
Author: Chris Zheng
Can autonomous driving cars gradually develop from SAE L2 autonomous driving to L4 autonomous driving through algorithmic iteration?
In June 2015, the answer from Chris Urmson, the CTO of Google’s self-driving car project (now known as Waymo), was: NO.

“(Transitioning from L2 to L4) is as unrealistic as trying hard to practice jumping and hoping to learn how to fly one day.”
At the same time, Tesla CEO Elon Musk chose to embark on this “road of no return”.
With 8 cameras on the whole vehicle, the self-developed FSD autonomous driving chip, multiple restructures of the team, and the launch of the supercomputer Dojo, Tesla’s autonomous driving technology route has permanently deviated from the mainstream trend of the industry and embarked on a unique path.
From 2015 to 2020, let’s review together the path of Tesla’s visual perception advancement.
8 Cameras
On October 14, 2015, Tesla held the Tesla OS v7.0 system update conference. This was not Tesla’s first system update. Elon held a special conference because this was the first time in Tesla’s history that Autopilot, the assisted driving system, was pushed to the public through this update.

This is a landmark event not only for Tesla but also for the intelligent driving industry.
Elon said at the conference that every Model S owner (Model X was not yet delivered, and Model 3 was not yet released) is an expert trainer. Tesla will collect road testing data from various roads through the system, train the Autopilot algorithm, and update the entire vehicle through OTA to continuously improve the robustness of the Autopilot system.
However, this conference was far less significant than a new message a month later.
On November 3, Mobileye CEO Ziv Aviram, Tesla’s core ally in the field of intelligent driving, leaked the hardware architecture of Autopilot 2.0 during its earnings conference call.
We are working with a car manufacturer on the industry’s first car equipped with 8 cameras. In addition to the front triple-camera, there will be 4 cameras around the vehicle and 1 rear camera, along with a millimeter-wave radar and ultrasonic sensors around the vehicle.
The system will be powered by a computing platform consisting of 5 Mobileye EyeQ3 chips.
Ziv Aviram refused to disclose the name of the manufacturer, but mentioned in another public meeting a few days later that Tesla is willing to push the envelope faster and more aggressively than any other OEM, implying that the new system is expected to be launched within a year.
This is equivalent to an announcement that Tesla’s Autopilot 2.0 hardware models will be mass-produced in 2016, and it indirectly illustrates that the Autopilot 1.0 hardware has been a “cannon fodder” since it was put into production on the first day in the rapidly changing technological year of 2016.
Of course, we never saw the so-called “computing platform consisting of 5 Mobileye EyeQ3 chips”.
In May 2016, Tesla Model S owner Joshua Brown turned on Autopilot and started watching “Harry Potter” on DVD. Autopilot and Joshua Brown “failed to see” the white semi-trailer crossing the road, and Joshua Brown was killed in the accident.

This accident directly led to a public confrontation between Tesla and Mobileye. In the end, the two companies with the deepest belief in visual perception split. The computing platform consisting of 5 EyeQ3 chips in the Autopilot 2.0 hardware test version of Tesla was replaced by the Drive PX2 platform from NVIDIA.
FSD chip
In October 2016, the “cannon fodder” Autopilot 1.0 hardware models faced delisting after only two years of production, which is much lower than the average product cycle of seven years in the automotive industry.Tesla has announced the official production of Autopilot 2.0 equipped with eight cameras and NVIDIA’s Drive PX2 computing platform.
At the same time, Tesla has launched an industry-first controversial Full Self-Driving optional package.
People used to believe that Autopilot 2.0 hardware would shine in the next few years until it enabled self-driving. But Elon knew that the huge computing demand of eight cameras made Drive PX2 just a “guinea pig 2.0.”
In September 2015, chip guru Jim Keller left AMD and was faced with two choices: first, to lead Samsung’s smartphone SoC development; second, to start an AI chip company focusing on vertical scenarios.
Finally, a more attractive position vetoed the above two options: in December 2015, Elon personally convinced Jim Keller to join Tesla to lead the research and development of Tesla’s self-driving chip.
In April 2019, Tesla held an Autonomous Investor Day and announced the official production and installation of Autopilot 3.0 equipped with FSD self-driving chips.
FSD self-driving chips have great significance in the development of Tesla Autopilot.
Pete Bannon, VP of Autopilot Hardware Engineering, who oversees the development of the FSD chip, said, “The biggest feature of the FSD chip project is that ‘there is only one customer, Tesla.'”
During the Q&A session after last year’s press conference, Elon expressed a similar view on NVIDIA, Tesla’s chip partner: “NVIDIA is a great company, but they have many customers and have to make a universal chip solution.”Most people cannot understand the importance of “only one customer, Tesla”. Fortune has reported on Jim Keller’s chip design philosophy during his time at Tesla: 1. Deeply understand the software operating mechanism of Tesla Autopilot; 2. Reduce or eliminate modules in general chips (such as Nvidia chips) that are not related to Tesla software.
Therefore, the secret to significantly improving performance while reducing power consumption lies in the trade-offs in the chip design process. Compared with “taking”, the meaning of “giving up” is more important.
In the end, the architectural design became extremely precise, and the heterogeneous design executed parallel computing of NPU which took up the largest physical area in SoC, with every inch and every centimeter being carefully considered.
Each FSD computing platform is equipped with two completely identical chips, each with a computing power of 72 Tops, while the previous generation Nvidia Drive PX2 platform had a computing power of only 8-10 Tops. At the same time, Drive PX2 consumes 57W of power, while Tesla’s NPU consumes only 15W.
In Pete Bannon’s words, he had never seen a performance improvement of more than 3 times in his nearly 40-year chip engineering career, but Tesla improved it by 20 times (110 frames per second on HW 2.0 vs 2300 frames per second on HW 3.0).
Tesla vertically integrated multiple teams, such as SoC design, power supply design, signal integrity design, packaging design, system software, circuit board design, firmware, and system verification, and parallelized the R&D process. Finally, they completed the complete process of chip processing from the first employee joining to the chip being fully installed on the car for sale in 36 months.
“Operational Holiday”
On September 11, 2020, Cruise, a self-driving company owned by General Motors, released a post introducing a deep learning infrastructure called “Continuous Learning Machine.”
Simply put, the “Continuous Learning Machine” combines a self-supervised learning framework that supports automatic annotation of data and a framework for actively learning data mining.# Cruise’s Autonomous Driving System
Cruise’s autonomous driving system recognizes extreme scenarios with perception errors through active learning and adds them to Cruise’s training data set. The self-supervised learning framework supports automatic data annotation, greatly reducing annotation costs and improving the iteration speed of deep neural networks.
With the “Continuous Learning Machine,” Cruise has achieved highly automated, continuous learning of various time-consuming and labor-intensive aspects of the deep learning infrastructure, without human intervention.
But what about before 2020, say in 2017? How did Cruise train its algorithms then?
The iteration of algorithms relies heavily on large-scale data training. Prior to this, the mainstream method for machine learning algorithm training was called supervised learning.
Supervised learning means that data needs to be manually annotated before it is given to the algorithm for training. (For example, basic manual annotation involves drawing boxes to annotate different shapes of motor vehicles, non-motorized vehicles, pedestrians, traffic lights, etc. on the image).
This is a hidden industry in the rapid development process of the AI industry. According to a report by Xinhua News Agency on September 10, 2019, there are more than 100 companies specializing in data annotation in just one city of Beijing, and more than 10 million people are engaged in data annotation work across the country.
This is also the main reason why AI technology, which has always been crowned with high-tech halo, is ridiculed as a “digital Foxconn” and “labor-intensive industry.”
In 2017, Cruise, like most companies, promoted the iterative development of perception algorithms through a development process dominated by supervised learning.
In the same year, Andrej Karpathy, a research scientist at OpenAI, joined Tesla as Director of AI. In his social media profile, Andrej wrote, “I like to train deep neural networks on large datasets.”
He faced a database of such magnitude: by October 2016, Autopilot had accumulated a total of 222 million miles, while Cruise’s autonomous driving road test mileage during the same period was only 130,000 miles.
The huge “digital gap” between Tesla and Cruise meant that from day one, Tesla was unable to use traditional manual annotation tactics to iteratively develop algorithms-the astronomical cost of manual annotation would completely drag down the commercial model of Autopilot/FSD.In November 2019, Andrej Karpathy introduced Tesla’s “Operational Holiday” data flow automation plan. As expected, Tesla applied a self-supervised learning framework that is similar to General Cruise.
The so-called self-supervised learning refers to using a set of pure data for algorithm training instead of a traditional training set that is manually annotated. By digging into the characteristics of the data itself, continuous iterations of perception algorithms are achieved.
Moreover, in 2019, the Cruise team had reached a size of 1800 people, while the Autopilot engineering team had only about 300 people, and Andrej’s AI full-stack team had only 30 people. This made the Autopilot team take a more aggressive approach to data flow automation:
“We are automating a lot of the workflows, and it is not just about the neural network training itself, but everything surrounding that.”
The main focus of the Tesla AI team is on the construction of algorithm operating environment and process automation, algorithm calibration, evaluation, and continuous integration, rather than the development of the algorithm itself.
The ultimate goal of Tesla’s data flow automation is the title of this section: “Operational Holiday.” When everything is developed to the ideal form, the self-driving system should automatically evolve without human intervention. Therefore, the AI team can go on holiday during project operation (because no intervention is needed), which is the ideal form of the project.
Dojo is the most mysterious component of Tesla’s autonomous driving technology architecture. Whenever it comes to Dojo, Elon and Andrej always use “we are not ready to discuss it yet” to evade the question.For a long time, the public’s understanding of Dojo was limited to “the server Tesla uses for cloud training”. However, in 2020, Elon began to continuously disclose information about Dojo on Twitter, finally outlining the basic outline of Dojo for the public.
Simply put, Dojo is a supercomputer used by Tesla for cloud training, which can process a large amount of video training data and effectively run ultra-sparse arrays with a large number of parameters, large amounts of memory, and high bandwidth between cores. Dojo supports unsupervised learning training on a large number of videos.
According to Elon’s statement, Dojo is built based on FPGA programmable circuit chips, and the current development progress is only 0.01%. Tesla still needs about a year to realize the operation of Dojo V1.0 version. The challenge is not only limited to chips, but also includes complex power supply and heat dissipation problems.
Why did Elon say that Dojo is a truly variable?
When talking about the peak performance of Dojo, Elon said this sentence:
A truly useful exaflop at de facto FP32.
In one sentence, two terms exaflop and FP32 appeared, interspersed with two Latin words de facto, which indeed obstructed the widespread dissemination of the media to a certain extent (it is speculated that Elon deliberately did so). Let’s talk about them one by one.
FP32 is a single-precision floating-point format, which is a mainstream format in the field of deep learning, representing weights, activation values, and other values in neural networks.
Compared with FP32, exaflop is a more important and typical Tesla-style rhetoric. Exaflop is a floating-point operation measurement unit, which means 10 to the power of 18, that is, 1 exaflop represents the computing speed of a supercomputing cluster can reach one million trillion times per second.
Therefore, the complete translation of this sentence should be: (Dojo running in FP32 format) Peak performance will be measured in exaflops.
Why is this a very typical Tesla rhetoric?
In 2013, when Tesla was still a desert in the suburbs of Reno, Nevada, it announced the construction of a super battery factory named Gigafactory.
In 2019, after a series of intensive reserves and acquisitions to rapidly increase core technology assets for battery production capacity, Tesla announced that the next super factory would be named Terafactory.Here, Giga and Tera refer to GigaWatt-hours and TeraWatt-hours, respectively, as production capacity units of super factories with 1 million kilowatt-hours and 100 million kilowatt-hours.
After 7 years of construction, in 2020, Tesla’s Gigafactory in Nevada achieved an annual production capacity of 35 GWh/year, becoming the world’s largest battery factory.
So, how long does it take for Dojo to truly use exaflops as a measuring unit from scratch? As mentioned earlier, Tesla needs about a year to achieve the operation of Dojo V1.0.
Looking at the world, where do supercomputers using exaflops as a measuring unit stand? Below is the Top 10 list of global supercomputers updated by the International Supercomputer Conference (ISC) in June 2020.
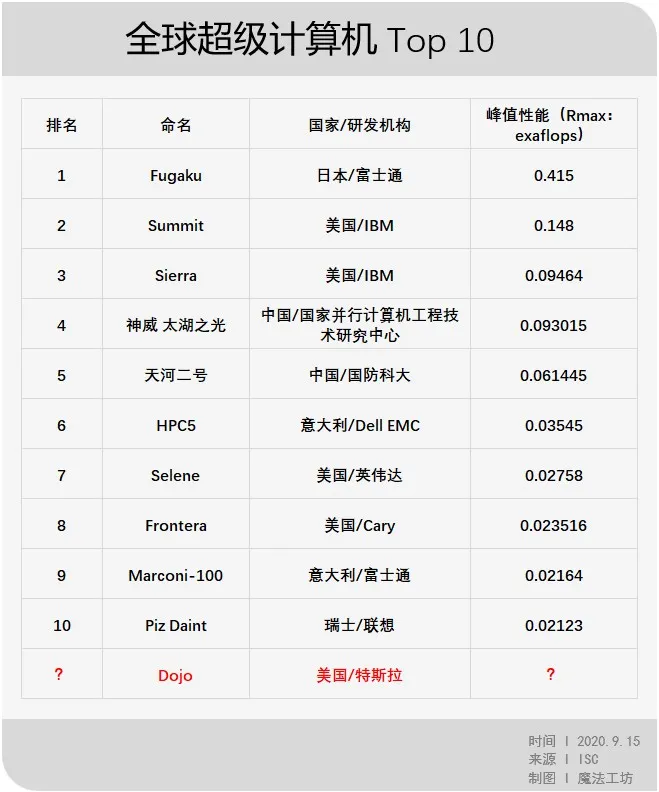
As can be seen, a truly exaflop-class supercomputer has not yet appeared in the world. The peak performance of the first-ranked Fugaku is only 0.415 exaflops.
Compared with Elon’s ultra-high-performance Dojo, what we should pay more attention to may be the significance of autonomous driving to automakers.
Looking back at the table above, without exception, the top ten supercomputers are developed by professional computer manufacturers and owned by national laboratories of various countries. Their application scenarios are also mostly in the fields of medium and long-term weather forecasts, oil and gas exploration, physical simulation, quantum mechanics, and other areas that commercial companies cannot effectively address.
That is to say, before this, the development and implementation of supercomputers mostly reflected the national will of various countries, and the common application scenarios were those super large-scale computing scenarios that commercial companies could not solve effectively.
Tesla is the first automaker to manufacture world-class supercomputers driven by business needs for ultra-high computing power in autonomous driving.
With the advent of autonomous driving in the automotive industry, can we still regard the automotive industry as a light industry based on manufacturing? Nothing can better illustrate that the automotive industry has completely evolved into a high-precision industry representing the cutting-edge research and development capabilities of a country than developing a supercomputer.
The Final Blow
In an article on the topic of Dojo supercomputers, why do we spend more than half of the space describing Tesla’s 8 cameras, FSD autonomous driving chips, and data flow automation development process?The origin of everything can be traced back to the eight cameras in 2015. In the QA session of Tesla’s v7.0 release event in October 2015, Elon unveiled the five-year plan of Tesla’s Autopilot department:
“The Autopilot 1.0 hardware is not a complete autonomous driving sensor system. To achieve autonomous driving, it is obviously necessary to have a 360-degree visual coverage, redundant front cameras, redundant computing platforms, and power and steering systems.”
Over the course of five years, Tesla Autopilot has iterated on this plan through three hardware versions.
With “redundant power and steering systems” and the completion of the Dojo supercomputer in one more year, Tesla’s self-driving cars just need one final push.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.