
Abstract
-
In 2020, self-supervised learning may upgrade the latest technology status of computer vision.
-
Tesla is committing to a specialized computer – Dojo, which employed self-supervised learning technology for training neural networks.
-
With the help of active learning technology, Tesla can automatically create the most useful video clips for self-supervised learning, and the video material is sourced from nearly 750,000 Tesla-connected cars with cameras.
-
Tesla’s large fleet can also provide additional benefits in computer vision, behavioral prediction, and (autonomous driving) decision-making.
-
Regarding the trillion-dollar (income generated) question: Can unmanned taxis be realized? If this goal can be achieved, and Tesla can mass deploy unmanned taxis, the company’s stock price may double.
In my opinion, “Among the variables that affect Tesla’s long-term market value, the most important unknown variable is whether the company has the ability to launch an autonomous driving taxi (or unmanned taxi) service.”
This is why I closely follow Tesla’s latest software upgrade packages, and why I am trying to learn about machine learning in related fields. This way, my confidence in understanding the technology behind it will be stronger.
Here is the latest news: Tesla has just launched what it calls “Full Self-Driving Visualization Preview”. The software upgrade displays target object detection on the vehicle’s display, providing parking signs, traffic lights (including color changes), lane lines, turn arrows, and even garbage cans.
The visualization function looks like a video game that showcases minimalist graphics. The video podcast below shows the status of the new software while the vehicle is running.
Obviously, Tesla is continuously improving its computer vision capabilities, and the company’s recent goal is to release new Autopilot features for use on urban roads.
In this article, I will continue to explore this technology and firmly believe that Tesla will continue to improve its computer vision capabilities. I will also explain why I believe this technology will gain a competitive advantage in the field of autonomous driving.
Weakly Supervised Learning for Computer Vision
In my previous Tesla articles, I discussed how clues to human behavior can provide automatic labels for camera data. Such automatically labeled data can be used to train artificial neural networks related to computer vision. For autonomous driving technology, computer vision is an indispensable part. This method is called weakly supervised learning.The main example I explore is labeling the area of manual driving as “free space” (such as blank space), while labeling all other areas except for free space as non-free space (such as occupied space). Another example (not limited to visual) is predicting the curvature of the road based on the driver’s steering angle.
In addition to these examples, there are various relationships between human behavior and environmental factors (driving). For example, a generally good (but not perfect) predictor can predict whether a traffic light is red or green, and therefore determine whether the human driver should stop or continue driving based on weak supervisions.
Competitors such as General Cruise and Google Waymo own a large number of vehicles, accounting for almost one-thousandth of the total number of vehicles on the road. However, for Tesla, the advantage of weak supervision learning is that its automatic labeling training data collection is nearly a thousand times that of other competitors.
According to Baidu’s research, if Tesla has a data volume that is nearly a thousand times that of other competitors, Tesla may surpass its competitors in terms of neural network performance, and the amount of automatic labeling tasks the company can obtain is ten times or more of that of its competitors.
Weak supervision learning forms a clear contrast with fully supervised learning, which is the most common form of deep learning in computer vision.
In the fully supervised learning mode, manual annotators complete manual labeling of image or video content, a process that is undoubtedly time-consuming and laborious. Of course, fully supervised learning can be scaled up until its labor cost is too high to afford. However, fully supervised learning can be shared with weak supervision learning and other methods. Therefore, from a personal perspective, I believe that fully supervised learning will continue to play an important role in the foreseeable future.
Self-supervised learning is another method that aims to avoid the labor cost of manual labeling of data. As the name implies, in the self-supervised learning mode, data can be self-monitored. In other words, the training signal will tell the neural network which output values are correct and which incorrect output values should be blamed on the data itself. Let me give a concrete example.
Companies like Tesla can collect massive image data through in-vehicle cameras. Self-supervised learning can attempt to learn the internal structure of such images-recurring patterns inside the images, which requires task training to achieve, and this task represents a proxy for what we really want the neural network to do, called a proxy task (also known as a pretext task).The proxy task may involve extracting an image that has removed random patches and filled in missing pixels. During training, the neural network can access the entire unmodified image.
During testing, a set of new images that have never been seen before, with random missing patches, are presented to the neural network. By comparing the generated pixel frames with the actual missing pixels, the accuracy of the neural network can be determined.
This “fill in the blanks” concept can be used for missing patches in video frames. Therefore, companies like Tesla may be able to use sequence frames from video clips, not just images.
Then, I understood that in the training process of such proxy tasks, the neural network can learn to express various aspects of the physical world, including targets such as cars, humans, bicycles, and road surfaces such as lanes, sidewalks, and lawns.
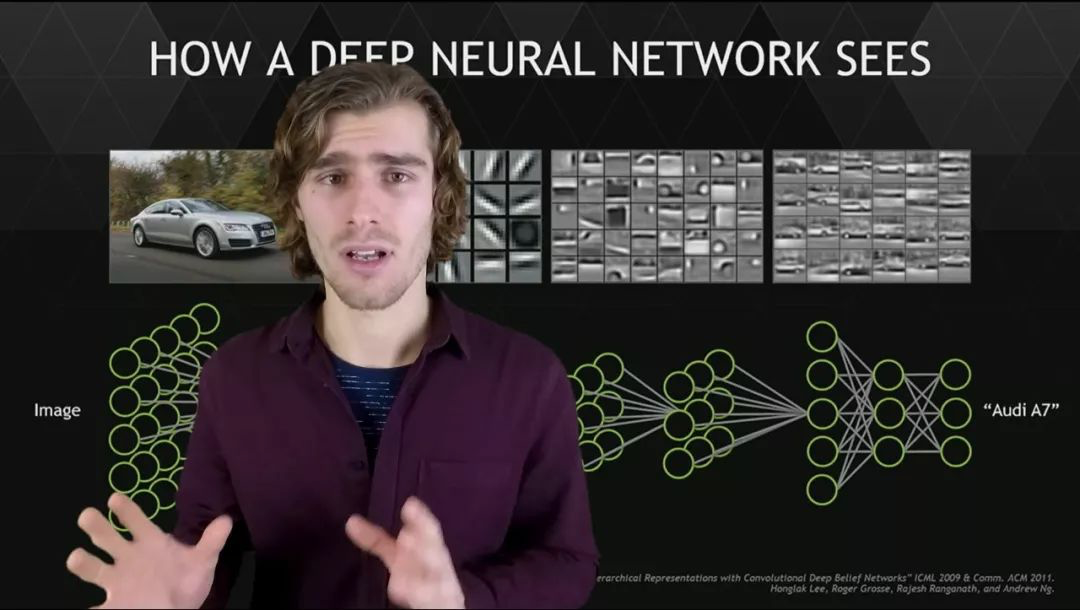
Training a neural network in one or more proxy tasks will involve pre-training. Then, the same neural network can be trained with manually labeled images or videos, known as “fine-tuning”.
The annotation team created 3D boxes (3D bounding boxes) for objects such as vehicles in each frame of images of road surfaces, and then used color codes. Neural networks learn these displayed labels (explicit labels) faster and perform better because they have already established internal representations of such visual phenomena.
In fully supervised learning mode, the neural network can improve existing representations of this kind and associate them with explicit labels. This is where self-supervised pre-training comes in to drive fully supervised learning.
In a recent paper published by DeepMind, researchers found that with self-supervised pre-training, providing only half of the manually annotated images as training examples can achieve better results in image recognition. In contrast, the same neural network would require twice the number of image examples to achieve the same effect. Therefore, the data validity of self-supervised pre-training is more than twice the effectiveness of the neural network.### Translation
In another experiment, researchers provided a pre-training dataset for neural networks which consisted only 1% of the amount of conventional manually annotated training data. However, the pre-trained neural network outperformed other non-pre-trained networks, whose training data size was as high as 5% of the training dataset. Obviously, the data effectiveness of the former is five times that of the latter.
The practitioners in deep learning predict that self-supervised learning will become a remarkable research field because if the nut can be cracked, it will benefit computer vision and other deep learning tasks by achieving scaling through data and computation without staggering human costs.
Today, the duration of videos on YouTube has reached billions of hours. Google has collected nearly 350,000 hours of open data sets from video clips created from YouTube for deep learning research. The research data is there.
Tesla has approximately 750,000 vehicles equipped with eight cameras each, with an average driving time of about one hour per day. This means that the entire Tesla fleet can obtain about 20 million hours of video time per month. If all the videos captured by these vehicles’ eight cameras are collected, the cumulative duration of the videos is about 170 million hours.
Tesla has a lot of videos, and manual annotation is not economically feasible. However, self-supervised learning can provide the correct proxy task, and this technique may automatically extract video clip segments from massive videos, and then extract excellent intrinsic representations. If this representation is obtained through multiple fully supervised learning approaches, its data effectiveness may increase several times.

How Tesla Uses Self-Supervised Learning in Computer Vision
At Tesla’s Autonomy Day event in April 2019, CEO Elon Musk hinted that self-supervised learning was the company’s top priority. (Note: Unsupervised learning is synonymous with self-supervised learning).
Musk said, “Vehicles are conclusion optimization computers. Tesla is working on a big project that I can’t talk too much about today called Dojo, which is a super powerful training computer. Dojo will be able to ingest massive amounts of video data. We can also use the Dojo computer to do massive unsupervised training on video.”In a recent statement, Andrej Karpathy, the senior director of artificial intelligence at Tesla, stated that the ultimate goal of training computers with Dojo is to achieve lower costs and significantly improve performance. It is currently unknown what stage the development of Dojo is at or when it will be deployed.
We have learned that Tesla is exploring self-supervised learning for computer vision, specifically for perceiving depth in a given field.
With nearly 750,000 smart connected vehicles in their fleet, Tesla is capable of using active learning to select and save relevant video clips, which are then uploaded via wireless network. Active learning attempts to choose the most instructive training examples through various methods to maximize learning efficiency.
For example, Nvidia has developed a method for automatically selecting video frames from lengthy driving videos. They then paid human evaluators to manually select frames and compared the results to the automated method. Nvidia found that using the automated video frame selection improved neural network performance by 3-4 times compared to manual selection.
Therefore, it is likely that Tesla will use active learning to automatically create video clips from their vehicle fleet’s videos. The company will use self-supervised learning techniques and these video clips to automatically train their neural networks, accelerating the process with Dojo-trained computers.
Yann LeCun, a pioneer in the field of deep learning mentioned earlier, expects researchers to break through in self-supervised video learning technology. He estimates that by 2020, practitioners in the field of deep learning will be able to successfully apply self-supervised video learning in a meaningful way.
When this happens, I believe Tesla may achieve results as significant as those of DeepMind in video-based (self-supervised learning) tasks, increasing its data efficiency by up to 5 times or more with its image recognition technology.
It is worth noting that active learning can be applied to any form of data collection and will serve Tesla’s machine learning technology. When training examples are manually labeled, this will increase efficiency. When bandwidth, data storage, or computation becomes a constraint, active learning enables Tesla to achieve higher neural network performance under those constraints.
It is speculated that with nearly 750,000 cars on the road, Tesla will encounter a higher number of top-quality examples than its competitors. In computer vision, this not only applies to self-supervised or weakly supervised learning, but also to fully supervised learning. In self-supervised or weakly supervised learning, Tesla holds an advantage in terms of data scope. Active learning can also be applied in fields other than computer vision.## Can Lidar Give Tesla an Overwhelming Advantage?
Tesla is known for not using Lidar in its vehicles and currently has no plans to adopt Lidar technology. However, there is some encouraging news recently.
Mobileye has released a demo video showing a self-driving car navigating through the streets of Jerusalem using an 8-camera perception suite that offers road guidance to the test vehicles. Although the processing power of the test vehicle is only a third of Tesla’s latest models.
My view is that if, competing companies such as Waymo, indicate Lidar-equipped autonomous taxis are a practical goal and Tesla cannot develop autonomous taxis without Lidar technology. Therefore, even if Lidar were adopted, it would not necessarily pose an overwhelming challenge to Tesla.
Though Tesla entered the industry late, it has a great advantage in almost every important area of autonomous driving, except for Lidar perception, thanks to its large fleet of data, including computer vision.
If Waymo is the first company to truly deploy large-scale autonomous driving businesses, I believe Tesla can be a fast follower. In this scenario, committing to acquire an autonomous driving startup that has long been involved in Lidar perception technology would undoubtedly be a strategic wise move.
With revenue from autonomous taxis, Tesla could provide several benefits for customers who purchased its full self-driving suite, such as retrofitting services or even buying back their cars and retrofitting them, or paying them in cash. This goal is achievable because: 1. Autonomous taxis are expected to be a very profitable business; 2. Retrofitted cars can also be deployed as autonomous taxis.
Regarding computing hardware, the same approach can be taken. If the computing power of Tesla’s production vehicles is insufficient to support the neural network of autonomous taxis, the company can configure expensive heavy-duty hardware equipment specially, like Waymo’s workshop.
Tesla’s autonomous driving system consists of three major components: computer vision, behavior prediction, and planning (sometimes called “decision-making”).
-
Computer vision refers to the scene “seen” by the vehicle.
-
Behavior prediction refers to the prediction of behavior and trajectory of pedestrians, cyclists, vehicles, animals, and other moving targets on the road.
-
Planning means that the vehicle will decide on its own actions and determine its trajectory based on spatial and temporal factors.Tesla can use behavior prediction methods to train neural networks, which are very similar to LeCun’s predictive computer vision self-supervised learning method, and this method will soon be implemented.
Compared with predicting future video frames, the behavior prediction neural network only needs to predict the trajectory of abstract representations, such as the 3D bounding box around a vehicle. This training is self-supervised because the computer vision system tells the vehicle whether the bounding box is moving according to its predicted trajectory.
Abstract representations, such as 3D bounding boxes, used for (behavior) prediction can also be used for planning. Essentially, there are two main ways for neural networks to learn planning:
-
Learn by imitating human behavior, i.e., “imitation learning”.
-
Learn by trial and error, i.e., “reinforcement learning”. Karpathy discussed imitation learning in detail at Tesla’s Autonomy Day.
Imitation learning and reinforcement learning can be mixed and matched for better results than simply using one technique. In addition, neural networks and hand-coded software can be mixed and used to better cope with new situations without sufficient training data. When the neural network is not confident, the system will hand control over to the hand-coded planner.
I will discuss imitation learning and reinforcement learning in more detail in future articles.
Questions involving trillions of dollars (investments)
Overall, by combining large fleet data with active learning, Tesla believes it has many advantages in the following five different areas:
-
Fully supervised learning for computer vision (e.g., training based on manually annotated images and videos).
-
Weakly supervised learning for computer vision (e.g., using images and video labels generated by drivers).
-
Self-supervised learning for computer vision (e.g., using video clips to predict the contents of other parts of the video).
-
Self-supervised learning for prediction (e.g., using abstract representations of past behavior, such as bounding boxes, to predict the future).
-
Imitation and reinforcement learning for planning (e.g., using human behavior and real-world experience to train neural networks and using abstract representations as input to make driving decisions).
According to the Baidu study I mentioned earlier, when Tesla’s training data collection reaches nearly a thousand times that of its competitors in any of the above areas (such as the second, fourth, and fifth items listed above), the performance of Tesla’s neural networks may be ten times that of its competitors. In areas where active learning can be applied on a large scale (including the first and third items listed above), its performance may be several times better.For rare wild animals such as bears, moose, and uncommon vehicles like trailers, Tesla’s data collection is a thousand times higher than their competitors because their competitors have a much smaller fleet.
So, is this kind of technology and advantage enough to solve the problems faced by autonomous taxis? This is a trillion-dollar issue.
ARK Invest’s financial model calculates that 5 million autonomous taxis will bring Tesla a market cap of $1.4 trillion (approximately RMB 96 trillion) and Tesla’s stock price will also increase to $6,100 per share (approximately RMB 41,919.81 per share). This means that the total market cap of global autonomous taxi companies will reach $4 trillion (approximately RMB 27.49 trillion):
McKinsey predicts that in the Chinese market alone, the sales of autonomous taxis and fully automatic driving vehicles will generate $2 trillion (approximately RMB 13.74 trillion) in annual revenue, provided that almost two-thirds of the passenger traffic mileage in China will be completed by fully automatic driving vehicles.
So, the question arises: is an autonomous taxi feasible? If so, how long do we have to wait to achieve this goal?
The most encouraging news may come from Waymo, which has finally provided autonomous riding experience for some of its earlier test users:
As for the question of whether the experience of autonomous driving can be expanded on a large scale and ensure its safety, it remains to be seen. In addition, the industry is still looking forward to Waymo’s demonstration of related statistical data to prove that its autonomous riding experience is indeed safer than human driving.
I hope that Waymo will make autonomous riding a commonplace thing rather than a rare exception. I also hope that the company will release more rigorous safety data to prove to the world that it has made a prudent decision.
Cruise also inadvertently provided some safety data to the public because one of the company’s internal reports was leaked to the media. The report included a company internal forecast that was completed in mid-2019. According to Cruise’s estimates, by the end of 2019, the safety of autonomous vehicles under Cruise will reach 5-11% of human driven vehicles.
For me personally, this is very encouraging news because this data shows that if Cruise’s prediction is proven to be accurate, then “only” a tenfold to twenty-five-fold increase in the safety of autonomous driving is needed to ensure that the operation safety of vehicles is comparable to that of human driving or even exceeds it.As for me personally, this news is quite encouraging, as the value has been confirmed, which is definitely better than the situation of “to improve nearly a thousand times to achieve the level of manual driving”. According to research by Baidu, DeepMind, and NVIDIA, improving by 10 times in the field of machine learning is also not unheard of.
In addition, I will closely follow the release (or continue postponing) of Tesla’s “feature-complete” fully automated driving, which is a very important version of Autopilot that can achieve driving on urban roads and suburbs.
If the initial version of the feature-complete fully automated driving suite encounters the same flaws as the initial versions of Navigate on Autopilot and Smart Summon, I wouldn’t be surprised at all. However, I believe that Tesla will need to meticulously polish this version within 1-3 years after its release.
As for predicting when Tesla’s self-driving taxis will hit the market, or whether they will hit the market at all, I’m a bit uncertain. However, I firmly believe that Tesla will not be too far away from the futuristic driving assist technology, a technology that may make traditional car companies envious.
Tesla has the upper hand in the field of electric vehicles, which may help it occupy a place in the global electric vehicle market, and its market share in the future may be comparable to Toyota.
This article is a translation by ChatGPT of a Chinese report from 42HOW. If you have any questions about it, please email bd@42how.com.