
Author: Bernice
In the past 40 years, there has been a major innovation in human-computer interaction almost every decade.
After mice, keyboards, and touch screens, what will be the next generation of interaction? We do not yet know. But as an important player in the future IoT field, the application scenarios of the car cockpit will provide some inspiration for the transformation of the next generation of human-computer interaction.
Smart era needs to focus on “voice” for in-car interaction
Traditional car cockpit interaction methods were relatively simple, consisting of buttons, levers, knobs, and some touch screen interaction.
With the increasing intelligence of the cockpit, more vehicles are equipped with vehicles with rich functional infotainment systems and different levels of driving assistance, which have caused an explosion of information in the cockpit. Faced with massive information, buttons or touch screens will only make users flustered and make it difficult for the cockpit to truly understand their intentions.
Therefore, traditional interaction methods are clearly no longer applicable, and smart cockpit interaction methods urgently need to change.
At the current level of product development, although L2 driving assistance functions are quickly rolling out, the main task of users in the car in the short term is still driving, and the attention of the user’s limbs and mind is occupied. Although hands can touch screens, they must hold the steering wheel; although eye tracking can be achieved through gaze, attention must still be focused on the road ahead.
Therefore, the interaction resources that car manufacturers can take advantage of are the abilities that can be freed up from these organs. Of the limbs including eyes, arms, mouth, brain, legs, and feet, speech interaction that can be achieved through the mouth is a relatively good choice.

“Active multimodal interaction” combining voice and vision is the future trend
Relying solely on voice in the car will certainly not paint a clear picture of what the next generation of interaction looks like, so “multimodal interaction” centered on voice is the more specific direction of the future, such as combining buttons, touch screens, gesture recognition, face recognition, emotional recognition, and so on.

In addition, user needs are actually beyond language. No one will constantly have commands on their lips, which is not practical or elegant, especially since the cockpit is a semi-public space. Therefore, in most cases, user pain points still exist, which may be an unexpressed need or something that they can still bear. In such situations, the cockpit needs to have the ability to observe the user’s language and behavior, think about their needs at all times, and proactively provide services. If these subtle services can be done well, the experience will be greatly improved, and the user stickiness will be very high.
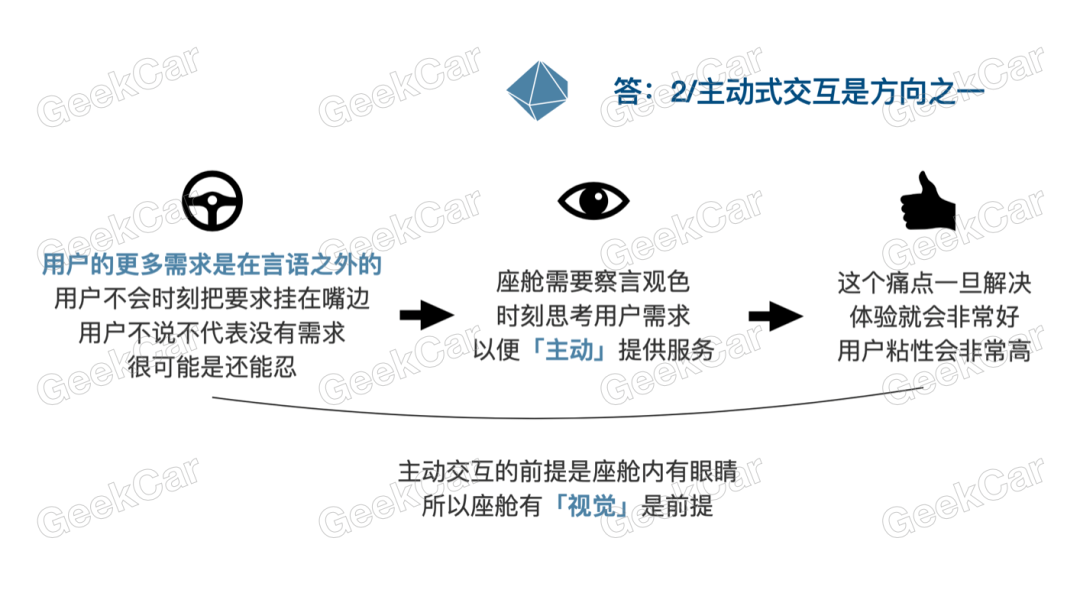 Just now we mentioned that gesture recognition, facial recognition, emotion recognition, and the ability to read and understand passengers’ expressions all require eyes in the cabin. This is the prerequisite for active interaction and all visual-related functions.
Just now we mentioned that gesture recognition, facial recognition, emotion recognition, and the ability to read and understand passengers’ expressions all require eyes in the cabin. This is the prerequisite for active interaction and all visual-related functions.
Therefore, “voice”-centered multimodal interaction and “vision”-centered active interaction are the two important directions for the future. The former is accurate but passive; the latter is active but vague. Theoretically, they cover most service needs.

How is the current implementation for in-car voice and vision?
Currently, there are already several cabins that have implemented relevant voice and vision functions.
Taking voice as an example, I roughly divided it into five stages.
The first stage can achieve basic voice skills and run a complete technical chain of front-end noise reduction-voice triggering-recognition-understanding-feedback; The second stage can combine the voice with more ecosystems of the car system, such as music, navigation, operating system, car windows, and smart homes; The third stage can achieve flexible natural language understanding, realizing automatic error correction, multi-round dialogue, context understanding, and other capabilities without wake-up; The fourth stage can understand more complex natural language, realize full-car voice interaction of source location and multiple pickups, and understand more complex natural language such as multiple conditional overlay expressions and indirect intent expressions; The fifth stage is to form a unique communication personality and use language and services to convey brand concept to users.

Currently, different types of car factories have stood at different stages.

New powerful brands represented by NIO, Ideal, and Xpeng have reached the third stage, and although they still rely on suppliers, their self-development ratio is getting higher and higher. Some have established independent voice frameworks and can express brand personality and attitude through voice.
NIO has already combined voice with driving assistance, inform users the car’s next decision at any time to reduce their mistrust of new features, and NOMI’s support can abstract the voice into emotional expression, which can achieve brand achievement reversely.
Xpeng has built its own voice framework, which can flexibly customize new functions and is not limited by the open capabilities of suppliers. In addition, SR’s automated driving environment simulation display can make users clear when to take over the vehicle through voice and vision.The Ideal One car has achieved multi-zone interaction in the car. It uses a four-microphone distributed array to achieve four-way human voice separation and six-way sound zone detection, completing the collection, positioning, noise reduction, echo cancellation, and voice wakeup of multiple speakers in the car. In other words, it can accurately determine the spatial positions of multiple speakers in the car, highlighting the positioning of the Ideal One family cockpit.
Chinese domestic brands represented by Great Wall Motors, Geely, and SAIC can basically achieve the third stage in terms of experience, but their implementation paths are somewhat different from those of new forces. They rely more on leading domestic voice suppliers or invest in digital external companies to serve themselves.
The car voice of SAIC Roewe RX5 PLUS is provided by Baidu. Specifically, the Dharma Institute provides front-end algorithms/voice wakeup; iFLYTEK provides voice recognition capabilities; and Sogou provides TTS tones. This car has a full-duplex voice system that supports continuous interaction for 90 seconds, and the experience is not inferior to that of new energy vehicle models.
Traditional luxury brands represented by Audi, Mercedes-Benz, BMW, and Cadillac are still in the first and second stages, mostly relying on long-term cooperation with old suppliers while also integrating relevant capabilities from domestic voice suppliers.
The 2020 Audi A4L’s voice system is provided by DaZhong WenWen, and also integrates relevant capabilities from Nuance and Tmall Genie. The overall experience is better than other luxury brands, but it is far from the top tier. Nuance and DaZhong WenWen each provide an ASR and NLU capability to this vehicle, and the two run in parallel. Therefore, when the user enters any command, both channels need to run through, and finally the command is unified and executed, so the overall experience is slower.
After discussing car voice, there aren’t actually many functions related to vision that have been implemented.
XPeng G3 once launched a fatigue detection and warning function in version 1.5 of Xmart OS. The principle is to use the in-car camera to detect the driver’s fatigue characteristics in real-time during driving (such as yawning and closing eyes for a long time), and provide a warning through vibration and voice alert.
Ai Chi U5 also has similar functions. The camera is installed on the A-pillar, and the system will give a voice warning when the driver is calling, yawning, or looking away from the front.
In 2015, BMW’s gesture recognition was first introduced on the BMW 7 series. It can recognize commands such as adjusting the volume and switching tracks through a camera. Recognition rate is high, but its usefulness is debatable.The Changan UNI-T offers a relatively rich set of features, including gaze activation, fatigue detection, multimodal lip-reading recognition, driver behavior recognition, intelligent emotion recognition, and other active AI features provided by Horizon Robotics. It also comes equipped with the vehicle-grade AI chip, “Journey 2.”
As evidenced, many products have already begun implementing speech and visual functions within cars. However, there is an inconsistency in experiences, with substantial variations. Most importantly, speech and vision have not been fundamentally merged and still remain separate, parallel lines. It still feels like solitary systems.
What kind of experience can genuine audio-visual fusion bring?
Genuine audio-visual fusion can provide users with a more comprehensive range of services and feedback through multilateral perception. Specifically, the vehicle can sense the current state of the driver/passenger and the specific scenario through speech, vision, and related vehicle data. It can form predictable demands using automobile-related abilities, providing users with valuable services and information at will.
For instance, when the co-pilot answers a phone call, the vehicle speaker system automatically reduces the volume of the music. When the user does not know where to buy an Apple charging cable nearby, the in-car system proactively provides the location of nearby corporate stores or convenience stores. When the air quality within the car is poor, the system ventilates and adjusts the in-car temperature automatically…
These functions are minor and may not be used every time someone drives, but if the car factory can target user schedules and scenarios accurately and provide intelligent functions, these active AI features can truly understand the user’s feeling.
Here are a few fantastic examples that aren’t currently in mass production and are strictly for entertainment and information purposes:
Car factories can automatically provide a better rest environment for users through the “speech+vision” feature. When the user activates the rest feature, the cabin system automatically plays relaxing music, adjusts seat positions, and monitors the temperature of the air conditioning system. By using the “visual” function, the system can observe the user’s sleep cycles continually. When the user enters a light sleep stage, it automatically lowers the music volume, and when approaching the wake-up time, it plays soft music and gently guides the user into a fresh wakefulness.
Car manufacturers can use the “speech+vision” function to stabilize the baby’s emotions, alleviating anxiety while sitting on the safety seats in the back row. The system can chat with the child sitting in the back row, adjust their emotions, play appropriate children’s education stories, and guide them through reasoning.
When augmented reality (AR) navigation becomes feasible through the windshield in the future, users can use the “speech interaction+gaze tracking+AR Navigation” form to recommend recommendations based on the user’s mood. For instance, when the user says, “I want to park nearby,” “I want to eat Lawson’s ice cream,” “Which Uniqlo is currently on sale?” or “Where can I find a quick car wash around here?” The windshield will mark the corresponding store on nearby buildings, and the system will provide audio feedback on the price per person, new releases, and other critical information.
And the cabin can recommend nearby places based on the owner’s mood. For example, if the user is in a bad mood, it will proactively recommend nearby extreme sports gyms. According to the owner’s role, it provides users with surrounding information that may be needed. If the owner is a parent, it will show that a certain brand of diapers at XX supermarket is on sale, imported milk powder has been restocked at XX shopping mall, and a children’s programming education institution has opened at the doorstep…
Conclusion
Some car voice products can already achieve good interaction experience, and more and more users are exposed to and recognize this interaction method.
However, this is far from the end. Around voice, we can still have more imagination, such as multimodal interaction, proactive service, and so on. Before sorting all of this out, the industry still needs to continue to accelerate its pace.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.