
![]()
After years of technological advances, today our machines can almost perceive all spatial information in the world, including the “bottom exploration” of the Mariana Trench and the “observation” of Helicobacter pylori in people’s gastrointestinal tract.
Technological development has brought about dramatic changes in industries such as consumer electronics, biomedicine, civil engineering, and aerospace. However, in the automotive industry, there seems to have been little fundamental change compared to 100 years ago.
With the rapid development of image recognition, AI neural networks, software algorithms, optics, semiconductors, and communication technology, we are delighted to find that they all ultimately point to the best destination for transportation, “autonomous driving”.
On the road to this beautiful destination, there are still numerous obstacles. What are these obstacles and what are the methods to overcome them?
This article hopes to explore the potential final outcome purely from a technical perspective.
The full article is about 5,000 words long. Please bear with us until the end if possible.
Visual Perception of Machines
Humans see the world in vibrant colors because we perceive only the reflected light from objects in the outside world.
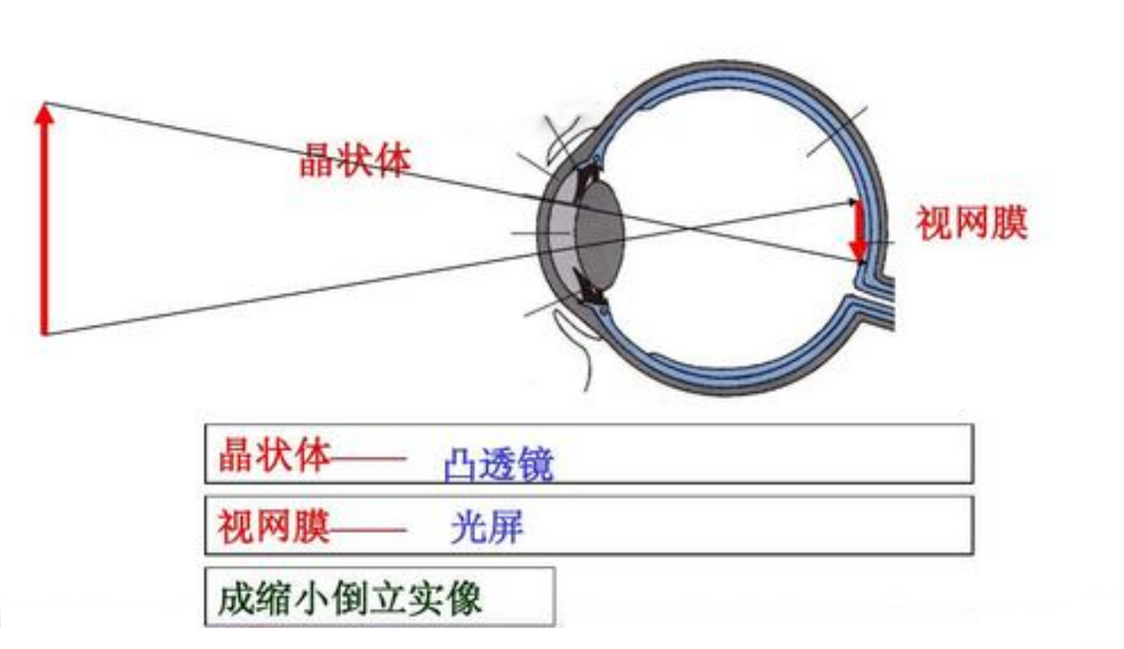
During the day, the light from the sun reflects off objects and collects on the lens after passing through the eyeball. The lens then refracts the light onto the retina, which captures the “pixels” of the object. Finally, the brain extracts color distribution, texture features, contours, and detail information from these pixels through the “neurons”.
The brain then compares the analyzed image information with inherent abstract concepts to make judgments and choices.
This is also why sometimes we will mistake one person for another, because the person we see looks very similar to the abstract concept in our brain.
In one aspect, machines “mimic” humans. The camera captures images of the road and the chip processes this information. That is to say, machines have “eyes” and “brains”, but lack the ability to “think deeply”.
Therefore, we give the machine a “convolutional neural network” (CNN), which has a similar principle to human thought patterns.
However, unlike humans, the machine does not have a “retina”, so the way it “generates vision” is different from humans.
Machines convert images into “digital matrices”, which means that each image is recognized from the bottom layer of RGB, outputting a series of digital 0s and 1s that the machine can understand.
In this process, different images correspond to different digital matrices, which means that the essence of image recognition is a classification problem based on numerical matrices.
Then, we use “convolution” to establish multiple layers of structures like human neurons, between different representations of the same object, to find the same features and make decisions.Translate the Chinese Markdown text to English Markdown text, professionally, preserving the HTML tags inside Markdown, and only output the corrected and improved parts, without writing explanations.
Here we will use a “convolution kernel” that sets the extraction logic.
We can simply understand the image as a large grid of 10×10 squares, and the convolution kernel is a small square of 2×2 squares placed inside the large square. The small square thus obtains a new image, which is the “feature map.”
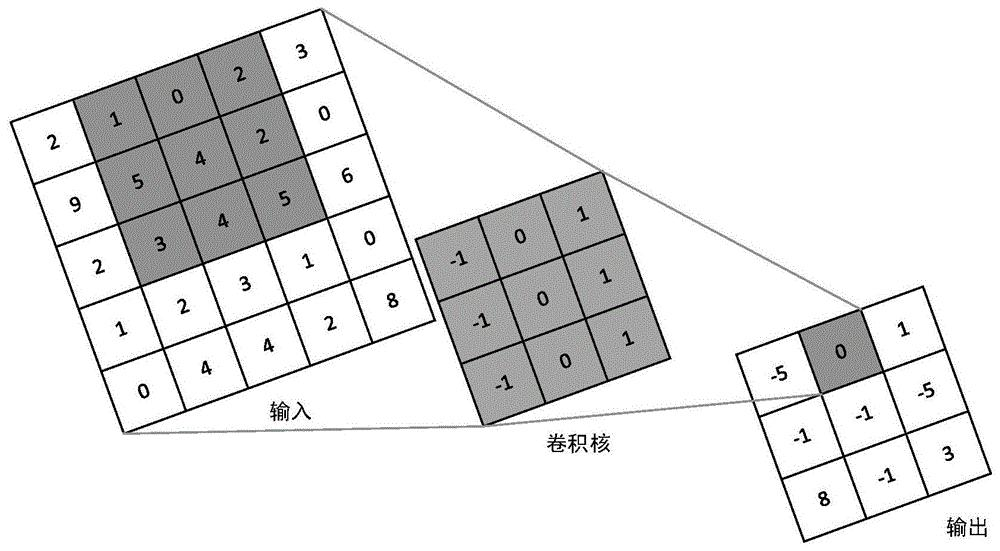
To make it easier to understand, let’s use an inappropriate example. If we have three cars, the “convolution kernel” is set to extract the feature of “car lights.” The kernel will then scan and extract the image area with this feature.

For example, if the image recognition detects 6 car lights, and the logical algorithm tells the machine that 2 car lights equal 1 car, the machine will output that there are 3 cars in the image.
It should be noted that a single image can have multiple “convolution kernels,” and convolution usually extracts image features from three dimensions: length, width, and depth. Therefore, the resulting image is usually three-dimensional.
The extracted feature map is then “pooled” and “activated.” “Pooling” refers to the useful information in the feature map being magnified and the unnecessary information reduced, and then the output data is added up.
The purpose is to reduce the amount of data and parameters while retaining the original image features and reducing the machine’s computational load.
To continue with the example above, now we want to highlight the “BMW car lights” feature and remove the background information unrelated to that.
“Activation,” on the other hand, uses an “activation function” to present the image feature more clearly as a value between 0 and 1 after image pooling. The closer the value is to 1, the more pronounced the feature is.
After multiple rounds of convolution, pooling, and activation, in combination with our algorithm logic, the machine can recognize which car is a BMW based on the digital feature of “BMW car lights” in the image.
In summary, the convolutional neural network is mainly used to extract image features, and then the network is trained and reinforced with data to recognize and judge objects.
To supplement, the purpose of the 8 million pixel high-definition camera is similar to that of the human eye, with some differences. In image recognition, the “perception threshold” is important. In essence, a high pixel camera captures denser and clearer features when capturing images of distant objects, which can help in recognition.Assuming that the perception threshold for identifying a cow requires a feature composed of 100 pixels, a scenario with 1.2 million pixels would require a distance of 200 meters to capture enough pixels. Conversely, 8 million pixels can be captured from a distance of 400 meters with a high-resolution camera; albeit, this process requires high computing power as it involves extracting the required features from more pixels.
In the process of advanced driver assistance, once a camera has recognized obstacles in the distance, the focus shifts to “tracking” instead of re-identification. The tracking process requires less computing power, allowing for additional resources to be allocated to detect other distant obstacles.
Consequently, high-resolution cameras are needed, not only for forward-facing cameras but also for rear-facing ones. Consider an example where a driver is changing lanes on an unrestricted highway; if the rear-facing camera can recognize cars from farther away, safety can be more effectively ensured.
Unfortunately, even powerful neural networks are not as efficient as the human brain, and 8 million pixels are not as high as 324 million pixels seen by the human eye. Even highly skilled individuals occasionally mistake identities, and despite being entirely focused while driving, accidents can still occur.
Therefore, the current trend in the automotive industry is to incorporate multiple sensors through fusion techniques for autonomous driving, which appears to be the most feasible solution.
It’s Not a Simple Overlay
Apart from cameras, the traditional millimeter-wave radar is still prevalent and used to achieve range finding functionality. The millimeter-wave radar has the following advantages: small volume, light weight, low cost, strong penetration capability, high and stable transmission efficiency. However, it also has some drawbacks such as the lack of elevation information.
Recently, the popular solution is 4D millimeter-wave radar. According to the President of Velodyne, Jeff Xu, who spoke to the Asia-Pacific Region, 4D millimeter-wave radar can virtually create 5-10 times as many antennas by using software algorithms, based on the original physical antennas.
This can accomplish the effect of having 120 antennas, and when used with FOV 120 degrees, a high-resolution image with a resolution of 1 degree can be achieved, resulting in a detection range of up to 350 meters.
It seems like the solution to the problem of identifying distant obstacles, but in my opinion, automakers have not fundamentally solved the problem. Millimeter-wave radar is also sensitive to metal objects, which has its pros and cons. One advantage is its ability to accurately detect vehicles, both in front and at the rear. However, the disadvantage is that metal-containing objects such as electrical wires, manhole covers, and roadside barriers are also detected in normal road environments.This means that although the data fed back by millimeter wave technology from moving metallic objects, which reflects reliable and credible electromagnetic wave information, “the data reflecting from stationary objects is difficult to provide a significant assistance to autonomous driving decision-making.”
This is because millimeter wave technology is not capable of identifying what the stationary objects are. To avoid abrupt braking, such data needs to be filtered out. However, the presence of actual stationary obstacles on roads means that automotive manufacturers cannot completely filter out this type of data either.
Therefore, for automotive manufacturers, even after using 4D millimeter wave radar, due to the nature of millimeter wave technology, the implementation process remains a “trial-and-error” problem.
Now let’s talk about LiDAR. As the cost of LiDAR technology continues to drop, LiDAR is becoming a “darling” among automotive manufacturers.
LiDAR can solve the problem of point cloud information caused by pulse, which not only compensates for the shortcomings of long-tail effects of cameras, but also provides absolute distance measurement. In terms of chips, computation is lower and can therefore be considered as a “plug and play” solution.
Thus, for automotive manufacturers, LiDAR with the ability to 3D model carries a large decision-making weight for autonomous driving.
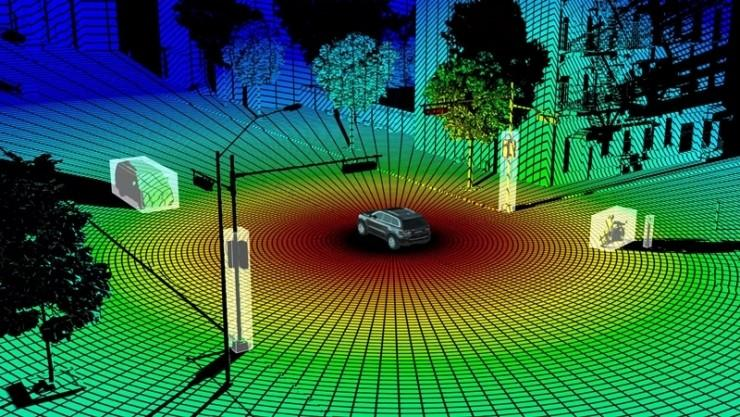
This is because cameras cannot understand what they have not seen, and millimeter wave technology is too sensitive, which leads to uncertainty in available information. The characteristics of these two sensors determine that in extreme scenarios, the data from LiDAR is relatively more reliable.
For example, suppose there is a zebra crossing ahead with a zebra on it. Due to the large overlap of pixels between the zebra and the background, and the fact that cameras have not been extensively trained to recognize the image of a zebra, it is not recognized. At the same time, the echo of the stationary object is filtered out by the algorithm, making a collision a likely event.
In this scenario, LiDAR can detect that there is an obstacle on the zebra crossing ahead. Although at present, LiDAR may not be able to accurately identify the obstacle, it can still prompt the vehicle to slow down or stop, preventing accidents from happening.
Furthermore, LiDAR can classify and identify objects, as the emitted and reflected pulse signals differ. Thus, adding a convolutional neural network to the point cloud algorithm, LiDAR is also capable of identifying and determining object characteristics. At present, it can be more easily achieved for highly reflective objects, such as the ice cream cone and reflective cones.
Additionally, the absolute distance information brought by pulse solves the challenge of depth of field for cameras. Tesla AI Senior Director Andrej Karpathy mentioned that Tesla uses a “Bird’s Eye View” approach.In simple terms, it uses the 2D images captured by the five-directional cameras on the vehicle to calculate pixel depth, and then simulates a 3D environment by synchronizing the time and space delays in the images from the five cameras. Finally, it calculates the relative distance to obstacles and obtains a point cloud information similar to that of a LiDAR.
In principle, this approach is feasible, although it places higher demands on computing power and algorithms since it requires synchronizing the time and space delays of the different camera information for various vehicle speeds and creating 3D modeling from the 2D images of multiple cameras.
I believe that for Tesla, this is just one step towards “climbing Mount Everest.”
However, this does not necessarily mean that Tesla will not use LiDAR. Although I think that visual solutions may have the chance to achieve L4 in the long run, there are two main reasons why vision is not the best solution for all scenarios. Firstly, cameras are significantly affected by extreme weather conditions like heavy fog which cannot be easily solved through technology. Secondly, don’t forget that the biggest difference between current L2 assisted driving and L4 autonomous driving is that legal responsibility is transferred from humans to automakers.
According to industry insiders, even at current technology levels, if a large quantity of 905nm LiDARs were purchased, their cost could drop to $300-500. The question to consider here is the cost of achieving short-term L4 autonomous driving versus the risk cost of transferring legal responsibility to the automaker, which is lower for Tesla’s core idea of “cost reduction”.
Of course, I believe that as visual solutions continue to develop, they will weaken the position of LiDAR in autonomous driving, but it is difficult to replace completely. I tend to agree with the statement made by the XPeng self-driving product director, Huang Xin, that “LiDAR is overrated in the long run and underestimated in the short run. My personal opinion may be wrong.”
Finally, I would like to say that if everyone is only using L2 and legal responsibility still lies with humans, why does Tesla need LiDAR? However, at present, from the perspective of safety redundancy, I believe that it is more cost-effective for visual solutions to pay the cost than to fuse multiple sensors.
Multiple sensor fusion, in simple terms, refers to the process of collecting multiple types of information from the vehicle and making decisions and judgments. However, because there are errors in the time-frequency, spatial, and speed information collected by multiple sensors, the fusion algorithm used becomes crucial.Firstly, let’s talk about the time delay, which is caused by different “sampling rates” of sensors. The laser radar can produce hundreds of thousands, if not millions, of points per second, while a typical automotive camera captures only around 30 frames per second. Therefore, there exists a significant time gap between these sensors.
For example, which frame should we match with the 500,000 laser pulses received within the last 0.01 seconds?
Regarding spatial information, since cameras, millimeter wave, and LiDAR are placed in different positions, the perception areas are not the same. To form a machine understandable perception world, we need to merge the target objects captured by the camera with the information acquired by the millimeter wave into the same coordinate system.
For example, which pixel area of the screen should we match with the 500,000 laser pulses received within the last 0.01 seconds?
In terms of speed, millimeter waves can provide distance and speed information directly based on the Doppler effect, while cameras can obtain distance and speed information by tracking feature pixel area changes and using a “Kalman filter.” However, there will still be discrepancies between the two.
Clearly, the millimeter waves are more timely since they measure speed using electromagnetic waves. When shooting a car traveling at 120 kilometers per hour, assuming the camera captures 30 frames per second, the car will have moved one meter in spatial distance between frames.
Therefore, to solve the aforementioned issues, we first need to use “fusion algorithms” to achieve temporal and spatial synchronization.
However, after the synchronization, a new problem arises. In addition to the examples of cameras and millimeter waves mentioned above, there are errors in the information collected by every sensor. Whose information should we trust?
Our current approach is “post-fusion,” where cameras, millimeter waves, LiDAR, and other sensors first collect information and generate their own information lists.
At this point, we assign “weights” based on the different characteristics of each sensor in different scenarios and then use methods such as Kalman filters to calculate relatively accurate estimation values between different perceived information.
We have mentioned “Kalman filtering” twice, so we will briefly explain its principle. Essentially, based on the information collected by each sensor, the filter will make an estimation according to the proportional weight.
For instance, suppose a camera measures a 30-meter distance to the obstacle ahead via depth of field calculation but millimeter wave information shows only 26 meters away. In this case, we apply the “Kalman filter.” Since the millimeter wave radar is more accurate in distance measurement than the camera, even though it may not have completely trustworthy information due to sensitivity to metal, the filter will give more weight to the millimeter wave information and use the camera information as a reference to estimate the distance to the obstacle ahead as 27.32 meters.
In fact, the “Kalman filter” has a specific equation that is quite complicated, to the point that we suspect a significant amount of computing power is consumed.In this process, the original perception information intended to be “determinized” for better processing inevitably gets filtered out by the Kalman filtering method, which means that many decision-making data in assisted driving at this stage are essentially “predicted” by the machine.
However, the industry has actually had the method of “front fusion” of sensors a few years ago. It’s just that, in terms of technical threshold, it is higher than the latter fusion, just mastering the “raw data of all sensors” alone made many car companies “hesitate”.
Because in “front fusion”, what needs to be done is to make other sensors learn the ability of “deep learning” like the camera, and everyone uses the same set of “algorithms” to make judgments.
Simply put, whether humans use vision to see a car, smell exhaust fumes with their noses, or hear a car’s exhaust sound with their ears, our brains will output the same information “a car has passed by”, rather than having to fuse the three sets of information again before making a judgment and selection.
It should be noted that front fusion also blends “low-level” characteristics, not all of them.
The key point is to merge the original data from cameras, millimeter-wave radar, lidars, and other sensors with the same set of algorithms, so that the chip processor responsible for processing information becomes like a “sky eye”.
With the existence of “sky eye”, the machine’s perception of external information is already very clear. Based on this, further perception and control algorithms can be developed.
In this way, by improving the consistency of sensor output information and reducing the number of calculations, the efficiency and accuracy of the perception system can be improved.
This way, the machine can also obtain more redundant computing power, even if it occasionally makes a “small mistake” like a human driver, it does not affect the final safety.
In conclusion
If you have read this far, the article is actually slightly over 5000 words. But what I want to say has not been fully expressed yet. There are still many things to talk about in autonomous driving, such as chips, control redundancy, and phased array lidars that are still “futures”.
Since entering 2021, the biggest feeling is that the electric vehicle industry is pushing forward without stopping. Our cognition is being constantly refreshed by the industry every day, and many things are happening much earlier than expected.
If you, like us, pay attention to the development of autonomous driving and love the lifestyle changes brought about by technological progress, welcome to join our community and “chat” with us about our imagination for the future.
Finally, before Dr. Fleming invented penicillin, human beings were still troubled by bacterial infectious diseases. Before Karl Benz invented the automobile, human beings could not experience the convenience of travel.
Fortunately, our generation has the opportunity to witness another historical change.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.