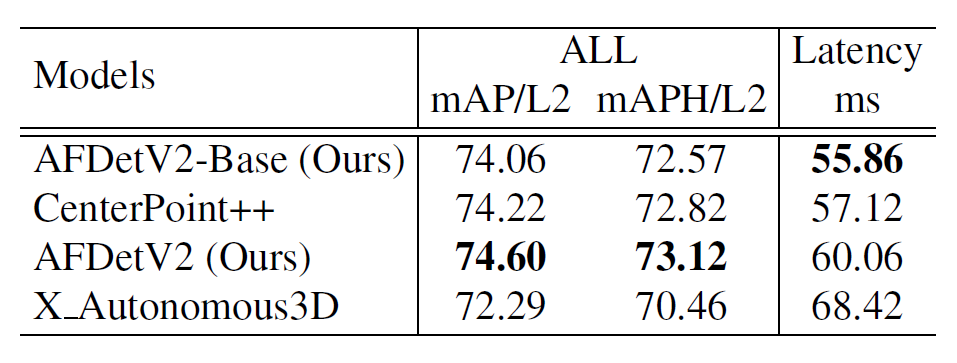 In this competition, Horizon team optimized the algorithm in three aspects: model, training, and hardware implementation. In terms of the model, they adopted the mainstream Anchor-Free detection algorithm while deeply analyzing the use of two-stage networks. Based on sufficient comparison, Horizon team ultimately chose the Single-stage network, despite the fact that most models in the industry (including CenterPoint and PV-RCNN) use two-stage networks to achieve higher accuracy. In the detection head of this Single-stage network, Horizon team innovatively added an IoU branch for predicting confidence in object localization and used its prediction results to weight the scores of the classifier, effectively solving the mis-alignment between the classification and localization branches. With this improvement, Horizon team’s Single-stage network can achieve the same or higher accuracy as a two-stage network with less computation, greatly improving the model’s efficiency. Based on these improvements, Horizon team also made improvements in 3D feature extraction, expanding the neural network’s perception field, predicting the quality of bounding boxes, and predicting key points. In terms of training, data augmentation and random weight averaging are used to further improve the model. The combined use of these techniques has significantly increased the detection accuracy of the original model (by more than 4APH/L2), while the increased computation can be ignored. In terms of hardware implementation, Horizon team used GPUs to parallelize the processing of 3D point clouds, achieving a speed increase of over 20% (reducing the running time by 17ms).
In this competition, Horizon team optimized the algorithm in three aspects: model, training, and hardware implementation. In terms of the model, they adopted the mainstream Anchor-Free detection algorithm while deeply analyzing the use of two-stage networks. Based on sufficient comparison, Horizon team ultimately chose the Single-stage network, despite the fact that most models in the industry (including CenterPoint and PV-RCNN) use two-stage networks to achieve higher accuracy. In the detection head of this Single-stage network, Horizon team innovatively added an IoU branch for predicting confidence in object localization and used its prediction results to weight the scores of the classifier, effectively solving the mis-alignment between the classification and localization branches. With this improvement, Horizon team’s Single-stage network can achieve the same or higher accuracy as a two-stage network with less computation, greatly improving the model’s efficiency. Based on these improvements, Horizon team also made improvements in 3D feature extraction, expanding the neural network’s perception field, predicting the quality of bounding boxes, and predicting key points. In terms of training, data augmentation and random weight averaging are used to further improve the model. The combined use of these techniques has significantly increased the detection accuracy of the original model (by more than 4APH/L2), while the increased computation can be ignored. In terms of hardware implementation, Horizon team used GPUs to parallelize the processing of 3D point clouds, achieving a speed increase of over 20% (reducing the running time by 17ms).
Model Optimization
Lightweight Point Cloud Feature Extraction
In any object detection model, feature extraction is crucial to the final performance of the model and is often the most computationally demanding step. Especially for laser point clouds, which are unstructured data, it becomes even more critical to use convolutional neural networks effectively to extract features. In Horizon’s approach, the point cloud data is transformed into a fixed-range, fixed-size 3D grid (corresponding to X, Y, and Z in world coordinates). For each grid, the reflected intensity of the points falling into it is averaged to represent the feature value of that grid. It should be noted that this 3D grid is very sparse, with many grids having no data points. If traditional 3D convolution is used for feature extraction, it will be very inefficient. Therefore, as shown in Figure 3, sparse 3D convolution (spConv) and submanifold sparse convolution (subM) are used for multi-stage feature extraction in Horizon’s model. Additionally, Horizon team reduced the number of residual blocks in the front end and the number of sampling convolutions in the Z direction to balance accuracy and speed.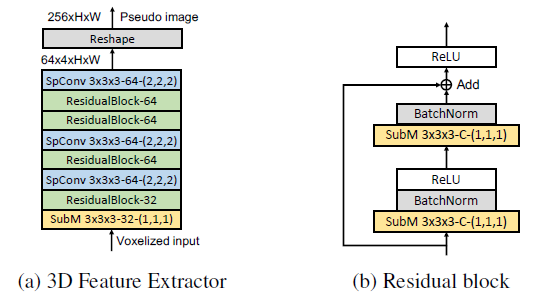
Expanding the receptive field of neural networks
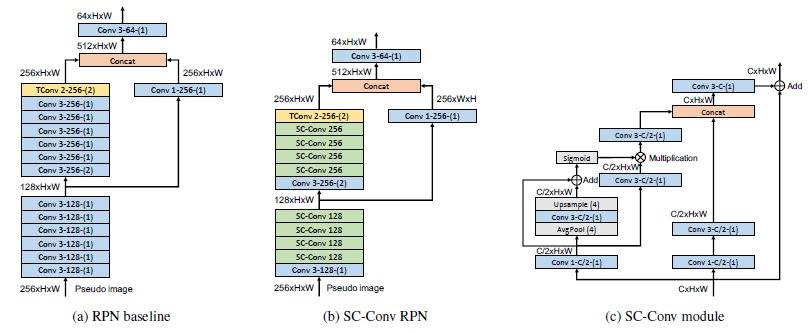
Receptive field is an important indicator for measuring the feature extraction capability of neural networks. A larger spatial receptive field can not only cover objects of different sizes, but also extract contextual features of the surrounding environment. This contextual semantic information is very helpful for detecting partially occluded or distant objects. Therefore, in the backbone network for object detection, Horizon Robotics team uses a self-calibrated convolution (SC-Conv) operation to expand the spatial receptive field and introduces attention mechanisms in spatial and feature channels, as shown in (a) and (b) in Figure 4. It is worth mentioning that with clever parameter settings (as shown in Figure 4c), these additional operations do not increase the computational cost, but improve the accuracy of the entire detection model.
Additional prediction branches
Compared with last year’s model, the Horizon Robotics team has added two prediction branches in this model: IoU confidence prediction and key point prediction. IoU stands for Intersection-over-Union, which is used to measure the degree of overlap between two object boxes. When the predicted object box and the actual object box have a high degree of overlap, the IoU value is large, and vice versa. Therefore, IoU is usually used to measure the quality of predicted object boxes. In a standard object detection network, the prediction branch outputs the confidence and corresponding object box of the object, but this confidence only represents the probability of the current location containing an object of a certain category, and does not represent the quality of the object box, which is the often mentioned mismatch problem between classification and localization tasks. Therefore, by adding a prediction for the confidence of the object box and using it to weight the classifier score, the matching degree of the classification and localization tasks can be improved, thereby improving the accuracy of both tasks.
In the localization branch, in addition to predicting the center point and length, width, and height of the object box, an additional branch is added to predict key points, such as the corner points of the object box. This can help the neural network better learn the edge information of objects, because the objects seen in point clouds often only have partial surfaces, and the center point is not in the visible point cloud. After adding the corner points of the 3D box, the model can better fit the training data, thereby improving the accuracy of localization.
![Figure 5 All prediction branches]### Training Optimization
For training, the first step is to use data augmentation techniques to increase the diversity of training samples, such as randomly selecting labeled samples, randomly flipping X and Y coordinates, and global rotation and scaling. These operations are very helpful for reducing neural network overfitting and improving its generalization ability. In addition, the Horizon training method also includes a random weight averaging operation (Stochastic Weights Averaging, SWA). Specifically, after normal model training is completed, the learning rate is reduced to 1/10 of the original, and 5 more rounds (epochs) are trained. The five models obtained from these 5 rounds of training are averaged, and then trained for another round to determine the parameters of Batch Normalization. SWA improves the overall performance of the model by about 0.2 mAPH/L2, with a greater than 0.5 APH/L2 improvement in the “pedestrian” category, demonstrating its effectiveness. Moreover, the model after SWA can further reduce the risk of overfitting and has better generalization ability. These optimized training processes do not increase any computational overhead during the prediction phase and can therefore be considered a “free lunch.”
Hardware Implementation Optimization
This step is also crucial for optimizing the speed of the model. As mentioned earlier, to convert point cloud data into three-dimensional grid data, additional operations are required, such as calculating the grid to which each point belongs and calculating the average feature values of multiple points within the grid. When using multiple frames of point clouds, the point clouds also need to be converted to a different coordinate system. These operations are necessary preprocessing operations before the data is fed into the neural network. However, in the past, due to a lack of parallel processing algorithms, these operations became one of the bottlenecks that affected the speed of the entire model. To address this issue, the Horizon team improved the algorithm for these operations and wrote dedicated code to parallelize them within the GPU, greatly speeding up the point cloud preprocessing.
The Driving Force Behind Horizon’s Industry Advancements
Real-time object detection in open road scenarios is one of the core technologies of autonomous driving. Currently, both in academia and industry, the mainstream algorithm for real-time 3D object detection uses a single-stage, anchor-free strategy. The Horizon team carefully optimized every aspect of the algorithm, making it both highly accurate and low-latency.
High Accuracy.### Horizontal’s Algorithm
The algorithm from Horizontal team participating in the competition can detect multiple objects under open road conditions, including vehicles, pedestrians, and cyclists. The evaluation metric reaches 73 mAPH/L2, and the algorithm can easily be extended to more object categories without major modifications. Although the evaluation metric still has a little way to go before reaching a perfect score of 100, it’s important to note that the metric takes into account all objects within a 75-meter radius in all directions. For autonomous driving applications, it’s often unnecessary to detect all objects within the scene. Typically, only stable detection of objects that influence driving behavior is required. For example, pedestrians outside of a 50-meter radius while the vehicle is driving at low speeds, or pedestrians outside of the vehicle’s current trajectory, are not likely to affect the driving behavior of the vehicle, so they can be excluded from the evaluation metric. Therefore, evaluation metrics such as those used in the Waymo Challenge are actually more challenging than practical applications. Currently, there are also some safety test plans for autonomous driving vehicles in the industry, such as the test plan proposed by the authoritative safety certification agency Euro-NCAP (European New Car Assessment Programme/Centre). These plans define various scenarios that are likely to lead to traffic accidents and test autonomous driving vehicles under closed-road conditions for these scenarios. Based on my experience, Horizontal’s algorithm can achieve a 73 mAPH/L2 under general open scenarios, which should pass Euro-NCAP’s testing requirements.
Low Latency
Horizontal’s algorithm can achieve low latency of less than 60ms while ensuring high precision. This speed is already very impressive even without further product-level algorithm optimization, meeting the real-time requirements of autonomous driving applications. In addition, all parts of Horizontal’s 3D object detection algorithm, from pre-processing of raw data to feature extraction of point clouds, to the main network and prediction branch, can be accelerated by parallel computing on GPUs, laying a good foundation for implanting the algorithm into on-board chips in future.
In conclusion, this raises a question for us: “How should solution companies promoting progress in the autonomous driving industry operate?”
Previously, the market’s perception of Horizontal was as an “AI chip company” and it seemed that hardware and software were naturally separated in the autonomous driving sector. However, this is not the case. Horizontal not only focuses on the automatic driving chips but also has a deep algorithm capability, which is something they have always emphasized. Their aim is to empower original equipment manufacturers (OEMs), and fully empower them with software and hardware technology solutions to assist automobile manufacturers’ intelligent transformation.
There are two significant values for the entire industry:
- To practice diverse development models for autonomous driving hardware companies.# The Importance of a Diverse Approach to Autonomous Driving
Since the establishment of multiple solution companies in 2014, the autonomous driving industry has seen a trend towards companies becoming more specialized in certain areas. However, this can cause problems for companies that do not diversify their approach, as hardware companies with limited algorithm capabilities can hinder their future development.
Contrary to misconceptions, companies such as Horizon Robotics, Huawei, and NVIDIA have successfully diversified their approach to the industry, combining both hardware and software development to maintain their competitiveness.
Horizon Robotics offers several benefits to car manufacturers who partner with them, including rapid development of assisted driving capabilities, an opportunity for car manufacturers to improve their algorithm capabilities, and overall shorter development times.
The importance of mastering a variety of technologies in the field of autonomous driving is critical to the growth and success of solution-based companies such as Horizon Robotics, who have a core focus on developing the underlying technologies that will help transform the automobile industry into an intelligent one.
The Waymo Autonomous Driving Challenge has provided a fair and open platform for research institutions to test their capabilities in autonomous driving technology since its inception in 2020. This year’s challenge places a greater emphasis on system speed, bringing it closer to practical applications. The Horizon Robotics team has won first place in the 3D object detection task for the second consecutive year, proving their global leadership in this field and their strong technical and engineering capabilities. Furthermore, their solution incorporates many of the most advanced object detection technologies and innovative designs, making it a valuable resource for researchers to further advance in autonomous driving perception algorithms.
While there is still much to be done to further advance autonomous driving technology, progress depends on continued research and development. It is important for research institutions to participate in the field and offer more precise and efficient perception algorithms to ensure safer and more convenient travel for all.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.