*Author: Yanknow
At the “First Yanknow Automotive Annual Meeting”, Professor Baijie, Chairman of Suzhou Millimeter Wave Radar had something urgent to attend to, so he was represented by Li Sen from Tongji University, who presented on “The Integration and Advancements of Millimeter Wave Radar and Camera Technologies” as it relates to the cutting-edge technology of sensor fusion for ADAS, autonomous driving, and intelligent cabins, and shared the company’s 4D millimeter wave radar solutions related to deep learning.

Why do we need multiple sensor fusion?
Li Sen first introduced the basic concept of multi-sensor fusion, traditional methods of fusing radar and camera, and recent applications and future trends of radar and camera in deep learning.
He said that driving or traffic often encounters complex weather conditions, such as heavy rain, fog, sandstorms, strong light, and night, which are very adverse to images and lidar. It is difficult to cope with a single sensor because one sensor cannot handle all situations.
For example, some automatic driving tests or more mature Tesla intelligent driving accidents, due to the failure of their sensor system, have paid a relatively painful price. Therefore, sensor fusion is a necessary condition for building a stable perception system.

Levels and Structure of Multi-Sensor Data Fusion
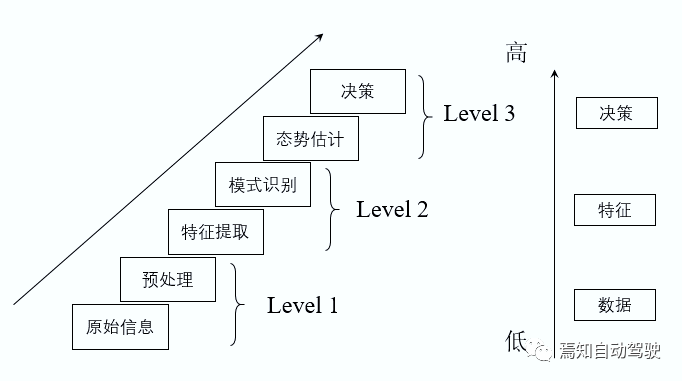
What is sensor fusion? Li Sen said that first, according to the estimation results of data and states from different sensors, different sensors such as images, lidar, and millimeter wave radar are used to fuse into the central processor for information complementarity, to obtain the best neutralization solution. Based on the different levels of sensor processing obtained by the center:
First, starting from the raw information belongs to the data-level scope;
Then, it is feature recognition after data processing, which belongs to the feature-level scope;
Finally, it is danger estimation and final decision, which belongs to the decision-level fusion.
Specifically, decision-level fusion is to preprocess and extract features from millimeter wave radar and image radar to obtain target position and classification information. Afterwards, the unified analysis and judgment are carried out in the processor, including methods such as Kalman filtering and weight discrimination. The feature vector and feature matrix are obtained from data preprocessing, which are then fused by the processor.## Data-level Fusion
Data-level fusion refers to the process of unifying all original data into a processor, performing final data synchronization and then data processing. Currently, most solutions focus on target-level fusion, while future development will involve multi-level feature fusion. Due to the large amount of data, data-level fusion is currently limited by precontrollers or bandwidth constraints.
From the perspective of local sensor data processing, it is mainly divided into centralized, distributed, and hybrid structures.
Centralized structure: Similar to data-level processing, all sensor information is sent to the domain controller for data correlation, measurement fusion, target tracking, and finally decision-making. Its advantage lies in the high accuracy of data processing, but the disadvantage is that a large amount of data can easily cause communication overload and require higher performance from controllers.
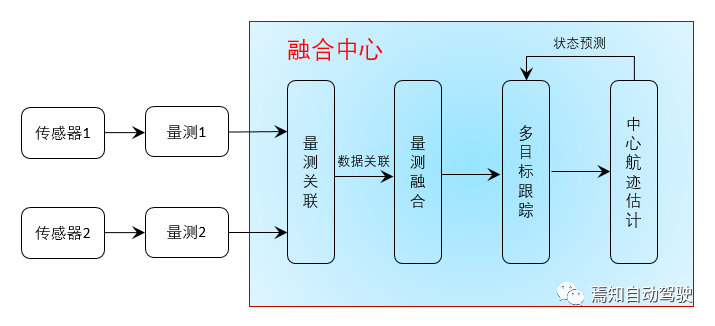
Distributed structure: In fusion, each sensor will perform local target observation processing of its own results, and the domain controller will receive the locally completed multi-target tracking trajectory information. Its advantage is that it requires low communication bandwidth and has fast computing speed, but the disadvantage is that the tracking accuracy is much lower than centralized processing.
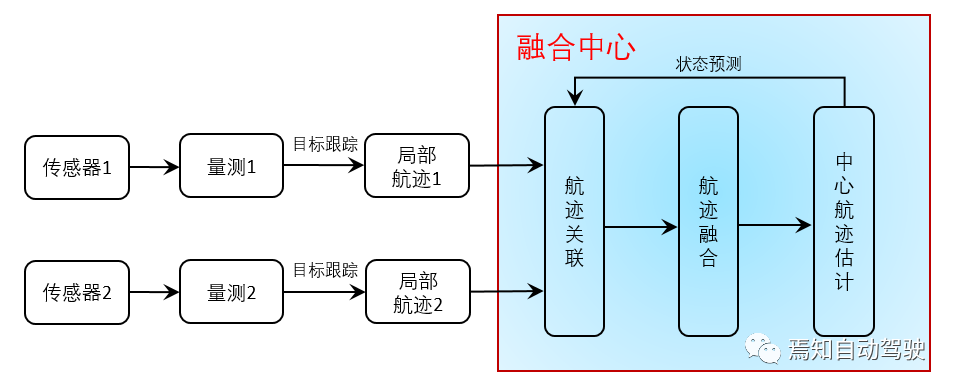
Hybrid structure: According to different data requirements, a hybrid structure is formed, combining the advantages of centralized and distributed structures and making up for their shortcomings.
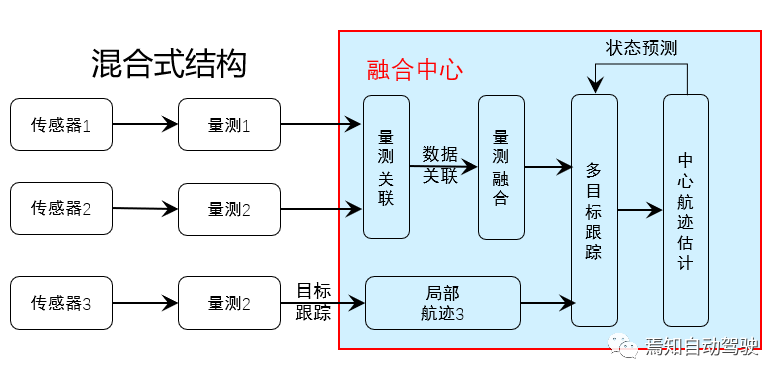
Currently, the majority of structures used are hybrid. Distributed sensors perform data processing separately, and after obtaining the target information list, fusion is performed, such as millimeter wave radar, which produces processed point clouds, and laser radar images.
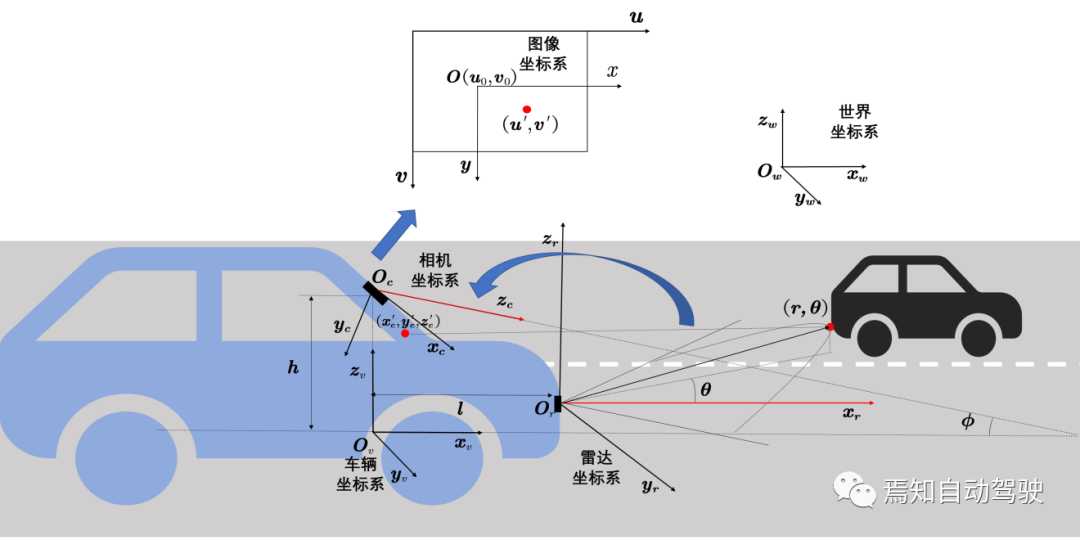
Multi-sensor data fusion must also consider the problems of spatial matching and clock synchronization. Spatial matching requires converting between multiple sensor coordinate systems, including world coordinate systems, geographic coordinate systems, and vehicle coordinate systems. In the sensor coordinate system, it mainly includes image coordinate systems, radar coordinate systems, and laser radar coordinate systems. Taking the camera and millimeter wave radar as examples, it is mainly necessary to calibrate the camera’s internal and external parameter matrices.
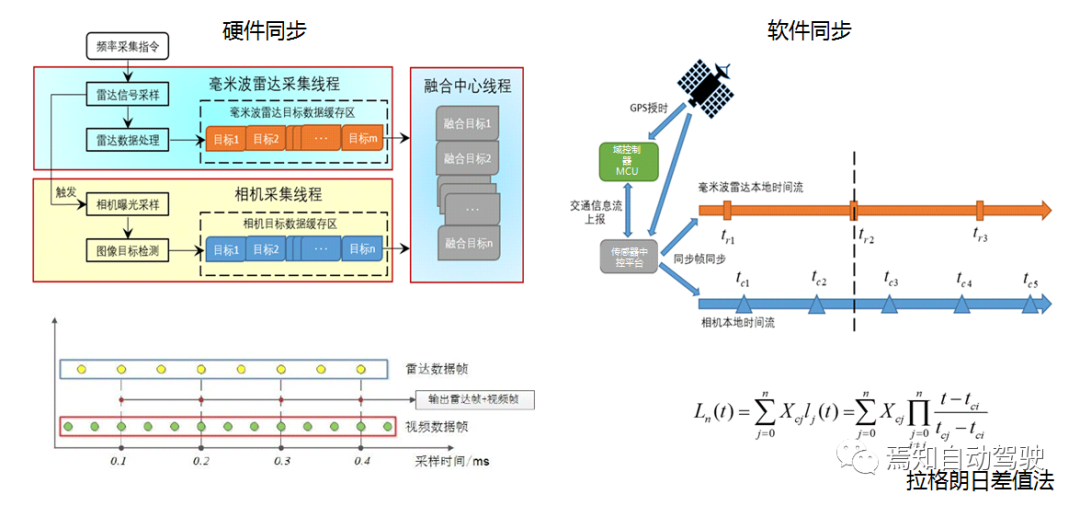
 Apart from data synchronization, clock synchronization is also important. There are mainly two solutions for time synchronization: hardware-based and software-based. Hardware synchronization involves setting up a hardware multi-threaded trigger, for example, the frequency of data transmission or sampling frequency for millimeter-wave radar and image processing may differ, and the radar sampling frequency is generally lower than that for video data.
Apart from data synchronization, clock synchronization is also important. There are mainly two solutions for time synchronization: hardware-based and software-based. Hardware synchronization involves setting up a hardware multi-threaded trigger, for example, the frequency of data transmission or sampling frequency for millimeter-wave radar and image processing may differ, and the radar sampling frequency is generally lower than that for video data.
Therefore, image information can be obtained by hardware trigger after radar detection. This solution is more suitable for low-cost integrated radar cameras, but the hardware aspect is relatively complex.
Software synchronization is currently a commonly used solution, where most data can be timestamped with GPS, such as millimeter-wave radar and camera data. Data compensation is performed based on the closest match or through interpolation methods such as linear interpolation and Lagrange interpolation.
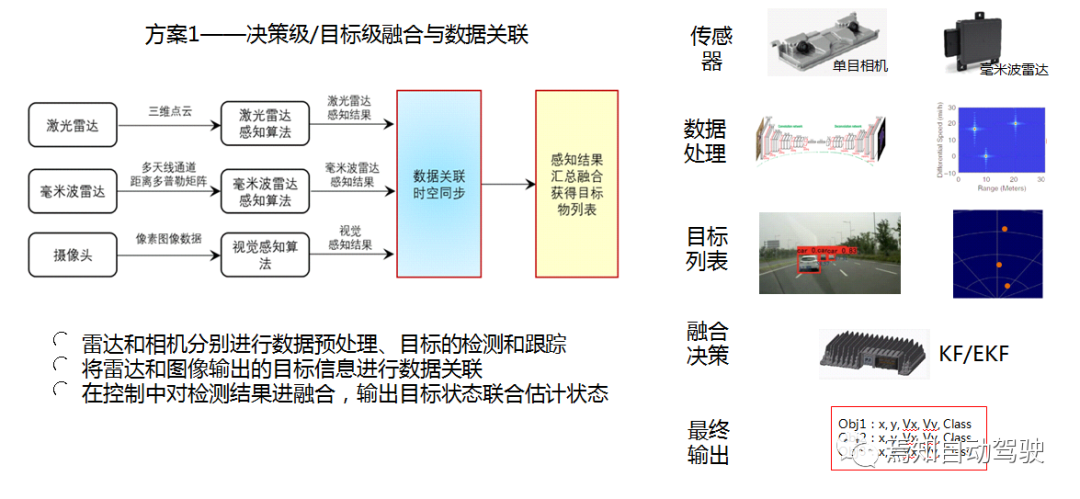
Classic fusion methods for cameras and radars
Li Sen introduced that there are currently two widely used solutions in ADAS systems. The first solution is decision-level/target-level fusion and data association, where sensors perform target detection separately in the controller, obtain the target position information and classification information list, then unify the data association and summarize the perception results, and finally obtain the best position result for a target through decision-making. This is currently the most commonly used solution in ADAS.
Generally, whether it is a traditional method or a deep learning method, image computing requires a step-by-step scan in the domain, which is time-consuming.
The second solution is based on generating the region of interest (ROI) from radar data. Fusion is performed at the image level by first calibrating the radar and image sensors, projecting the radar data results onto the camera to generate an ROI, and then performing target detection in the ROI. The new method can directly find the region of interest, and the image only performs target identification and classification within this box, which saves time.
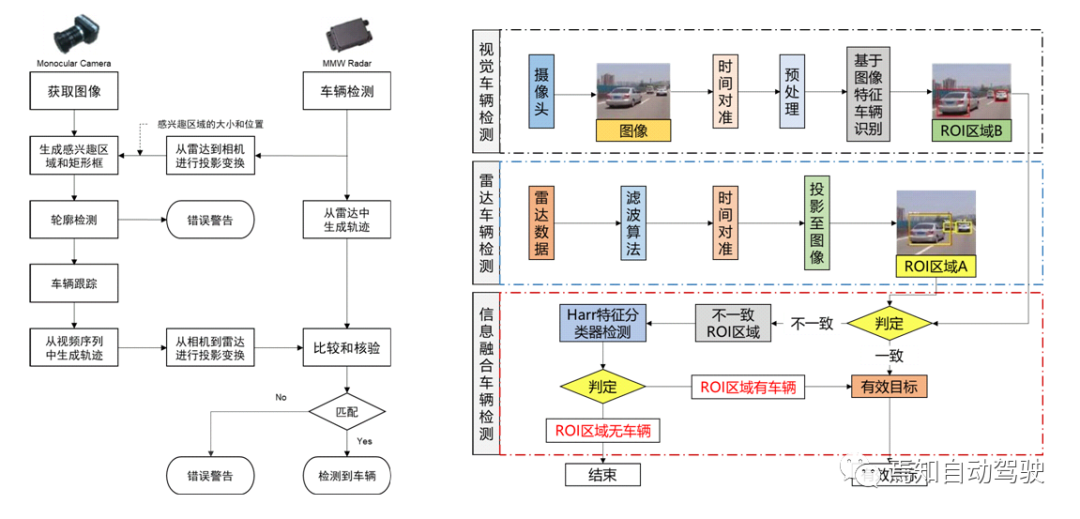 ## Multi-Target Tracking Scheme
## Multi-Target Tracking Scheme
In the multi-target tracking scheme, detection is performed through both camera and radar, and then matched by association based on speed calculation. The color scheme of green to red and back to green is a common feature in ACC and AEB systems, which is also widely used as a warning function in ADAS systems. By adding multiple sensors, such as multiple millimeter-wave radars, the perception accuracy can be improved. Yellow represents fusion results, green represents radar detection results, and red represents detection results obtained through optical flow methods.
From this method, it can be seen that in this scenario, radar sometimes cannot detect targets completely. Hence, it can be observed that in the solutions of Baidu at L3 or higher, L4, L5, high-beam lidar is used. Therefore, two-dimensional millimeter-wave radar is not ubiquitous in the application of major internet manufacturers and is mostly used as an additional function for forward warning. At present, millimeter-wave radar can only obtain two-dimensional point clouds, which has its limitations.
In multi-target tracking based on traditional radar imaging, due to the detection algorithm or distance of the sensors, or hardware reasons, some targets may have insufficient measurement detection capabilities. Also, there may be various obstructions between moving targets, where the objects behind may be blocked by the objects in the front, especially in the scenarios where vehicles are passing or overtaking, which may cause unstable tracking of the targets.
This scenario can be divided into several parts, one being noise disturbance, and the other being trajectory crossing, which may lead to false targets during matching. Especially in the fusion of radar and camera in the box, it is difficult to determine the intersection point between them, because they may belong to the first and second person’s boxes at the same time.
In the case of obstructions, the radar may detect two people (Case3), but due to its own deficiencies, it may identify one person, and the person in front obstructs the person behind. Other sensors, such as millimeter-wave and lidar, may not detect this. Therefore, for this scenario, we propose a tracking scheme based on radar and image fusion.
The radar detection results are associated with the image, and then a random linear level is generated. There is no order between the targets since we assume there is no order between the targets. In actual driving scenarios, it can be observed that targets appear and disappear, and some targets keep appearing and disappearing in the field of view.
We use a Gaussian mixture model, composed of its center and standard deviation, to initialize the targets. During the initialization process, we attach a label to it. In the prediction and update process, we divide it into two parts. For those detected, we perform subsequent state updates, and for those that suddenly disappear on both sides, we assume it is temporary measurement loss, whether detected by the sensor or not, but existed in the previous moment. We compensate using a decay function by targeting the label.Because our target will not appear or disappear out of nowhere, it must be continuous movement. Thus, the status estimation of the target is obtained through such release.
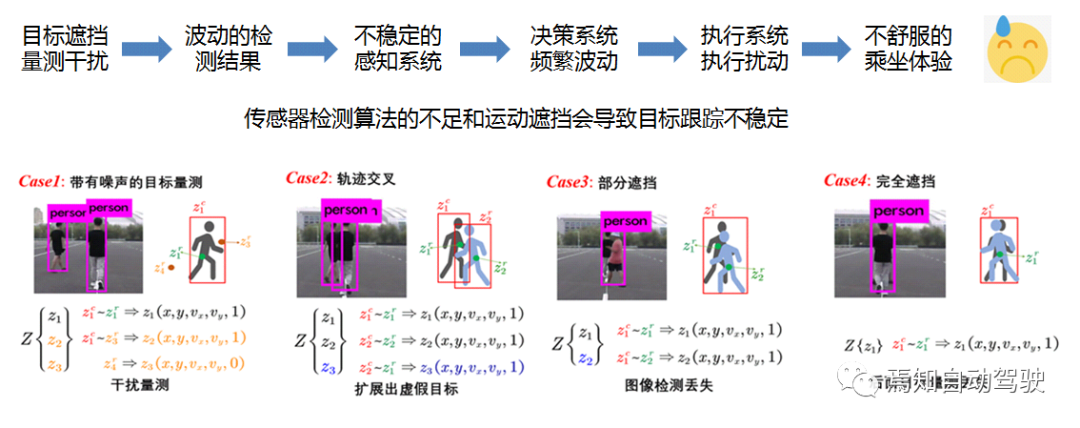
In an actual road test scenario, vehicle in Frame 100 switched to an intersection scene. In the algorithm, there will be multiple detections lost, and the detections are not continuous between targets. However, in the new algorithm, the curve is basically smoother.
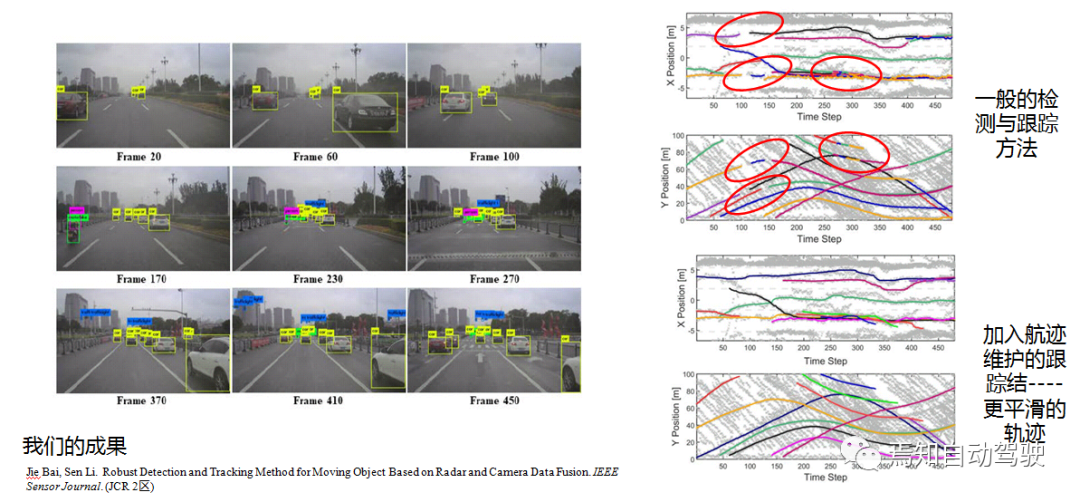
Advanced Methods of Camera and Radar Fusion
Li Sen stated that in recent years, deep learning research has been very active, and some advanced fusion tracking solutions have emerged: ordinary radar point cloud + camera, radar RF image + camera, and 4D radar point cloud + camera.
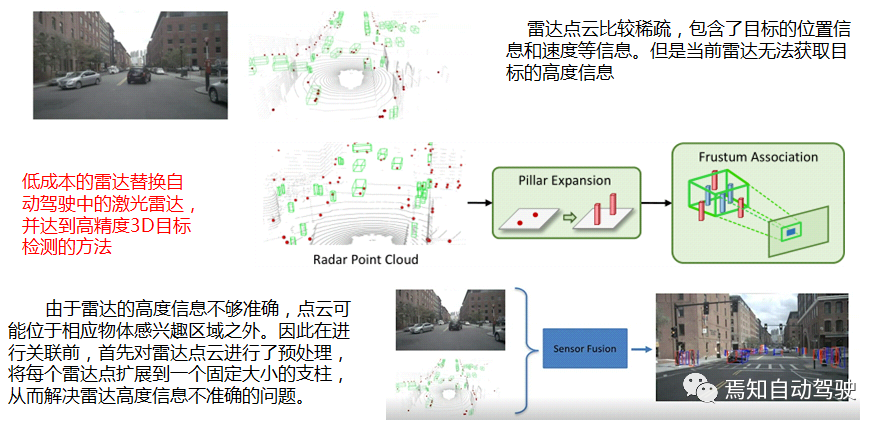
He believes that the current majority of sensor fusion methods focus on using LIDAR and cameras to achieve high-precision 3D object detection.
However, this method has its limitations. Cameras and LIDAR are sensitive to adverse weather conditions such as snow, fog, and rain, and the detection of distant targets is not accurate. Moreover, LIDAR is expensive, and there are still difficulties in promoting it. Due to the good robustness of radar to harsh weather conditions, the detection distance is very large, and it can accurately measure the speed of targets at a low cost. The radar in autonomous driving is increasingly receiving people’s attention.
Although radar data is more sparse and the laser radar method cannot be directly used, each point contains a lot of information and can play a significant role in fusion.
This article combines the image data from the camera and the point cloud data from the radar for fusion in the intermediate feature layer to achieve accurate 3D object detection.
Before the fusion, because the height information of the radar is not accurate, it cannot be well associated with the image target. Therefore, preprocessing of the radar point cloud is required, and the pillar expansion preprocessing method is used to expand each radar point cloud into a fixed-size pillar. If a part of the pillar enters the association region of interest (ROI), the radar point cloud can be associated and fused with the camera.
 Firstly, the image is fed into the CenterNet feature extraction network, and through deep learning, acquires information on the object’s heatmap (HM), width and height (WH), estimated depth (Dep), offset of object center from heatmap point (Off), rotation (Rot), and other information.
Firstly, the image is fed into the CenterNet feature extraction network, and through deep learning, acquires information on the object’s heatmap (HM), width and height (WH), estimated depth (Dep), offset of object center from heatmap point (Off), rotation (Rot), and other information.
Then, pillar expansion preprocessing is performed on the radar point cloud information, and through the frustum associated method, the radar point cloud is associated with the camera target. The radar is able to accurately measure the depth and velocity information of the target, and with features such as signal-to-noise ratio and radar scattering area, combines the radar features with the image features. The new feature map is placed in the deep learning model, and the final fused object detection result is obtained.
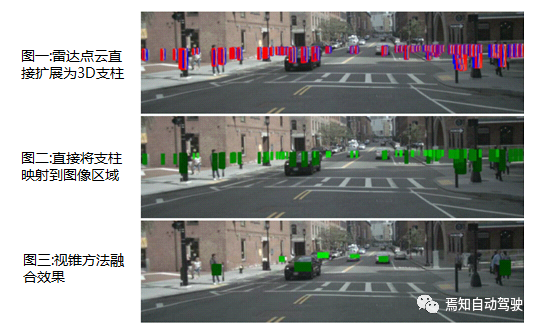
To associate the radar point cloud with the corresponding object in the image plane, the simplest method is to map each radar point to the image plane, and if the point is mapped within the object’s 2D boundary box, associate it with the object. However, this is not a good idea because there is no one-to-one mapping between the radar point cloud and the objects in the image; many objects in the scene will generate multiple radar detections, and there are also radar detections that do not correspond to any object.
In addition, due to the inaccuracies in the z dimension of the radar detection, the mapped radar points may fall outside the 2D boundary box of the corresponding object.
As can be seen from the figures, direct mapping will result in many bad associations and overlaps, and the association effect is poor. After using the frustum method, the radar can be mapped to the center of the object very well, and the overlap can be suppressed, resulting in a significant enhancement in the association effect.
In the image, if the centers of two objects overlap, CenterNet may only detect one center point and train the two objects as one. Therefore, the detection effect of overlapping objects in the image region is poor. But the radar point cloud contains rich information such as 3D position, velocity, and intensity, making it easy to distinguish objects that are difficult to differentiate in the image. Therefore, with the addition of radar information, the detection performance is significantly improved.
Lastly, the basic process of radar signal processing can be seen from the figure.The signal processing flow of radar is generated by an intermediate frequency signal, followed by a distance-Doppler matrix transformation. After that, CFAR target detection, position estimation, and filtering tracking can be integrated in the embedded MCU processor of the radar. In deep learning, convolutional neural networks can achieve target classification and localization by learning the features of the target in image object detection.
In order to achieve feature-level fusion, the detection results of the radar can be converted into a distance-angle matrix, and the echo intensity of the radar can be encoded into corresponding RGB colors to obtain the radio frequency (RF) image. The radar RF image contains more rich information about the target, such as its position, shape, surface texture, velocity, etc.
This method can use deep learning to achieve target detection. However, the radar detection results are not as clear as those of the camera, which can be easily distinguished by the human eye. Therefore, we need to fuse the results of the radar with the camera, and use a “teacher-student system” to train the radar to achieve target classification.
The entire sensor consists of a millimeter-wave radar and a stereo camera. The stereo camera is used to provide more accurate position estimation and 3D detection. The entire fusion architecture is shown in the figure on the right. We can see that the teacher system can achieve target localization, classification, and tracking by processing the image.
Then, the detection results are projected onto the distance-angle RF image of the corresponding class. The radar also uses the CFAR algorithm to extract the peak position of candidate targets. Then, the camera’s detection results are used for correction and learning in combination with the radar’s own detection results.
For the learning system, three types of network architectures are used, including 3D convolutional autoencoder, 3D convolutional stacked hourglass, and multiple temporal kernel-scale networks for target classification. For the target detection in dynamic and changing scenes, the detection results of a certain period of time can be added to the network, and the temporal deformation convolution (TDC) module can be used for processing. The detection results of each chirp in the radar can be merged using M-Net.
Due to the use of dynamic TDC and target feature module processing, the detection accuracy can reach 85.98% compared with traditional methods. The results are good in multiple scenarios, especially at night, where the radar can detect targets that are not visible on the image.
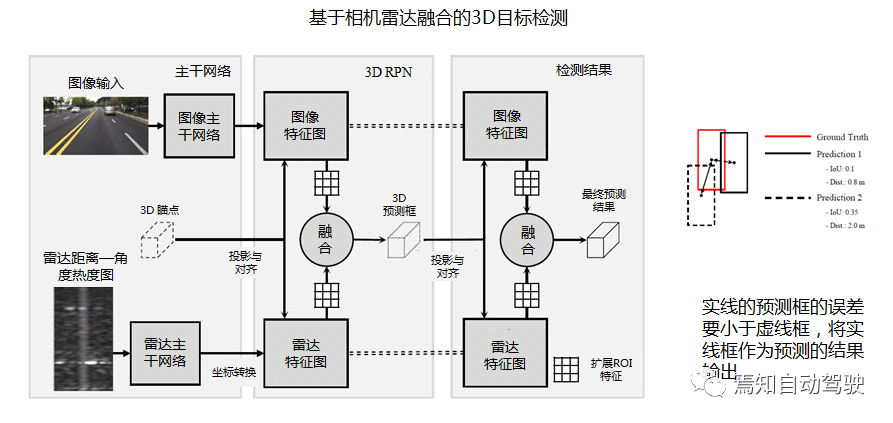
Another feature-based fusion network architecture for radar and camera. Unlike the previous scheme, the data levels of images and radar are the same, rather than having a teacher-student relationship.
Radar and image are first processed separately by their respective feature extraction backbone networks VGG16 and 3DRFN to generate their respective preview boxes. Then the fusion result is output by selecting the preview box with the smaller error. As can be seen, the solid-line predicted box on the right has smaller error than the dotted-line box, and is output as the predicted result.
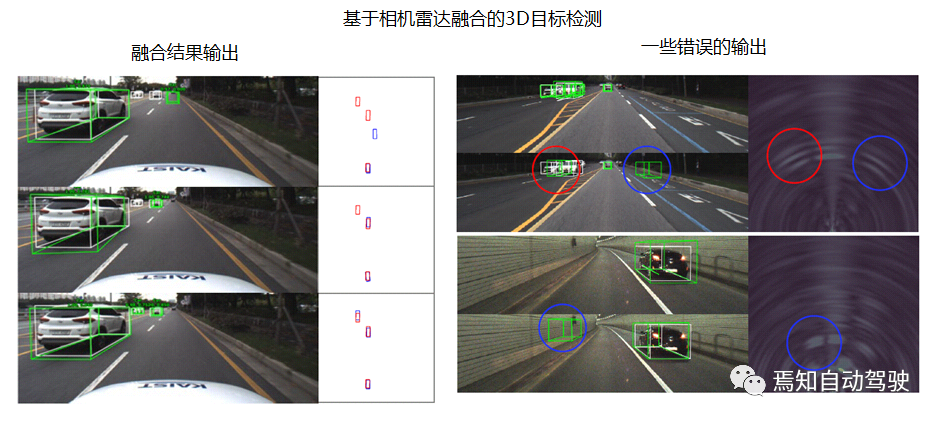
The detection results show that sometimes there is a lot of noise in the radar image, possibly due to some poor detection or complex electronic systems. While the 2D and RF point cloud methods of radar have relatively good effect, they require stronger computing power and have poor real-time performance.
The Future Belongs to 4D Millimeter-wave Radar
Li Sen demonstrated the target classification and detection research on urban road traffic participants based on Suzhou Haomi’s 4D imaging radar, including some visualization results of the target detection and classification dataset collected in Tongji University’s test field.
As can be seen, 4D imaging radar can output target point clouds with height, reflecting the outline and shape of the target, which is different from the principle of point cloud imaging by LiDAR. From the point cloud image of millimeter-wave radar alone, it is impossible to accurately determine the shape and other characteristics of a target, but its scattering characteristics have certain regularities.
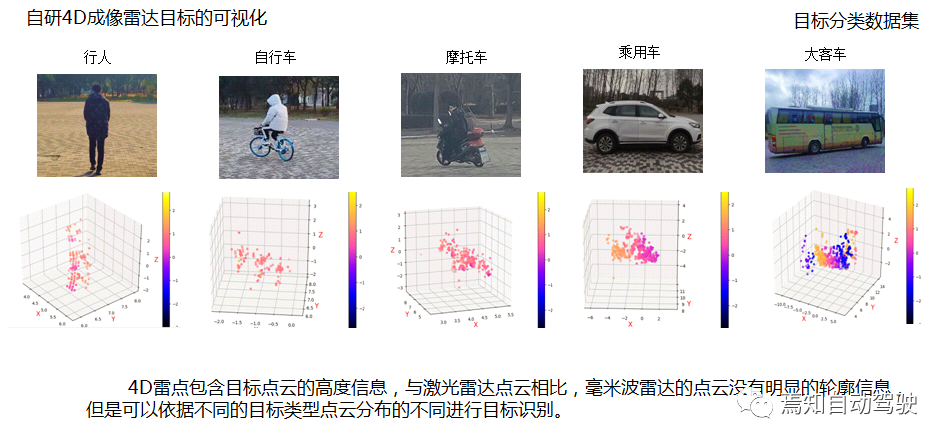
Its machine learning target classification algorithm incorporates several features of point clouds: Doppler velocity, point cloud intensity distribution, and correlation features related to distance. The feature parameter of machine learning is low, making it suitable for embedded classification, and the testing in the classification algorithm dataset has achieved high classification ability of over 95% for pedestrians, and especially 99% for large vehicle classification.
 Compared with LiDAR point clouds, although 4D radar point clouds are sparser than LiDAR, they can detect targets at a longer distance and include target velocity information. 4D millimeter-wave radar can assist in detecting the 3D profile and outline of targets. It can be seen that there is a significant difference in point cloud distribution between LiDAR and millimeter-wave radar in the same scene.
Compared with LiDAR point clouds, although 4D radar point clouds are sparser than LiDAR, they can detect targets at a longer distance and include target velocity information. 4D millimeter-wave radar can assist in detecting the 3D profile and outline of targets. It can be seen that there is a significant difference in point cloud distribution between LiDAR and millimeter-wave radar in the same scene.

Finally, Li Sen emphasized that 4D radar is gradually entering the market, and the future belongs to 4D millimeter-wave radar point clouds. As each target has richer point clouds, it will certainly play a more important role in the L4 system, which will significantly improve the perception system status of millimeter-wave radar.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.